Greenplum Python专用库gppylib学习——GpArray
gparray.py依赖的python包(datetime、copy、traceback、os),依赖的gp包(gplog、utils、db、gpversion、commands.unix)
from datetime import date
import copy
import traceback
from gppylib.utils import checkNotNone, checkIsInt
from gppylib import gplog
from gppylib.db import dbconn
from gppylib.gpversion import GpVersion
from gppylib.commands.unix import *
import os
代码分析
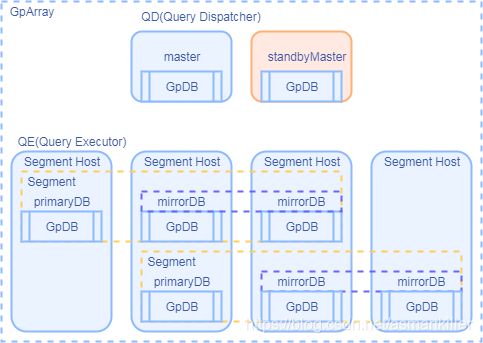
QD(Query Dispatcher)包含master和standby master,QE(Query Executor)包含primary和mirror。每个posgres数据库的信息使用GpDB对象表示。Segment对象代表primaryDB和其对应的零个、一个或多个mirrorDB。GpArray对象就是master、standbyMaster和多个Segmnet对象的组合。
GpDB类
GpDB类是单个dbid所指的postgres数据库实例的配置信息。其余成员都可以很好地理解,这里说说__filespaces成员是存放key为数据库对象oid,value为其数据库对象的文件目录路径的字典。因此GpDB类构造函数的datadir是SYSTEM_FILESPACE(oid为3052)所处的文件路径。
class GpDB:
def __init__(self, content, preferred_role, dbid, role, mode, status, hostname, address, port, datadir, replicationPort):
self.content=content
self.preferred_role=preferred_role
self.dbid=dbid
self.role=role
self.mode=mode
self.status=status
self.hostname=hostname
self.address=address
self.port=port
self.datadir=datadir
self.replicationPort=replicationPort
# Filespace mappings for this segment
self.__filespaces = {
SYSTEM_FILESPACE: datadir } # SYSTEM_FILESPACE oid of the system filespace 3052
# Pending filespace creation
self.__pending_filespace = None
# Catalog directory for each database in this segment
self.catdirs = None
# Todo: Remove old dead code
self.valid = (status == 'u')
def __str__(self): # 构造GpDB类可打印的字符串表示
def __repr__(self):
fsOids = [oid for oid in self.__filespaces] # 取出__filespaces中所有的key,及数据库对象对应的oid
fsOids.sort() # sort for determinism
filespaces = []
for fsoid in fsOids:
if fsoid not in [SYSTEM_FILESPACE]:
filespaces.append("%d:%s" % (fsoid, self.__filespaces[fsoid])) # 以oid:datadir字符串为item,放入filespaces
return '%d|%d|%s|%s|%s|%s|%s|%s|%d|%s|%s|%s|%s' % (self.dbid,self.content,self.role,self.preferred_role,self.mode,self.status,self.hostname,self.address,self.port,self.replicationPort,self.datadir,','.join(filespaces),','.join(self.catdirs) if self.catdirs else [])
def __cmp__(self,other): # 使用__reper__函数序列化GpDB对象,并进行比较
def equalIgnoringModeAndStatusAndReplicationPort(self, other): # 如果核心属性(比如filespace)都相同则返回true,该方法在updateSystemConfig函数调用(在移除mirror segment或再添加mirror segmnet时会造成catalog改变)
def copy(self):
def isSegmentQD(self):
def isSegmentMaster(self, current_role=False):
...
def isSegmentModeInResynchronization(self):
def getSegmentDbId(self):
def getSegmentContentId(self):
...
def getSegmentFilespaces(self):
def setSegmentDbId(self, dbId):
def setSegmentContentId(self, contentId):
...
def setSegmentDataDirectory(self, dataDirectory):
def addSegmentFilespace(self, oid, path):
def getSegmentPendingFilespace(self):
@staticmethod
def getDataDirPrefix(datadir):
retValue = ""
retValue = datadir[:datadir.rfind('/')]
return retValue
成员变量createTemplate函数创建GpDB的信息的模板,第一步确保dstDir有足够的空间存放segment和其filespace(通过fillespaces中存放的oid和dirpath,查询各数据库对象所对应的空间占用大小);第二步获取磁盘空闲空间(DiskFree.get_size_local(name = "Check for available free space for segment template", directory = dstDir));第三步使用LocalDirCopy类对象将segment数据目录拷贝到目标目录dstDir;第四步先判别__filespaces中除了SYSTEM_FILESPACE(oid为3052)之外是否还有其他数据库对象,如果有,先判别dstDir + "/fs_directory"目录是否存在,不断将fillespaces中存放的dirpath中的目录在目标路径进行创建,数据库对象文件进行拷贝;第五步,删除目标路径下的gp_dbid文件(dstDir + ‘/gp_dbid’),对dstDir设置0700权限。
def createTemplate(self, dstDir):
# Make sure we have enough room in the dstDir to fit the segment and its filespaces.
duCmd = DiskUsage(name = "srcDir", directory = dstDir)
duCmd.run(validateAfter=True)
requiredSize = duCmd.get_bytes_used()
name = "segcopy filespace get_size"
for oid in self.__filespaces:
if oid == SYSTEM_FILESPACE:
continue
dir = self.__filespaces[oid]
duCmd = DiskUsage(name, dir)
duCmd.run(validateAfter=True)
size = duCmd.get_bytes_used()
requiredSize = requiredSize + size
dstBytesAvail = DiskFree.get_size_local(name = "Check for available free space for segment template", directory = dstDir)
if dstBytesAvail <= requiredSize:
raise Exception("Not enough space on directory: '%s'. Currently %d bytes free but need %d bytes." % (dstDir, int(dstBytesAvail), int(requiredSize)))
logger.info("Starting copy of segment dbid %d to location %s" % (int(self.getSegmentDbId()), dstDir))
cpCmd = LocalDirCopy("Copy system data directory", self.getSegmentDataDirectory(), dstDir)
cpCmd.run(validateAfter = True)
res = cpCmd.get_results()
if len(self.__filespaces) > 1:
""" Make directory to hold file spaces """
fullPathFsDir = dstDir + "/" + DESTINATION_FILE_SPACES_DIRECTORY # DESTINATION_FILE_SPACES_DIRECTORY = "fs_directory"
cmd = FileDirExists( name = "check for existance of template filespace directory", directory = fullPathFsDir)
cmd.run(validateAfter = True)
MakeDirectory.local("gpexpand make directory to hold file spaces", fullPathFsDir)
for oid in self.__filespaces:
MakeDirectory.local("gpexpand make directory to hold file space oid: " + str(oid), fullPathFsDir)
dir = self.__filespaces[oid]
destDir = fullPathFsDir + "/" + str(oid)
MakeDirectory.local("gpexpand make directory to hold file space: " + destDir, destDir)
name = "GpSegCopy %s to %s" % (dir, destDir)
cpCmd = LocalDirCopy(name, dir, destDir)
cpCmd.run(validateAfter = True)
res = cpCmd.get_results()
# Remove the gp_dbid file from the data dir
RemoveFile.local('Remove gp_dbid file', os.path.normpath(dstDir + '/gp_dbid'))
logger.info("Cleaning up catalog for schema only copy on destination")
# We need 700 permissions or postgres won't start
Chmod.local('set template permissions', dstDir, '0700')
静态成员函数initFromString(s)为工厂函数,从字符串中初始化GpDB对象,该字符串和repr()输出兼容。
@staticmethod
def initFromString(s):
tup = s.strip().split('|')
# Old format: 8 fields Todo: remove the need for this, or rework it to be cleaner
if len(tup) == 8:
# This describes the gp_configuration catalog (pre 3.4)
content = int(tup[0])
...
datadir = tup[7]
# Calculate new fields from old ones
# Note: this should be kept in sync with the code in
# GpArray.InitFromCatalog() code for initializing old catalog
# formats.
preferred_role = ROLE_PRIMARY if definedprimary else ROLE_MIRROR
role = ROLE_PRIMARY if isprimary else ROLE_MIRROR
hostname = None
mode = MODE_SYNCHRONIZED # ???
status = STATUS_UP if valid else STATUS_DOWN
replicationPort = None
filespaces = ""
catdirs = ""
# Catalog 3.4 format: 12 fields
elif len(tup) == 12:
# This describes the gp_segment_configuration catalog (3.4)
dbid = int(tup[0])
...
catdirs = ""
# Catalog 4.0+: 13 fields
elif len(tup) == 13:
# This describes the gp_segment_configuration catalog (3.4+)
dbid = int(tup[0])
...
catdirs = tup[12]
else:
raise Exception("GpDB unknown input format: %s" % s)
# Initialize segment without filespace information
gpdb = GpDB(content=content,preferred_role=preferred_role,dbid=dbid,role=role,mode=mode,status=status,hostname=hostname,address=address,port=port,datadir=datadir,replicationPort=replicationPort)
# Add in filespace information, if present
for fs in filespaces.split(","):
if fs == "":
continue
(fsoid, fselocation) = fs.split(":")
gpdb.addSegmentFilespace(fsoid, fselocation)
# Add Catalog Dir, if present
gpdb.catdirs = []
for d in catdirs.split(","):
if d == "":
continue
gpdb.catdirs.append(d)
# Return the completed segment
return gpdb
Segment类
Segment类代表相同contentID的SegmentDBs,目前至多一个primary SegDB和单个mirror SegDB,在后续版本中会支持多mirror SegDB。
class Segment:
primaryDB=None #primary (GpDB实例)
mirrorDBs =None
def __init__(self):
self.mirrorDBs = [] #mirror (GpDB实例)
pass
def addPrimary(self,segDB) #设置primary
def addMirror(self,segDB) #追加mirror
def get_dbs(self) #返回Primary和Mirror实例组成的列表(GpDB实例列表)
def get_hosts(self) #返回Primary和Mirror所在主机的主机名的列表
def is_segment_pair_valid(self):
"""Validates that the primary/mirror pair are in a valid state"""
for mirror_db in self.mirrorDBs:
prim_status = self.primaryDB.getSegmentStatus()
prim_mode = self.primaryDB.getSegmentMode()
mirror_status = mirror_db.getSegmentStatus()
mirror_role = mirror_db.getSegmentMode()
if (prim_status, prim_mode, mirror_status, mirror_role) not in VALID_SEGMENT_STATES:
return False
return True
primary和mirror对的合法状态如下,各个字段含义如下:primaryDB.getSegmentStatus、primaryDB.getSegmentMode、mirror_db.getSegmentStatus、mirror_db.getSegmentMode。
VALID_SEGMENT_STATES = [
(STATUS_UP, MODE_CHANGELOGGING, STATUS_DOWN, MODE_SYNCHRONIZED),
(STATUS_UP, MODE_CHANGELOGGING, STATUS_DOWN, MODE_RESYNCHRONIZATION),
(STATUS_UP, MODE_RESYNCHRONIZATION, STATUS_UP, MODE_RESYNCHRONIZATION),
(STATUS_UP, MODE_SYNCHRONIZED, STATUS_UP, MODE_SYNCHRONIZED)
]
- primaryDB状态为up,模式为CHANGELOGGING,mirrorDB状态为down,模式可以为SYNCHRONIZED、RESYNCHRONIZATION
- primaryDB状态为up,模式为RESYNCHRONIZATION,mirrorDB状态为up,模式为RESYNCHRONIZATION
- primaryDB状态为up,模式为SYNCHRONIZED,mirrorDB状态为up,模式为SYNCHRONIZED
如果要返回primaryDB的主机名,可使用segment1.primaryDB.getSegmentHostName()。
GpArray类
GpArray类构造函数接受包含QD和QE的GpDB的列表segments,
class GpArray:
def __init__(self, segments, segmentsAsLoadedFromDb=None, strategyLoadedFromDb=None):
self.master =None #GpDB实例
self.standbyMaster = None #GpDB实例
self.segments = [] #Segment实例列表
self.expansionSegments=[]
self.numPrimarySegments = 0
self.recoveredSegmentDbids = []
self.__version = None
self.__segmentsAsLoadedFromDb = segmentsAsLoadedFromDb
self.__strategyLoadedFromDb = strategyLoadedFromDb
self.__strategy = FAULT_STRATEGY_NONE # FAULT_STRATEGY_NONE = 'n' # mirrorless systems 无mirror系统
self.setFilespaces([])
for segdb in segments:
# Handle QD nodes # 处理QD节点
if segdb.isSegmentMaster(True):
if self.master != None:
logger.error("multiple master dbs defined")
raise Exception("GpArray - multiple master dbs defined")
self.master = segdb
elif segdb.isSegmentStandby(True):
if self.standbyMaster != None:
logger.error("multiple standby master dbs defined")
raise Exception("GpArray - multiple standby master dbs defined")
self.standbyMaster = segdb
# Handle regular segments # 处理QE节点
elif segdb.isSegmentQE():
if segdb.isSegmentMirror():
self.__strategy = FAULT_STRATEGY_FILE_REPLICATION # FAULT_STRATEGY_FILE_REPLICATION = 'f' # valid for versions 4.0+ # 有mirror节点
self.addSegmentDb(segdb)
else:
# Not a master, standbymaster, primary, or mirror?
# shouldn't even be possible.
logger.error("FATAL - invalid dbs defined")
raise Exception("Error: GpArray() - invalid dbs defined")
# Make sure we have a master db
if self.master is None:
logger.error("FATAL - no master dbs defined!")
raise Exception("Error: GpArray() - no master dbs defined")
def __str__(self):
def hasStandbyMaster(self):
def addSegmentDb(self, segdb): # segdb是GpDB实例,向self.segments中加入新的segment或向原有的segment对象添加GpDB实例(addPrimary或addMirror)
def isStandardArray(self):
def is_array_valid(self):
def dumpToFile(self, filename):
def setFaultStrategy(self, strategy):
def getFaultStrategy(self):
....
initFromCatalog从数据库中获取GpArray对象的数据成员的数据,形参为数据库URL,设置utility模式。主要是一些查找数据库状态信息的SQL,作为DBA需要收集学习这些SQL,以备后续学习运维使用。
@staticmethod
def initFromCatalog(dbURL, utility=False):
conn = dbconn.connect(dbURL, utility)
# Get the version from the database:
version_str = None
for row in dbconn.execSQL(conn, "SELECT version()"):
version_str = row[0]
version = GpVersion(version_str)
if version.getVersionRelease() in ("3.0", "3.1", "3.2", "3.3"):
# In older releases we get the fault strategy using the
# gp_fault_action guc.
strategy_rows = dbconn.execSQL(conn, "show gp_fault_action")
# Note: Mode may not be "right", certainly 4.0 concepts of mirroring
# mode do not apply to 3.x, so it depends on how the scripts are
# making use of mode. For now it is initialized to synchronized.
#
# Note: hostname is initialized to null since the catalog does not
# contain this information. Initializing a hostcache using the
# resulting gparray will automatically fill in a value for hostname.
#
# Note: this should be kept in sync with the code in
# GpDB.InitFromString() code for initializing old catalog formats.
config_rows = dbconn.execSQL(conn, '''
SELECT dbid, content,case when isprimary then 'p' else 'm' end as role,
case when definedprimary then 'p' else 'm' end as preferred_role,
's' as mode,case when valid then 'u' else 'd' end as status,
null as hostname,hostname as address,port,null as replication_port,
%s as fsoid,datadir as fselocation FROM pg_catalog.gp_configuration
ORDER BY content, preferred_role DESC
''' % str(SYSTEM_FILESPACE))
# no filespace support in older releases.
filespaceArr = []
else:
strategy_rows = dbconn.execSQL(conn, '''
SELECT fault_strategy FROM gp_fault_strategy
''')
config_rows = dbconn.execSQL(conn, '''
SELECT dbid, content, role, preferred_role, mode, status,
hostname, address, port, replication_port, fs.oid,
fselocation
FROM pg_catalog.gp_segment_configuration
JOIN pg_catalog.pg_filespace_entry on (dbid = fsedbid)
JOIN pg_catalog.pg_filespace fs on (fsefsoid = fs.oid)
ORDER BY content, preferred_role DESC, fs.oid
''')
filespaceRows = dbconn.execSQL(conn, '''
SELECT oid, fsname FROM pg_filespace ORDER BY fsname;
''')
filespaceArr = [GpFilespaceObj(fsRow[0], fsRow[1]) for fsRow in filespaceRows]
# Todo: add checks that all segments should have the same filespaces?
recoveredSegmentDbids = []
segments = []
seg = None
for row in config_rows:
# Extract fields from the row
(dbid, content, role, preferred_role, mode, status, hostname,
address, port, replicationPort, fsoid, fslocation) = row
# If we have segments which have recovered, record them.
if preferred_role != role and content >= 0:
if mode == MODE_SYNCHRONIZED and status == STATUS_UP:
recoveredSegmentDbids.append(dbid)
# The query returns all the filespaces for a segment on separate
# rows. If this row is the same dbid as the previous row simply
# add this filespace to the existing list, otherwise create a
# new segment.
if seg and seg.getSegmentDbId() == dbid:
seg.addSegmentFilespace(fsoid, fslocation)
else:
seg = GpDB(content, preferred_role, dbid, role, mode, status,
hostname, address, port, fslocation, replicationPort)
segments.append(seg)
datcatloc = dbconn.execSQL(conn, '''
select fsloc.dbid, fsloc.fselocation || '/' || case when db.dattablespace = 1663
then 'base' else db.dattablespace::text end || '/'||db.oid as catloc
from pg_Database db, pg_tablespace ts,
(SELECT dbid, fs.oid, fselocation
FROM pg_catalog.gp_segment_configuration
JOIN pg_catalog.pg_filespace_entry on (dbid = fsedbid)
JOIN pg_catalog.pg_filespace fs on (fsefsoid = fs.oid)) fsloc
where db.dattablespace = ts.oid
and ts.spcfsoid = fsloc.oid''')
conn.close()
catlocmap = {
}
for row in datcatloc:
if catlocmap.has_key(row[0]):
catlocmap[row[0]].append(row[1])
else:
catlocmap[row[0]] = [row[1]]
for seg in segments:
seg.catdirs = catlocmap[seg.dbid]
origSegments = [seg.copy() for seg in segments]
if strategy_rows.rowcount == 0:
raise Exception("Database does not contain gp_fault_strategy entry")
if strategy_rows.rowcount > 1:
raise Exception("Database has too many gp_fault_strategy entries")
strategy = strategy_rows.fetchone()[0]
array = GpArray(segments, origSegments, strategy)
array.__version = version
array.recoveredSegmentDbids = recoveredSegmentDbids
array.setFaultStrategy(strategy) # override the preliminary default `__strategy` with the database state, if available
array.setFilespaces(filespaceArr)
return array
initFromFile函数从文件中读取GpArray的信息,通过GpDB的initFromString函数,并使用GpArray构造函数创建GpArray对象。
@staticmethod
def initFromFile(filename):
segdbs=[]
fp = open(filename, 'r')
for line in fp:
segdbs.append(GpDB.initFromString(line))
fp.close()
return GpArray(segdbs)
使用
通过gppylib的system文件夹下提供的configurationInterface接口,注册配置Provider,并初始化Provider,通过调用loadSystemConfig函数加载GpArray对象。get_gparray_from_config函数返回GpArray对象。
def get_gparray_from_config():
# imports below, when moved to the top, seem to cause an import error in a unit test because of dependency issue
from gppylib.system import configurationInterface
from gppylib.system import configurationImplGpdb
from gppylib.system.environment import GpMasterEnvironment
master_data_dir = os.environ['MASTER_DATA_DIRECTORY']
gpEnv = GpMasterEnvironment(master_data_dir, False)
configurationInterface.registerConfigurationProvider(configurationImplGpdb.GpConfigurationProviderUsingGpdbCatalog())
confProvider = configurationInterface.getConfigurationProvider().initializeProvider(gpEnv.getMasterPort())
return confProvider.loadSystemConfig(useUtilityMode=True)
代码来自于greenplum-db-5.27.1源代码