KAFKA学习
Kafka学习
官网下载网址:
https://mirrors.bfsu.edu.cn/apache/kafka/2.5.0/kafka-2.5.0-src.tgz
中文文档:https://kafka.apachecn.org/
brew安装组件说明:
组件安装文件路径:/usr/local/Cellar/
组件配置文件路径:/usr/local/etc/
1. 简介
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于
zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于
hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服
等等,用scala和java语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
1.1 特性
-
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作;
-
可扩展性:kafka集群支持热扩展;
-
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
-
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
-
高并发:支持数千个客户端同时读写;
-
支持实时在线处理和离线处理:可以使用Storm这种实时流处理系统对消息进行实时进行处理,同时还可以使用Hadoop这种批处理系统进行离线处理;
1.2 常用名词
1、消息生产者:即:Producer,是消息的产生的源头,负责生成消息并发送到Kafka服务器上。
2、消息消费者:即:Consumer,是消息的使用方,负责消费Kafka服务器上的消息。
3、主题:即:Topic,由用户定义并配置在Kafka服务器,用于建立生产者和消息者之间的订阅关系:生产者发送
消息到指定的Topic下,消息者从这个Topic下消费消息。
4、消息分区:即:Partition,一个Topic下面会分为很多分区,例如:“kafka-test”这个Topic下可以分为6个分
区,分别由两台服务器提供,那么通常可以配置为让每台服务器提供3个分区,假如服务器ID分别为0、1,则所有
的分区为0-0、0-1、0-2和1-0、1-1、1-2。Topic物理上的分组,一个 topic可以分为多个 partition,每partition
是一个有序的队列。partition中的每条消息都会被分配一个有序的 id(offset)。
5、Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为 broker。
6、消费者分组:Group,用于归组同类消费者,在Kafka中,多个消费者可以共同消费一个Topic下的消息,每个
消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。
7、Offset:消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文件中的偏移量,这个
偏移量就是所谓的Offset。
1.3 kafka结构图
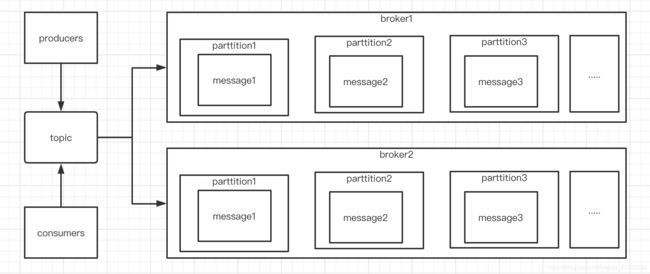
2. kafka安装及启动
2.1 采用homebrew的方式安装
brew install kafka
2.2 解除注释
-
执行命令: vi /usr/local/etc/kafka/server.properties
-
解除注释 #listeners=PLAINTEXT://your.host.name:9092 为
listeners=PLAINTEXT://localhost:9092(若无此则新增)
2.3 启动zookeeper 服务
- 进入到 cd /usr/local/Cellar/kafka/2.2.1/bin
执行命令: zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties &
(&:后台启动zk)
- 或者自己本机安装的zookeeper其他路径
2.4 启动kafka服务
- 进入到 cd /usr/local/Cellar/kafka/2.2.1/bin
执行命令: kafka-server-start /usr/local/etc/kafka/server.properties &
2.5 创建主题topic
执行命令(新开终端)
进入到 cd /usr/local/Cellar/kafka/2.2.1/bin
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic hello
查看已有主题的list
kafka-topics --list --zookeeper localhost:2181
2.6 创建生产者(输入内容生产消息由消费者获取)
执行命令(新开终端1):kafka-console-producer --topic hello --broker-list localhost:9092
2.7 创建消费者(读取生产者生产的消息内容)
执行命令(新开终端2):
kafka-console-consumer --bootstrap-server localhost:9092 -topic hello
3. SpringBoot+Kafka的实战
3.1 创建一个基本的springboot项目,并引入kafka依赖
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
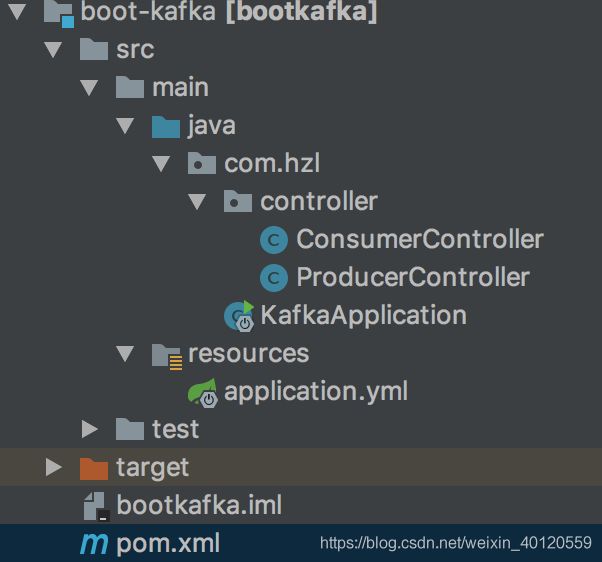
3.2 修改配置
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092 # kafka服务的server,可以配制成集群,集群搭建以逗号隔开
consumer:
group-id: springboot-kafka # 消费者组的id
auto-commit-interval: 200ms # 自动提交的间隔,默认5000ms
enable-auto-commit: true # 开启可以自动提交
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3.3 编写代码
生产者
package com.hzl.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @program: SpringBootExample
* @description
* @author: zhilin
* @create: 2020-07-04 17:01
**/
@RestController
public class ProducerController {
@Autowired
private KafkaTemplate kafkaTemplate;
@RequestMapping("send/{message}")
public String sendMessage(@PathVariable("message") String message) {
// 此处模拟消息入库
String topic = "test";
kafkaTemplate.send(topic, message);
System.out.println(message);
return "success " + message;
}
}
消费者
package com.hzl.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
/**
* @program: SpringBootExample
* @description
* @author: zhilin
* @create: 2020-07-04 17:06
**/
@Component
public class ConsumerController {
@Autowired
private KafkaTemplate kafkaTemplate;
@KafkaListener(topics = "test")
public void useMessage(String message) {
System.out.println(LocalDateTime.now().toString() + " === " + message);
}
}
未完待续