SpringCloud学习(九)——SpringCloud Stream消息驱动原理与搭建
1.消息驱动基本概念
(1)什么是消息驱动?
用的比较少,可以简化开发人员对消息中间件的使用复杂度,可以整合常用消息队列,它基于SpringBoot实现,拥有自动化配置功能。
(备注:SpringCloud对消息队列的整合体现在哪:Bus,Stream)
(2)消息驱动Stream原理
底层就是把不同消息队列封装成统一API,开发人员只需要对接Stream组件即可,不需要关注MQ原理只需要关注业务。
通过定义绑定器作为中间层,实现了应用程序与消息中间件细节隔离。通过向应用程序暴露统一的Channel(消息通道),程序不需要考虑不同的消息中间件实现。当需要升级或者更换其他消息中间件产品时,只需要更换对应的Binder绑定器
原理图:

官网的原理图:
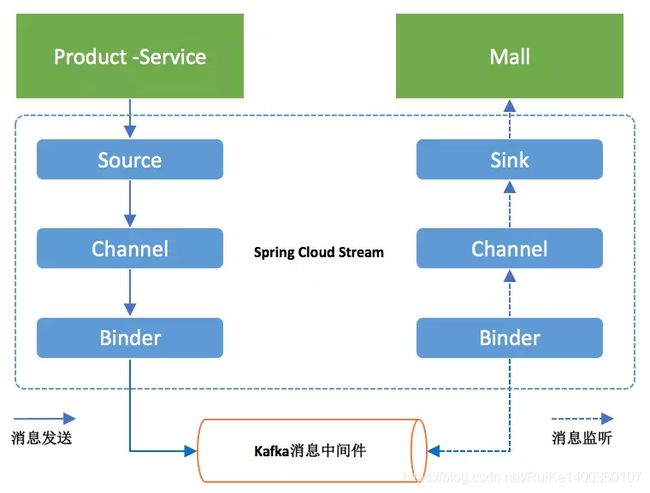
(2)消息驱动核心概念(如上图)
Source:当需要发送消息时,Source将会把我们所要发送的消息(POJO对象)进行序列化(默认转换成JSON),然后将这些数据发送到Channer中。
Sink:用来监听消息。负责从消息通道中获取消息,并将消息反序列化成消息对象(POJO对象),然后交给具体的消息监听处理进行业务处理。
Channel:消息通道,Stream的抽象之一。通常向消息中间件发消息或者监听消息时需要指定主题(Topic)/消息队列名称,但如果变更主题时需要修改单代码。但是通过Channel抽象,具体Channel对应哪个主题就可以在配置文件中指定,做到主题变更时不需要改代码,实现了具体消息中间件的解耦
Binder:绑定,Stream的抽象之一。通过不同的Binder可以实现与不同消息中间件的整合,可以提供统一的消息手法接口
2.消息驱动搭建步骤
生产者环境:
生产者流程:创建发送消息通道——>生产者投递消息(往通道发消息)——>开启绑定(结合)
(1)创建管道
// 创建管道接口
public interface SendMessageInterface {
// 创建一个输出管道,用于发送消息
@Output("my_msg") //表示写入
SubscribableChannel sendMsg();
}
(2)发动消息
@RestController
public class SendMsgController {
@Autowired
private SendMessageInterface sendMessageInterface;
@RequestMapping("/sendMsg")
public String sendMsg() {
String msg = UUID.randomUUID().toString();
System.out.println("生产者发送内容msg:" + msg);
Message build = MessageBuilder.withPayload(msg.getBytes()).build();
sendMessageInterface.sendMsg().send(build);
return "success";
}
}
(3)启动服务
@SpringBootApplication
@EnableBinding(SendMessageInterface.class) // 开启绑定
public class AppProducer {
public static void main(String[] args) {
SpringApplication.run(AppProducer.class, args);
}
}
消费者环境:
(1)管道中绑定消息
public interface RedMsgInterface {
// 从管道中获取消息
@Input("my_msg")
SubscribableChannel redMsg();
}
(2)消费者获取消息
@Component
public class Consumer {
@StreamListener("my_msg")
public void listener(String msg) {
System.out.println("消费者获取生产消息:" + msg);
}
}
(3)启动消费者
@SpringBootApplication
@EnableBinding(RedMsgInterface.class)
public class AppConsumer {
public static void main(String[] args) {
SpringApplication.run(AppConsumer.class, args);
}
}
消费组(消息分组):
在现实的业务场景中,每一个微服务应用为了实现高可用和负载均衡,都会集群部署,按照上面我们启动了两个应用的实例,消息被重复消费了两次,为了解决重复消费,引入了“消费组”
消费组配置:
server:
port: 8001
spring:
application:
name: spring-cloud-stream
# rabbitmq:
# host: 192.168.174.128
# port: 5672
# username: guest
# password: guest
cloud:
stream:
bindings:
mymsg: ###指定 管道名称
#指定该应用实例属于 stream 消费组
group: stream
MQ更改为kafka(不用动代码,只需要改配置文件):
迁移步骤:修改破灭文件绑定改为kafka——>修改yml连接改为kafka连接
Maven依赖:
org.springframework.cloud
spring-cloud-starter-stream-kafka
2.0.1.RELEASE
生产者配置:
server:
port: 9000
spring:
cloud:
stream:
# 设置成使用kafka
kafka:
binder:
# Kafka的服务端列表,默认localhost
brokers: 192.168.212.174:9092,192.168.212.175:9092,192.168.212.176:9092
# Kafka服务端连接的ZooKeeper节点列表,默认localhost
zkNodes: 192.168.212.174:2181,192.168.212.175:2181,192.168.212.176:2181
minPartitionCount: 1
autoCreateTopics: true
autoAddPartitions: true
消费者配置:
server:
port: 8000
spring:
application:
name: springcloud_kafka_consumer
cloud:
instance-count: 1
instance-index: 0
stream:
kafka:
binder:
brokers: 192.168.212.174:9092,192.168.212.175:9092,192.168.212.176:9092
zk-nodes: 192.168.212.174:2181,192.168.212.175:2181,192.168.212.176:2181
auto-add-partitions: true
auto-create-topics: true
min-partition-count: 1
bindings:
input:
destination: my_msg
group: s1
consumer:
autoCommitOffset: false
concurrency: 1
partitioned: false