Python爬取豆瓣电影信息并分析
Python爬取豆瓣电影信息并分析
一个数据分析的作业0.0
不知道怎么爬取豆瓣所有的电影信息,所以只能从一些榜单中爬取,如果是所有电影,效果应该会好很多。。。
爬取豆瓣高分电影榜电影信息并分析
榜单上
榜单中
榜单下
总共784部电影
一、爬取豆瓣高分电影
1.先查看网页源代码
找到存放电影信息的代码:
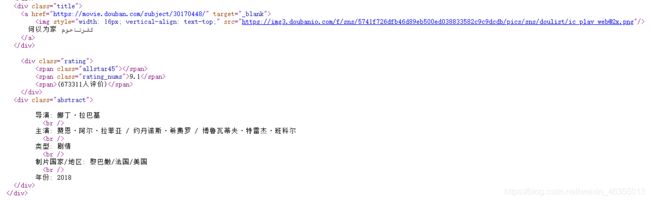
class=‘title’的div标签文本中存放着电影名称
class=‘rating’的div标签中存放着星级,评分和评价人数
class=‘abstract’的div标签中存放着导演,主演,类型,制片国家/地区和年份的信息
根据上述获得的信息即可进行爬虫
2.编写代码
使用requests库获取页面信息,使用BeautifulSoup解析获取的html代码,当然也可以直接用正则表达式解析html代码
定义get_movies()方法,返回电影的名字,类型,评论人数,评分,制片国家/地区,主演,导演,年份的7个列表
其中年份按照几几年划分到xx世纪xx年代
import re
import requests
from bs4 import BeautifulSoup
import pandas as pd
def get_movies(link):
headers = {
# 这是请求头
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/83.0.4103.116 Safari/537.36 '
}
movie_names=[]
movie_types=[]
movie_dis=[]
movie_grade=[]
movie_addr=[]
movie_actor=[]
movie_director=[]
movie_year=[]
r=requests.get(link,headers=headers,timeout=10)
soup=BeautifulSoup(r.text,"lxml")
for each in soup.find_all('div',class_='abstract'):
a=each.text
#.匹配任意字符,除了换行符
tp = re.search(r'类型: (.*)',a)
if tp==None:
movie_types.append(" ")
else:
movie_types.append(tp.group(1))
actor = re.search(r'主演: (.*)',a)
if actor==None:
movie_actor.append(" ")
else:
movie_actor.append(actor.group(1))
director = re.search(r'导演: (.*)',a)
if director==None:
movie_director.append(" ")
else:
movie_director.append(director.group(1))
addr = re.search(r'制片国家/地区: (.*)',a)
if addr==None:
movie_addr.append(" ")
else:
movie_addr.append(addr.group(1))
year=re.search(r'年份: (.*)',a)
if year==None:
movie_year.append(" ")
else:
year_str=year.group(1)
sj=int(year_str[:2])+1
nd=year_str[2]+'0'
movie_year.append(str(sj)+'世纪'+nd+'年代')
#查询所有class=title的div
div_list=soup.find_all('div',class_='title')
for each in div_list:
movie_name=each.a.text.strip() # 在div中,a标签的text的内容就是中文电影名称
movie_names.append(movie_name)
for each in soup.find_all('div',class_='rating'):
a=each.text.split('\n') #在div中,第三个span的text的内容就是评价人数
#获取字符串中的数字
x=re.sub("\D","",a[3])
movie_dis.append(int(x))
movie_grade.append(float(a[2]))
return movie_names,movie_types,movie_dis,movie_grade,movie_addr,movie_actor,movie_director,movie_year
用for 循环读取每页的数据并写入dataframe
movies=get_movies("https://www.douban.com/doulist/240962/")
movies_1=pd.DataFrame({
'电影名称':movies[0],'电影类型':movies[1],'导演':movies[6],'主演':movies[5],'评价人数':movies[2],'评分':movies[3],'国家/地区':movies[4],'年代':movies[7]})
for i in range(1,18):
#总共18页,一页25个
link="https://www.douban.com/doulist/240962/?start="+str(i*25)
movies=get_movies(link)
movies_1=movies_1.append(pd.DataFrame({
'电影名称':movies[0],'电影类型':movies[1],'导演':movies[6],'主演':movies[5],'评价人数':movies[2],'评分':movies[3],'国家/地区':movies[4],'年代':movies[7]}),ignore_index=True)
all_movies=movies_1
总共读取三个网页的电影信息,操作类似
整合所有数据后的到

二、数据分析
首先把年份的列名改成year
data.rename(columns={
'年代':'year'},inplace=True)
统计每个年代上榜影片数量,并用plotly绘制柱状图
plotly官方教程
首先要导入相关库
import plotly.express as px
import plotly.graph_objects as go
n=data.groupby('year').count()
x=list(n.index)
y=list(n['评分'])
fig = go.Figure()
fig.add_trace(go.Bar(
x=x,
y=y,
))
plotly可以用以下方法下载图片
import plotly.io as pio
pio.write_image(fig, '1.png')
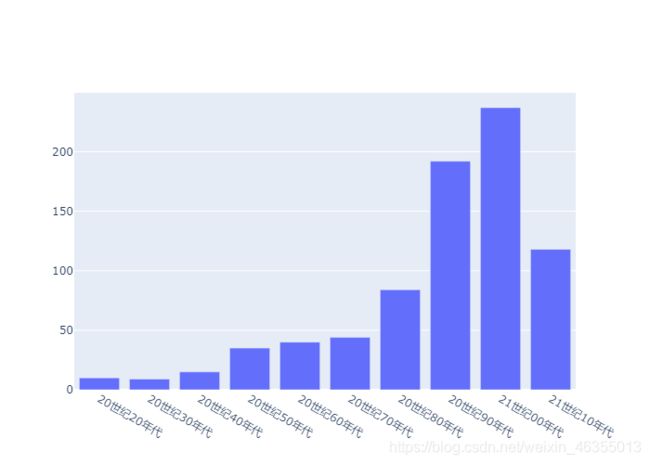
评分和评价人数
这里需要标准化数据,使他们落在一个区间
x=data.groupby('year')['评价人数','评分'].mean()
s=(x-x.mean())/x.std()
fig = px.line(s)
fig.show()
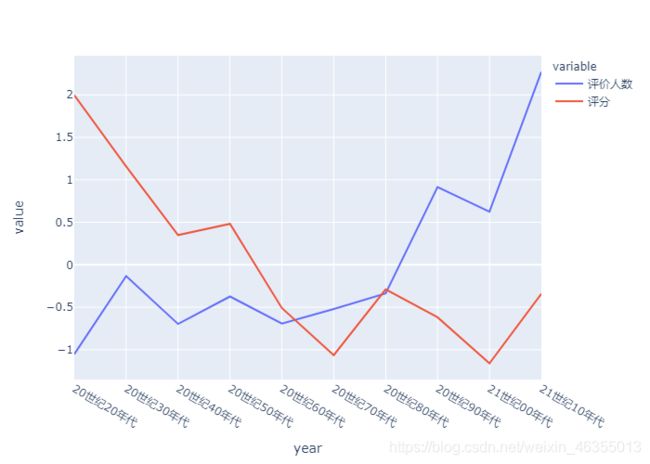
20世纪早期的电影观看人数较少,但评分普遍较高,了20世纪中期之后的电影观看人数开始增加,但评分却略显平庸,到了本世纪,评分才有了上涨的趋势。
统计所有上榜电影类型
首先将电影类型按照 ‘/’ 分割,并去空格,转化成list 的目的是使用collections.Counter
先导入
from collections import Counter
types=data['电影类型'].str.split('/')
l=[]
tl=[]
for i in range(783):
l.extend(types[i])
for i in l:
tl.append(i.strip())
c = Counter(tl)
k=list(c.keys())
v=list(c.values())
count=pd.DataFrame({
'type':k,'c':v})
count.sort_values(by='c')
total=count
绘制饼图
fig = px.pie(total, values='c', names='type')
fig.show()
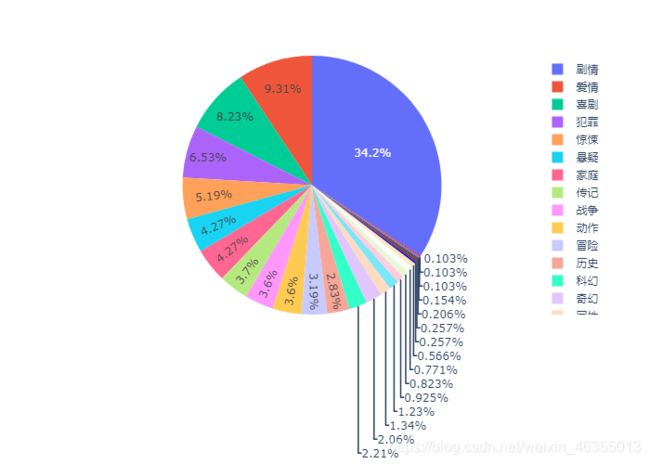
剧情这一类型涵盖的方面实在是太广了,所以剧情占大头,其次就是爱情和喜剧了。
每个年代电影类型占比的统计
用以下方法筛选出每个年代的电影
data_y=data[data.year==year]
再按照之前的方法进行统计
并计算出每个年代各个类型出现的概率,画出柱状图
其中x是所有电影类型的列表
y是该年代各个电影类型的占比
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Bar(
x=k,
y=get_ep(l20_20,k),
name='20世纪20年代',
))
fig.add_trace(go.Bar(
x=k,
y=get_ep(l20_30,k),
name='20世纪30年代',
))
fig.add_trace(go.Bar(
x=k,
y=get_ep(l20_40,k),
name='20世纪40年代',
))
fig.add_trace(go.Bar(
x=k,
y=get_ep(l20_50,k),
name='20世纪50年代',
))
fig.add_trace(go.Bar(
x=k,
y=get_ep(l20_60,k),
name='20世纪60年代',
))
fig.add_trace(go.Bar(
x=k,
y=get_ep(l20_70,k),
name='20世纪70年代',
))
fig.add_trace(go.Bar(
x=k,
y=get_ep(l20_80,k),
name='20世纪80年代',
))
fig.add_trace(go.Bar(
x=k,
y=get_ep(l20_90,k),
name='20世纪90年代',
))
fig.add_trace(go.Bar(
x=k,
y=get_ep(l21_00,k),
name='21世纪00年代',
))
fig.add_trace(go.Bar(
x=k,
y=get_ep(l21_10,k),
name='21世纪10年代',
))
fig.show()
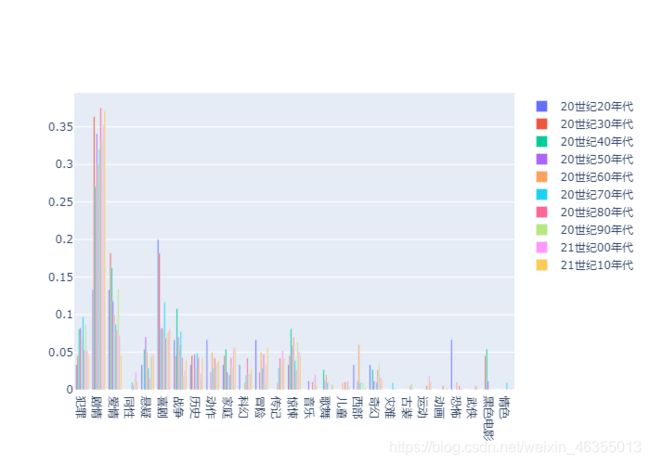
可以详细查看其中占比较多的几类
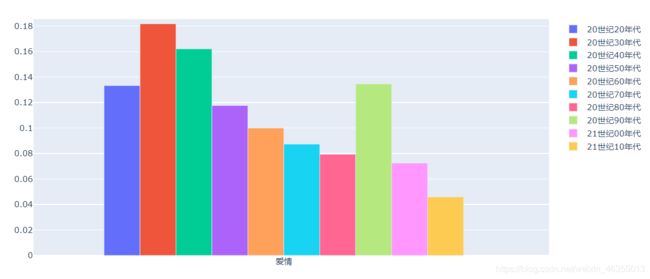
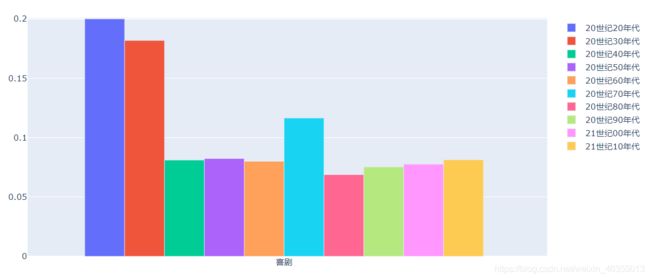
可以看出最近几十年来并没有很多的爱情和喜剧电影上榜
总体来看家庭和战争类的高分电影出现的概率有上升的趋势
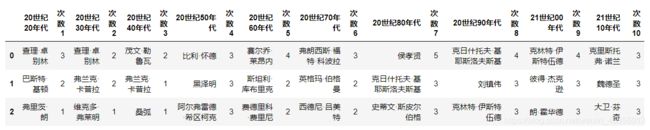
每个年代上榜次数前三的演员
用相似的方法统计演员出现的次数,并按年代划分
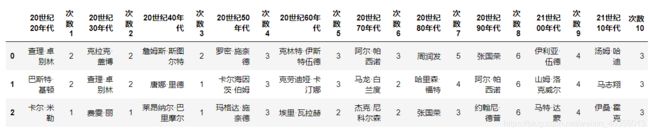
总次数上榜前三的演员

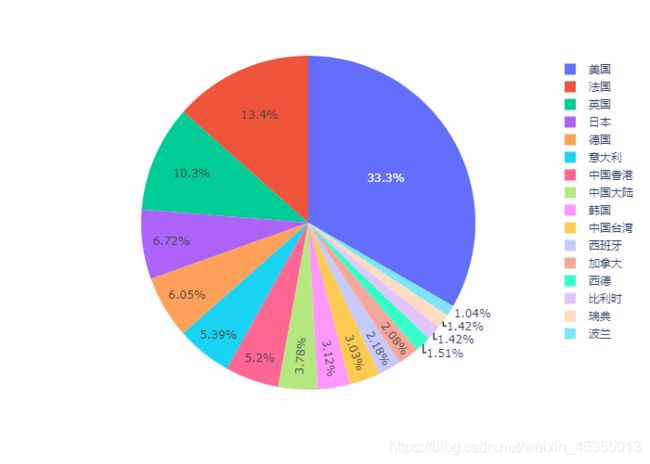
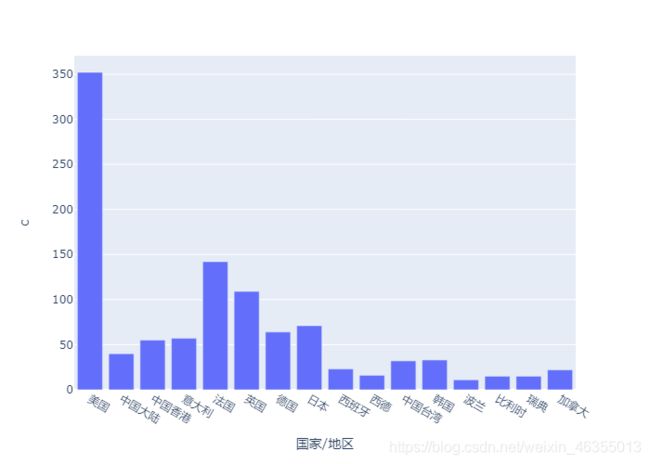
上榜电影数大于10部的国家和地区

并画出饼图和柱状图
每个年代上榜次数前三的导演