
2013年发布至今, Docker 一直广受瞩目,被认为可能会改变整个软件行业。的确,目前公司有很多业务已经在选择上云,而 k8s 的实现,便是基于 Docker 技术。本文将从 Linux 的角度,讲述一下 Docker 的大致实现原理。
传统 pass 服务的缺陷
传统 pass 服务基于虚拟机技术,我们先来看一下虚拟机的架构图:
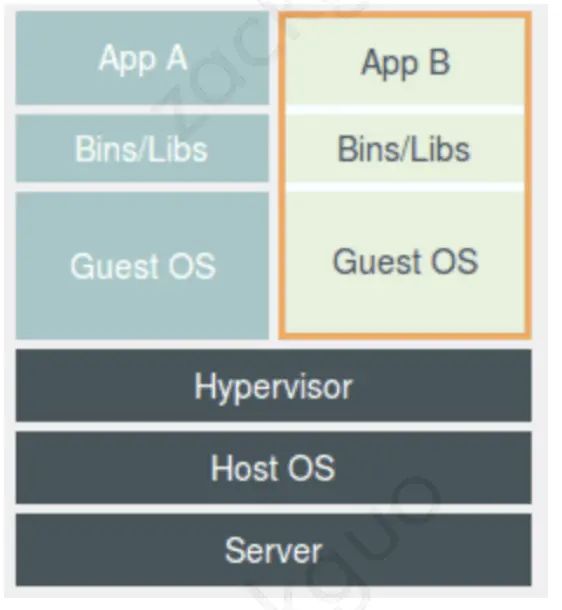
虚拟机通过硬件虚拟化技术,在一台宿主机上用软件模拟硬件,隔离出一个个虚拟操作系统。
这种架构的好处是,运行在不同虚拟机上的两个进程,可以做到硬件级别的隔离。
但是,也会带来几个问题:
- Guest OS 本身是一个完整的操作系统,这就不可避免地带来了额外的资源消耗和占用。
- 我们在 Guest OS 层中的大部分系统调用,都需要通过 Hypervisor 做中转,会造成一定的性能损耗。
- 开发者将本地应用部署到远端虚拟机时,可能会因两端运行环境不一致,产生或多或少的问题。
Docker 能带来什么
看一下 Docker 的架构图:
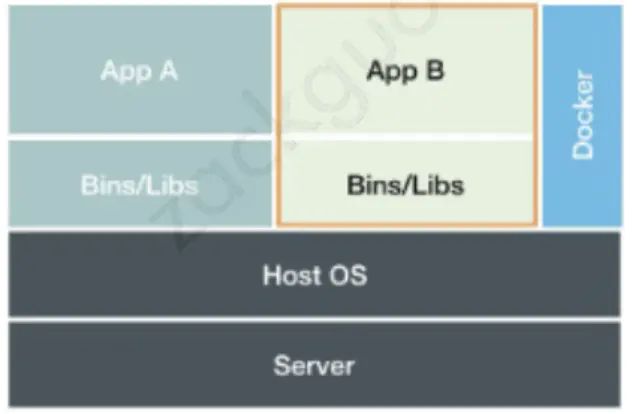
- docker 的实现基于 linux 容器,而 linux 容器只是一个特殊的进程。
所以,docker run 的本质,就是辅佐启动一个运行在 linux 上的特殊进程而已,这就免去了无谓的性能消耗和资源占用。
- docker 镜像不仅会打包应用,也会打包整个操作系统文件和目录。也就意味着,应用以及它运行时所需要的所有依赖,都被封装在了一起。这样就做到了本地和远端运行环境的一致性。
Linux容器的原理
所谓 linux 容器,就是采用一系列系统调用,改造一个进程变成我们需要的沙盒进程。
一. 利用 Namespace 以及 chroot,做到进程视图级别的隔离。
- Namespace
当我们使用 clone()
系统调用创建进程时,可以指定 namespace,该进程就只能看见同一个命名空间下的信息了。
举个例子, pid namespace:
(1) 编写一个 C 程序:
#define _GNU_SOURCE
#include
#include
#include
#include
#include
#include
#include
#define STACK_SIZE (1024 * 1024)
static int childFunc(void *arg)
{
printf("In child process.n");
execlp("bash", "bash", (char *) NULL);
return 0;
}
int main(int argc, char *argv[])
{
char *stack;
char *stackTop;
pid_t pid;
stack = malloc(STACK_SIZE);
if (stack == NULL)
{
perror("malloc");
exit(1);
}
stackTop = stack + STACK_SIZE;
pid = clone(childFunc, stackTop, CLONE_NEWPID|CLONE_NEWNS, NULL);
if (pid == -1)
{
perror("clone");
exit(1);
}
printf("clone() returned %ldn", (long) pid);
sleep(1);
if (waitpid(pid, NULL, 0) == -1)
{
perror("waitpid");
exit(1);
}
printf("child has terminatedn");
exit(0);
}复制代码 (2) 编译,运行:

通过 echo ?,我们可以得到当前 bash 的进程号 - 9882。
一旦运行了上面的程序,我们就会进入一个新的 pid 的 namespace。当我们再次 echo 的时候,就会发现当前新建的 bash 的进程号变成了 1。上面的程序运行了一个新的 bash,它在一个独立的 pid namespace 里面,自己是1号进程。
但其实,我们另起一个终端,在宿主机视角下,发现新建的 bash 进程,真正的 pid 为 24991,而真正的 1 号进程另有其人:

真正的 pid 1 号进程:

这种机制,其实就是对被隔离应用的进程空间做了手脚,使得这些进程只能看到重新计算过的进程编号。
除了pid ns,Linux 还支持以下 ns,用来对进程上下文进行不同的“障眼法”操作:

- chroot
我们可以使用 mount ns 让被隔离进程只看到当前 ns 里的挂载点信息,即不同 ns 下的进程看到的文件系统结构是不同的。
但是通过 clone 创建的 mount ns 会默认继承父 ns 的内容,也就是说两者看到的文件系统内容是一样的:
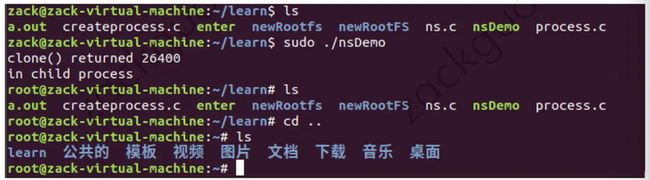
也就是说,我们创建的容器,看到的文件系统和宿主机是完全一样的,这样就违背了隔离性。
理想的情况应该是,当我们新创建一个容器时,该容器拥有一个独立的隔离环境,而不是继承宿主机的文件系统。
所以我们使用 chroot ,它可以修改进程的根目录,举个例子:
(1) 首先新建一个根目录,将程序需要的库和程序拷贝到新根目录下(还是使用之前那个例子的程序):
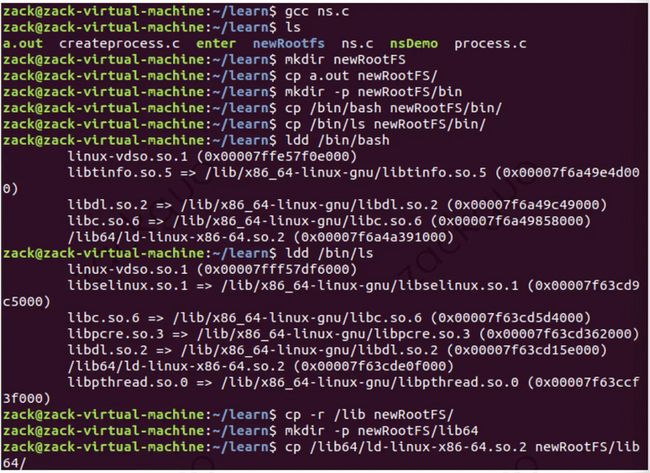
(2) 使用 chroot 运行自己编译好的 C 程序:
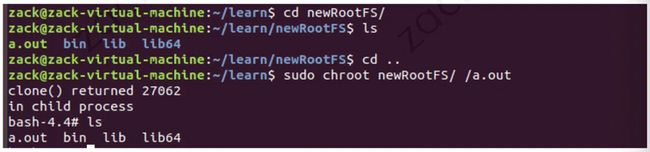
这样,该进程就有了自己的根文件系统。
当然,为了能够让这个根目录看起来更真实,我们一般会在这个容器的根目录下挂载一个完整操作系统的文件系统,也就是所谓的"容器镜像",即 rootfs (根文件系统)。
二. 利用 Cgroups,限制进程资源。
虽然我们采用 namespace 和 chroot 技术,蒙蔽了容器的双眼,进行了"隔离"。但是对宿主机而言,它依旧是个进程,可以肆无忌惮的争夺资源。而 Linux Cgroups 就是 Linux 内核中用来为进程进行资源限制的技术。
Linux Cgroups 的全称是 Linux Control Group。它可以用来限制一个进程组能够使用的资源上限,包括CPU、
内存、磁盘、网络带宽等。该机制暴露给用户的操作接口是文件系统,具体的使用步骤如下:
- 在对应的资源子系统目录下新建进程组目录,此时操作系统会自动在该目录下生产相应的资源限制文件
。
- 在资源限制文件中写配置,即进行资源限制。
- 把需要被限制的进程 PID 写入进程组里的 tasks 文件中。
举个例子:
(1) 写一个运行死循环的 C 程序:
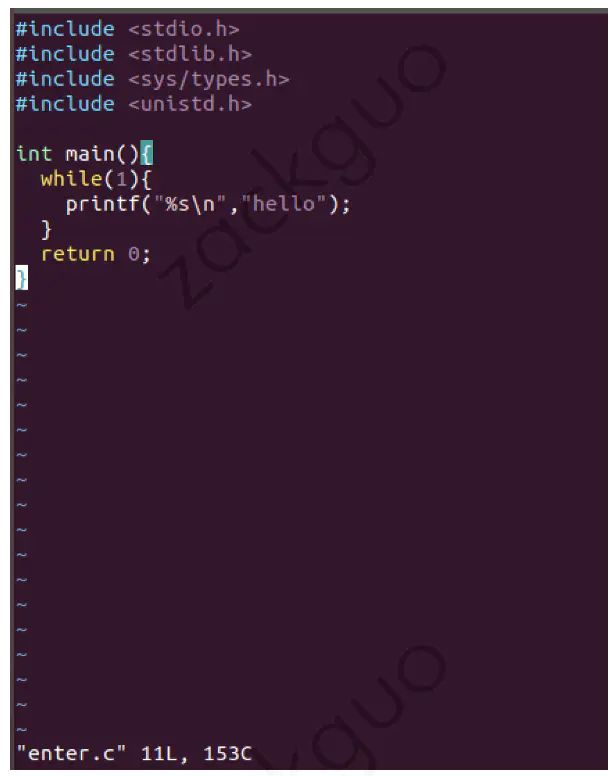
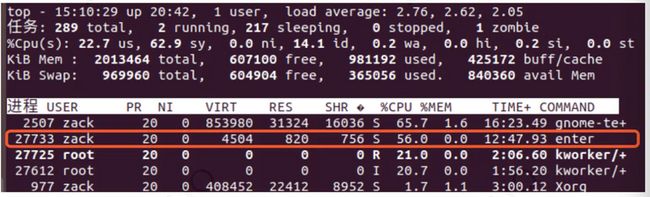
(2) 编译运行,发现该进程占用了 56% 的 CPU 资源:
(3) 找到 cpu 对应的资源限制子系统,创建一个目录,即控制组:
(4) 然后,操作系统会在新创建的 container 目录下,自动生成该子系统对应的资源限制文件:

(5) 查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us):

(6) 修改这些文件的内容来设置限制。比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):

它意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。
(7) 最后,我们把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了:
Docker 分层镜像
Docker中的镜像采用分层构建设计,每个层可以称之为“layer”,这些 layer 被存放在 /var/lib/docker/
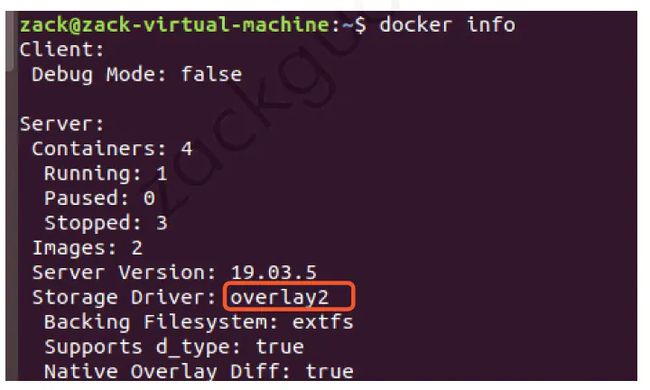
一. overlay2 联合挂载
overlayfs 通过三个目录:lower 目录、upper 目录、以及 work 目录实现,其中 lower 目录可以是多个基础只读层,upper 是容器运行时的读写层,work 目录为工作基础目录,挂载后内容会被清空,且在使用过程中其内容用户不可见,最后联合挂载完成给用户呈现的统一视图称为 merged 目录。
以下使用 mount 演示其如何工作的:
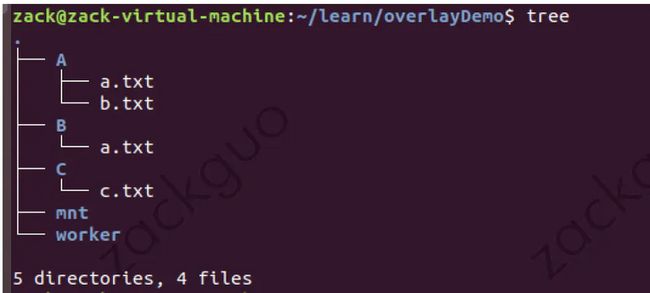
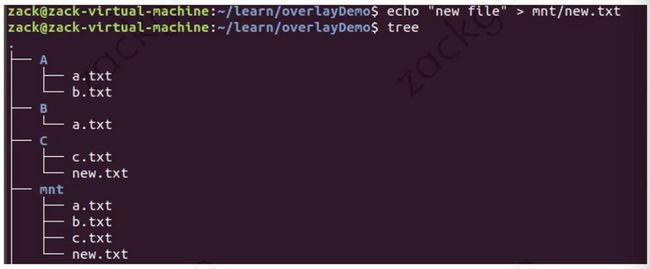
(1) 创建目录 A、B、C, worker 以及最终希望挂载到的目录 mnt :
(2) 然后使用 mount 联合挂载到 mnt 下:

发现目录 A、B、C 被合并到了一起,并且相同文件名的文件会进行“覆盖”,这里覆盖并不是真正的覆盖,而是当合并时候目录中两个文件名称都相同时,merged 层目录会显示离它最近层的文件:

二. docker 与 overlay
以下是来自 docker 官网关于 overlay 的工作原理图:
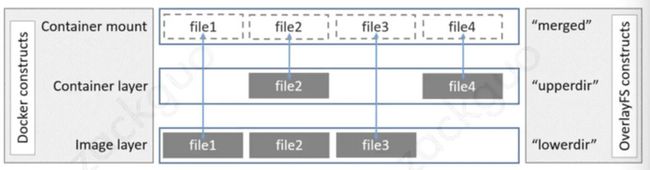
在上述图中可以看到三个层结构,即:lowerdir、uperdir、merged。
- owerdir 是只读的 image layer,其实就是 rootfs,对比我们上述演示的目录 A 和 B,我们知道 image layer可以分很多层,所以对应的 lowerdir 是可以有多个目录。
- upperdir 则是在 lowerdir 之上的一层,这层是读写层,在启动一个容器时候会进行创建,所有的对容器数据更改都发生在这里层,对比示例中的 C。比如我们在挂载区域 mnt 新建文件,其实是在 upperdir 指向的 C 目录下新建文件:
- merged目录是容器的挂载点,也就是给用户暴露的统一视角,对比示例中的 mnt。而这些目录层都保存在 /var/lib/docker/overlay2/或者/var/lib/docker/overlay/ (如果使用 overlay )
容器读写文件的工作模式:
读:
- 如果文件在容器层(upperdir),直接读取文件;
- 如果文件不在容器层(upperdir),则从镜像层(lowerdir)读取;
修改:
- 首次写入: 如果在 upperdir 中不存在,overlay2 执行 copy_up 操作,把文件从 lowdir 拷贝到 upperdir,后续对同一文件的再次写入操作,转换为对已复制到 upperdir 的文件副本进行操作。这也就是常常说的写时复制(copy-on-write)
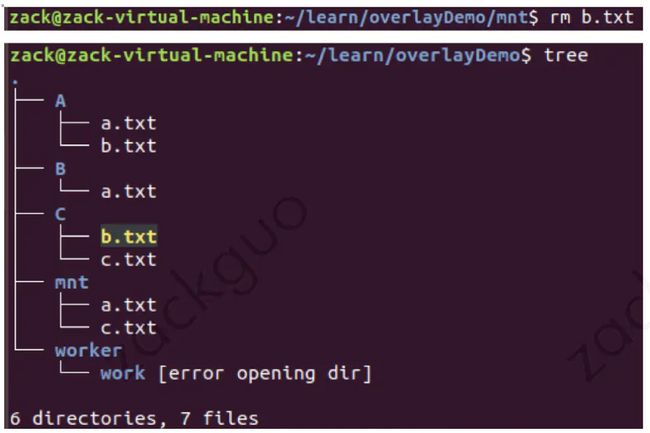
- 删除文件和目录: 当容器要删除镜像层文件时,并不会真正删除在 lowerdir 的文件,而是在 upperdir 创建 whiteout 文件利用 without 阻止他们显示:
注:
- copy_up 操作只发生在文件首次写入,以后都是只修改副本。
- 只要是对镜像层文件的操作,无论是多小的改动,都会在容器层新建一个文件副本,所以对大文件修改要慎重,避免导致镜像变得很大。
- 容器中的文件删除只是一个“障眼法”,是靠 whiteout 文件将其遮挡,image 层并没有删除,这也就是为什么使用docker commit 提交保存的镜像会越来越大,无论在容器层怎么删除数据,image 层都不会改变。
三. 具体使用
我们拉取一个 ubuntu:latest 镜像看一下具体使用:
运行镜像:

新启终端,找到容器挂载信息:lowerdir, upperdir, workdir 以及最终使用的挂载目录 mnt:
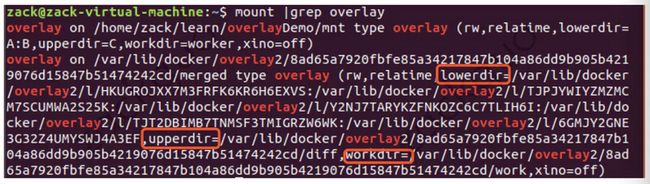
lowerdir:指定容器依赖的镜像层地址(从上往下排列),l 目录包含了所有层的软连接,短链接使用短名称,避免 mount 时候参数受到限制。
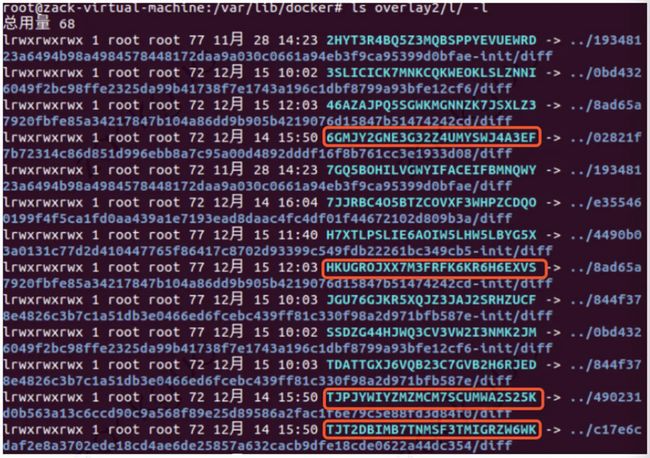

发现lowerdir上不只有我们拉取的四层镜像,还有一个 init 层:
init 层是以一个 uuid+-init 结尾表示,夹在只读层和读写层之间,作用是专门存放 /etc/hosts、/etc/resolv.conf 等信息。
需要这一层的原因是当容器启动时候,这些本该属于 image 层的文件或目录,比如 hostname,用户需要修改,但是 image 层又不允许修改,所以启动时候通过单独挂载一层 init 层,通过修改 init 层中的文件达到修改这些文件目的。而这些修改往往只对当前容器生效,所以在 docker commit 提交镜像时,并不会将 init 层提交。
查看 lowerdir 真正指向的文件:
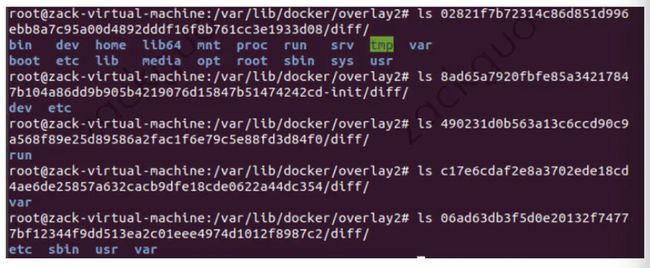
处于底层的镜像目录包含了一个diff和一个link文件,diff 目录存放了当前层的镜像内容,而 link文件则是与之对应的短名称:
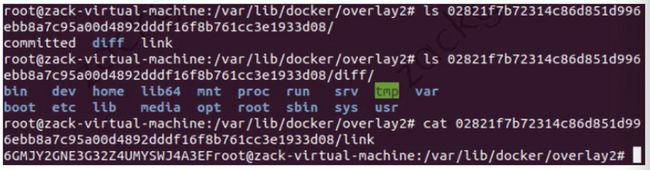
在这之上的镜像还多了 work 目录和 lower 文件,lower 文件用于记录父层的短名称,work 目录用于联合挂载指定的工作目录
upperdir 和 workdir:

最终联合挂载的mnt:

那么这些目录和镜像的关系是怎么组织在的一起呢?也就是我们下载的 ubuntu:latest 镜像是如何与这些目录关联起来的呢?
答案是通过元数据关联。元数据分为 image 元数据和 layer 元数据。
我们来具体看一下,先查找镜像id:7753...

元数据信息存储在 /var/lib/docker/image/overlay2/ 目录下
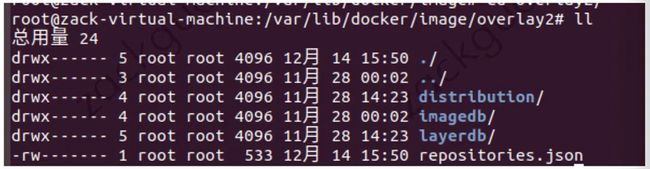
imagedb:用来放置镜像的元数据,例如包含哪些 layer。
layerdb:存放具体的层的元数据,便于各个镜像间共享。
到 imagedb/content/sha256 下,找到对应的镜像信息元数据:
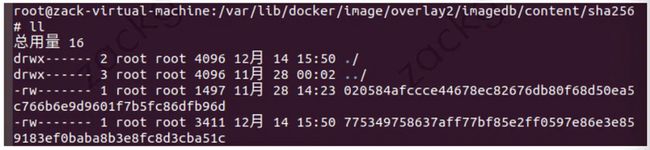
打开文件,可以找到该镜像依赖的 4 个 layer ID。
从上往下看,就是底层到顶层,即 cc96... 是image的最底层:
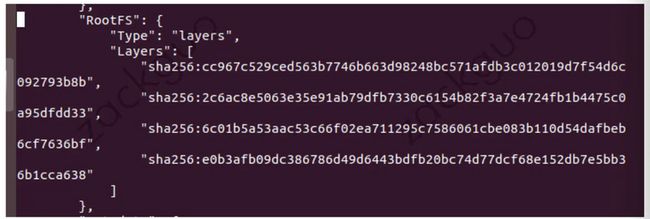
得到了组成这个 image 的所有 layerID,那么我们就可以带着这些 layerID 到上一层的 layoutdb 中去寻找对应的 layer 了:
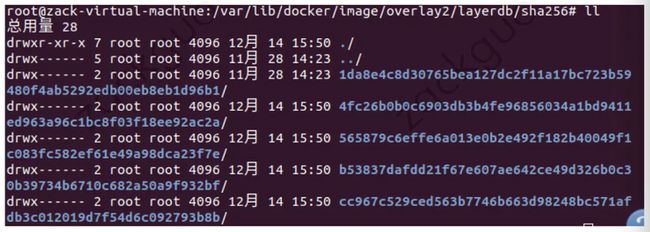
在这里,我们仅仅发现 cc96... 这个最底层的 layer,那么剩余三个 layer 为什么会没有呢?
那是因为 docker 使用了 chainID 的方式去保存这些 layer,简单来说就是 chainID=sha256sum(H(chainID) diffid),也就是cc96...的上一层的 sha256 id是:

这样,我们就能找到 5658... 这个 layer 层了。依次类推,我们就能找出镜像依赖的所有的 layerID 的组合。
但是,这里只是存放各个 layer 元数据的地方,并不是镜像真正使用的 rootfs。
为了找到真正使用的 layer 数据,我们打印一下
5658.../catch-id:

到 /var/lib/docker/overlay2/ 就能找到
这个id就是对应
的文件:
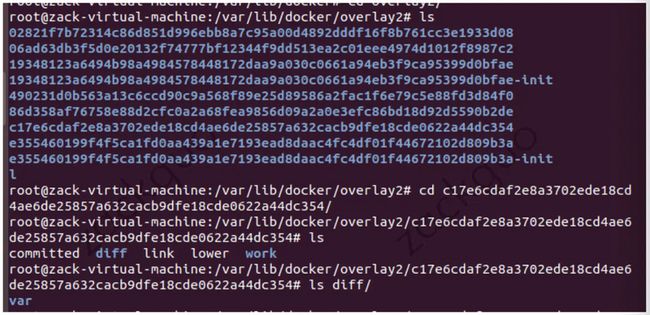
以此类推,通过更高一层的 layer 的 cache-id 也能找到对应的 rootfs,当这些 rootfs 的 diff 目录通过联合挂载的方式挂载到某个目录,就是整个容器需要的完整 rootfs 了。
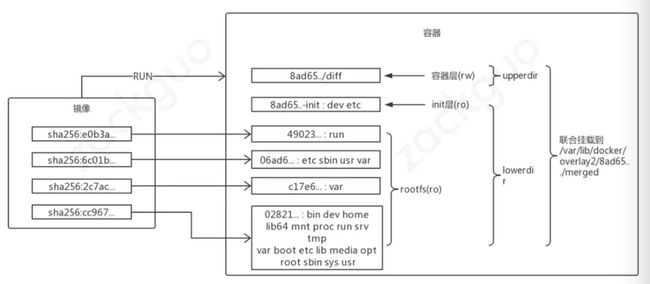
通过以上的内容介绍,一个容器完整的层应由三个部分组成,如下图:
- 镜像层:也称为 rootfs,提供容器启动的文件系统。
- init 层: 用于修改容器中一些文件如 /etc/hostname、/etc/resolv.conf 等,配置只对当前容器有效,即 docker commit 只会提交只读镜像层和容器可读可写层。
- 容器层:使用联合挂载统一给用户提供的可读写目录。
附录 - 参考资料
- 趣谈Linux操作系统:time.geekbang.org/column/intr…
- 深入剖析Kubernetes:time.geekbang.org/column/intr…
- Docker镜像存储-overlayfs:www.cnblogs.com/wdliu/p/104…