基于Yolov3的口罩识别
文章目录
- 基于Yolov3的口罩识别
-
- 1、项目简介
- 2、参考资料
- 3、硬件软件信息
- 4、项目文件信息
- 5、项目教程
-
- 5.1环境配置
- 5.2验证环境是否配置正确
-
- 5.2.1 Python版本:打开Command
- 5.2.2 TensorFlow Keras版本
- 5.2.3 CUDA版本
- 5.3下载数据集
- 5.4安装Labelimg
- 5.5使用Labelimg给图片打标签
- 5.6生成训练相关文件
- 5.7给训练集添加路径地址
- 5.8权重转换
- 5.9修改yolo模型参数
- 5.10训练
- 5.11调用OpenCV进行实时监测
- 6.联系方式
- 7.权重文件链接
基于Yolov3的口罩识别
1、项目简介
本项目是基于YoloV3,使用Keras进行口罩识别。
该项目源代码已全部上传至GitHub
https://github.com/Rodeson/MaskIdentification
2、参考资料
DataSet:
https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset
Blogs:
https://blog.csdn.net/qinchang1/article/details/89608058
https://blog.csdn.net/cungudafa/article/details/105074825
Weights:
https://github.com/MacwinWin/face_mask_dataset
3、硬件软件信息
Software:
TensorFlow-GPU 2.3.0
Keras 2.4.3
CUDA 11.0
Python 3.7.4
Hardware:
GPU NVIDIA GeForce GTX 1050(4G)
CPU Inter® Core™ i7-8750H CPU @ 2.20GHz
4、项目文件信息
1.项目名称:MaskIdentification
2.文件夹简介:
Annotation:存放标签,因为文件太大,打包时已删除
ImageSets:存放训练集 测试集图片名称
JPEGImages:存放图片文件 因为文件太大 打包时已删除
LOG:存放权重文件
yolo3:存放yolo模型
model_data:存放yolo模型配置文件
3.文件说明
convert.py 将.weight文件转为.h5文件
makeTxt.py随机生成训练集 测试集编号
voc_label.py将训练集路径信息与标签链接
yolo.py yolo设定模型参数,路径
yolo_video.py调用摄像头进行测试
4.程序运行方式
使用终端打开该文件夹,并运行 pyhton yolo_video.py 等待片刻即可。
5、项目教程
5.1环境配置
参考链接https://blog.csdn.net/gangeqian2/article/details/79358543
5.2验证环境是否配置正确
5.2.1 Python版本:打开Command
python
理论输出
Python 3.7.4 (default, Aug 9 2019, 18:34:13) [MSC v.1915 64 bit (AMD64)] :: Anaconda, Inc. on win32
5.2.2 TensorFlow Keras版本
cmd >python
>>> import tensorflow as tf
2020-11-28 00:07:06.379481: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cudart64_101.dll
>>> tf.__version__
'2.3.0'
>>> import keras as K
>>> K.__version__
'2.4.3'
可以看到TensorFlow版本为2.3.0 Keras版本为2.4.3
5.2.3 CUDA版本
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Wed_Jul_22_19:09:35_Pacific_Daylight_Time_2020
Cuda compilation tools, release 11.0, V11.0.221
Build cuda_11.0_bu.relgpu_drvr445TC445_37.28845127_0
可以看到CUDA版本为11.0
5.3下载数据集
本项目使用的数据集为武汉大学开源口罩数据集
https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset
吐槽:该数据集没有标签,并且分类混乱,建议下载后自己手动标签
5.4安装Labelimg
https://blog.csdn.net/zong596568821xp/article/details/80395079
总结 在终端输入以下命令
pip install PyQt5
输出以下内容(笔者已安装所以为already satisfied)
Requirement already satisfied: PyQt5 in d:\anaconda\anaconda3\lib\site-packages (5.15.1)
Requirement already satisfied: PyQt5-sip<13,>=12.8 in d:\anaconda\anaconda3\lib\site-packages (from PyQt5) (12.8.1)
输入以下命令安装tools
pip install pyqt5-tools
输出以下内容(笔者为已安装输出)
Requirement already satisfied: pyqt5-tools in d:\anaconda\anaconda3\lib\site-packages (5.15.1.1.7.5)
Requirement already satisfied: click in d:\anaconda\anaconda3\lib\site-packages (from pyqt5-tools) (7.0)
Requirement already satisfied: python-dotenv in d:\anaconda\anaconda3\lib\site-packages (from pyqt5-tools) (0.14.0)
Requirement already satisfied: pyqt5==5.15.1 in d:\anaconda\anaconda3\lib\site-packages (from pyqt5-tools) (5.15.1)
Requirement already satisfied: PyQt5-sip<13,>=12.8 in d:\anaconda\anaconda3\lib\site-packages (from pyqt5==5.15.1->pyqt5-tools) (12.8.1)
输入以下内容安装labelimg
pip install labelimg
输出以下内容(笔者为已安装输出)
Requirement already satisfied: labelimg in d:\anaconda\anaconda3\lib\site-packages (1.8.3)
Requirement already satisfied: lxml in d:\anaconda\anaconda3\lib\site-packages (from labelimg) (4.4.1)
Requirement already satisfied: pyqt5 in d:\anaconda\anaconda3\lib\site-packages (from labelimg) (5.15.1)
Requirement already satisfied: PyQt5-sip<13,>=12.8 in d:\anaconda\anaconda3\lib\site-packages (from pyqt5->labelimg) (12.8.1)
5.5使用Labelimg给图片打标签
终端打开Labelimg(CMD)
>labelimg
以下为标签工作截图
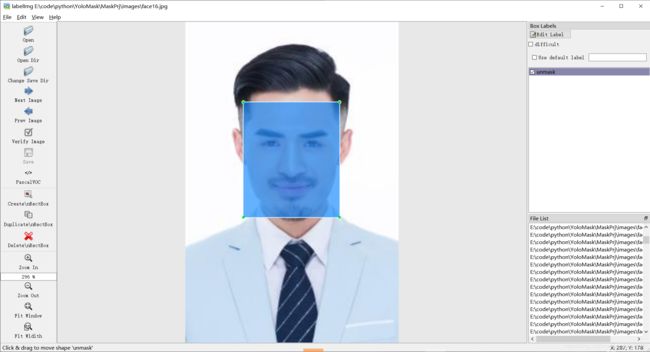
5.6生成训练相关文件
运行该项目文件夹下的makeTxt.py
得到以下四个文件
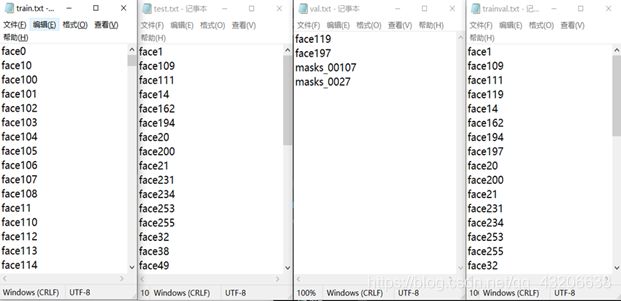
5.7给训练集添加路径地址
运行该项目文件夹下的voc_label.py
得到以下文件
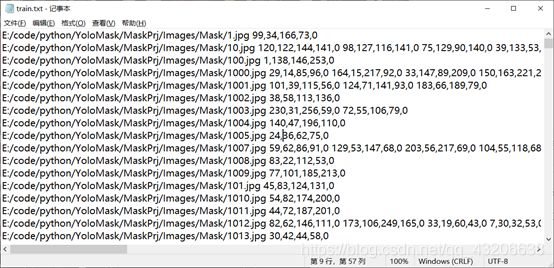
5.8权重转换
因为.weight文件为DarkNet使用格式 需要转换为Keras适用格式.h5
运行该项目文件夹下的convert.py
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
5.9修改yolo模型参数
打开本项目文件夹下的LOG>yolov3.cfg文件
修改yolo以下信息
c l a s s = 2 class = 2 class=2
f i l t e r s = 7 × ( c l a s s + 1 ) = 7 × 3 = 21 filters = 7\times(class +1) = 7\times3 = 21 filters=7×(class+1)=7×3=21
5.10训练
训练前修改model_data文件夹下的voc_classes.txt 改为自己的标签名称
python train.py
漫长等待 可以去睡一觉
根据自己显卡显存大小设置合适的batch_size值,否则训练一半显存会溢出。
5.11调用OpenCV进行实时监测
需要提前修改yolo.py 内路径信息
pyhton yolo_video.py
效果图展示
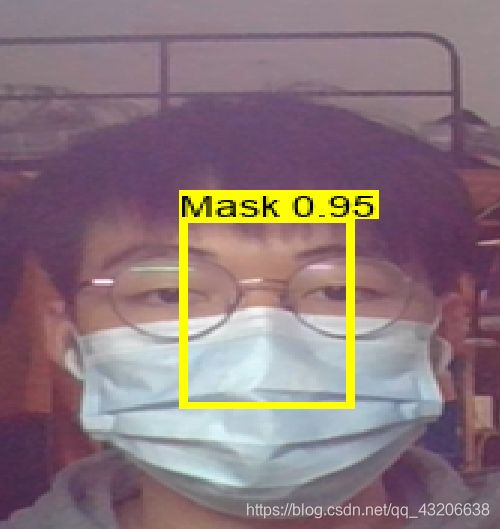
6.联系方式
如果你在进行该口罩识别项目过程中遇到问题请邮件联系我。
Subject:MaskIdentificationCSDN
Email Address:[email protected]
7.权重文件链接
本项目训练好的权重文件已上传至百度云盘(Github单个文件上限100M)
链接:https://pan.baidu.com/s/1GNeG3sIZoEvrx7KPn0xbCw vdl5