python 利用selenium实现自动打卡
0. 前言
由于疫情需要天天打卡,刚好在学爬虫便借此机会利用selenium实现自动打卡。
1. 前期准备
这里使用的是chrome浏览器,需要配置好ChromeDriver,还要安装好Selenium库。
from selenium import webdriver
# 这是模拟打开百度的test
url = 'https://www.baidu.com/' # 网址
browser = webdriver.Chrome() # 打开chrome浏览器
browser.get(url) # 进入所指定的网站
2. 模拟打卡
当进入网站后直接来到登录页面,我们需要输入用户名、输入密码、点击登录。
2.1 输入用户名、密码
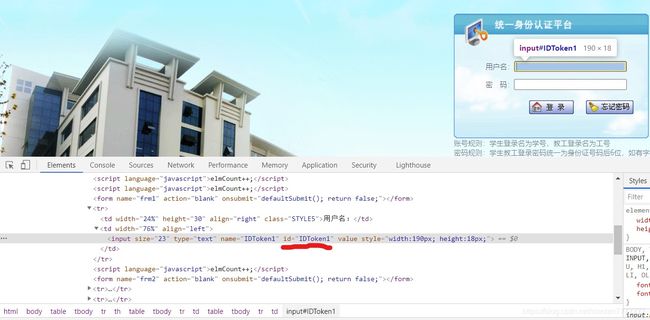
在chrome的检查里我们可以看到用户名输入栏对应的id,同理也可以找到密码对应的id。
# 登录的用户名和密码
name = "xiaolan"
word = '123456'
# 获取用户名的id并输入
username = browser.find_element_by_id('IDToken1')
username.send_keys(name)
# 获得密码的id,并输入
password = browser.find_element_by_id('IDToken2')
password.send_keys(word)
2.2 点击登录
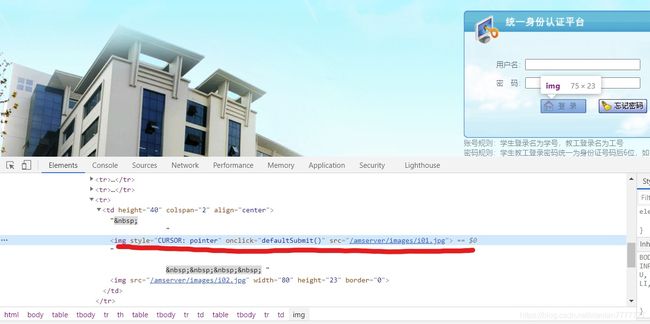
可以发现登录是一张图片,并不像之前一样能用id选择,因此这里通过xpath定位到登录。
# 点击登录
browser.find_element_by_xpath('/html/body/table/tbody/tr[2]/th/table[2]/tbody/tr[2]/td[2]/table/tbody/tr[6]/td/img[1]').click()
2.3 进入页面
点击登录后,进入进入界面。我们需要在这里点击进入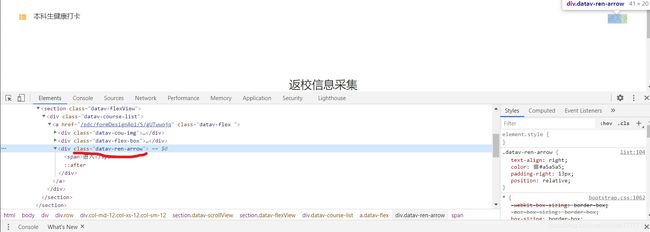
这里我们可以通过class定位到进入。
# 点击进入
browser.find_element_by_class_name('datav-ren-arrow').click()
2.4 提交页面
点击进入后来到提交页面,由于服务器已经记录之前提交过的结果,并预先帮你默认好,因此只需要点击提交按钮即可。
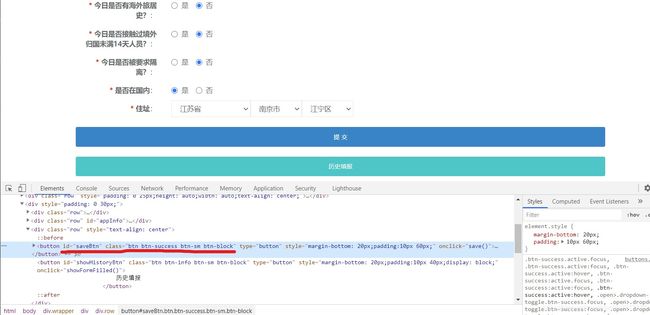
这里可以通过选取id、或者class来定位到提交按钮。
# 点击提交
browser.find_element_by_id('saveBtn').click()
3. Selenium被反爬
其实我也不知道是服务器的原因还是被反爬的原因。
有时候服务器会在登录界面返回第二套页面,登录图片的xpath和第一套有一个节点不一致,更换对应xpath后之后正常进行,但最后一步提交服务器必定会返回出现未知错误的页面。
有时候就很正常的打卡成功。
感兴趣的可以了解下把webdriver的JS中的关键字替换掉,去反反爬。
4. 代码
from selenium import webdriver
from selenium.webdriver import ChromeOptions
import time
# 打开浏览器进入网址
url = '' # 你要进入的网址
browser = webdriver.Chrome() # 打开chrome浏览器
browser.get(url) # 进入所指定的网站
# 登录的用户名和密码
name = 'xiaolan'
word = '123456'
# 获取用户名的id并输入
username = browser.find_element_by_id('IDToken1')
username.send_keys(name)
# 获得密码的id,并输入
password = browser.find_element_by_id('IDToken2')
password.send_keys(word)
time.sleep(2)
# 点击登录
browser.find_element_by_xpath('/html/body/table/tbody/tr[2]/th/table[2]/tbody/tr[2]/td[2]/table/tbody/tr[6]/td/img[1]').click()
# browser.find_element_by_xpath('/html/body/table/tbody/tr[2]/td/table[2]/tbody/tr[2]/td[2]/table/tbody/tr[6]/td/img[1]').click()
time.sleep(10)
# 点击进入
browser.find_element_by_class_name('datav-ren-arrow').click()
time.sleep(5)
# 点击提交
browser.find_element_by_id('saveBtn').click()