Python进阶之前端和爬虫基础
前端和爬虫基础
一、了解前端页面源代码
1、了解前端页面源代码的构成
html全称HyperText Mackeup Language,翻译为超文本标记语言,它不是一种编程语言,是一种描述性的标记语言,用于描述超文本内容的显示方式,主要由三样东西构成:
- 标签 - 数据(content - 承载了页面的内容)
- 层叠样式表(CSS)- 显示(display - 渲染页面)
- JavaScript(JS) - 行为(behavior - 控制页面交互式行为)
- 命名规范:驼峰式命名(从第二个单词开始首字母大写)
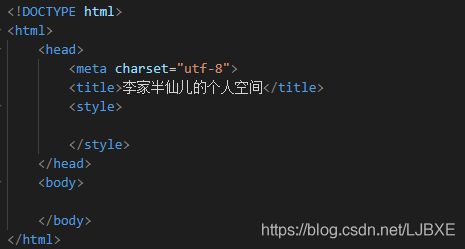
2、页面的大体结构构成
对于初学者来说,要想写一个前端的页面,最先要了解前端页面源代码的大体结构的构成,然后再往里面镶嵌自己想要增加的内容
- 前端页面大体结构主要由 三个标签构成
- html标签:声明部分,主要是用于告诉浏览器这个页面使用的是哪个标注
- head标签:主要是将页面的一些额外信息告诉服务器,不会显示在页面上,但是一般会包含比较重要的元信息,一般我们要对页面中的内容进行格式渲染,就写在head标签里面
- body标签:是页面需要实现的主要内容,我们写的代码就必须放在这个标签里面
3、了解HTML中的相关标签
(1)文本相关
- h1 - h6 : 标题样式,h1 (给文本增加主标题也叫一级标题的语义),以此类推
- p : 段落标签,里面的内容被换行,并且上下的内容之间也有一行空白,P标签是块级标签,里面的内容独占一行
- sub / sup : 下标 /上标
- strong : 加粗
- em : 斜体
(2)图像
- img - 图像,src 要显示图片的路径,路径最好用绝对路径
(3)链接
- a标签 - href属性,是指定要去哪里/name属性(锚点属性)/target属性(_self在当前页面打开新页面,)
- 页面链接
- 锚链接
- 功能链接
(4)表格
- table标签
(5)列表
- ul - 无序列表(unordered list) - li(列表项,列表中的元素)
- ol - 有序列表(ordered list) - li(列表项,列表中的元素)
(6)定义
- dl(标签)
- dt(定义的标题)
- dd(定义的描述)
(7)音视频
- audio(音频) - source
- video(视频)
(8)表单
- form —> input
二、爬虫
1、爬虫的分类
- 通用爬虫:搜索引擎
- 定向爬虫:只爬取自己需要的数据
2、爬虫的作用
-
中小企业一般情况下,数据都是短板,只能靠爬虫去采集数据
-
舆情监控
-
竞品分析、了解行情
3、了解爬虫获取页面所需三方库 - 请求库(requests)
要想通过Python从浏览器中爬取数据,首先要在python中导入一个三方库requests,利用requests的属性来获取网页中的数据信息
(1)了解http协议
-
URI - Universal Resource Identifier - 统一资源标识符
-
URL - Universal Resource Locator - 统一资源定位符
- 域名/IP地址 - 要连接的主机
- 端口号 - 端口用来区分不同的服务
- 资源路径
-
URI = URL + URN(x)
-
协议 - HTTP / HTTPS
- HTTP - Hyper-Text Transfer Protocol - 超文本传输协议,请求响应式协议
- HTML - Hyper-Text Markup Language - 超文本标记语言
- HTTPS - HTTP over SSL —> 安全的HTTP
- 2017年1月1日苹果AppStore强制使用HTTPS
- 微信小程序强制使用HTTPS跟后台程序通信
- Chrome从2017年发布的版本都会对HTTP提示不安全
-
DNS - Domain Name System - 将域名解析为IP地址
-
HTTP请求
- 请求行 - GET / HTTP/1.1
- GET:从服务器获取资源
- POST:向服务器提交数据
- 请求头 - 键值对 - 告诉服务器的额外的信息
- 空行(\r\n)
- 消息体 - 你要发给服务器的数据
- 请求行 - GET / HTTP/1.1
(2)发送请求
-
首先在Python中导入三方库:import requests
-
get请求:可以请求任何网站的URL
-
r = requests.get('https://api.github.com/events') -
post请求
-
r = requests.post('http://httpbin.org/post', data = { 'key':'value'})
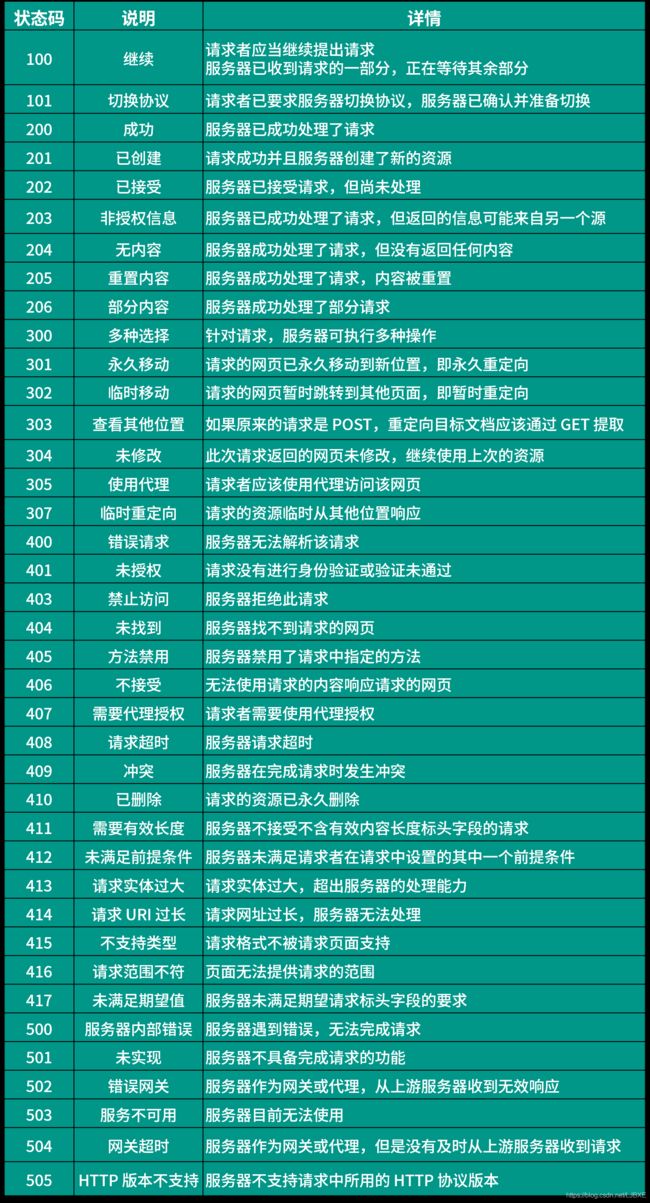
(3)检测响应状态码
- 在向浏览器发送了请求之后我们可以检测一下响应状态码
- r.status_code
- 响应状态码 -------404 Not Found / 403 Forbidde
- 2xx:成功了
- 3xx:重定向
- 4xx:请求有问题
- 5xx:服务器有问题
- 常见的响应状态码有:
(4)获取响应内容
- 文本响应内容:.text
- 二进制响应内容:.content
- JSON响应内容:.json
- 服务器发给浏览器的数据
- 如果请求的是图片,就获得图片的二进制数据
- 如果请求的网页,就获得网页的源代码,浏览器执行代码,用户看到页面
4、爬虫时如何隐匿自己的身份
法不禁止即为许可。爬虫是一个灰色地带,总的来说是不违法的,但是我们在进行爬虫时也要注意隐匿自己的身份,爬虫协议:robots.txt
- 在看网页源代码时,你会发现网页源代码的请求头中有一个‘User-Agent’,他能够使服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
- 因此我们可以在发送请求时定制一个请求头
(1)如何定制请求头
-
只需要传递一个dict给headers参数就可以了,headers参数里面是一个字典,添加’User-Agent’的键,再把网页源代码的User-Agent的值复制粘贴过来就可以了
-
import re import requests resp = requests.get( url='https://movie.douban.com/top250', headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } ) # 418 - I am a teapot. print(resp.status_code) print(resp.text)
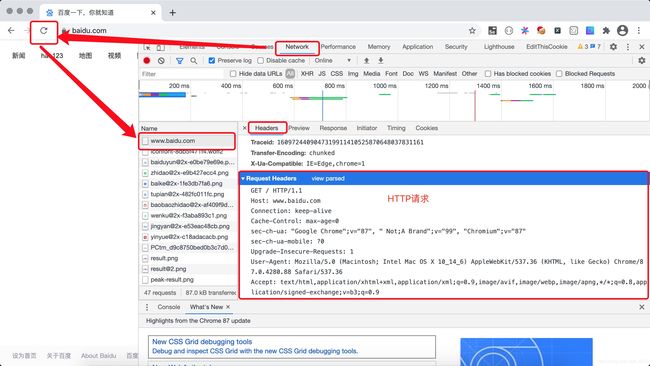
(2)如何在网页中查看到’User-Agent’
- 第一步:右键点击网页任何一处空白处,再点击检查
- 第二步:点击network,再刷新页面
- 第三步:点击第一个,就可以在Request Headers里面看到’User-Agent’
5、如何解析页面?
要了解我们爬取到的是页面的全部信息,但是我们可能只是需要其中的一部分信息,其他繁杂无用的信息都不需要,因此我们要对我们爬取到的页面信息进行解析,从而获取到自己想要的那一部分
(1)正则表达式解析
- 首先将要查找的内容转化成正则表达式:Pattern = re.compile(‘ …正则表达式…’)
- 然后再利用re模块中的findall去查找r.text中符合Pattern格式的内容
- results = Pattern.findall(r.text)
import re
import requests
resp = requests.get(
url='https://movie.douban.com/top250',
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
)
# 使用正则表达式捕获组从页面代码中提取电影名称
pattern = re.compile(r'\(.*?)\<\/span\>')
print(type(pattern))
print(pattern.findall(resp.text))
(2)CSS选择器解析
虽然使用正则表达式性能较好,但是由于正则表达式使用起来较难,因此我们更加常用的解析方式是CSS选择器解析,使用起来较为简单
a.了解选择器有哪些
- 通配符选择器:*
- 标签选择器:对所有的标签生效 ----h1
- 类选择器:用 . 表示比标签选择器更加具体 ---- . 类名
- ID选择器:用 # 表示是独一无二的(最具体)---- # id名称
- 父子选择器:a > p -----a类标签下的子p标签
- 后代选择器:b p ------ b类下的所有p标签
- 兄弟选择器: h1~p -----和h1平级的所有P标签
- 相邻兄弟选择器:h1 + p ----- 和h1紧邻的P标签
- 属性选择器: 加[ ]
b.导入三方库bs4 —Beautiful Soup 4
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式
- 安装:点开终端,输入pip install Beautiful Soup 4,即可安装成功
- 导入模块:import bs4
- 在用requests请求到内容之后,首先要对请求到的内容进行解析
- BeautifulSoup4 —> BeautifulSoup —> select —> Tag —> text / attrs
import bs4
resp = requests.get('https://www.sohu.com/index.html')
if resp.status_code == 200:
soup = bs4.BeautifulSoup(resp.text, 'html.parser')
- 标签的的几个重要方法
- select : 找到的是列表
- select-one : 找到的是元素,返回查找的元素第一个
- tag.attrs ----获取标签中的属性,获取到的是一个字典,在通过字典的键取对应的值
resp = requests.get('https://www.sohu.com/index.html')
if resp.status_code == 200:
soup = bs4.BeautifulSoup(resp.text, 'html.parser')
anchors = soup.select('div.list16>ul>li>a')
for anchor in anchors:
# 通过标签对象的attrs属性的索引操作获取指定的属性值
print(anchor.attrs['title'])
- 获取标签里的文本内容 :.text
6、封禁IP的反扒措施
(1)如果没登录不能访问,登录之后也还能访问 - 在请求头中强行添加登录信息(Cookie)
- Cookie(服务器保存在用户浏览器中的和用户身份相关的信息)
- 在网页的任何空白处,点击检查时,查看的网页源代码中就会有Cookie,上面就是我们登录后的信息,可以将上年的Cookie复制粘贴在我们的请求头里面
(2)不管是否登录都不能访问!!! —> IP代理
网上有很多专业的付费商业代理,一般在我们购买之后,都是提供给我们一个网络API接口(URL),通过请求这个接口就可以获得代理的信息。
-
让代理服务器帮我们向目标网站发起请求,目标网站返回的响应由代理返回给我们
-
如果做商业爬虫项目一般情况都需要购买商业IP代理(大量的代理服务器,失效了随时更换)
- 常见的代理:芝麻代理 / 蘑菇代理 / 快代理 / 讯代理 / 阿布云代理
以蘑菇代理举例:
- 我们用蘑菇代理提供的API接口返回JSON格式的数据,再通过response对象的json()方法将返回的JSON的数据处理成字典,再从中提取出IP代理的信息
- json是将返回的键值对变成字典,再放到列表里面,拿到代理服务器的列表
- 再随机抽出来一个代理服务器字典
- 再在请求头里面设置代理
resp = requests.get('http://piping.mogumiao.com/proxy/api/get_ip_bs?appKey=d36d8b6f1703481eb6c07cc78b3be0c1&count=5&expiryDate=0&format=1&newLine=2')
# json是将返回的键值对变成字典,再放到列表里面,拿到代理服务器的列表
proxy_list = resp.json()['msg']
for page in range(10):
# 随机抽出来一个代理服务器字典
proxy_dict = random.choice(proxy_list)
ip, port = proxy_dict['ip'], proxy_dict['port']
try:
resp = requests.get(
url=f'https://movie.douban.com/top250?start={page*25}',
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
},
# 设置代理
proxies={
# 'http': f'http://{ip}:{port}',
'https': f'http://{ip}:{port}' # http还是https,要和URL保持一致
},
timeout=3,
verify=False
)
7、商业爬虫项目,要提前创建好代理池(Cookies)
- Cookie是服务器放在浏览器里用来识别你身份的信息
- Cookies: 代理池,很多组IP代理,实效的代理会被移除,代理会定时更新
- 创建Cookies只需要在请求头里添加键值对即可 – ‘Cookie’ : ’ …’
- Cookie也可直接在网页的请求头里面查找
resp = requests.get(
url=f'https://movie.douban.com/top250?start={page*25}',
# 商业爬虫项目,需要提前创建好一个cookies池,每次请求从池子中随机选择一组cookies池
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Cookie': 'll="118318"; bid=hXdgbkzPeJk; __utmz=30149280.1609834076.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmz=223695111.1609834112.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __gads=ID=f2030357b13e661c-22c60d118dc500e4:T=1609840601:RT=1609840601:S=ALNI_MZx7S3mwNu_4fmaxmLsq20IlV3-0g; _vwo_uuid_v2=D579DA2B17F60E6D942734D1F3D975CCE|a4ed238b8f9fb09cd5f70bdb39a4e433; __yadk_uid=v1F1uNJZRDv3uEbSShXyw7NSqp36GVTd; dbcl2="229808144:LsAFGkwzIc8"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.22980; douban-profile-remind=1; ck=Igw5; __utmc=30149280; __utmc=223695111; ap_v=0,6.0; __utma=30149280.171995204.1609834076.1609901169.1609916179.6; __utmb=30149280.0.10.1609916179; __utma=223695111.1649735111.1609834112.1609901169.1609916179.6; __utmb=223695111.0.10.1609916179; _pk_ses.100001.4cf6=*; _pk_id.100001.4cf6=f6918bb273f7004a.1609834112.6.1609917103.1609901181.'
}
)
8、将爬取到的数据保存在Excel文件中
在我们获得爬取到的数据时,要将他们放在Excel表格里面,这样方便后续的保存和查看
(1)python中支持读写Excel文件的方式
- openpyxl —> XML —> xlsx
- xlrd / xlwt —> xls
- xlwings
(2)了解Excel的构成方式
- 每个Excel文件 —> 工作簿 —> Workbook
- 一个Excel文件可以包含多个工作表 —> Sheet —> 行和列
- 行和列交汇的地方叫做单元格 —> Cell
(3)保存步骤------以三方库xlwt为例
-
要想保存在Excel表格里面,首先要利用一个三方库:xlwt,在终端里把它安装上
-
然后需要创建一个工作簿对象: wb = xlwt.Workbook( )
-
再创建工作表:sheet = wb.add_sheet(‘工作报表的名称’)
-
指定行索引、列索引,往表里写入数据
-
最后保存Excel表:wb.save(‘保存的名称’)
wb = xlwt.Workbook() # 创建一个工作簿对象
sheet = wb.add_sheet('TOP250') # 创建一个表单
col_names = ('排名', '名称', '评分', '类型', '制片国家', '语言', '时长') # 创建Excel表格表头
for index, name in enumerate(col_names):
sheet.write(0, index, name)
9、如何读写csv文件(逗号分隔值文件)
首先要了解csv文件是一个文本文件
(1)写csv文件
- 首先导入csv这个模块
- 主要是用到 .writerow([ ])
import csv
with open('test.csv', 'w', encoding='utf-8') as file:
csv_writer = csv.writer(file, quoting=csv.QUOTE_ALL)
csv_writer.writerow(['张飞', 90, 80, 70])
csv_writer.writerow(['关羽', 98, 80, 70])
csv_writer.writerow(['马超', 95, 85, 70])
csv_writer.writerow(['赵云', 34, 80, 70])
csv_writer.writerow(['黄忠', 67, 56, 70])
(2)读csv文件
- 用只读模式打开需要我们读取的文件
- csv.reader(file)
import csv
from Tools.scripts.mkreal import join
with open('2018年北京积分落户数据.csv', 'r', encoding='utf-8') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
print(',', join(str(row)))
# print(f'编号:{row[0]}')
# print(f'编号:{row[1]}')
# print(f'编号:{row[2]}')
# print(f'编号:{row[3]}')
# print(f'编号:{row[4]}')
10、动态网页的爬取
(1)了解解释器类型
-
CPython ----> C -----> GIL(全局解释器锁)
-
Jython ------> Java
-
IronPython ----> C#
-
PyPy -----> Python ----> JIT
(2)动态页面的爬取
页面上可能有动态内容(通过JavaScript代码动态生成,显示网页源代码时看不到内容)
-
方法一:JavaScript逆向 —> 找真正提供数据的URL
-
- 直接通过浏览器开发者工具查找提供数据的URL(数据接口)
- 通过专业的抓包工具,直接获取到数据接口
-
- Fiddler / Charles / Wireshark(Ethereal)(网络协议分析工具)
- 三个随便装一个
-
方法二:通过Python代码操控浏览器,直接拿到带动态内容的页面,然后再提取数据+ +
-
selenium.webdriver
-
pip install selenium
-
浏览器一般有:Chrome / Firefox / Safari / Edge / Opera
-
from selenium import webdriver
import bs4
driver = webdriver.Chrome()
driver.get('https://image.so.com/z?ch=beauty')
# page_source是带动态内容的页面源代码
soup = bs4.BeautifulSoup(driver.page_source, 'html.parser')
imgs = soup.select('img')
for img in imgs:
print(img.attrs['src'])
- 计算机软硬件系统中的缺陷和问题,我们一般统称为bug,把bug揪出来的过程叫debug(调试)。
- 在运行程序时,如果对程序存在疑问,可以使用调试模式来运行程序,那么程序会在放置断点的地方停下来,这样我们就可以一步一步的执行程序观察到底发什么了事情。
三、多线程(并发编程)
-
进程:我们运行的程序通常会对应到一个或多个进程,进程是操作系统分配内存的基本单位
-
线程:一个进程通常会包含一个或多个线程,线程是操作系统分配CPU的基本单位
-
单线程程序 —> 我们的程序中只有一个执行线索(主线程)—> 创建多个线程(有多个可以并发的部分)
-
并发编程:让程序有多个执行线索(有多个部分能够齐头并进的执行)
- 多线程 —> I/O密集型任务 —> CPython —> GIL —> 无法使用多核特性
- 多进程 —> 计算密集型任务 —> 使用到多个CPU和多核特性 —> 每个CPU高负荷运转
- 异步编程
- 注意:在编写多线程程序时,一定要注意线程的创建和释放有较大的开销,而且如果创建了太多的线程,线程之间的调度切换本身也是有开销的,所以线程并不是越多越好,最好的用法是创建若干个线程,然后重复的使用它们
-
线程池:先用一个容器,提前创建好若干个线程放进去,用线程的时候从线程池中借出一个线程,用完了之后,不要释放线程,而是把这个线程放回池子,让线程可以被重复利用
-
池化技术基本上都是空间换时间的做法
1、创建多线程
当程序中有耗时间的任务,可能会阻塞别的任务的执行,并且他们之间没有因果关系,就可以利用多线程来同时进行
(1)创建线程对象
-
def main( ):
t1 = Thread(target = output1)
(2)指定线程属性 - args
(3)启动线程
- t1.start()
(4)等待线程结束 - join
import random
import time
def record_time(func):
def wrapper(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f'{func.__name__}执行时间:{end-start:.3f}秒')
return result
return wrapper
@record_time
def download(filename):
print(f'开始下载{filename}')
time.sleep(random.randint(5, 10))
print(f'{filename}下载完成')
@record_time
def main():
print(download.__name__)
t1 = Thread(target=download, args=('窗前明月光.pdf',))
t1.start()
t2 = Thread(target=download, args=('疑是地上霜.avi',))
t2.start()
t3 = Thread(target=download, args=('原来是幻觉.avi',))
t3.start()
t1.join()
t2.join()
t3.join()
print(f'下载总时间: ')
if __name__ == '__main__':
main()
2、创建线程池
- 第一步:创建任务列表:makeRequests(任务对应的函数,参数列表)
- 任务函数有且只有一个参数
- 参数列表中元素的个数决定了任务列表中任务的个数
tasks = threadpool.makeRequests(download, [f'电影{x}' for x in range(100)])
tasks2 = threadpool.makeRequests(save, [0])
- 第二步:创建线程池对象
- ThreadPool(线程的数量)
pool = threadpool.ThreadPool(10)
- 第三步:在线程池中添加任务
- 线程池对象.putRequest(任务对象)
for task in tasks2:
pool.putRequest(task)
for task in tasks:
pool.putRequest(task)
-
第四步:执行和等待
- 相当于先start 然后再join
pool.wait()
3、多线程竞争一个资源 - 线程锁(threading.Lock)
当有多个线程想要竞争一个资源,想要保护资源(在关键操作上只有一个线程能够访问到这个资源)就需要用到线程锁,当一个线程拿到锁的时候,其他线程只能等到该线程执行完之后释放锁,再进行争抢锁
- 保证一个数据对应一个锁对象:锁对象 = Lock()
- 线程在第一次操作数据前加锁:锁对象.acquire()
- 线程在结束数据操作后解锁:锁对象.release()
- 在添加锁的时候可以使用上下文语法,当进入with时就会自动拿到所得代码,只要崩溃了或者正常执行完结束了就会自动释放锁这句代码
4、遇到死锁 - 利用condition线程调度
当一个线程拿到锁之后,可能会死在里面,但是其他线程又没有接收到释放锁的消息,无法拿到锁,这就会造成死锁的情况,这种情况就可以利用线程调度来解决。
- condition也是一把锁,但是他是一个条件锁,可以在两个线程之间进行协调,也就是线程调度,利用condition线程调度,利用wait让进程进行等待