JVM-G1垃圾回收器:G1回收流程(Rset、CSet、SATB)
JVM-G1垃圾回收器:G1回收流程(Rset、CSet、SATB)
- G1垃圾回收的周期
- App Thread (用户线程)
- Concurrence Refinement Thread(同步优化线程)
- RSet(Remember Set :记忆集合)
- CSet(Collection Set 回收集合)
- SATB(Snapshot At the Begging)
-
- SATB + RSet 解决了什么问题?
- YoungGC 的工作流程
- MixGC 的工作流程
- 转移失败的担保机制 Full GC
- 总结一下
G1垃圾回收器总体来说,分为两种回收方式:第一种就是:YoungGC 对年轻代Region的回收,第二种就是MixGC。这种分代思想是垃圾回收器一直使用的。这种方式,让垃圾回收器只关注要回收的区域,降低程序的回收暂停时间。
G1垃圾回收的周期

从上图,我们可以看出来。G1垃圾回收器的垃圾回收方式分为两种。一就是YoungGC,主要回收的是年轻代Region中的垃圾。第二种就是混合回收模式(Mix GC),这种回收模式会回收年轻代跟老年代中的所有垃圾。根据上图,我们接下来就详细讲解一下垃圾回收周期中的各个流程的详细内容。
首先我们要知道的是G1垃圾回收器的算法是标记-整理算法,通过回收一个个Region(上一章我们讲到过的G1内存模型),来充分减少标记-整理算法上的内存浪费的缺点。
然后我们科普几个名词解释
App Thread (用户线程)
这个很简单,App thread 就是执行一个java程序的业务逻辑,实际运行的一些线程。
Concurrence Refinement Thread(同步优化线程)
这个线程主要用来处理代间引用之间的关系用的。当赋值语句发生后,G1通过Writer Barrier技术,跟G1自己的筛选算法,筛选出此次索引赋值是否是跨区(Region)之间的引用。如果是跨区索引赋值,在线程的内存缓冲区写一条log,一旦日志缓冲区写满,就重新起一块缓冲重新写,而原有的缓冲区则进入全局缓冲区。Concurrence Refinement Thread 扫描全局缓冲区的日志,根据日志更新各个区(Region)的RSet。这块逻辑跟后面讲到的SATB技术十分相似,但又不同SATB技术主要更新的是存活对象的位图。
Concurrence Refinement Thread(同步优化线程) 可通过 -XX:G1ConcRefinementThreads (默认等于-XX:ParellelGCThreads)设置。如果发现全局缓冲区日志积累较多,G1会调用更多的线程来出来缓冲区日志,甚至会调用App Thread 来处理,造成应用任务堵塞,所以必须要尽量避免这样的现象出现。可以通过阈值-X:G1ConcRefinementGreenZone/-XX:G1ConcRefinementYellowZone/-XX:G1ConcRefinementRedZone 这三个参数来设置G1调用线程的数量来处理全局缓存的积累的日志。
RSet(Remember Set :记忆集合)
每一个Region都会划出一部分内存用来储存记录其他Region对当前持有Rset Region中Card的引用,这个记录就叫做Remember Set。我们可以看看以下的分区模型图:

G1垃圾回收器,有对STW时间的控制,通过参数 -XX:MaxGCPauseMillis 来设置,而对于整个堆进行一次回收所需要的的实际STW时间可能远远超过这个值,所以G1可以不用扫描整个堆,只要通过扫描RSet来分析垃圾比例最高的Region区,放入CSet(Collection Set :回收集合)中,进行回收。
Rset的储存方状态,会根据对当前区域中引用数量的增加依次递增,分别为:稀疏(hash)->细粒度->粗粒度。
稀疏状态: 一个其他Region引用当前Region 中Card 的集合 被放在一个数组里面,Key:redion地址 Value:card 地址数组
细粒度: 一个Region地址链表,共同维护当前 Region 中所有card 的一个BitMap集合,该card 被引用了就设置对应bit 为1,并且还维护一个 对应Region对当前Region中card 索引数量
粗粒度: 所有region 形成一个 bitMap,如果有region 对当前 Region 有指针指向,就设置其对应的bit 为1
加入一条索引的源码的工作流程图如下:

我们发现如果有Rset的数据结构退化成了粗粒度的时候,要对Region进行回收的时候,就必须对Region进行全扫描才能正确回收,这样就大大增大了G1垃圾回收器的工作量,降低了效率。
其次为了追求效率一般Young代Region不会有RSet,因为维护Rset需要消耗不少性能,而年轻代快速回收的特性,带来了大量的浪费
有兴趣的同学可以去下载OpenJdk源码: https://hg.openjdk.java.net/jdk/jdk12,也可以看如下博客:https://blog.csdn.net/a860MHz/article/details/97276211
CSet(Collection Set 回收集合)
收集集合(CSet)代表每次GC暂停时回收的一系列目标分区。在任意一次收集暂停中,CSet所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。因此无论是年轻代收集,还是混合收集,工作的机制都是一致的。年轻代收集CSet只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到CSet中。
CSet根据两种不同的回收类型分为两种不同CSet。
1.CSet of Young Collection
2.CSet of Mix Collection
CSet of Young Collection 只专注回收 Young Region 跟 Survivor Region ,而CSet of Mix Collection 模式下的CSet 则会通过RSet计算Region中对象的活跃度,活跃度阈值-XX:G1MixedGCLiveThresholdPercent(默认85%),只有活跃度高于这个阈值的才会准入CSet,混合模式下CSet还可以通过XX:G1OldCSetRegionThresholdPercent(默认10%)设置,CSet跟整个堆的比例的数量上限。
SATB(Snapshot At the Begging)
SATB,也可以称为对象快照技术,在GC之前对整个堆进行一次对象索引关系,形成位图,相当于堆的逻辑快照。在并并发回收过程中,通过增量的方式维护这个对象位图。
-
SATB解决了什么问题?
主要是为了解决并发标记过程中,出现的漏标,误标等问题。 -
什么是漏标,误标。
在并发标记过程中,APP线程跟GC线程同时进行,GC线程扫描的时候发现一个对象位垃圾对象,不对他进行标记,而APP线程马上就会操作索引指向这个对象。那么在垃圾回收的时候这样漏标的对象被回收就会产生灾难性的后果。也有的情况就是,在GC标记完一个对象不需要回收之后,APP线程之后就会把所有指向这个对象的索引完全去除,那么这就是一个垃圾对象,然而在回收过程之中并没有回收,造成了浮动垃圾,这种情况就是误标。 -
漏标、误标的解决方案。
解决漏标误标,就必须了解两个名词。第一个名词:三色标记法,第二个名词:writer barrier(写栅栏)
首先解释第一个名词:三色标记算法
首先我们知道无论是 g1还是CMS垃圾标记算法都叫做根可达(root searching),首先搜索比如 线程栈上的对象、静态变量、常量池中的对象以及jni指针,这个部分往往发生是G1的初始标记阶段,会进行STW。然后就进入了并发标记阶段。首先我们定义:扫描过当前对象以及其子索引对象的为不可回收的对象位黑色对象,有黑色父对象索引指向的,并且未扫描其子索引的对象为灰色对象,需要回收的对象:为白色对象。
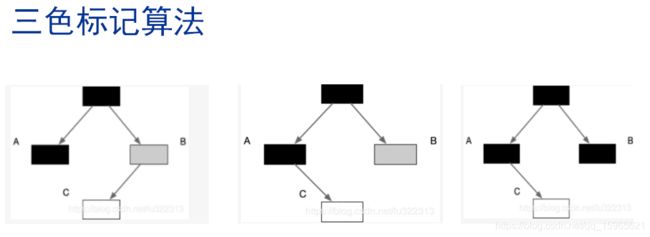
第二个名词:写栅栏:write barrier
当上图中 B->C 改变成 A->C 的索引,垃圾回收器是如何感知的?就是通过writer barrier技术,其实就相当于一个钩子程序,但执行索引改变的时候,触发一下write barrier,然后write barrier根据相应的需求增加一条索引更改的日志。每个App现场都会有一个LTB(local thread buffer)当一个LTB缓冲区写满之后,就新起一个缓冲区,把原来的缓冲区写入全局缓冲中,又相应的垃圾回收线程去更新SATB 的对象快照图。
SATB + RSet 解决了什么问题?
上面说了三色标记算法,为了解决漏标问题提出了一个writeBarrier的解决方案。但是还是有一种情况的漏标是writeBarrier解决不了的。就是在并发的情况下,当一个线程扫描对象A,对象A有索引:A->B,A->C,其中线程T1,扫描完B在扫描C的状态中,此时有个线程T2把索引B改动,改成A->D,把A设置为灰色,此时T1把C扫描完了,把A设置为黑色。这时我们就发现黑色对象A,下面就会有一个白色对象D未扫描。那么这样的漏标如何解决?
SATB位图构建过程中,所有有索引改动的对象,如上面所说的D跟B,就放入一个队列中。当Remark阶段,扫描这个队列里面的所有对象,重新标记。但是重新标记,按照道理来说,我们又需要扫描整个堆,但是我们其实只想回收某一个Region,又去扫描整个堆效率上来说肯定是不行的。这个时候,我们就可以去扫描Region中的RSet,如果RSet 没有记录其他Region对这个对象的索引,自己内部也没有,那么这个对象就是一个可回收的垃圾对象。
CMS中通过incremental update解决了部分漏标问题,但是像这样并发情况的下的漏标是不能解决的。所以为了解决可能存在的漏标问题,也是通过WriterBarrier,将A这样有改变过索引的对象放入一个堆栈中,在AbortPreClean、Remark阶段重新扫描一次这些对象。
YoungGC 的工作流程
YGC 的工作流程很简单:APP线程跑,然后就进行青年代Region的回收,把需要回收的YoungRegion,放入YoungCSet中,在YGC阶段就进行对年轻代CSet中的Region进行回收。因为大部分都是垃圾,且用了复制回收算法,基本只需要较短时间的STW就能完全回收了。
MixGC 的工作流程
当老年代垃圾达到一个阀值的时候,就会触发MixGC,就像第一幅图IPOH所标识的那样。阈值-XX:InitiatingHeapOccupancyPercent(默认45%)时,G1就会启动一次混合垃圾收集周期。在经过第一次YGC的同时,进行Init Mark,然后再后面几次YGC的整个过程中进行进行ConcurrentMark,并把需要收集的Region放入CSet当中。然后进行一次STW的时候,ReMark(重新标记,主要是扫描堆栈上新的对象的索引),并且进行Clean(主要的任务是直接清理没有用的大对象Region,也叫做HumongousRegion),然后就开始分步清理CSet中的Region,根据ReSet中计算出垃圾比率较高的Region开始清理。这一系列循环收集的过程称为混合收集周期(Mixed Collection Cycle)。
转移失败的担保机制 Full GC
我们看到第一幅回收流程图的过程,进行MixGC的同时也在并发的进行APP线程,产生了新的垃圾,如果这个时候发生了新产生的对象进入老年代Region,而堆空间不够的时候就会发生转移失败(Evacuation Failure),此时G1便会触发担保机制,执行一次STW式的、单线程的Full GC。Full GC会对整堆做标记清除和压缩,最后将只包含纯粹的存活对象。但是有一个参数-XX:G1ReservePercent(默认10%)可以保留空间,来应对晋升模式下的异常情况,最大占用整堆50%,但是太大了一般会浪费空间,也没有太大的意义。
G1在以下场景中会触发Full GC,同时会在日志中记录to-space-exhausted以及Evacuation Failure:
- 从年轻代分区拷贝存活对象时,无法找到可用的空闲分区
- 从老年代分区转移存活对象时,无法找到可用的空闲分区
- 分配巨型对象时在老年代无法找到足够的连续分区
由于G1的应用场合往往堆内存都比较大,所以Full GC的收集代价非常昂贵,应该避免Full GC的发生。
总结一下
总的来说G1是一款非常优秀的垃圾回收器,现在也在企业应用的过程中越来越多的用到。其控制响应时间,跟简单的设置就能达到优秀的效率上面来说相对于于CMS等垃圾回收器来说无疑是巨大的进步。在我们发现使用CMS垃圾回收器时候了解不是很深刻,又或者对CMS调优方面已经在当前面临的情况没有好的办法了,尝试切换成G1垃圾回收器肯定会打来意想不到的收获。
但是在G1也有不少的缺点,因为有Concurrent Refine Thread 还有 RSet 等机制的存在一是对性能的影响,对内存的浪费都存在不少缺点。不过现在JDK15已经在2020.09.15面世,其中已经将ZGC(Zero GC作为主推的垃圾回收器),其管理内存在理论上已经达到了32T,而且MaxPauseTime 可以保证在10ms以内,无疑是巨大的进步。不过JDK15还不是LTS版本,所以只能说期待吧。有机会可以在以后的时间中与大家分享ZGC的内容。