HashMap实例演示---key-value的类型
HashMap实例演示—key-value的类型
前言
对于HashMap的基础学习,相信网上已经有很多很详细的讲解,包括各种深入的源码的分析,各种拓展知识,以及各种和面试官的针锋相对。在这里,我不在进行源码的分析,而是直接用案例向大家演示一下HashMap的实现,让大家带着实际案例学习,我认为这是一个好的学习方式。
一.key为自定义对象,value为String类型
我们知道,HashMap是以key-value类型进行元素存储的集合,而集合里一般是存储对象的,所以我先以自定义对象作为key,String类型作为value进行演示。
注意:key不能是基本数据类型,如int、float、char等类型,因为key后面要使用到对象的方法,而基本数据类型是没有方法的,但基本数据类型可以包装成对象,如int被包装后为Integer,可以作为key。
既然key为自定义对象,那么首先先创建一个对象,我把它命名为People,大家应该都会,后面People的实例化对象将作为key。
直接贴代码:
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class People {
private String name;
private int age;
//定义构造函数
public People(String name,int age){
this.name=name;
this.age=age;
}
//定义getName函数返回类的name
public String getName(){
return name;
}
//定义setAge函数返回类的age
public void setAge(int age){
this.age = age;
}创建完People对象后,我们需要实例化两个对象p1,p2用来比较,然后既然是用HashMap来存储对象,那么也要实例化一个HashMap。
注意:使用HashMap时需要导入对应的包,否则报错
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
为了方便后面使用Map和Set可以一并写上。
实例化p1 p2和map:
public static void main(String[] args) {
Map<People,String>map=new HashMap<>();
People p1=new People("小明",18);
People p2=new People("小红",16);
System.out.println("P1的hashcode:"+p1.hashCode()+"p2的hashcode为:"+p2.hashCode());
map.put(p1,"学号1");
map.put(p2,"学号2");
System.out.println(map);
}因为value设为String,所谓我把value设为"学号1"和“学号2”,此时key就是创建的People对象的p1,其信息为小明,18和小红16。接下来使用put方法将对应的key-value存入HashMap。
这时,可能有人注意到了我获取了p1和p2的hashcode(即key的hashcode),那么hashcode有什么作用呢?
注意:在把key作为自定义对象给HashMap进行存储时,HashMap会进行去重操作,具体做法为:先计算key的hashcode然后和其他的进行比对,如果hashcode不等,直接认为是不同的对象,直接存储。若hashcode相等,则会用equals再进行对象内部信息比较,如果一样,才认为是同一个对象,不会存储,反之equals比对不等,就会存储,这里就说明了为何key不能是基本数据类型,因为基本数据类型没有hashcode和equals方法。
这个了解之后我们就先计算一下这两个key的hashcode,结果如下:

通过观察,这两个hashcode不等,仔细想想,确实,小明和小红两个不一样的人肯定不等,但,我们把这两个对象设为同一个人的信息,看看有什么变化:
Map<People,String>map=new HashMap<>();
People p1=new People("小明",18);
People p2=new People("小红",16);
People p3=new People("小明",18);
System.out.println("P1的hashcode:"+p1.hashCode()+"p2的hashcode为:"+p3.hashCode());创建了一个新的对象p3,其信息和p1一样,都是小明,18,那么他们的hashcode会相等吗?
结果:

发现p1和p3结果不同,那么按照上面的说法,hashcode不同则直接存储进HashMap。
注意:这里有两个问题需要着重注意:
1.我们仔细想一想这种是否符合实际,同一个人,由于前一分钟在教室,后一分钟到操场,难道就不是同一个人了吗?显然是不符合实际存储的要求的。
2.由结果可知,这种hashcode是没有实际意义的,同一个人都无法区分,那么我们还要它做什么呢?
重点:hashcode方法为Object类所拥有的方法,由c++实现,计算对象的地址的散列值并返回整数,所以,由于p1和p3对象地址不同,所以,其hashcode肯定不等,但我们又要使用hashcode的值分配到散列表中,方便数据比对,该怎么办呢?(hashcode的散列特性作用可以在其他文章了解)
对于Object类的hashcode我们是无法使用了,那么,我们需要重写hashcode,让它为我们所用(这部分面试官可能会询问你实际重写过hashcode吗),hashcode的写法有很多种,根据实际情况来写,这里,像String和Integer都已经重过hashcode,大家自行研究,因此我们来重写hashcode:
public int hashCode(){
final int h=31;
int result=1;
int namehashCode=name.hashCode();//String的hashcode
result=h*result+age;//类似于String的hashcode为h=31*h+ASCII
result=h*result+((name==null)?0:namehashCode);//类似的A?B:C 如果A为真则选B,否则选C,如果name==null为真就选0反之为namehashCode
return result;
}其中,People对象中的name在开始定义时为String,而String已经重写过hashcode,所以这里我们重写的hashcode,再用上String写过的hashcode,更加能提高hashcode的查询效率,减少遇到相同的hashcode,防止hash冲突。
具体的重写hashcode的方式请自行了解
重写过的hashcode运行结果:
 可以发现,此时p1和p3的hashcode一致,符合实际需求。
可以发现,此时p1和p3的hashcode一致,符合实际需求。
接着,我们需要使用equals方法比较这两个对象的内容是否相等。
注意:因为hashcode只是通过对象的信息计算出来对应的整型值,且有相同的hashcode的对象肯定不是一个,所以,我们还要对具体的内容进行比较,这里就使用equals方法。
System.out.println(p1.equals(p3));结果: 从结果看来,他们的equals比对不一致,那么就要存储了,但是p1和p3是同一个人,也不合理。
从结果看来,他们的equals比对不一致,那么就要存储了,但是p1和p3是同一个人,也不合理。
equals和hashcode一样,都是Object类自带的方法,其作用是比对两对象地址是否相等,这里p1和p3不是同一地址,所以不相等。
我们发现,equals也是比对地址的,肯定也不能用,我们实际是要比对的具体信息是否相等,比如两个name是否都叫小明,就是比对小明这两个字符串是否一致,以及是不是都是18,比对大小一致,这里,就需要重写equals了。
重写equals方法:
@Override
public boolean equals(Object obj) {
if(this==obj){
//判断此类对象和要比较的是不是同一个对象
return true;
}
else if (obj==null){
//如果对象是null,空的或不存在的对象
return false;
}
else if (getClass()!=obj.getClass()){
//判断返回的类的对象是否相等
return false;
}
People other=(People)obj;//将其他同类的不同对象赋值为本类型对象
if(age!= other.age){
//判断本类的age和其他同类对象age是否一致
return false;
}
if(name==null){
if(other.name!=null){
//其他同类的name是否存在
return false;
}
}else if (!name.equals(other.name)){
//判断本类的name和其他同类的name是否一致
return false;
}
return true;
}具体的重写方式就是判断两个对象的实际的数值或者字符串是否相等。
再次运行:

结果为true,实现了具体要求。
不同的情况其实equals的重写大体类似,需要将对象中的具体内容进行比对。
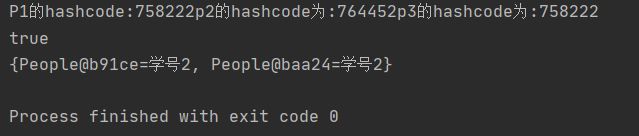
这时,我们将这两个对象放入HashMap中:
map.put(p1,"学号1");
map.put(p2,"学号2");
map.put(p3,"学号2");
System.out.println(map);结果:
修改一下输出:
public String toString(){
return "Person[name:"+name+",age="+age+"]";
}
这时,虽然定义了p3,但是它和p1是同一个人,只是由于成绩问题换了个学号,但实际只会存储一个对象,且如果已经存在了此对象,后面的会覆盖前面存的对象。
注意:开始放的p1,学号1,由于p3和p1是同一个人,只是学号变了,如果把p3放进去就会覆盖了p1,学号也就变为2,这点要注意
到此,以自定义对象,String类型的HashMap就演示到这。
二.key为自定义对象,value为自定义对象
最后再演示一下key-value都是自定义对象的形式
新增一个HashMap对象,类型为People,People,将两个对象put进去:
Map<People,People>map1=new HashMap<>();
map1.put(p1,p2);
map1.put(p2,p2);结果:

注意:HashMap中,不同的key可以有相同的value,但一般情况我们只存储不同的key,如果存储相同的key,会覆盖旧key的对象。
如put两个都是p1的key,加上put(p1,p1):
map1.put(p1,p2);
map1.put(p2,p2);
map1.put(p1,p1);结果:
 此时:原本第一次put(p1,p2)值为:
此时:原本第一次put(p1,p2)值为:
Person[name:小明,age=18]=Person[name:小红,age=16]
增加put(p1,p2)后,结果变为:
Person[name:小明,age=18]=Person[name:小明,age=18]
原本的数据已经不存在,所以相同的key会覆盖旧key的对象,造成数据遗失,相当危险。