python+selenium自动化测试基本框架-学习笔记
一、框架结构介绍
1、环境搭建
① 安装python
官网:https://www.python.org/downloads/下载按装,安装时可以勾选自动添加环境变量;如果未添加通过手动添加
② 安装selenium
pip install selenium
③ 安装xlrd模块,读excel表
pip install xlrd
④ 安装unittestreport模块,输出测试html格式的测试报告
pip install unittestreport
2、注意:在第一层文件目录中,需要手动创建__init__.py文件
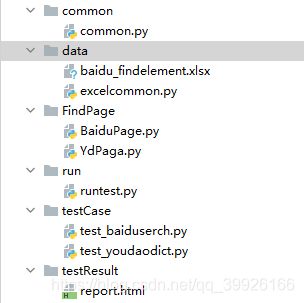

① common为公共模块
② data:存放数据(如excel,数据库等)
③ FindPage:查找页面元素
④ run:运行测试脚本
⑤ testCase:存放测试用例
⑥ testRessult:最后出入的html文件格式的测试报告
二、公共模块common
common.py
#common.py
from selenium import webdriver
import logging
import os
import sys
Basepath = os.path.split(os.path.dirname(os.path.abspath(__file__)))[0]
class Common():
#初始化属性
def __init__(self,driver):
self.driver = driver
def openWww(self,url):#打开网页 #1
self.driver.get(url)
def findElement(self,*element):#查找元素 #2
return self.driver.find_element(*element)
def closeBrowser(self):
self.driver.quit()#关闭浏览器
def setlog(loginfo):
fp = Basepath + "//log"
logging.basicConfig(
format='py文件名:%(filename)s 日志等级:%(levelno)s 等级名:%(levelname)s 行数:%(lineno)s 记录时间:%(asctime)s 信息:%(message)s',
level = logging.DEBUG,
filename = fp + "my.log",
filemode= 'a',
)
logging.debug(loginfo)
1、打开网页示例代码,上面模块中的 openWww()打开网页
#例子:
from selenium import webdriver
from time import sleep
#打开浏览器
driver = webdriver.Chrome()
#打开百度网页
driver.get("http://www.baidu.com")
#强制等待3s
sleep(3)
#关闭浏览器
driver.quit()
2、查找元素的表现形式;findElement()中的find_element()表现方式,其中 *element 表示的是可以传递一个序列,元组形式;一下列表中是selenium中基本的八种元素定位方式,在FindPage中会用到,按照页面定位灵活应用
| by_id(通过id 进行查找) | find_element(“id”,"") |
|---|---|
| by_xpath(通过xpath路径进行查找) | find_element(“xpath”,"") |
| by_name(通过name属性进行查找) | find_element(“name”,"") |
| by_tag_name(通过标签名定位) | find_element(“tag name”,"") |
| by_class_name(通过class名进行查找) | find_element(“class name”,"") |
| by_css_selector(通过css属性定位) | find_element(“css selector”,"") |
| by_link_text(通过链接名定位) | find_element(“link text”,"") |
| by_partial_text(通过部分链接名定位) | find_element(“partial link text”,"") |
例子:下面是一个序列的形式,(‘id’,‘kw’)后面带入比较方便,用send_keys输入内容,这部分放在了FindPage中
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
#下面是一个序列的形式,('id','kw')后面带入比较方便
driver.find_element("id",'kw').send_keys("123")
sleep(3)
driver.quit()
3、logging模块在八中有介绍
三、查找页面元素
FindPage
BaiduPage.py #百度页面
#BaiduPage.py
from selenium import webdriver
#from selenium.webdriver.common.by import By
import sys
import os
Basepath = os.path.split(os.path.dirname(os.path.abspath(__file__)))[0]
print(Basepath)
sys.path.append(Basepath + "\\common")
sys.path.append(Basepath + "\\FindPage")
from common import Common
class SerchFrame(Common):
serchframe = ["id","kw"] #1
button = ["id","su"]
def __init__(self,driver):
super().__init__(driver)
#清除输入框中数据
def serch_content_clear(self):
self.findElement(*self.serchframe).clear()#*self.serchframe接受序列的值的 #2
def serch_content_sendkeys(self,send_keys):
self.findElement(*self.serchframe).send_keys(send_keys)
def submitClick(self):
self.findElement(*self.button).click()
def get_title(self):
return self.driver.title
1、查找元素的话,第二点中有介绍
2、*var,表示可以传入一个序列
四、data模块
excelcommon.py
#excelcommon.py
import xlrd
class ExcelCommon():
#book= None
#sheet = None
def __init__(self,filepath):
self.filepath = filepath
def openexcel(self):
self.book = xlrd.open_workbook(self.filepath)
def index_sheet(self,num):
self.sheet = self.book.sheet_by_index(num)
def getcell(self,x,y):
return self.sheet.cell(x,y).value
1、用到了xlrd模块,读取data/ 目录中excel表,使用方法:https://blog.csdn.net/qq_39926166/article/details/108264267
excel表:


五、测试用例
testCase
test_baiduserch.py #编写一个百度搜索的测试用例
#test_baiduserch.py
from selenium import webdriver
import unittest
import sys
import os
import time
Basepath = os.path.split(os.path.dirname(os.path.abspath(__file__)))[0]
sys.path.append(Basepath + "\\common")
sys.path.append(Basepath + "\\FindPage")
sys.path.append(Basepath + "\\data")
from excelcommon import ExcelCommon
from BaiduPage import SerchFrame
from common import setlog
class BaiduSerch(unittest.TestCase):
def setUp(self):
driver = webdriver.Chrome()
self.serch = SerchFrame(driver)
driver.implicitly_wait(30)#显示等待时间
self.serch.openWww("https://www.baidu.com")
def test_baiduserchfreme(self):
setlog("测试用例1")
excel = ExcelCommon(Basepath + "\\data\\baidu_findelement.xlsx")
excel.openexcel()
excel.index_sheet(0)
self.serch.serch_content_clear()
content = excel.getcell(1,2)
#pinrt查看是否有错
print(content)
self.serch.serch_content_sendkeys("unittest")
self.serch.submitClick()
time.sleep(2)
get_title = self.serch.get_title()
self.assertEqual(get_title,"unittest_百度搜索")
time.sleep(2)
def tearDown(self):
self.serch.closeBrowser()
1、断言:
| assertEqual(a, b) | a ==b |
| assertNotEqual(a, b) | a !=b |
| assertTrue(a) | a is True |
| assertFalse(a) | a is False |
| assertIs(a, b) | a is b |
| assertIsNot(a, b) | a is not b |
| assertIsNone(x) | x is None |
| assertIsNotNone(x) | x is not None |
| assertIn(a, b) | a in b |
| assertNotIn(a, b) | a not in b |
| assertIsInstance(a, b) | isinstance(a,b) |
| assertNotIsInstance(a, b) | not isinstance(a,b) |
六、运行模块 Run
runtest.py
#runtest.py
#coding=utf-8
from selenium import webdriver
import unittest,time
from unittestreport import TestRunner #1
import sys
import os
Basepath = os.path.split(os.path.dirname(os.path.abspath(__file__)))[0]
sys.path.append(Basepath + "\\testCase")
filename = Basepath + "\\testCase"
def runtest():
discovers = unittest.defaultTestLoader.discover(filename,pattern="test_*.py") #2
return discovers
if __name__ == "__main__":
fp = Basepath + '\\testResult'
runner = TestRunner(runtest(),filename="report.html",report_dir=fp,title="百度搜索测试",tester="LLEI",desc="针对百度搜索进行测试的测试报告")
runner.run()
1、unittestreport模块输出html格式测试报告,使用方法:https://blog.csdn.net/qq_39926166/article/details/107941509
2、discover用法 unittest.defaultTestLoader.discover,返回到测套件中
filename: 测试用例文件存放目录
pattern: 筛选以test_开头的py文件
七、os的使用
python中os模块简单使用
import os
import sys
1、获取文件所在目录:
print(os.path.realpath(__file__))
------------------------------------------------------------------------------------------------------------
E:\练习文档\python笔记\写入文件\os.py
2、os.path.slipt(path)分割成目录和文件
print(os.path.split(os.path.realpath(__file__)))
------------------------------------------------------------------------------------------------------------
('E:\\练习文档\\python笔记\\写入文件', 'os.py')
3、dirname(path) 返回 path目录
print(os.path.split((os.path.dirname(__file__))))
------------------------------------------------------------------------------------------------------------
('e:/练习文档/python笔记', '写入文件')
4、abspath()获取 当前文件所有路径
print(os.path.abspath(__file__))
------------------------------------------------------------------------------------------------------------
e:\练习文档\python笔记\写入文件\os.py
5、sys.path.append(路径)加入环境变量中去
paths = os.path.split(os.path.dirname(os.path.abspath(__file__)))[0]
print(paths)
#将'e:\练习文档\python笔记'路径添加到环境变量中
sys.path.append(paths)
------------------------------------------------------------------------------------------------------------
e:\练习文档\python笔记
八、输出日志的使用logging
import logging
import os
'''
logging.debug("debug 一般打印调试信息")
logging.info("info 打印正常操作信息")g
logging.warning("warning 打印警告信息")
logging.error("error 打印错误信息")
logging.critical("critical 打印致命错误信息,等级最高")
'''
'''
%(name)s:Logger的名字
%(levelno)s:打印日志级别的数值
%(levelname)s:打印日志级别的名称
%(pathname)s:打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s:打印当前执行程序名
%(funcName)s:打印日志的当前函数
%(lineno)d:打印日志的当前行号
%(asctime)s:打印日志的时间
%(thread)d:打印线程ID
%(threadName)s:打印线程名称
%(process)d:打印进程ID
%(message)s:打印日志信息
'''
BasePath = os.path.dirname(__file__)
fp = BasePath + "//log"
logging.basicConfig(
level=logging.ERROR,
filename = fp + 'my.log',#不要加斜杠,直接加文件名称
filemode="a",
format='记录时间:%(asctime)s 日志等级:%(levelno)s 等级名称:%(levelname)s 当前行号:%(lineno)s 文件名: %(filename)s 信息:%(message)s',)#filemode为文件打开模式,"a"追加模式,也可以为 "w" 每次重新写入
logging.debug("debug 一般打印调试信息")
输出日志时我遇到一个问题就是,不能将log文件输出到某个目录中去,现在是输出到项目项目中目录中,在公共模块中使用(common.py
)中