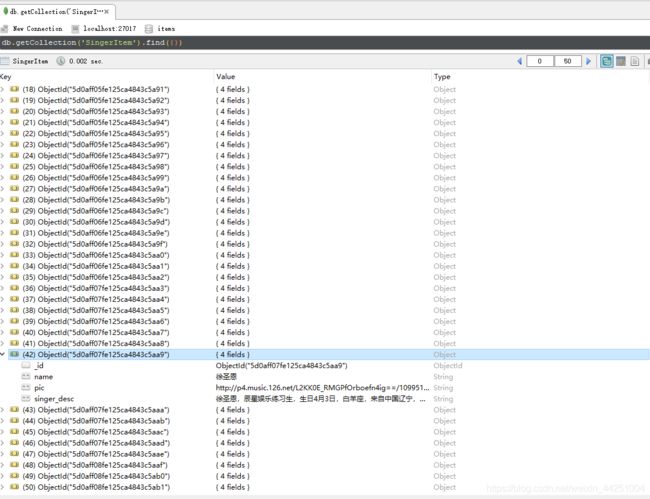
使用scrapy创建一个项目爬取网易云音乐的所有歌手的相关资料
1、创建一个项目
- scrapy startproject 项目名称
我的项目叫Neteasy_music,所以命令是scrapy startproject Neteasy_music2、创建一个爬虫
先把目录切换到项目里面
- cd 项目名称
- scrapy genspider 爬虫名字 网站地址
我这里取的名字是neteasy_music,爬取的网页是music.163.com/discover/artist,
所以命令是scrapy genspider neteasy_music music.163.com/discover/artist3、编写爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from Neteasy_music.items import SingerItem
class NeteasyMusicSpider(scrapy.Spider):
name = 'neteasy_music'
allowed_domains = ['music.163.com']
start_urls = ['https://music.163.com/discover/artist']
base_url = 'https://music.163.com'
def parse(self, response):
# 获取歌手分类链接:如华语男歌手、欧美女歌手的链接
singer_type_href = response.xpath('//a[@class="cat-flag"]/@href').extract()
del singer_type_href[0] # 删除推荐歌手
for url in singer_type_href:
full_url = self.base_url + url
# print(url)
yield Request(url=full_url, callback=self.parseDetail, encoding='utf-8')
def parseDetail(self, response):
# 获取按字母排序歌手名字的列表页链接
singer_initial_url = response.xpath('//ul[@id="initial-selector"]/li[position()>1]/a/@href').extract()
for url in singer_initial_url:
full_url = self.base_url + url
yield Request(url=full_url, callback=self.parseDetail1, encoding='utf-8')
def parseDetail1(self, response):
# 获取歌手的详情页的链接
singer_list_href = response.xpath('//div[@class="m-sgerlist"]/ul/li/div/a/@href').extract()
for url in singer_list_href:
full_url = self.base_url + url
yield Request(url=full_url, callback=self.parseDetail2, encoding='utf-8')
def parseDetail2(self, response):
item = SingerItem()
# 歌手姓名
item['name'] = response.xpath('//h2[@id="artist-name"]/text()').extract_first()
# 歌手图片
item['pic'] = response.xpath('//div[@class="n-artist f-cb"]/img/@src').extract_first()
# 获取歌手介绍连接
sing_desc_href = response.xpath('//ul[@id="m_tabs"]/li[last()]/a/@href').extract_first()
full_url = self.base_url + sing_desc_href
yield Request(url=full_url, callback=self.parseDetail3, encoding='utf-8', meta={'data': item})
def parseDetail3(self, response):
item = response.meta['data']
# 歌手简介
singer_desc = response.xpath('//div[@class="n-artdesc"]/p/text()').extract_first()
try:
item['singer_desc'] = singer_desc
except:
item['singer_desc'] = ''
# print(item)
yield item
4、编写字段文件
import scrapy
class SingerItem(scrapy.Item):
# define the fields for your item here like:
#歌手名字
name = scrapy.Field()
# 歌手图片
pic = scrapy.Field()
# 歌手简介
singer_desc = scrapy.Field()
5、编写保存到数据库的文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
class NeteasyMusicPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
# from_crawler用于实例化某个对象(中间件,模块),常常出现在对象的初始化,负责提供crawler.settings
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
# 当spider被开启时,这个方法被调用
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
# 当spider被关闭时,这个方法被调用
def close_spider(self, spider):
self.client.close()
# '''
# 每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的item将不会被之后的pipeline组件所处理。
#
# 参数:
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
#
# '''
def process_item(self, item, spider):
collection_name = item.__class__.__name__
self.db[collection_name].insert(dict(item))
return item
6、修改设置文件

上图是设置user_agent,还有爬虫协议,这里是选择不遵守

上图是设置request_headers

上图是设置item_pipelines,作用是调用之前写的保存到数据库的文件
7、启动爬虫

编写main文件可以不用在命令行中输入
from scrapy import cmdline
cmdline.execute('scrapy crawl neteasy_music --nolog'.split())
然后启动它,run 'main'
或者在命令行中,把路径切换到项目路径,然后输入
scrapy crawl neteasy_music这个代码就是启动爬虫了,如果后面加上--nolog就是运行时不输出日志。
启动并运行完成之后,在数据库中就可以看到这些数据了