JC-1、python学习笔记
目录
- 一. 语言基础
-
- 1. 数据类型
-
- 1.1. 字符串(2020.05.27)
- 1.2. 整数与浮点数(2020.05.27)
- 1.3. 布尔型(2020.05.27)
- 1.4. 时间日期(2020.05.27)
- 1.5. 类型查看与转换(2020.05.27)
- 2. 数据结构
-
- 2.1. 列表(list)(2020.05.27)
- 2.2. 元组(tuple)(2020.05.28)
- 2.3. 集合(set)(2020.05.28)
- 2.4. 字典(dict)(2020.05.28)
- 2.5. 列表、元组、集合、字典的互相转换(2020.05.28)
- 3. 控制流程
-
- 3.1. 顺序结构(2020.05.28)
- 3.2. if分支(2020.05.28)
- 3.3. while循环(2020.05.28)
- 二. DAY_1
-
-
- 1.1. input()键入与格式化输出(2020.05.28)
- 1.2. sys和os的常用命令(2020.05.28)
- 1.3. 三元运算、编码变换和全局变量(2020.05.29)
-
- 三. DAY_2
-
-
- 1.1. 函数(2020.05.30)
- 1.2. 类(2020.06.06)
- 1.3. 文件和异常(2020.05.31)
-
一. 语言基础
1. 数据类型
1.1. 字符串(2020.05.27)
#1.字符串基本操作
print ('hello world!')
c = 'it is a "dog"!'
print (c)
c1 = "it's a dog!"
print (c1)
c2 = """hello
world
!"""
print (c2)
print ("""hello
python
!""")
#总结:字符串的输出可用单引号、双引号、三引号,但需保证与字符串中的引号不重合,不冲突。三引号
# 情况下字符串汇中有换行符也不影响输出
#2.转义字符\
print ('it\'s a dog!')#可以看到字符串的引用是单引号,字符串中也有单引号,但增加了转义字符\
#后,字符串中的单引号则不报错
print ("hello world!\nhello python!")#\n相当于回车的作用
print ('\\\t\\')#\t是制表符,其前后各还有两个\是因为\已被制表符占用,要对\进行转义
#总结:转义字符\针对其后的字符进行转义
#3.原样输出引号内字符可在引号前加r,此时引号内的符号的特殊含意消失,看到的是什么样,输出就是
# 什么样
print (r'\\\t\\')
#总结,除非输出简单字符串,其他字符串的输出尽量不要赋值,直接print加引号输出
#4.子字符串及运算
s = 'python'
print ('py' in s)
print ('Py' in s)
print ("python" in s)
print ('tho' in s)
#总结:功能是判断子字符串(区分大小写)是否是原字符串的一部分,,输出为布尔型
#5.从字符串中取字符
print (s[2])
print (s[1:3])
print (s[0:60])#若索引超过字符串长度,则取完为止
#实现了取单个字符和取字符片段的功能
#6.字符串连接与格式化输出
word1 = '"hello"'
word2 = "'world'"
print ('the first word is %s,and the second word is %s'%(word1,word2))#此处的%s是指后
#边括号中的内容,第一个%s指()中的第一个字符串,第2个%s指()中的第2个字符串
print (word1 + ' '+word2+'.')
sentence = word1.strip('"')+' '+word2.strip("'")+"!"#strip意为剥离
print (sentence)
#总结:%s的用法,字符串的连接与剥离
# 修改字符串变量内容
name = '无为'
print ('Hello',name)
name1 = name
name = 'Adam'
print ('Hello',name)
# 三引号的三种使用
# 1. 多行注释
'''第一行注释
第二行注释
第三行注释
'''
# 2. 打印多行字符串
str1 = '''第一行内容
第二行内容'''
print (str1)
# 3. 不使用转义字符\的前提下,和单(双)引号配合嵌套使用,避免冲突
str2 = '''I'm a man!'''
print (str2)
重要补充:
1.print中的连接(不论是字符串或是什么东西),尽量用,而不用+。
2.单行注释可用#注释,多行注释用’’‘注释’’'或""“注释”""。
3.三引号’’'的三种功能:1)、三引号可用于多行注释、2)、字符串中与单(双)引号形成嵌套、3)、打印多行字符串,其中换行可在字符串的引号中输出\n或直接键入回车。
4.注意格式化输出的方法,%s,%d,%f,分别表示字符型,整型,浮点型。cf本文后文内容的——键入与格式化输出。点击参考文章。
1.2. 整数与浮点数(2020.05.27)
#整数,任意大小,正负
a = 7
b = a + 3
c = 5 - 3
d = 5 * 3
e = 7 / 3
f = 7 // 3
g = 7 % 3
h = 7 ** 3
print (a,b,c,d,e,f,g,h)
#总结:次方用**表示,除法取整用//表示,除法取余用%,print输出多个结果时用,隔开
#浮点数
i = 7.0 / 3
j = 1.11*10**2#先计算平方
k = 0b1111#0b表示二进制数,转为十进制数k
l = 0xff#16进制
m = 1.2e-1#1.2乘10的-1次方,e后边的数字是0或正的也要有+号,比如+0,+1,+2
print (i,j,k,l,m)
#总结:继续奋斗
#log运算
import math
print (math.log(math.e+e))
print (math.log(1000,10))#以10为底,1000的对数
#总结:第一个print有困惑
1.3. 布尔型(2020.05.27)
#布尔型
a = True
b = False
c = True and False#区别于集合的交并差运算
d = True or False
e = not True
f = True + False + True#主要此处输出为整型
print (a,b,c,d,e,f)
if 18 >= 6*3 or 'py' in 'python':
g = True
elif 18 >= 6*3 and 'Py' in 'python':
g = False
elif 18 >= 6*3 and 'py' in "python":
g = True
print (g)
#总结:and,or,not的使用,True和False为特殊字符,不可占用,且区分大小写
#布尔型的加减法结果是整型,区分and和加法,回头看两个elif好像没啥用
1.4. 时间日期(2020.05.27)
#获得时间元组
import time
now = time.strptime('2020-05-27','%Y-%m-%d')
now1 = time.strptime('20-05-27','%y-%m-%d')#%Y大写,对应前边的四位数年份2020,小写时前边
#年的格式需改为2位数。横杠处不论是下横杠还是上横杠,空格,或是其他什么类型,前后格式对应即可
print (now,now1)#返回时间元组
#时间元组转换为可读形式
now2 = time.strftime('%y %m %d',now)
print (now2)#将输入的时间元组改为定义的可读格式,即:年 月 日
#获取天数差
import datetime
oneday = datetime.date(2003,6,30)
anotherday = datetime.date(2003,5,20)
deltaday = anotherday - oneday
day = deltaday.days
print (day)#输出为天数的差值,可正可负
# 获取实时时间与时间延迟
print ('start:%s' % time.ctime())
time.sleep(5)# 延迟5秒
print ('end:%s' % time.ctime())# 打印实时时间
重要补充:延迟命令、获取实时时间
datetime格式汇总如下表:
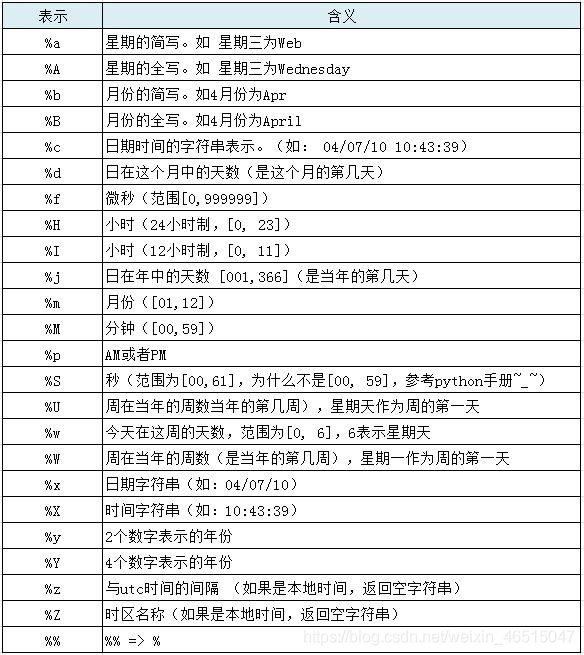
1.5. 类型查看与转换(2020.05.27)
#查看变量类型
a = type(None)#None不属于任何类型
b = type(1.0)
c = type(True)
#d = type(true)不可以,会显示true未定义
e = 'nonetype'
f = type(e)#加',""或3引号的字母即代表字符传送,不加引号的字母代表变量名
print (a,b,c,f)
#总结:查看数据类型或结果,可通过将计算机结果赋给某个变量,在通过print()输出查看
#类型转换
g = str(10086)#此处的g被赋值为字符串类型,相当于g = '10086'
print (g)
h = float(10086)
print (h)
i = int('10086')#字符串类型转为整型
print (i)
j = int(10086.8)#浮点型转换为整型,直接舍掉小数点后的数而不遵从4舍5入
print (j)
k = complex(10086,10085)#输出K为复数类型,即10086+10085j
print (k)
重要补充:欲查看某项中间执行结果,可通过将计算机的中间计算结果赋给某个变量,在通过print()输出查看。
2. 数据结构
2.1. 列表(list)(2020.05.27)
#用来存储数组的容器,列表用[]表示,其中元素类型可不相同
list1 = [0,1,2.1,'a',True,5]#注意字符串a要用''
print (list1)
#用索引调用列表中单个元素,切片顾头不顾尾
print ('[4]=',list1[3])#注意索引从0开始
print ('[-3]='+list1[-3])#字符串的连接仍可用+,-3的含义是从右向左数第3个元素(从1开始)
print ('[1:4]=',list1[1:4])#输出索引为1-4的元素组
print ('[:4]=',list1[:4])#输出索引为:起始-4 的元素组
print ('[2:]=',list1[2:])
print ('[0:4:2]=',list1[0:4:2])#索引范围为0:4,0作为第一个输出元素,后边输出元素的索引以此加2
print ('[-5:-1:]=',list1[-5:-1:])#元素输出的正序还是倒序,取决于从冒号:前的元素算起到冒
#号:后的元素,也就是说:前后元素的位置。此处是从倒数第5个算起到倒数第1个,索引每次+1
print ('[-2::-2]=',list1[-2::-3])#从倒数第2个元素的索引开始推算到倒数第最后,索引每次-2
#总结:元素的输出顺序总是按照从冒号前到冒号后的顺序,[第一个元素:最后一个元素:间隔]
#修改列表
list1[3] = '小华'
print (list1[3])
list1[5] = 10086
print (list1)
#尾部插入元素
list1.append('nian')#增加一个元素到尾部
list1.extend(['yue','ri','shi'])#增加多个元素到尾部,注意多个元素要用数组的形式
print (list1)
# 实现1-10平方的列表
squares = []
for value in range(1,11,1):
squares.append(value**2)
print (squares)
# 列表解析求上述问题
squares1 = [value**2 for value in range(1,11,1)]
print (squares1)
#任意处插入元素或数组
list2 = [16,27,38,49]
list1.insert(1,list2)#在索引1出插入数组,注意此处是小括号()
print (list1)
print (list1[1])#刚才输入的数组只占一个索引,区别于尾部插入多个元素占多个索引
# 删除元素
# del语句删除指定索引元素,被删除的元素无法保存
motor = ['honda','yamaha','suzuki']
del motor[0]
print (motor)
# pop弹出指定索引元素,并删除弹出的元素,可保存删除的元素
a = list1.pop(1)#弹出指定索引对应的元素,并删除原数组中的该元素,保存该元素至a
print (a)
print (list1)
# remove删除指定值元素,被删除元素可以保留
motor = ['honda','yamaha','suzuki']
motor.remove('suzuki')# a = motor.remove('suzuki')
print ('suzuki')# 注意,因此方法指定删除的值,索引自然指定被删除的值是什么
print (motor)
#判断元素是否在列表中
print ('nian' in list1)# 返回布尔型
print ('yue' not in list1)
print (list1.count('ri'))#用于统计某个元素在列表中出现的次数
print (list1.index('nian'))
#range函数生成整数列表
print (range(10))#range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型,
# 所以打印的时候不会打印列表。默认从0到10,步长为1
print (range(-5,5))#默认步长为1
print (range(-10,10,2))#括号中的内容分别是起始值,终止值,步长
print (range(16,10,-1))
for i in range(-2,11,2):
print(i)
# 组织列表sort,sorted,reverse,len
# sort永久性修改
# 按字母正序排列
cars = ['bmw','audi','toyota','subaru']
cars.sort()
print (cars)
# 按字母逆序排列
cars = ['bmw','audi','toyota','subaru']
cars.sort(reverse = True)
print (cars)
# 列表元素为元组时,按照元组中某个位置的元素排列
a = [('b',4),('a',0),('c',2),('d',3)]
print (sorted(a,key = lambda f:f[0]))# 按照各元组中第一个元素对元组进行排序,临时
#key=lambda是固定语句,用于对元组的某个位置元素排列,f为临时指定名称,[0]为元组中元素索引
a.sort(key = lambda f:f[1])# 按照各元组中第二个元素对元组进行排序,永久
print (a)
# sorted临时修改
cars = ['bmw','audi','toyota','subaru']
print (sorted(cars))# 注意与sort的使用格式不同
print (cars)
# reverse倒着打印列表,也为永久性修改使用格式同sort
cars = ['bmw','audi','toyota','subaru']
cars.reverse()
print (cars)
# 虽reverse是永久性修改,但再次使用该命令可使其复原,区别于sort
# len确定列表长度
cars = ['bmw','audi','toyota','subaru']
print (len(cars))
# 数字列表的统计计算
digists = [0,1,2,3,4,5,6,7,8,9]
print (min(digists))
print (max(digists))
print (sum(digists))
# 复制列表的方法及错误
list1 = [1,2,3,4]
list2 = list1[:]
list1.append(5)
print (list1)
list2.append(6)
print (list2)
# 错误复制,而只是给列表[1,2,3,4]取了两个名字
list1 = [1,2,3,4]
list2 = list1
list1.append(5)
print (list1)
list2.append(6)
print (list2)
重要提示:
- range()的使用和切片的索引,都是顾头不顾尾,例如range(-10,10,2),访问-10而不访问10访问区间为[-10,10),步长为2。
- 末尾增加一个元素append(),末尾增加多个元素(多个索引)extend(),在指定索引插入元素insert()的用法
- 计数count(),获取指定值的索引index()的用法
- list1.pop()的用法,弹出列表中的指定索引对应的元素,若括号中不填则默认为0;del 、remove的用法。
- sort、sorted、reverse、len的用法。
- 数字列表的统计计算min、max、sum。
- 列表解析求平方的列表squares1 = [value**2 for value in range(1,11,1)]
- 复制列表要用切片法复制,而不可仅用名字复制,用名字赋值相当于只是给同一列表取了两个不同的名字(也就是说两个名字对应同一个列表)。
- 检查指定的元素是否在列表中用in(not in)返回布尔型。
2.2. 元组(tuple)(2020.05.28)
# 元组类似列表,元组中的元素也是进行索引计算。列表中的元素值可以修改,而元组中的不可以,
# 只能读取,元组符号是(),列表符号是[]
scores = [90,80,77,66]
studentstuple = ('ming','jun','qiang','jun',scores)
print (studentstuple)
try:
studentstuple[1] = 'fu'
except TypeError:
print('typeerror')#用此结构证明了元组中元素不可修改
scores[1] = 100
print (studentstuple)#元组中嵌套的列表中的内容可修改
print ('jun' in studentstuple)
print (studentstuple[:4])
print (studentstuple.count('jun'))#统计元组中jun的个数,此处为小括号
print (len(studentstuple))#其中的scores列表仍仅占一个索引
#总结:仅针对索引的处理时用中括号,涉及元素时用小括号
重要提示:
- try:…except :…的应用。cf DAY-2 1.3文件 异常的处理。
- 元组中嵌套的子列表中的元素可以改变
- 抓住列表可读写,元组只可读这一特征,其他的操作列表和元组基本通用。
- 元组中的元素虽不可重新赋值,但可对整个元组重新赋值,相当于对变量重新赋值。
2.3. 集合(set)(2020.05.28)
# 集合的两个功能,一是进行集合操作,二是消除重复元素。集合的格式是:set(),其中()内
# 可以是列表、字典、字符串,因为字符串是以列表的形式存储的
list1 = [0,1,2,'han',4,'long','wan',10086,'小华']
studentsset = set(list1)
print (studentsset)
studentsset.add('xu')#假如此处.add('wan')则打印出的元素中也仅有一个'wan',
#因集合有消除重复元素的功能
print (studentsset)
studentsset.remove('xu')
print (studentsset)#以上三个打印证明了集合中的元素打印出来并不遵从输入的排序
a = set('abcnmaaaaffsnf')
print ('a=',a)#打印集合中的字符串中的每个字符仍无顺序且不重复打印
b = set('abcd')
print ('b=',b)#集合中字符串中各字符的打印、各元素的打印,均无顺序且不重复
#交集
x = a & b#此处不可用and,区别布尔型运算
print ('x=',x)#此处不可用+代替,
#并集
y = a | b
print ('y=',y)
#差集
z = a - b
print ('z=',z)
#总结:集合中字符串中各字符的打印、各元素的打印,均无顺序且不重复
重要补充:
- 注意集合的交并差(& | -)运算区,别于布尔型的与或非(and or not)运算。
- 集合是由命令set(列表)转变而来的。
2.4. 字典(dict)(2020.05.28)
#字典dict也称关联数组,用大括号{},使用keys-values存储,可快速查找,key值不可重复
k = {
'sex':'man','name':'小华'}
print (k['sex'])#索引用中括号[],元素用小括号(),字典用大括号{}
print (k.keys(),k.values())
#增加、修改字典k中的key-value
k["home"] = 'hangzhou'
k['sex'] = 'woman'
print (k)
print (k.get('name'))#获取k中的key对应的value,若没有找到该key则返回None
print (k.get('school',0))#若没有找到'school'对应的值,则返回0
#删除key-value元素
print (k.pop ('home'))#直接删除key即可,对比列表直接删除索引即可
print (k)
#总结:.pop表示弹出且删除在对列表的操作也有体现
# 字典中多个键值对的格式问题,print中内容过长的格式问题
k = {
1 : 'xiaohong',#按回车自动缩进
'name1':'xiaolan',
'name2':'xiaohua',
'name3':'xiaoming',
}
print (k)
print ('I have a good friend,',
'she\'s name is',# 缩进需手动添加Tab键
k['name2'].upper()+
'.')
# 第一部分和最后一部分可视情况长短和前后括号相连
# 遍历字典中的所有键值对
wuhua = {
'name':'adam wu',
'first':'adam',
'last':'wu'
}
print (wuhua.items())
for key,value in wuhua.items():
print ('\nkey:%s'%key)
print ('value:%s'%value)
# 遍历字典中所有的键
for key in wuhua.keys():# 遍历字典会默认遍历所有的键,也就是说如果本行改为for key in wuhua:
#结果不变
print(key)
favorite_languages = {
'xiaohong':'c',
'xiaohua':'python',
'xiaoming':'java',
'xiaoli':'None'
}
friends = ['xiaohong','xiaohua']
for friend in friends:
if friend in favorite_languages.keys():
print ('%s\'s favorite language is %s'%(friend,favorite_languages[friend]))
# 将字典嵌套在列表中
ets = []
for i in range(5):
et = {
'name':'et%s'%i,'sex':'man'}
ets.append(et)
print (ets)
print (ets[:2])
重要补充:
- pop表弹出且删除在对列表中元素和字典中元素的操作中都有体现。
- get()的用法,获取键所对应的值。
- 字典中多个键值对的格式问题,print中内容过长的格式问题,字典定义中每次按回车会自动缩进,print按回车后需手动添加tab键。第一部分和最后一部分可视情况长短和前后括号相连。
- 获得字典中所有的键值对用.items()、获取所有的键用keys()、获取所有的值用values()。这三个命令返回的都是列表!!!
- sort,sorted按照第一个元素的元组中指定元素的位置排序,cf列表
2.5. 列表、元组、集合、字典的互相转换(2020.05.28)
list1 = [0, 1, 2, '小月', 4, 19978, 'han', 'long', 'wan']
k = {
'sex': 'woman', 'name': '小华'}
print (type(list1))
print (tuple(list1))#将列表形式转换为元组形
print (list(k))#注意变量名不要用某命令的名称,例如此处若变量名用list则会出错
#列表,元组,集合,字典的缝合
z = zip(('a','b','c'),[1,2,3])
print (z)
print (dict(z))#以前边元组为keys,后边列表为values,通过dict命令创建字典
#总结:注意变量名不要用某命令的名称,例如此处若变量名用list则会出错
重要补充:注意变量名不要用某命令的名称,例如此处若变量名用list则会出错。变量名只能是 字母、数字或下划线的任意组合
变量名的第一个字符不能是数字
以下关键字不能声明为变量名
[‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘exec’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘not’, ‘or’, ‘pass’, ‘print’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’],也不要使用list,tuple,set,dict这些命令名。
3. 控制流程
3.1. 顺序结构(2020.05.28)
# python中通常程序执行是从上向下执行,而使用控制流语句可改变程序的执行顺序
# 三种控制流类型:顺序结构、分支结构、循环结构。
# python中可以使用分号;分隔语句,但一般用换行分隔。语句块不用大括号{}而使
# 用缩进(可以使用4个空格)
# 顺序结构
s = '7'#字符串类型
num = float(s)#改变数据类型
num -= 1
num *= 6
print (num)
3.2. if分支(2020.05.28)
print ('获得三次分数对应的等级')
count = 0
while count < 3:
score = int(input('输入分数:'))# 此处会先直接打印出'输入分数:',再等待输入,并将输入
# 强制转换为int型,再赋给score。也就是所有的转换和赋值都是针对输入内容的
if score > 100:
print ('Are you kidding me?')
elif score >= 90:
print ('A')
elif score >= 80:
print ('B')
elif score >= 70:
print ('C')
elif score >= 60:
print ('D')
else:
print ('E')
count += 1
print ('3次机会使用完毕')
# python缩进
_username = 'Adam Wu'
_password = '123456'
username = input ('username:')
password = input ('password:')
if _username == username and _password == password:# 用and或or检测多个条件
print ('welcome user {name} login...'.format(name=username))#格式化输出
# print ('welcome user %s login...'%username)
else:
print ('invalid username or password!')
# 总结:注意if...else...的缩进
# 大写字母和小写字母不相同,lower(),upper(),title()不改变数据的原始值
car = 'Audi'
if car =='audi':
print ('True')
elif car.lower()=='audi':
print ('False')
# for循环结合if语句测试等(==)检测列表中的特殊值并做处理
a = [1,2,3,4,5,6]
for i in a:
if i ==3 :
print ('舍掉3')
else:
print ('获取%s'%i)
print ('完成了所有操作\n')
# 检查列表是否为空
a = []
if a:# 若a为空则此语句返回false
print ('a是空列表\n')
else:
print ('a不是空列表\n')
# 若a列表的元素均在b列表中,才将a列表元素输出
a = [0,1,2,3]
b = [1,3,5,7]
for i in a:
if i in b:
print ('输出',i,'\n')
else:
print ('舍去',i,'\n')
重要补充:
- Python的缩进有以下几个原则:
1)、顶级代码必须顶行写,即如果一行代码本身不依赖于任何条件,那它必须不能进行任何缩进
2)、同一级别的代码,缩进必须一致
3)、建议缩进用4个空格(摁一次Tab键)。 - if…elif…elif…else代码是从上到下依次判断,只要满足前一个条件,就不会再往下走。
- 该结构可以仅有if,而没有elif和else。
- 注意name = input(’’)的使用。括号中引号中的内容为提示符,没有实际作用。
- if语句中可用and或or检查多个条件是否满足。
- 大写字母和小写字母不相同,lower(),upper(),title()不改变数据的原始值
- for循环结合if语句测试等(==)检测列表中的特殊值并做处理。
- 检查列表是否为空。
- 若a列表的元素均在b列表中,才将a列表元素输出。
- 约定if条件中,若有==、>=、<=需在符号两侧各加一个空格。
3.3. while循环(2020.05.28)
# break用于完全结束一个循环体,跳出循环体执行循环体后面的语句。continue和break有点类似,
# 区别在于continue只是终止循环体中的本次循环,接着还执行循环体下次的循环。
#break
count = 0
while count <= 100:
if count <=5:
print ('loop',count)
else:
break
count += 1
print ('---out of while loop---')
#continue
count = 0
while count <= 100:
if count >=5 and count <= 95:
count += 1
continue
print ('loop',count)
count += 1#若本行和上一行调换位置,则可输出到loop 101
print ('---out of while loop---')
# 与其它语言else 一般只与if 搭配不同,在Python 中还有个while ...else 语句while 后面
# 的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面
# 的语句
# while ...else...
count = 0
while count <= 5:
print ('loop',count)
count +=1
else:
print ('循环体完整执行完毕')
print ('--- out of while loop---')
#对比没有else的while
count = 0
while count <= 5:
print ('loop',count)
count +=1
print ('循环体完整执行完毕\n--- out of while loop---')
# 总结:感觉这个while...else...没啥用啊
# 如果执行过程中被break啦,就不会执行else的语句啦
count = 0
while count <= 5:
if count == 3:
break
print ('loop',count)
count += 1
else:
print ('循环体完整执行完毕')
if count == 3:
print ('跳出循环体,并且不执行else')
print ('---end---')
# 总结:似乎while...else...还有点用
重要提示:3个点。
- break。2.continue。3.while…else…。break和continue的区别。
- break可用于任何循环,例如for循环,不一定是while。break直接退出整个循环体
- continue仅跳过循环体中的某次循环,直接执行循环体的下次循环
- 用while来移动列表元素至新列表、删除列表中指定的所有元素、将用户输入存为字典。
- 标志位的使用。
二. DAY_1
1.1. input()键入与格式化输出(2020.05.28)
# print、input的使用
name = input ('what\'s your name?\n')
print ('hello '+name)
# 总结:print("Hello",name),print中逗号分隔直接将字符串用空格分隔,若用+号连接,并且
# 想留空格,则在前一字符串留空格即可
#输入输出
username = input('username:')
password = input('password:')
print (username,password)
# 格式输入输出
# 方法1
name=input("Name:")
age=input("age:")
job=input("job:")
info='''---------info of ---------''' + '''
Name:'''+name+'''
Age:'''+age+'''
Job:'''+job
print(info)
#总结:三引号可用于多行注释、打印多行字符串、字符串中与单(双)引号形成嵌套
#方法2
name = input ('name:')
age = int(input ('age:'))# 如果不用int()就无法和后边的%d匹配就会报错,因为虽然键入数
# 字,但print(type(age))为str型。以上原因是python中若不强制类型转换,就会默认字符型
job = input ('job')
info = '''---info of---
name:%s
age:%d
job:%s'''%(name,age,job)
print (info)
# 总结:python中若不强制类型转换,就会默认字符型
# 记住这种输出方法。字符型用%s,整型用%d,浮点型用%f。参考1.1. 字符串的重要补充
# 方法3
name=input("Name:")
age=int(input("age:"))
job=input("job:")
info='''---------info of ---------
Name:{_name}
Age:{_age}
Job:{_job}'''.format(_name=name,_age=age,_job=job)# 区别方法2用%(),
# 方法3、4用的是.format()
print(info)
# 方法4
name=input("Name:")
age=int(input("age:"))
job=input("job:")
info='''---------info of ---------
Name:{0}
Age:{1}
Job:{2}'''.format(name,age,job)
print(info)
# 输入密码不可见
import getpass
pwd = getpass.getpass('请输入密码:')
print (pwd)
# 将提示字符赋给变量,再讲变量作为input的提示符
prompt = 'If you tell me who you are, I can personalize the messages you see.'
prompt += '\nWhat\'s your first name?'
name = input (prompt)
print ('hello',name+'!')
重要提示:
- python中若不强制类型转换,就会默认输入为字符型,以至于不能和数字比较大小。
- 三引号’’'的三种功能:1)、三引号可用于多行注释、2)、字符串中与单(双)引号形成嵌套、3)、打印多行字符串,其中换行可在字符串的引号中输出\n或直接键入回车。
- 使用%s,%d,%f(字符,整数,浮点数)的格式化输出。
- 变量中存储字符串时,仍可使用+=来扩充字符串;可将变量作为input()的输入提示文字。
1.2. sys和os的常用命令(2020.05.28)
# sys的使用
import sys
print (sys.path)# 返回模块的搜索路径,初始化时使用 PYTHONPATH 环境变量的值
print (sys.path[0])# sys.path[0]表示本文件所在目录的路径
print (sys.argv)# 打印命令行参数 List所有元素,第一个元素是程序本身路径,也可以打印
# 某指定索引对应的路径,例如sys.argv[0]表示本文件路径
print (sys.argv[0])# sys.argv[0]表示本文件的路径
# print (sys.exit(-1))
# sys.exit(n)退出程序引发SystemExit异常. n默认值为0, 表示正常退出. 其他都是非正常退出.
# 如果状态是整数,它将被用作系统退出状态。
# 如果它是另一种对象,如sys.exit("sorry!"),它就会被打印到系统中,退出状态将为1。
# 一般主程序中使用此退出.
# 进度条
import time
for i in range(50):
sys.stdout.write('#')# sys.stdout标准输出,其形式是print的一种默认输出格式
sys.stdout.flush()# 刷新输出
time.sleep(0.01)# 延迟0.01秒
# os的使用
import os
cmd_res = os.system ('dir')
print ('——>',cmd_res)
# 总结:system函数可以将字符串转化成命令在服务器上运行
# os.system()执行后直接输出到终端,然后结束
cmd_res1 = os.popen('dir')
print ('——>',cmd_res1)
# 得到的是内存对象值
cmd1_res1 = os.popen('dir').read()
print ('——>',cmd_res1)
# 读取数据必须再后面加个read()
os.mkdir ('new_dir')# 系统会在本文件所在目录下创建名为new_dir的目录
os.removedirs ('new_dir')# 系统会删除本文件所在目录下名为new_dir的目录
print ('path =',os.path.join('中国','北京','清华大学'))
# 创建对多个路径的连接,输出为:path = 中国\北京\清华大学
print ('dirname =',os.path.dirname(sys.argv[0]))
# os.path.dirname()返回指定文件所在目录的路径,括号中的文件路径可指定;而sys.path[0]
# 仅返回本文件所在目录路径
print (os.listdir(sys.path[0]))
# os.listdir() 方法用于返回指定对象()下包含的文件或文件夹的名字的列表list。
print (os.path.isdir(sys.path[0]))
# os.path.isdir()用于判断对象是否为一个目录路径,返回布尔型
print (os.path.isfile(sys.argv[0]))
# os.path.isfile()用于判断对象是否为一个文件路径,返回布尔型
print (os.path.exists(sys.argv[0]))
print (os.path.exists(sys.path[0]))
# os.path.exists()判断对象是否存在,对象可以是文件路径或目录路径,总之是个路径
print (os.path.split(sys.argv[0]))
# os.path.split()将对象(可为文件或文件夹)切分成所在目录路径和文件名(或文件夹名),
# 并存储在元组tuple
重要补充:
绝对路径:E:\book\网页布\代码\第2章\bg.jpg 缺点:在其他设备环境失效
相对路径:.\model\plate_recongnize\model.ckpt-70.meta前部的.\代表代码文件所在的目录路径,重点掌握!
虚拟路径:/img/bg.jpg的真实路径为E:\book\网页 布局\代码\第2章\img\bg.jpg
重要提示:
os即operating system(操作系统)Python中的os模块用于和系统进行交互。相当于提供了命令对系统进行主动操作,修改系统中内容,可理解为对系统进行读写操作;而sys相当于提供了命令对系统进行只读操作。(2020.05.29的粗浅理解)
os 模块提供了非常丰富的方法用来处理文件和目录
os和sys的常用命令
1.3. 三元运算、编码变换和全局变量(2020.05.29)
# 三元运算
a=1
b=2
c=3
d=a if a<b else c# 如果a>b则d = a,否则d = c
print(d)
# 编码变换
# str与bytes的转化
# utf-8与gbk互相转化需要通过Unicode作为中介
msg = "我爱杭州西湖!"# 默认编码为Unicode
print (msg)
print (msg.encode(encoding = "utf-8"))# 转码为utf-8格式
print (msg.encode('utf-8'))#与上行效果相同,但代码更简洁
print (msg.encode(encoding = 'utf-8').decode(encoding = 'utf-8'))# 解码为Unicode格式
print (msg.encode('gbk'))
print (msg.encode('gbk').decode('gbk').encode('gb2312'))
# 此时msg.encode('gbk')即转为gbk了。在转为gb2312之前,则需要先告诉Unicode你原先的编码
# 是什么,即msg.encode('gbk').decode('gbk'),再对其进行编码为gb2312,即最终
# 为msg.encode('gbk').decode('gbk').encode('gb2312')
# 总结:python3中文本是Unicode格式即str类型表示,二进制数用bytes表示,并且不自动相互转化
# 全局变量
names = ['xiaoming','xiaohong','xiaohua']
def change_name():# 除了整数和字符串在函数内不能改,列表,字典这些可以改
names[0] = '小明'
print ('inside func',names
)# 此处生成一个回车
change_name()
print (names)
# 当全局变量与局部变量同名时,在定义局部变量的子程序内,局部变量起作用,在其它
# 地方全局变量起作用。
重要提示:
全局变量中,除了整数和字符串在函数内不能改,列表,字典这些可以在函数中改。
三. DAY_2
1.1. 函数(2020.05.30)
# 1.无参函数
def fun1():# 定义一个函数
'''test1'''
print ('in the function1')
return 1
# 定义一个过程,实质就是没有返回值的函数
def fun2():
'''test2'''
print ("in the function2")
x = fun1()
y = fun2()
print (x)
print (y)# 没有返回值是,返回None不属于任何类型
import time
def logger():
time_format = '%Y %m %d %X %A %B %p %I'
time_current = time.strftime(time_format)# time strftime() 函数接收以时间元组,
# 并返回以可读字符串表示的当地时间,格式由参数format决定。
with open('用python生成(读写)的文档.txt','a+')as f:# 判断同级目录下有无生成(读写).txt文件,
# 若没有则创建并打开,若有则打开
f.write('time %s end action\n'%time_current)# 在该文件中写入文本
def test1():
print ('in the test1')
logger()
def test2():
print ('in the test2')
logger()
return 0
def test3():
print ('in the test3')
logger()
return 1,{
5:'sda',6:'zad'},[1,2,3]
x = test1()# 这也是调用函数的方法,只不过同时间函数返回值赋给了x
y = test2()
z = test3()
print (x)
print (y)
print (z)
'''总结:返回值个数为0时返回:None
返回值个数为1是返回设定值
返回值个数>1时,返回元组tuple'''
# 2.有参数函数
def test(x,y=1):# 给某形参赋默认值,若后续不给该形参传递实参,则使用该默认值
print (x,y)
test(1,2)#位置实参,与顺序有关
test(y=2,x=1)# 关键字,与顺序无关
test(1,y=2)# 既有关键字调用又有位置参数,前面一个一定是位置参数,一句话:关键参数一定不能写在位置参数前面
test(1)# 使用默认值y=1
def describe_pet (name,type1='dog'):# 形参实参赋值时等号前后不能有空格
# 形参付默认值,一般放在最后一个参数位置,目的是防止调用时使用位置实参时出错。
# 不给形参赋值时使用形参的默认值。
print ('\nI have a',type1)
print ('My',type1+'\'s name is',name.title(),'.')# title()表示各单词首字母大写
describe_pet(type1='cat',name='adam')# 关键字传递实参方法,不区分参数前后顺序
# 总结:upper()表示个单词字母均大写,lower()各单词字母均小写
def describe_pet_one (name,type1):
print ('\nI have a',type1)
print ('my %s\'s name is %s.'%(type1,name.title()))
describe_pet_one('xiaoming','dog')# 位置参数传递
# 用*args传递多个参数,转换成元组的方式。*表示一个功能代号表示接受的参数不固定,args随意起名
def test(*args):
print (args)
test(1,2,3,4,5,6)
test(*(1,2,3,4,5,6))# 直接就赋值为*元组的形式
def test(x,*args):# *args放在最后
print (x)
print(args)
test(1,2,3,4,5,6)
# 字典传值 **kwagrs:把N个关键字参数,转换成字典的方式
def test(**kwargs):
print (kwargs)
print (kwargs['name'].title(),kwargs['age'],kwargs['id'],kwargs['sex'])
test(name='adam',age=23,id=10,sex='man')# 因为是转换成字典的方式,所以采用关键字赋值
# 此处仍然是函数关键字赋值的方法
# 对比字典增加、修改key-value的方法:kwargs['name'] = adam
test(**{
'name': 'adam', 'age': 23, 'id': 10, 'sex': 'man'})# 直接赋值为**字典的形式
def test(name,**kwargs):
print (name.title())
print (kwargs)
test('adam',age=23,job='student')
#默认参数得放在参数组前面
def test(name,age=23,**kwargs):
print (name)
print (age)
print (kwargs)
test('Adam',sex='man',job='student',age=100)# 优先赋值给定义过的默认参数,然后才是字典
test('Adam',3,sex='man',job='student')# 使用位置参数时位置要对应
test('Adam')# 后边的**kwarges不赋值输出为空字典
def test(name,age=23,*args,**kwargs):
print (name)
print (age)
print (args)
print (kwargs)
test('Adam',100,1,2,3,sex='man',job='student')
# 总结:*赋值为元组时类似于位置赋值,**赋值为字典时类似于关键字赋值,
# 形参排列参考顺序:普通形参,赋有默认值的形参,元组形参,字典形参
# 高阶函数
# 变量可以指向函数,函数的参数能接受变量,那么一个函数就可以接受另一个函数的
# 返回值作为参数,这个函数就叫做高阶函数,就相当于一个函数是另一个的子函数,复合函数
def f(x):
return x
def add(x,y,f):
return f(x)+f(y)
res = add(1,2,f)
print (res)
重要补充:
1.time.strftime(time_format)以获取当前时间。
2.title()、upper()、lower()分别表示各单词首字符大写、各单词各字母大写、各单词各字母小写。
3.格式化输出%s。
4.将函数存储在模块中时(也就是将函数存储在另一个文件中),调用时类似于导入Numpy库,使用impor filename导入整个模块,调用时用命令filename.function()。import filename as fn为导入的模块命名,调用时用命令fn.function()。from filename import function1,function2导入模块中的某些函数,调用时直接用function1()、function2()。from filename import function as fn为从模块中导入的某个函数命名,调用时直接用fn()。
5.函数名值包括小写字母和下划线,为形参实参赋值时等号前后不要有空格
6.with open() as f的用法。提供了通过python创建、修改文件的方法
1.2. 类(2020.06.06)
class Dog():
'''模拟小狗的尝试'''
def __init__(self,name,age):
'''初始化属性name和age'''
self.name = name
self.age = age
#上两行的操作可将self.name和self.age应用于该类的所有方法(函数)
def sit(self):#此时仅定义形参self即可将初始化中的name和age都传入
'''模拟命令下蹲'''
print (self.name.title(),'is sitting now.')
def roll_over(self):
'''模拟命令打滚'''
print (self.name.title(),'rolled over.')
# 实例化,通过类可创建任意多的实例
my_dog = Dog('adam',6)# 通过此行命令,可将Dog类中的变量、函数均传给my_dog,
# 并给Dog类中的变量赋初值,这就是将类创建对象的实例化。创建了my_dog实例
print ('my dog\'s name is',my_dog.name.title()+'.')
print ('my dog is',str(my_dog.age),'years old.')# 将数字整型转为字符型
my_dog.sit()
my_dog.roll_over()
print ('\n')
your_dog = Dog('Elizabeth',6)
print ('your dog\'s name is',your_dog.name+'.')
print ('your dog is',str(your_dog.age),'years old.')
your_dog.sit()
your_dog.roll_over()
class Car():
'''模拟汽车的尝试'''
def __init__(self,make,year,model):
'''初始化汽车属性'''
self.make = make
self.year = year
self.model = model
self.odometer_reading = 5# 增添一个属性(并不在形参处增加)并给属性赋初始值
# 该属性和上述属性一样都集成到self中了
def get_desciptive_name(self):
'''返回车的描述性信息'''
long_name = self.make+' '+self.model+' '+str(self.year)# 注意str对整型的转换
print (long_name.title())# 只有上边行使用+时title()才起作用,使用逗号不行
def read_odometer(self):
'''打印里程表'''
return 'This car has '+str(self.odometer_reading)+' miles on it.'
def update_odometer(self,mileage):# 在类中定义修改初始化里程属性的函数,
# 注意mileage仅为该函数的变量而并非全部类的变量
self.odometer_reading += mileage
my_car = Car('audi',2020,'a4')
my_car.get_desciptive_name()
print (my_car.read_odometer())
my_car.update_odometer(23)# 调用增加初始化里程的函数并将增加的值赋上
print (my_car.read_odometer())
'''
修改属性值的方法还可以直接在实例中修改,如:
my_car.odometer_reading += 23
print (my_car.read_odometer())
'''
# 继承
class ElectricCar(Car):# 注意括号内为父类名
'''电动汽车的独特之处
初始化父类属性,初始化电动车特有属性'''
def __init__(self,make,year,model):
super().__init__(make,year,model)# 此语句关联父类的变量初始化
self.battery_size = 70
# 根据ElectricCar类创建的实例都包含该属性
# 而根据Car类创建的实例不包含该属性
def describe_battery(self):
print ('This car has a',str(self.battery_size)+'-KWH battery')
def read_odometer(self):# 在子类中重新定义相同的函数名以修改父类的函数,但仅作用于该子类
print ('在子类中重新定义相同的函数名以修改父类的函数,但仅作用于该子类')
my_tesla = ElectricCar('tesla',2020,'a4')
my_tesla.get_desciptive_name()
my_tesla.describe_battery()
my_tesla.read_odometer()
# 将一些针对同样的属性和方法定义为一个类
class Battery():
def __init__(self,battery_size=70):
'''初始化电瓶属性'''
self.battery_size = battery_size
def describe_battery(self):
'''打印描述电瓶信息'''
print ('This car has a',str(self.battery_size),'-KWH battery.')
class ElectricCar(Car):
'''电动汽车的独特之处'''
def __init__(self,make,year,model):
'''初始化父类属性,再初始化电车特有属性'''
super().__init__(make,year,model)
self.battery = Battery()# 将某属性类赋给变量
my_tesla = ElectricCar('tesla',2020,'a4')
my_tesla.battery.describe_battery()
重要提示:
- 定义类的首字母大写。必须有初始化__init(self,参数1,参数2…)__,且初始化函数中的第一个形参必须是self,在初试化中,将其他形参都传入了self(例如self.参数1 = 参数1),在该类的其他方法(函数)中,仅需在函数定义中写入形参self即可调用init中的所有形参。
- 通过用类创建对象实现实例化,实例化后,直接使用实例名.变量(或实例名.函数)来使用类中的变量和函数。例如本例中的my_dog.name和my_dog.sit()
- 一定注意在定义类和函数时,’’‘注释类或函数的功能’’’,此注释可在调用时自动显示,以提示使用方法。
- 初始化一个属性的办法(不用在__init__中定义形参,直接在初始化函数中写入self.属性 = 5即可),在类中定义函数(该函数的形参不仅包括self还包括刚才定义的属性名)以修改刚才初始化的属性。在实例中若要修改该属性的值,则先调用该函数并赋予属性新的值即可。
- 仅在类中某个函数中定义的形参,在创建实例(括号内不含该形参)后调用该函数时,才在该函数括号内指定实参;若在init括号中没有形参,而在init函数中定义有self.形参,则仍将该形参捆绑给了self,只是在创建实例和调用函数时都不需要声明。
- 继承:子类继承父类的方法;子类增添新属性的方法;子类修改父类函数的方法。
- 将某些针对同一属性的函数定义为一个小类,在大类中用self.变量名 = 大类名调用;在定义每个类的每个函数中都要包含self,在创建实例时不用包含self。
- 将编写的类模块化,在需要时进行调用。
1.3. 文件和异常(2020.05.31)
'''with open('ly.txt','w',encoding = 'utf-8') as f:#通过with打开文件可实现自动关闭,别忘了冒号
# f = open('ly.txt','w',encoding = 'utf-8')
# 文件句柄 'w'为创建文件,并且销毁该文件中之前的内容
data = f.write('Hello world!')# 读取文件
#f.close()
with open('ly.txt','r',encoding = 'utf-8') as f:
data = f.read()
print (data)
with open('test.txt','a',encoding = 'utf-8')as f:# a为追加文件append
# 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容
# 将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
f.write('\n阿斯达斯,\n天安门上开大会')# 写入文档,但不读
f = open('try.txt','r',encoding = 'utf-8')
for index,line in enumerate(f.readlines()):# enumerate可同时遍历索引和元素
if index == 9:
print ('---分隔符---')
continue# for循环中也可使用continue
print (index+1,line.strip())
f.close()
with open('try.txt','r',encoding = 'utf-8') as f:
print (f.tell())
print (f.readline(4))# readline(size),size表示每行读取的字符长度
print (f.tell())
f.seek(0)
print (f.readline(4))
print (f.encoding)
print (f.buffer)
print (f.fileno)
print (f.flush())
filename = 'try.txt'
with open (filename,encoding = 'utf-8') as f:
for line in f:
print (line.rstrip())# rstrip()不能消除原文的空格和换行符,而只能消除print
# 执行带来的换行符
with open ('try.txt',encoding = 'utf-8') as f:
lines = f.readlines()# readlines()将文件各行保存在列表中
print (lines)
'''
# 读取文件
# 打开文件
with open('pi_digits.txt') as f:
contents = f.read()
print (contents.rstrip())# rstrip()仅能删除一个字符串末尾的换行符
# 相对路径,注意是反斜杠(正斜杠好像也可以)
with open('dir\one.txt') as f:
# with open('.\dir\one.txt) as f:也可以
contents = f.read()
print (contents.rstrip())
# 逐行读取
name = 'pi_digits.txt'
with open(name) as f:
for line in f:
print (line.rstrip())
# 将每行存为列表
name = 'pi_digits.txt'
with open(name) as f:
lines = f.readlines()
print (lines)
for line in lines:
print (line)
# 使用文件内容
name = 'pi_digits.txt'
with open (name) as f:
lines = f.readlines()
pi_string = ''
for line in lines:
pi_string += line.strip()# 删除元素中的所有空格及所有回车
def birthday(birth):
'''检测生日是否包含在圆周率内'''
if birth in pi_string:
print ('y')
else:
print ('n')
print (pi_string)
print (len(pi_string))
print ('\n仅打印前10位:\n',pi_string[:12]+'...')
birth = input ('Enter your birthday:')
birthday(birth)
# 写入文件
# 写入空文件
name = 'programming.txt'
with open (name,'w') as f:
f.write(str(123)+'\n')# python只能操作字符型数据
f.write('asdf\n')# 写入多行需在每行末尾加\n
# 附加到文件
with open (name,'a') as f:
f.write('附加内容')
with open (name) as f:
a = f.read()
print (a)
# 异常(Traceback)
# 处理ZeroDivisionError除0错误
# try-except
try:
print (5/0)
except ZeroDivisionError:
print ('you can\'t division by zero!')
# 总结:如果仅运行print (5/0)会出现Traceback,并在下边注明原因ZeroDivisionError
# try-except-else
print ('give me two numbers, and I\'ll divide them.\nEnter "q" to quit')
while 1:
a = input('\nplease enter the first number:\n')
if a == 'q':
break
b = input('\nplease enter the second number:\n')
if b == 'q':
break
try:
answer = int(a)/int(b)
except ZeroDivisionError:
print ('you can not divide by 0.')
else:
print ('The answer is:\n',str(answer))
# 处理FileNotFoundError找不到文件
def count_words(name):
'''计算各文档中的大致单词数'''
try:
with open (name,encoding='utf-8') as f:
contents = f.read()
except FileNotFoundError:
print ('Sorry, the file %s does not exist.'%name)# pass什么也不做
else:
words_list = contents.split()
numbers = len(words_list)
print ('The file %s has about %s words.'%(name,numbers))
names = ['Alice in Wonderland.txt','Siddhartha.txt','Moby Dick.txt','Little Woman.txt']
for name in names:
count_words(name)
# 若希望发生except FileNotFoungError时什么也不做,则可使用pass语句
# 处理TypeError的方法与上边相似,具体参考元组中的例子。
# 存储数据json。json.dump写入,json.load读出
import json
numbers = [1,2,3,4,5,6]
with open ('numbers.json','w') as f:
json.dump(numbers,f)# 第一个参数是欲写入的内容,第二个参数是欲写入的文件名
with open ('numbers.json') as f:
a = json.load(f)
print (a)
#保存和读取用户生成的数据
import json
name = 'name.json'
try:
with open (name,'r') as f:
a = json.load(f)
except FileNotFoundError:
username = input('Enter your name please:\n')
with open (name,'w') as f:
json.dump(username,f)
print ('I\'ll remember you when you come back %s!'%username)
else:
print ('Welcome back %s.'%a)
重要补充:
- rstrip()仅能删除一个字符串末尾的换行符。
- strip()能删除元素的所有空格和所有换行符。
- 逐行读取,直接用for语句即可。
- python只能读写字符型数据,若要使用读取的数字,需改为整型或浮点型,需用int()、float()语句;若要将数字写入文件,需先用str()将数字改为字符型;于此有联系的是print()中只能是字符型。
- 常用的读写操作模式:‘r’只读数据;‘w’只写数据,在没有指定文件名存在时自动创建新文件,在有文件名存在时自动清空文件内容进而写入新内容;‘a’附加写入数据,不清空之前数据,其他属性和w相同;‘r+’读写模式。
文件操作的相关命令
文件操作的相关命令 - 异常(Traceback)的处理
1、try-except代码块:如果出错(try错误)了怎么办(执行except)。
2、try-except-else代码块:如果出错(try错误)了怎么办(执行except),如果不出错(try正确)了怎么办(执行else)。
总结:仅将可能出现错误的代码放入try即可,不用放入太多。 - .split()将字符串切分为单词,并将各单词存储在列表中。切分依据是空格。
- 关于打开文件的编码问题,utf-8、gbk、byte的区别,采用不同的解码方式可能会导致文件不可打开。(我在处理names中的文件是出现了编码问题。)
- json.dump(欲写入的内容,欲写入的文件名
)和json.load(欲读出的文件名)生成和读取数据。保存用户数据。