豆瓣电影分析报告:大陆和港台到底差(cha)在哪里?
Python 2.7
IDE Pycharm 5.0.3
PyExcelerator 0.6.4a
可视化 Plotly
图片要是挂了
请看这里此文备份链接
前言
在上次爬完豆瓣的东西后,感觉锻(zhuang)炼(yi)能(xia)力(bi)之外,貌似并没有实际用处,说实话,我宁可去网页一页页浏览电影也不愿意面对这苍白的文字。所以,分析一下比较好。
目的
根据豆瓣所有的电影,分析各国各地区各类别时间年份评分数量等各个参数之间的联系,大体上进行分析。我会说谎,但是数据不会。
豆瓣的电影世界
这次爬取的电影总共6323部,因为豆瓣没有全部电影的列表,所以爬取的时候按照每类进行爬取,之后整合,去重,所剩参评影片4007部。(算法略简陋,最后列表大概有十部左右未爬取,但是综合各类别包含关系,误差会变得很小)
简单介绍下情况后,根据所需要的对比数据再进行再分割的处理,这个具体代码片段详见后半部分。好了,接下来轮到plotly大显身手的时候了。
今天要分析什么?
主要比较世界电影和中国,以及中国大陆和中国港台电影之间的差别,分析各参数之间是否存在关联性及对评分产生的影响;数据来源于豆瓣,我对评分不做主观表现,我只对数据进行分析展示,能力偏弱,但图像不弱。
能从年份&评分中看出点什么?
首先放上一张堪忧的世界电影好评趋势图
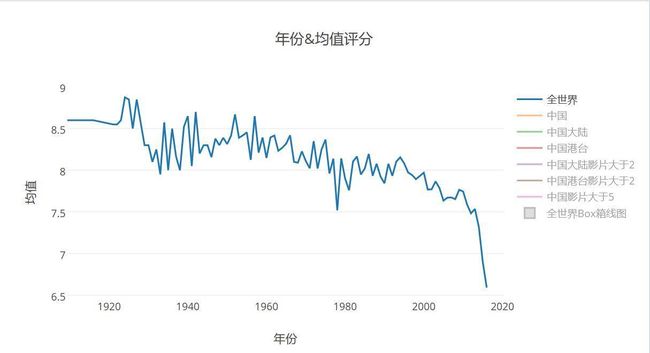
- 世界电影的评分均值趋势
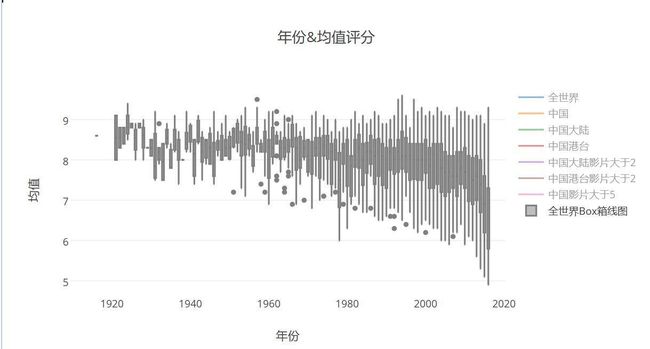
- 世界电影的评分Box箱线图趋势

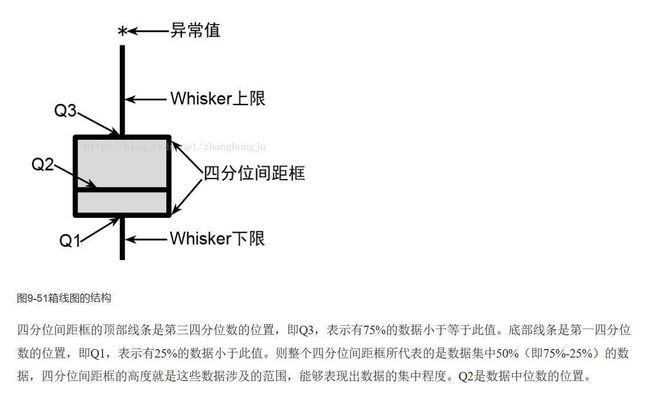
- 可以看出的是,豆瓣世界电影(简称世界电影),近些年的好评的趋势在逐年下降,特别是近两年!也就是说,在豆瓣里,近些年的低分评价越来越多,从评分均值上看,一直处于下滑状态,而且下滑曲线越来越陡,大量的烂片充斥着电影世界,导致平均分被严重拉低。另一方面,观察箱线图(箱线图的是什么意思?),从箱线图的第三四分位数(等于该样本中所有数值由小到大排列后第75%的数字)越来越低,可见,有75%的数据评分都在(约)7.3分之下;而第二四分位数,也就是中位数线也逐年向低分线靠近,对最近世界电影略微感到堪忧,难怪好片越来越少,垃圾片纵横。。。
补充箱线图概念:(@ZhangHongju–箱线图(数据分布)分析 )
世界电影趋势这样,那么中国呢?
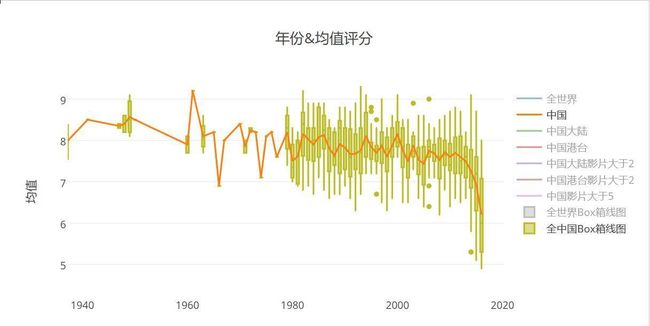
- 中国电影评分均值图趋势,红色线为均值线
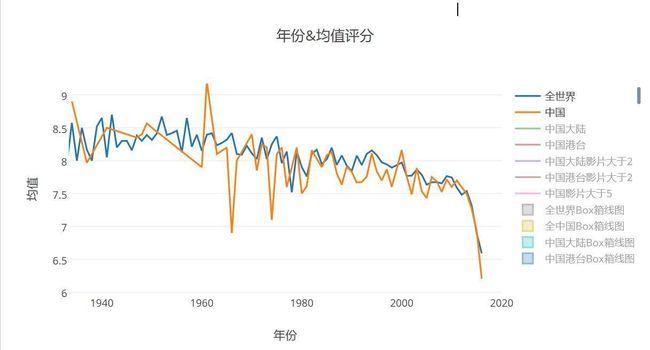
中国评分均值和全世界之间的比较
这零零散散的数据也真是少的可怜,上架豆瓣的中国电影数据量略微有点少,参评数目大概为662部左右,其中中国大陆电影为295部,中国港台为367部,趋势和世界电影的趋势差不多,也是颓废状态,但是分数更加低,大概中位数在6分以下 ,那么喜欢电影的朋友肯定知道大陆和港台电影风格还是有很大区别的,至于他们趋势分别是怎样的呢。。。
接下来看下大陆和港台的电影趋势
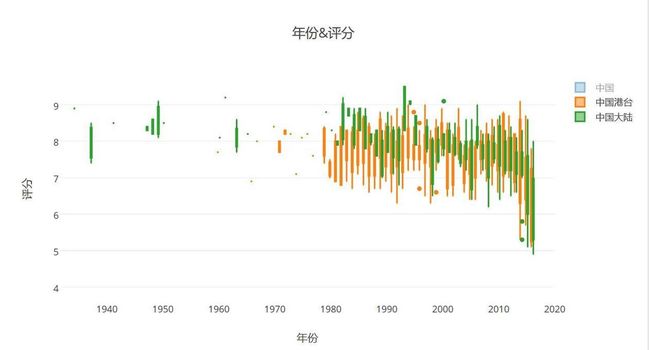
- 豆瓣中国大陆港台的box图趋势
- 整体趋势图大概是这样的,对比图形如上所示,大致维持在一个对等的水平,港台电影几乎稳定发挥,有好有坏,而大陆电影在有些年份的评分却差距非常大,为了方便,截取1980年之后的数据,使用均值线来看一下效果;
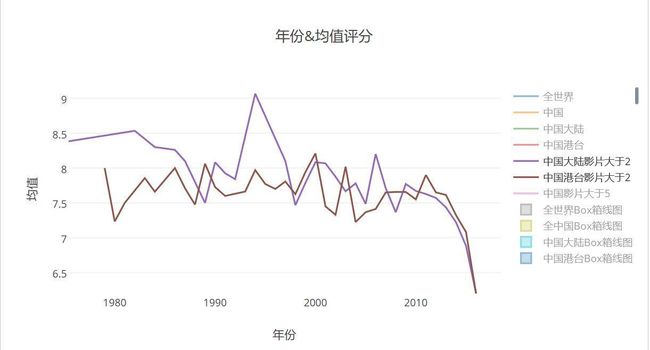
- 豆瓣中国大陆港台的评分均值图趋势
- 注:这里大于2是指取均值时候分母大于二,不然就是单个样本了,没办法,稍微协调一下,不然会抖动太明显。
把时间轴推移到二十世纪八十年代
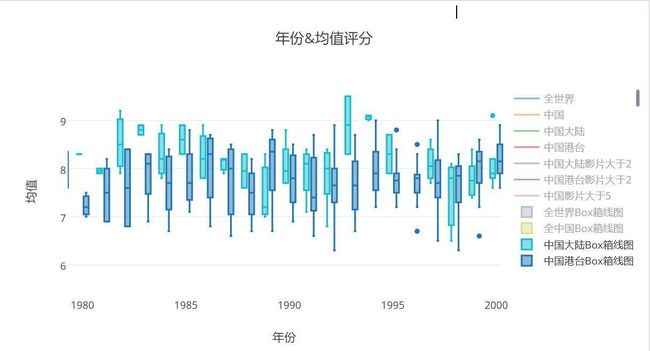
- 豆瓣中国大陆港台的box图趋势放大图1980-2000
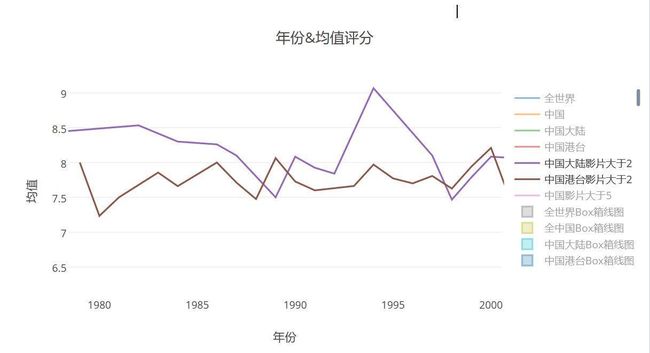
- 豆瓣中国大陆港台的均值线趋势放大图1980-2000
- 值得惊讶的是,在我的印象中,港台的电影应该会好于大陆,但是出乎我的意料,那时候的中国大陆电影评分都非常好,93,94年更是出彩,除了1989年那一年,其余的都要好于港台的水平,那时候的中国电影啊,感觉才是最繁盛的时候。
把时间轴推移到近十余年
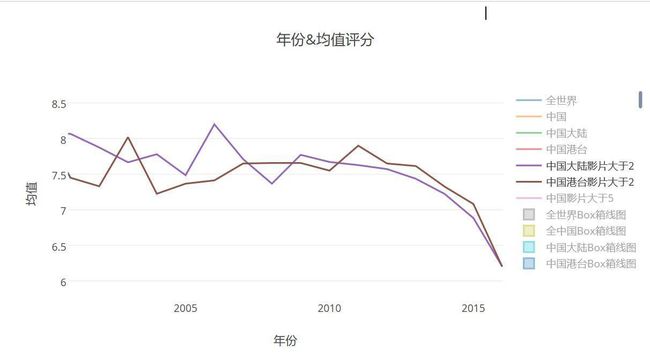
- 豆瓣中国大陆港台评分均值图趋势放大图2002-2016
- 大陆电影在2009年之后,很稳定的下滑,而港台方面则是挣扎下滑,2006年大陆方面达到一个小巅峰,但之后有严重下滑,虽然09年略有起势,但之后又开始下滑,一蹶不振的那种下滑
豆瓣中国大陆港台的box图趋势放大图2002-2016
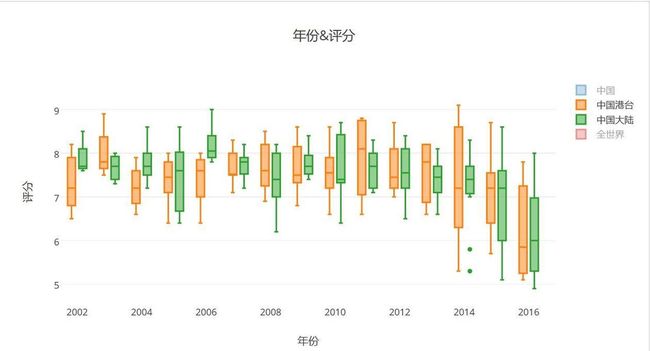
- 豆瓣中国大陆港台的box图趋势放大图2002-2016
- 在观察完均值之后,对箱线图进行观察:在2012年之前,港台和大陆电影都能保持一个比较稳定的水平,评分不算太高,但是也不低,两位并驾齐驱,虽然最高分在07年之后一直由港台电影占据,但是大陆的最高分也紧追其后。在2014年到达高峰之后,大陆和港台电影都陷入了低分的颓势当中,中位数急剧下滑,各个指数评分都下滑严重,下限也不断被刷新,这点从2014年的下限就可以看出一股烂片趋势,而在15和16年达到整体电影向烂片迁徙的状态,中位数纷纷跌破6分,而最高评分也止步于8分;我的分析能力并不是很强,但我仍然可以看出近些年来的确没有让人眼前一亮的片子了,不止是中国,全世界范围内也是大抵如此。
对比近十余年同期世界电影
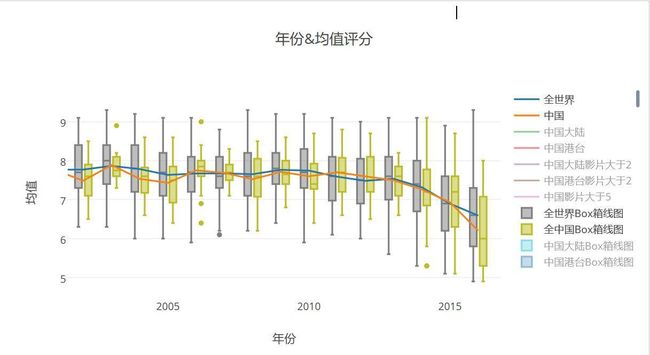
- 世界电影与中国电影均值箱线图2002-2016
- 虽然全世界电影都有颓废芝士,但是在14年之前,最低评分一直由国外保持着(08除外),但是在14年之后,最低分一直由我国负责刷新,而且第三四分位数几乎一直保持在世界平均水平之下,这点也值得我们思考。虽然世界电影有颓废趋势,但是高分电影仍然可以到达9分以上的分数,相比较于中国高分低分一块下降的局势。。。。。。
再来看一下上世纪八十年代世界其他电影进展
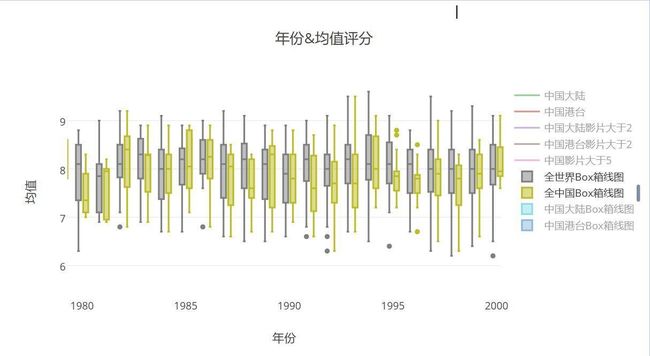
- 上世纪八十年代同期对比
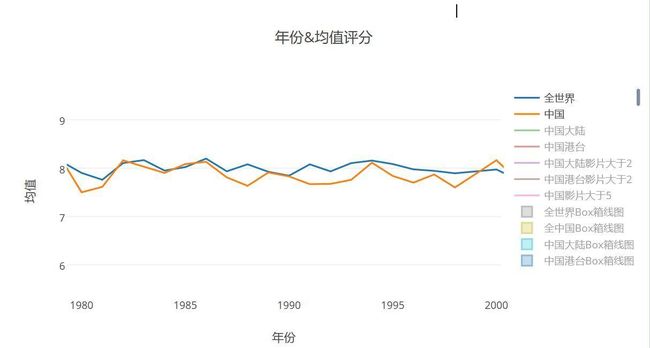
- 一句话概括这段时期:均值分始终低于世界平均水平,不好意思,我们扯着世界的蛋了。。。。
影评数和年份又有什么关系呢?
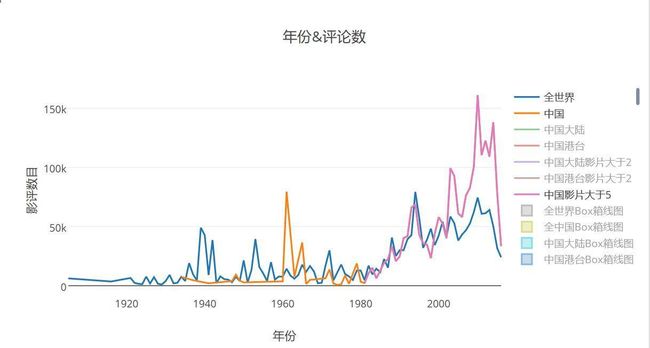
- 全世界和中国电影影评数对比
注意:这里我选取了每年电影必须大于5部的年份进行比较,不然曲线会变得太陡峭。比如橙色这根线,我没有做过处理,在1980年之后,参评电影远超5部之多,所以两线重合,但是在1980年之前,参评数目少于5部,被我切了。。
可以看出,中文的影评数在1980年一直追平世界平均水平,而在2004年之后呈上升趋势,一方面中国电影在此时刻开始数量不断上升,近两年成爆炸方式上升(难怪烂片也增加超多,评分就被相应拉低),来看看近些年电影产量:

- 中港电影产量对比:我说,国内的大导演们,能消停点拍点好片么,这两年拍的都是什么玩意啊,数量是上去了,质量呢?港台电影虽然数量没有上升,但是不骄不躁稳扎稳打啊,你看看吊车尾一溜的中国大陆。。。。。
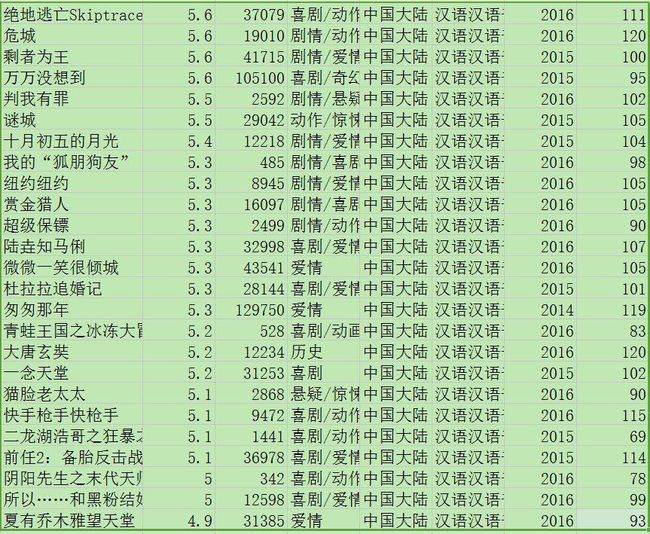
- 评分倒数几位:几乎都是15-16年拍的,全部是大陆拍的,厉害了word哥(手动再见)
所以回到上一个话题,就是电影评论数和年份的关系,一个原因就是拍的片多了,评论会相应上升,但是,这些求得都是均值,所以数量而言并不是非常重要,我!觉!得!是!烂片太多!吐槽也越发严重!!!!!但看着烂片吐槽我赶脚着还是很有意思的哈哈
补充一张图:类型和评论数的关系
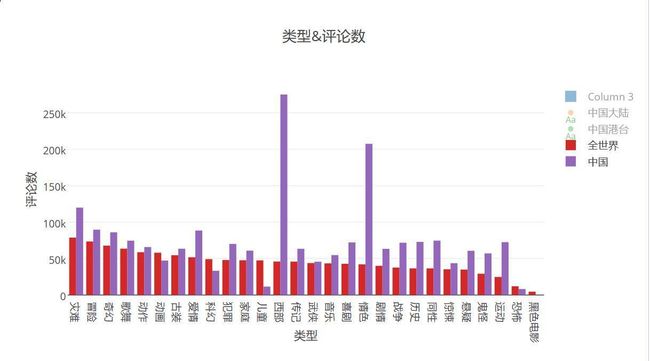
- 大家看西部电影评论数为什么那么高呢?我们来看下中国都有哪些西部电影

- 让子弹飞,无人区。。。。。哎,我还是太年轻了

脑洞1:年份和时长有没有关系呢?
- 还是看数据说话
中国大陆电影时长
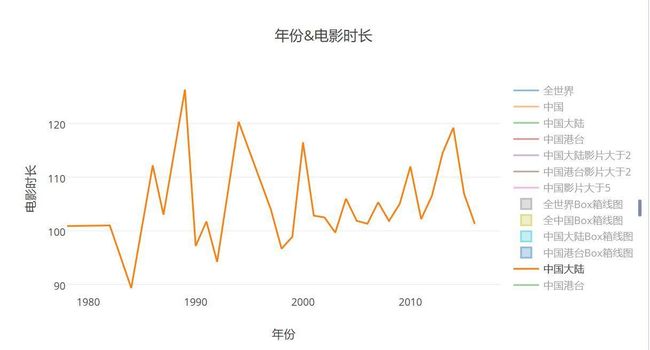
- 这个就有点意思了哈,我一直以为会保持在一个稳定的值,没想到浮动还有点剧烈(虽然也只有20分钟上下浮动)但是可以看出,时长的总体趋势是越来越长了,近些年最低的时长也超过100分钟,而且竟然有点周期性波动的意思,导演,这个是什么套路?
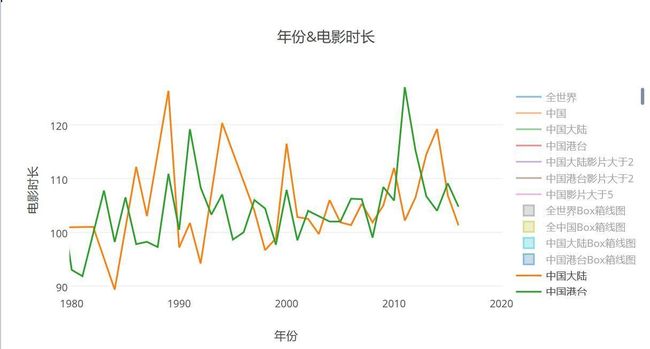
- 港台和大陆时长对比:难道玩的是同个套路?
吓得我把世界电影时长拿出来看一下
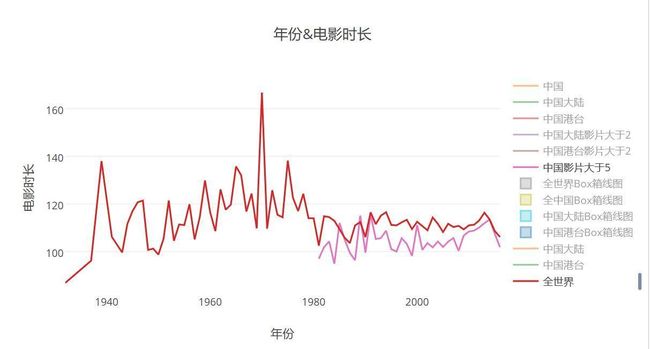
- 中国与世界电影时长对比:可以看出,国外电影时长普遍偏高,大家从电影院上映的大片也可以看出,随随便便就上120分钟了,国内的话还在追赶或者说拼凑时长来比肩世界水平,这个时候我真的想把美国的数据也拿出来,大片估计时长都会上120.。。。。
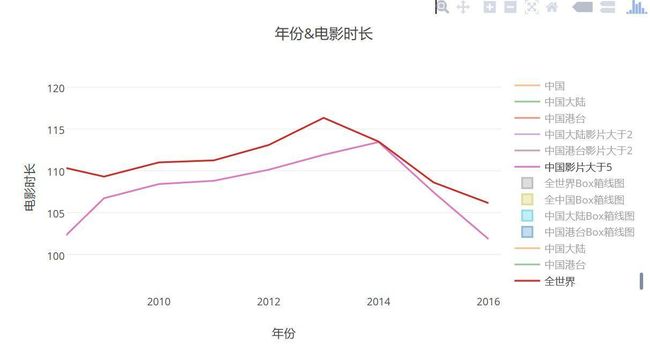
- 中国与世界电影时长对比近五年:2014年之后连续两年下降趋势,导演你又在弄啥捏~
脑洞2:时长不会和评分有关吧?
时长和评分

- 可以看出一点的是,时长很长的电影,都不会太烂,最容易踩雷区的是那种80-120分钟的,话又说回来,时间很短的电影看来分数还是会挺高的呢,低于80分钟的电影,评分竟然都高于8分,不管中国还是全世界,都是这个趋势,所以,导演们,要么浓缩精华,把电影拍精致了,或者就是用内容来填充时间,饱含内容的电影或许包罗万象,那么我们来看看,时间比较长的电影都是什么内容呢。
时长和类型探索
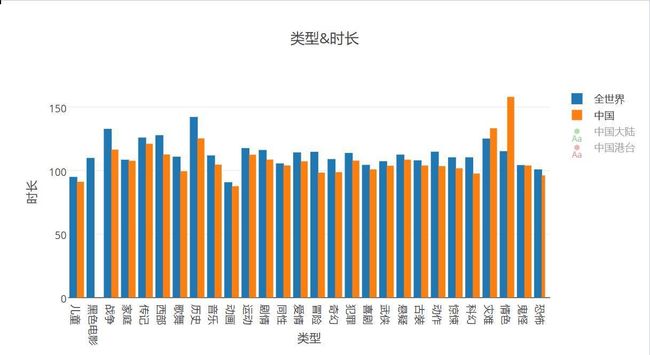
- 可以看出,几乎所有类型,中国电影的时长都在世界电影时长平均线以下,情色电影超长因为样本只有一个,没有什么好对比的,其余的都短于平均水平。BTW中国没有黑色电影。。。
- 全世界电影时长可以看出的是,历史,战争,传记,西部,灾难片类型占据时长的前五名,那这时长前五的电影评分怎么样呢,是不是有内在关联呢?
类型&评分分析
全世界类型及评分
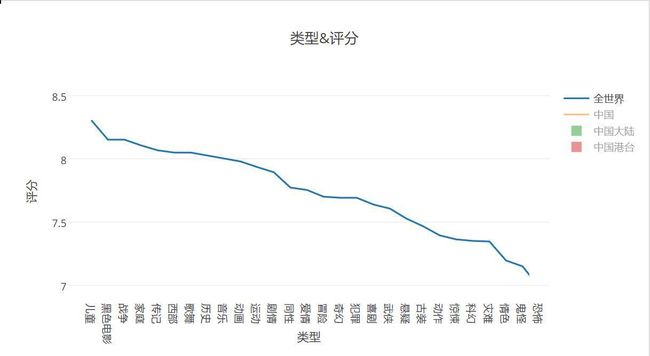
- 可以看出,儿童类型电影不仅时间很短而且评分很好呢,我们来看下什么电影贴了儿童标签
超级八Super8,6.4,27856,科幻/悬疑/惊悚/儿童,美国,英语,2011/6/10,112所以,这个标签是不是乱贴的呢,还是主演是孩子就是儿童电影呢,当然不是啦,反正我是没搞懂儿童电影和动画电影实质区别,动画电影有些并不适合儿童呢(脑补);
世界电影时长&类型&评分探索–最长时长
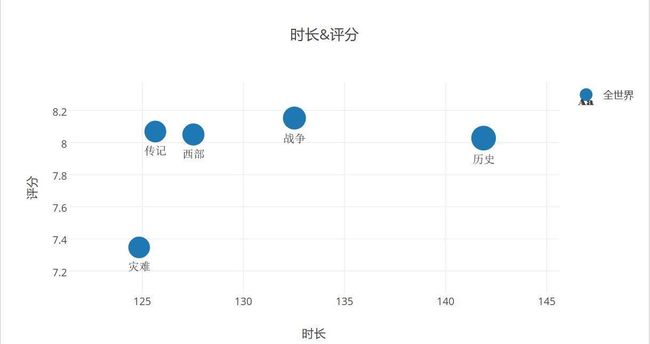
- 时长排名前五的类型:这里比较明显,时长越长,评分基本能达到很高的地步,时长排名前四的电影,评分都在8分以上,所以这几个类型可以拍的时间长一点,叙述事情可以比较清晰,细节方面可以安排较多,而灾难类型电影,不建议时长拉伸,观众们对于灾难片的认识多于特效和紧凑的剧情,所以时长的拉伸容易让观众产生疲劳,观众只是为了寻求现实生活中不会体会到的灾难刺激而去看片。压缩灾难片时长可以把成本放在特效上比较有报答率。
大陆和港台的时长&评分及类型分布–最长时长
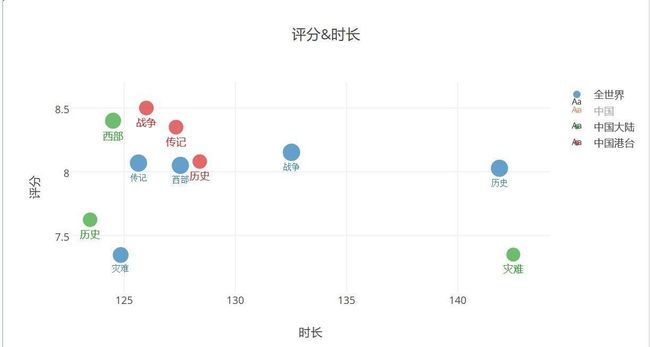
- 相比较而言,港台的趋势与世界趋势更加接近一些,大陆我估计点错时长树了。上面刚分析过,灾难片的时长需要控制一下不要太长,你刚拍就踩这个雷区,你说你分数低出了怪特效,怪演员,怪导演,怪编剧,怪龙套,怪我没给你早分析你还能怪谁!学学港台啊,把历史,传记往长了拍!喜欢看这类的估计都很耐得住性子的,他们要的是内涵!
大陆和港台的时长&评分及类型分布–时长最短
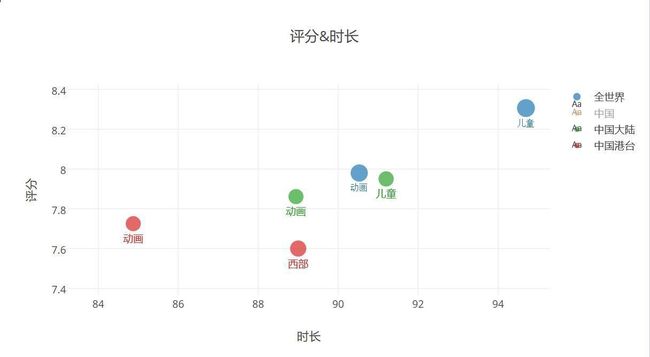
- 这个就有点有趣了,时长最低的几乎都是动画和儿童,全世界和中国的局势几乎一致,大家都认为,儿童类型电影没必要排那么多时间,把一个故事讲清楚了就可以了,而且你说儿童会有多大耐心去看一部两个多小时的电影呢。所以,这点分析出来还是挺符合现实的。
中国大陆和中国港台类型和时长
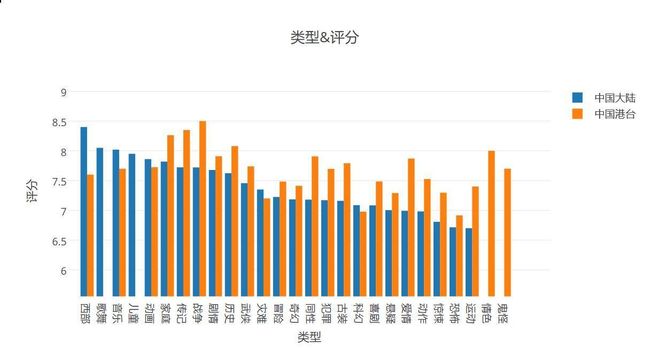
- 空白的为无此类型电影,就像大陆没有情色电影,港台没有歌舞电影一个道理。
- 可以看出的是,大陆评分前五的是西部,歌舞,音乐,儿童和动画,而港台的前几名依次是战争,传记和家庭。差距较大的电影就是大家熟悉的港台动作,惊悚,爱情都比大陆高出很多,要知道的是,这是平均分!大陆能胜于港台很少,灾难科幻,额。。。。。
时长&年份&评分炫酷看下
中国大陆时长&评分&年份三维分布
中国港台时长&评分&年份三维分布
- 我看不出啥,看着头晕,但是挺炫酷,就挂上了。不服可以过来打我啊哈哈哈
脑洞3:标签数目大家都是怎样的呢?
这个大家可能没注意,但是经过我分析(凑巧)发现,中国和世界的标签数目都是不一样的呢,差别还挺大的呢,还特么会影响评分呢!!(科幻/恐怖 这样算两个标签)
全世界的类别标签数目比例
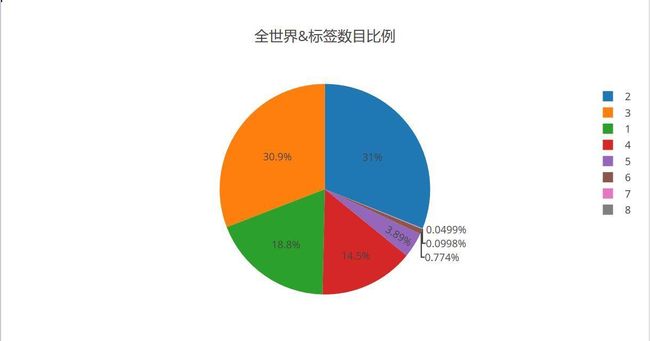
- OK,两个标签最多,三个标签其次
中国的类型标签数目比例
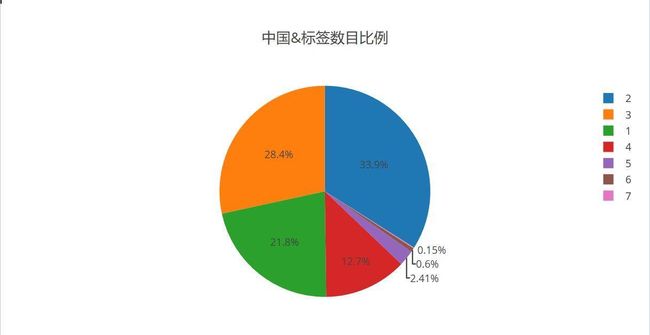
- 貌似和世界的差不多呢,排序一致,那我们来看看美国这个电影大国是怎样的
美国的类型标签数目比例
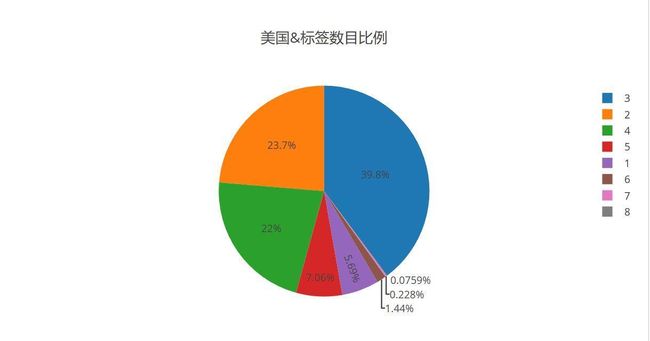
- 哇塞,是不是被震惊到了,竟然三个标签的占了第一名而且差距还那么大,别看这大概没什么影响,再给你看一幅图
类别和词频

- 这里能看出的是,美国的电影相比较于世界而言,平均每部电影所占标签数要高于全世界平均水平和远高于大陆水平,这能不能从另一个侧面反映出美国电影受欢迎的原因呢,如果说一部电影只能阐述一方面也就是一个类别,这样会不会使电影显得太单调乏味呢,而美国大片,一般电影元素中都会包含好几个主题相互映衬,并且主线依旧保持不乱,内容丰富又不缺乏主旨性,我想这点大陆电影真的可以学学。话说回来,港台电影和世界电影保持同一水平,而大陆电影却远离这条基准线,我想这和受欢迎程度应该还算有点轨迹可寻。
标签数和评分的关系
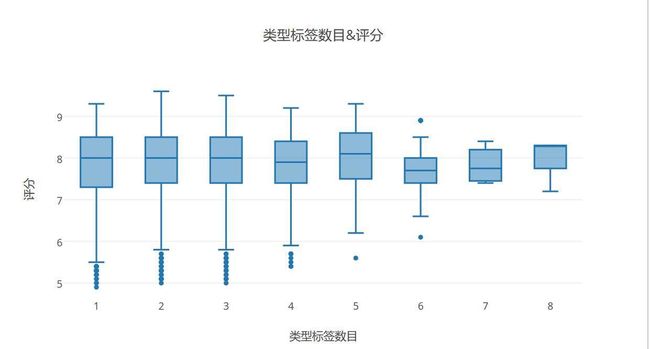
- 结论是,没啥关系,标签数越多最低分越高,但是标签数那么多的电影量太少,所以并不能作为评判标准,比如我们来看一下标签数目为8的电影的是什么奇葩玩意
![]()
末世纪爆潮 95年的科幻片,有空我得去看看集成科幻动作悬疑惊悚犯罪音乐奇幻的电影到底是个啥

接下来要分析什么?
时间间隔有点长,我脑子差不多糊了,还有什么想知道的,相分析的请留言,可能会得出很有意思结论呢,搞不好还能被大导演看到然后走上人生巅峰赢取白富美呢

福利环节
最后奉上豆瓣评分9分以上并且评论超过25万的不看就浪费生命系列电影。
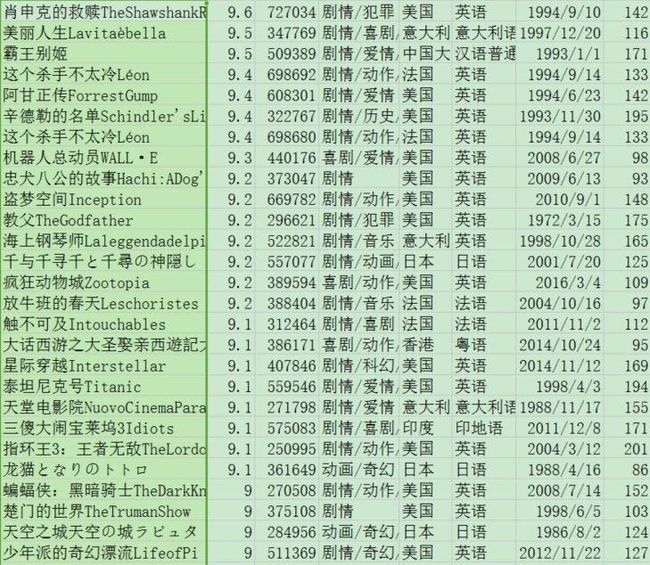
还有豆瓣评分6分以下并且有25k人忍着被侮辱的心灵写下影评,看了就浪费生命系列电影。
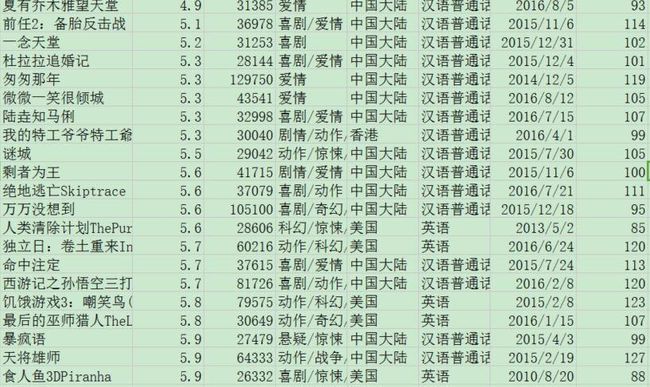
BTW-祖国总算为我们挣了口气呢~话说我赶脚独立日还是挺好看的啊0.0
好了,接下来就是程序员世界了
程序实现部分
douban_Crawl_Parts codes
代码贴了太长,需要的请下载源码下载
注意:原始代码我基本不怎么用,但是能用;对于类别的连续爬取,其实写个循环就可以了,我再爬电视剧的事后才想到,然后在之后的写入txt也好,写入excel也好,都是用了批量处理的代码,这样就不用查岗了,要知道,一个类别460部电影,即使用静态爬也爬了我25分钟,我还得看着它,爬完一类爬下一类。
内容格式:
殿下,这是利息!殿、利息でござる! 7.2 579 喜剧 日本 日语 2016-05-14 129代码格式爬取形式:
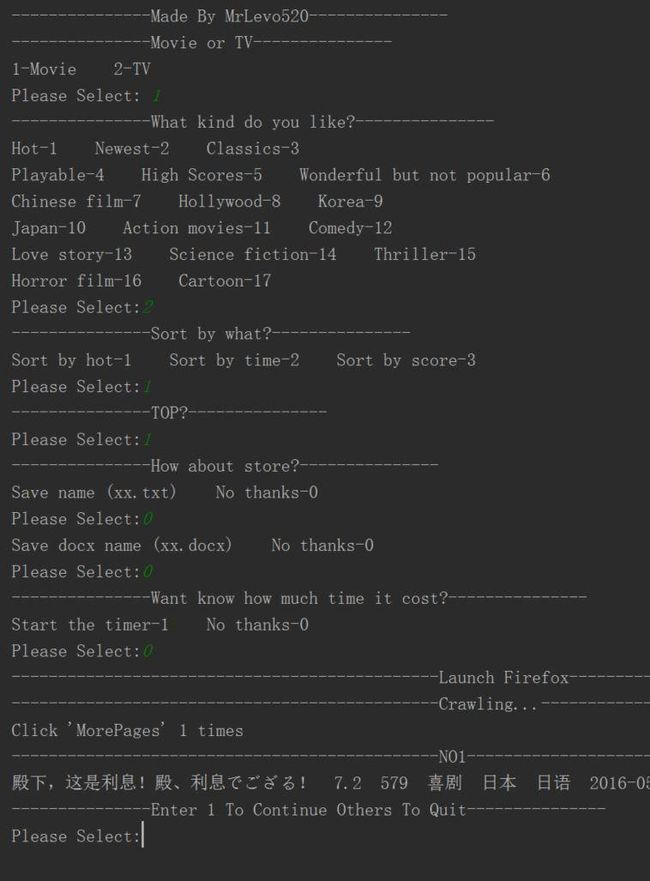
- 相较于以前版本,这次是爬名字类型评分等非动态元素,所以采用了静态方式爬取,速度加快很多。当然在页面类型的时候采用selenium的模拟点击也就是动态的爬取,这次是动态+静态的双重爬取,分工不同,请选择不同的爬取方式。
数据清洗过程
* -去重:*因为我爬十六个种类全部爬完,然后再聚合起来,其中肯定有重合部分,所以使用set函数去重,当然,你会发现,set函数也无法完全去重,因为爬的时候,评论数目还在变化,只要有一项不同,set就无法去重,结果还是excel直接去重。
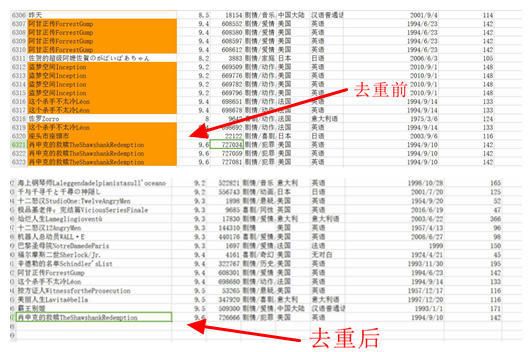
- 格式规范化:因为使用plotly展现图形,所以最好的方式就是将其写成excel的,至于怎么写,我下面有代码。
* - 缺失数据处理:*对于此类型数据,我的方法是剔除,当然我用的是最暴力的方法,剔除之后肯定不会对分析有点影响,但是这样的电影很少。比如说各种这样的电影,只要主要信息都在,我还是会爬取的,主要信息是指殿下,这是利息!殿、利息でござる! 7.2 579 喜剧 日本 日语 2016-05-14 129名字,评分,评论数,类型,国家,语言,时间,时长八个参数。

放上一个标准页面:
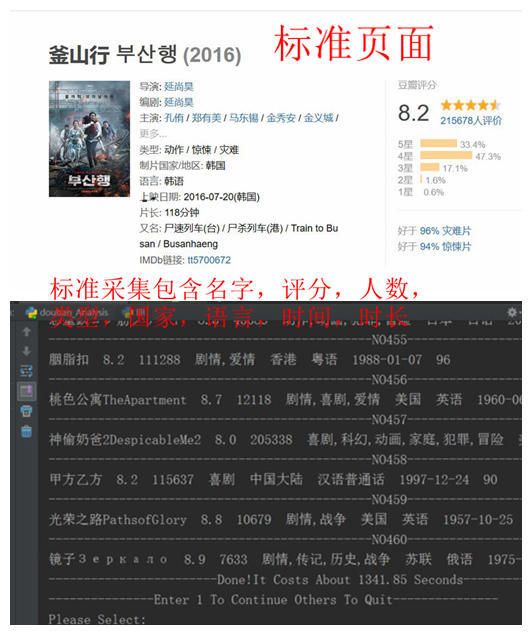
douban_Analysis_Parts codes
清洗函数
计算标签所占比例代码片
#计算总标签数,以及各类所占比例
import re
dicttype = {}
def TypeCount(line):
line = re.sub("\t",",",line)
line = line.split(",")
typeline = line[3]
typelines = typeline.split("/")
for i in typelines:
if i not in dicttype:dicttype[i]=0
dicttype[i] +=1
return dicttype
#测试的line格式,中间是tab键隔开的,制表符
#line = "诺斯费拉图Nosferatu/eineSymphoniedesGrauens 8.3 4202 恐怖/科幻 德国 德语 1922/3/4 94"
f = open("C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\ALLMovie.txt")
fr = open("C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\ALLMovie_typenum.txt","a")
k=0
lines = f.readlines()
for line in lines:
k +=1
dicttype = TypeCount(line)
x=0
for j in dicttype.values():
x +=j
print "参评影片总数:%s;所有标签总数:%s"%(k,x)
for i in dicttype:
print "%s:%s;类型所占比例:%.2f;标签词频比例:%.2f"%(i,dicttype[i],(dicttype[i])/(k*0.01),(dicttype[i])/(x*0.01))
fr.write("%s,%s,%.2f,%.2f"%(i,dicttype[i],(dicttype[i])/(k*0.01),(dicttype[i])/(x*0.01)))
fr.write('\n')最后得出如下记录,存入txt或者excel中就可以后续绘图处理了:

- 获取各类电影及分割存储码片
# 获取各个种类电影及存储分割,这里是对全部电影的切割,单独国家电影种类切割同理
def Write2txt(line,txtname):
fr = open(txtname,"a")
if line :
fr.write(line)
fr.write("\n")
fr.close()
readpath = "C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\ALLMovie.txt"
writepath = "C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\%s.txt"
typelist = ["犯罪","动作","歌舞","家庭","鬼怪","剧情","音乐","武侠","运动","战争","黑色电影","传记","历史","情色","儿童","悬疑","灾难","爱情","冒险","奇幻","科幻","古装","惊悚","恐怖","喜剧","动画","同性","西部"]
f = open(readpath)
lines = f.readlines()
for line in lines:
line = line.strip() # 记得去除空格,不然输出存在空格行
lineSplit = line.split("\t")
for type1 in typelist:
if type1 in lineSplit[3]:# 列表第四个为种类
lineCsv = line.replace("\t",",").strip()
Write2txt(lineCsv,writepath%(type1.decode('utf-8')))
- 注意:读取的txt格式必须是utf-8格式的!保存时候需要为utf-8格式,ANSI格式的会失效!
上述的式子只需要略微修改参数即可用于分类各个国家的各电影种类并单独存储,接下来是将存储在txt中的数据批量转化存储在excel中(有人会说为啥不一次性写入excel中,因为我懒啊,哈哈,其实,模块化我感觉挺好用,要不是为了能在plotly上用,我才懒得存excel)
# 以"中国大陆爱情.txt"的txt文件为例,其中存在txt中的格式为:苏州河,7.8,80931,剧情/爱情,中国大陆,汉语普通话,2000,83
from pyExcelerator import *
readpath = "C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\%s.txt"
writepath = "C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\%s.xls"
typelist = ["犯罪","动作","歌舞","家庭","鬼怪","剧情","音乐","武侠","运动","战争","黑色电影","传记","历史","情色","儿童","悬疑","灾难","爱情","冒险","奇幻","科幻","古装","惊悚","恐怖","喜剧","动画","同性","西部"]
for type1 in typelist:
try:
f = open(readpath%(u"中国大陆"+type1.decode('utf-8')))
lines = f.readlines()
w = Workbook()
sheet1 = w.add_sheet("Sheet1")
i = 0
for line in lines:
linesplist = line.split(",")
j = 0
for linesp in linesplist:
sheet1.write(i,j,linesp.strip().decode('utf-8')) # 需要转化成unicode才能存储
j += 1
i +=1
w.save(writepath%(u"中国大陆"+type1.decode('utf-8')+u"xls")) # 解码成unicode码
except:
print "No type: %s"%type1- 分割月份单独存储码片
分析评分或者类型是否与月份有关,那就有必要把月份单独提出出来了,随便修改个程序,同样批处理。
# 分割月份单独存储
def Write2txt(line,txtname):
fr = open(txtname,"a")
if line :
fr.write(line)
fr.write("\n")
fr.close()
readpath = "C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\AllOverTheWorld_alltype_splite\\%s.txt"
writepath = "C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\AllOverTheWorld_alltype_splite\\%s.txt"
typelist = ["犯罪","动作","歌舞","家庭","鬼怪","剧情","音乐","武侠","运动","战争","黑色电影","传记","历史","情色","儿童","悬疑","灾难","爱情","冒险","奇幻","科幻","古装","惊悚","恐怖","喜剧","动画","同性","西部"]
for typelist1 in typelist:
try:
f = open(readpath%(u"港台"+typelist1.decode('utf-8')))
lines = f.readlines()
for line in lines:
line = line.strip() # 记得去除空格,不然输出存在空格行
lineSplit = line.split(",")
try:
newline ="%s,%s,%s,%s,%s,%s"%(lineSplit[1],lineSplit[2],lineSplit[4],lineSplit[5],lineSplit[6].split("/")[1],lineSplit[7])
Write2txt(newline,writepath%(u"港台"+typelist1.decode('utf-8')+u"OnlyMonth"))
except:
print "Only year No month:%s"%lineSplit[0]
except:
print "No Type :%s"%typelist1对照一下,粗略看一下有没有处理正确,ok,没什么错误。
- 计算评分,评论数,时长等均值并存储excel的代码片段
# 计算不同年份的评分,评论数,时长平均值并存储excel
from pyExcelerator import *
def Write2txt(line,txtname):
fr = open(txtname,"a")
if line :
fr.write(line)
fr.write("\n")
fr.close()
def txt2excel():
try:
f = open("C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\ChinaAllmovieOnlyYearWithAverage.txt")
lines = f.readlines()
w = Workbook()
sheet1 = w.add_sheet("Sheet1")
i = 0
for line in lines:
linesplist = line.split(",")
j = 0
for linesp in linesplist:
sheet1.write(i,j,linesp.strip().decode('utf-8')) # 需要转化成unicode才能存储
j += 1
i +=1
w.save("C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\ChinaAllmovieOnlyYearWithAverage.xls") # 解码成unicode码
except:
print "Something wrong"
path = "C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\ChinaAllmovieOnlyYear.txt"
lines = open(path).readlines()
for years in range(1900,2017):
TotalStar,TotalComment,TotalTime,i = 0.0,0.0,0.0,0.0
for line in lines:
lineSplit = line.split("\t")
if lineSplit[6] == str(years):
TotalStar +=float(lineSplit[1])
TotalComment +=float(lineSplit[2])
TotalTime +=float(lineSplit[7])
i +=1
try:
if i>4: # 设置影片数目阈值
print "%s:Average star %s"%(years,TotalStar/i)
print "%s:Average comment %s"%(years,TotalComment/i)
print "%s:Average time %s"%(years,TotalTime/i)
print "%s: movieNum %s"%(years,i)
writeline = "%s,%s,%s,%s,%s"%(years,i,TotalStar/i,TotalComment/i,TotalTime/i)
Write2txt(writeline,"C:\\Users\\MrLevo\\PycharmProjects\\test\\M&TCleanData\\ChinaAllmovieOnlyYearWithAverage.txt")
txt2excel()
except:
print "No movie this year %s"%years之后效果应该是这样的
1981:Average star 7.6125
1981:Average comment 2312.25
1981:Average time 97.0
1981:movieNum 8.0
...最后
总结这一次的小项目, 经历了数据的收集爬取-数据的清洗规范-数据存储-数据可视化-数据分析,虽然对大神来说非常浅显而没有太多价值,但这也是我这种菜鸡必须需要经历的一步,完完整整,虽有各种波折,所幸全部解决,从中也学到很多,以后编代码思考也会成熟,共勉各位。
撰写记录
- 2016.10.2-19:49-第一次撰写
- 2016.10.4-21:12-第二次撰写
- 2016.10.5-11:21-第三次撰写
- 2016.10.7-22:21-第四次撰写
- 2016.10.10-18:10-第五次撰写
备用链接
防止辛辛苦苦做的50多张图片挂了,这里是备用链接(大)数据分析:豆瓣电影分析报告【1】
致谢
python对excel的读取操作
@MrLevo520–Python自定义豆瓣电影种类,排行,点评的爬取与存储(基础)
@MrLevo520–Python自定义豆瓣电影种类,排行,点评的爬取与存储(初级)
@MrLevo520–Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶上)
@MrLevo520–Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶下)
@MrLevo520–Python自定义豆瓣电影种类,排行,点评的爬取与存储(高阶上)