用了这么久Python,这些好玩又实用的库竟然不知道
在之前文章中有过介绍,Python之所以简单、高效,是因为它具有丰富的函数,可以拿来即用。最近在看一些Github的技术文章,发现了一些好玩又实用的Python库,有一种相见恨晚的感觉。今天将这些库整理一下,分享给大家。
pandas_profiling
做数据分析前需要先看一下数据的总体概况,pandas_profiling工具可以快速预览数据,对于数据整体概括和数据质量可以有一个清晰的认识,对于做数据非常有帮助。一份详细的数据报告,可以为我们节省大量时间(少敲代码),还不赶紧用起来。
1.安装
pip install pandas-profiling
2.整体数据预览
import pandas as pd
import pandas_profiling
data = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
data.describe()
pandas_profiling.ProfileReport(data)
3.数据分析报告
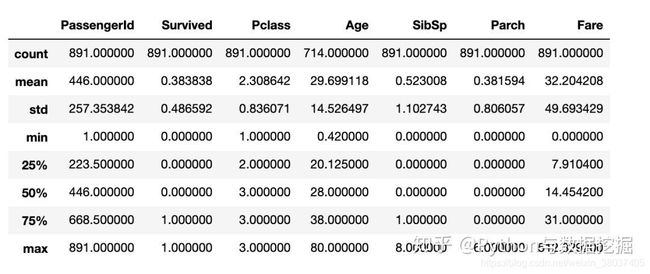
PyOD
数据探索没有捷径可走。如果你跳过数据科学阶段,直接进入到构建模型阶段,经过一段时间后,你会发现准确度会达到上限,即模型的性能不会提高。这是因为异常值(也称为“离散值”)这个经常被我们忽略的问题。
在之前文章干货分享|数据领域的小伙伴,异常检测这一篇就够了中,已经分享了一些异常检测的算法,最近发现了PyOD库,PyOD是一个用于检测数据中异常值的库,它能对20多种不同的算法进行访问,以检测异常值,并能够与Python 2和3兼容,使用起来也比较方便。
1.安装
pip install pyod # normal install
pip install --upgrade pyod # or update if needed
pip install --pre pyod # or include pre-release version for new features
2.举例说明
from __future__ import division
from __future__ import print_function
import os
import sys
# temporary solution for relative imports in case pyod is not installed
# if pyod is installed, no need to use the following line
sys.path.append(
os.path.abspath(os.path.join(os.path.dirname("__file__"), '..')))
from pyod.models.lof import LOF
from pyod.utils.data import generate_data
from pyod.utils.data import evaluate_print
from pyod.utils.example import visualize
if __name__ == "__main__":
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
# Generate sample data
X_train, y_train, X_test, y_test = \
generate_data(n_train=n_train,
n_test=n_test,
n_features=2,
contamination=contamination,
random_state=42)
# train LOF detector
clf_name = 'LOF'
clf = LOF()
clf.fit(X_train)
# get the prediction labels and outlier scores of the training data
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
# get the prediction on the test data
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
# visualize the results
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=False)
tushare
Tushare是一个免费、开源的python财经数据接口包。主要实现对股票等金融数据从数据采集、清洗加工 到 数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据,为他们在数据获取方面极大地减轻工作量,使他们更加专注于策略和模型的研究与实现上。考虑到Python pandas包在金融量化分析中体现出的优势,Tushare返回的绝大部分的数据格式都是pandas DataFrame类型,非常便于用pandas/NumPy/Matplotlib进行数据分析和可视化。
对于正在学习利用python进行数据分析的人来说,可以提供一个公开数据集,此外该数据库提供即时新闻,实时票房数据,是一个进行数据练手不错的地方。
1.获取数据
import tushare as ts
#一次性获取最近一个日交易日所有股票的交易数据
ts.get_today_all()
#新闻数据
ts.get_notices()
2.数据展示
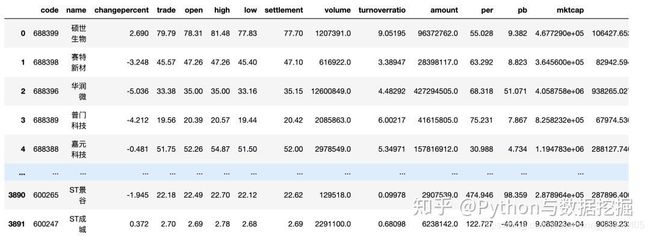
Wget
从网络上提取数据是数据科学家的重要任务之一。Wget 是一个免费的实用程序,可以用于从网络上下载非交互式的文件。它支持 HTTP、HTTPS 和 FTP 协议,以及通过 HTTP 的代理进行文件检索。由于它是非交互式的,即使用户没有登录,它也可以在后台工作。所以下次当你想要下载一个网站或者一个页面上的所有图片时,wget 可以帮助你。
1.安装
pip install wget
2.例子
import wget
url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
filename = wget.download(url)
100% [................................................] 3841532 / 3841532 filename razorback.mp3
imbalanced-learn
在模型训练中,如何处理数据不平衡问题,一直都困扰绕者数据挖掘工程师,imbalanced-learn给你解决了。imblearn提供SMOTEENN方法解决数据平衡处理,为此需要下载对应的包imblearn。
1.安装
pip install imblearn
2.用法
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.decomposition import PCA
import numpy as np
import pandas as pd
from imblearn.combine import SMOTEENN
# Generate the dataset
X, y = make_classification(n_classes=2, class_sep=2, weights=[0.1, 0.9],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=100, random_state=10)
sm = SMOTEENN()
X_resampled, y_resampled = sm.fit_sample(X, y)
print(y_resampled)
print(y_resampled.shape)
smtplib
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。python的smtplib提供了一种很方便的途径发送电子邮件。它对smtp协议进行了简单的封装。
Python的SMTP库、前端技术、数据库相结合,每周一些常规性数据分析报告以自动化邮件去发送,省时省力,提高做事效率。
Python创建 SMTP 对象语法如下:
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )
示例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import smtplib
from email.mime.text import MIMEText
from email.header import Header
sender = '********'
receivers = ['********'] # 接收邮箱
message = MIMEText('Python 邮件发送测试...', 'plain', 'utf-8')
message['From'] = Header("Python学习与数据挖掘", 'utf-8') # 发送者
message['To'] = Header("测试", 'utf-8') # 接收者
subject = 'Python SMTP 邮件测试'
message['Subject'] = Header(subject, 'utf-8')
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message.as_string())
print "邮件发送成功"
except smtplib.SMTPException:
print "Error: 无法发送邮件"
youtube-dl
你还在为无法下载网站视频烦恼吗?试试youtube-dl,统统帮你搞定,今天分享介绍这个强大的命令行下载神器,看名字以为是不是专门下载youtube网站视频的工具,其实不然,它支持超过全世界好几百个网站的视频下载,或许可能是国内有墙的因素,youtube-dl对墙外的那些不存在的网站支持的会相对好一些。
1.安装
pip install youtube-dl #安装
pip install --upgrade youtube-dl #升级
2.使用方法
[root@bear ~]# youtube-dl --max-quality url http://www.youtube.com/watch?v=XXXXXX
[root@bear ~]# youtube-dl --max-quality url http://v.youku.com/v_show/id_XXXXXX.html
[root@bear ~]# youtube-dl --list-extractors #查看支持网站列表
[root@bear ~]# youtube-dl -U #程序升级
更多精彩内容,关注微信公众号『Python学习与数据挖掘』
为方便技术交流,本号开通了技术交流群,有问题咨询小助手微信:connect_we,备注:CSDN,欢迎转载,收藏,码字不易,喜欢小编就点赞一下!
