学术前沿趋势分析1:论文数据统计
一 、数据集与开发环境
下载链接::https://www.kaggle.com/Cornell-University/arxiv
开发环境:Jupyter lab 2.1.5
二、 数据预处理
import seaborn as sns
from bs4 import BeautifulSoup
import re
import requests
import json
import pandas as pd
import matplotlib.pyplot as plt
data=[]
with open(r"D:\Datawhale\arxiv-metadata-oai-snapshot.json",'r') as f:
for idx, line in enumerate(f): #enumerate() 对于跟踪某些值在列表中出现的位置是很有用的。 所以,如果你想将一个文件中出现的单词映射到它出现的行号上去,可以很容易的利用 enumerate() 来完成
data.append(json.loads(line))
#json.load()是用来读取文件的,json.loads()是用来读取字符串
data=pd.DataFrame(data)
data.head()
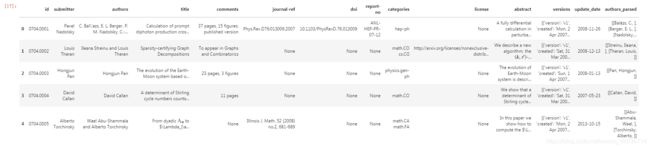
data["categories"]
unique_categories=set(i for l in [x.split(' ') for x in data["categories"]] for i in l)
len(unique_categories)
data["year"]=pd.to_datetime(data["update_date"]).dt.year
data["year"]
del data["update_date"]
data=data[data['year']>=2019]
data.reset_index(drop=True,inplace=True)
#drop=True: 把原来的索引index列去掉,丢掉。
#drop=False:保留原来的索引(以前的可能是乱的)
#inplace=True:不创建新的对象,直接对原始对象进行修改
#inplace=False:对数据进行修改,创建并返回新的对象承载其修改结果。
data
#爬取所有的类别
website_url=requests.get("https://arxiv.org/category_taxonomy").text
soup=BeautifulSoup(website_url,'lxml')
root=soup.find('div',{
'id':'category_taxonomy_list'})
tags=root.find_all(['h2','h3','h4','p'],recursive=True)
for t in tags:
if t.name=='h2':
level_1_name=t.text
level_2_code=t.text
level_2_name=t.text
elif t.name == "h3":
raw = t.text
level_2_code = re.sub(r"(.*)\((.*)\)",r"\2",raw) #正则表达式:模式字符串:(.*)\((.*)\);被替换字符串"\2";被处理字符串:raw
level_2_name = re.sub(r"(.*)\((.*)\)",r"\1",raw)
elif t.name == "h4":
raw = t.text
level_3_code = re.sub(r"(.*) \((.*)\)",r"\1",raw)
level_3_name = re.sub(r"(.*) \((.*)\)",r"\2",raw)
elif t.name == "p":
notes = t.text
level_1_names.append(level_1_name)
level_2_names.append(level_2_name)
level_2_codes.append(level_2_code)
level_3_names.append(level_3_name)
level_3_codes.append(level_3_code)
level_3_notes.append(notes)
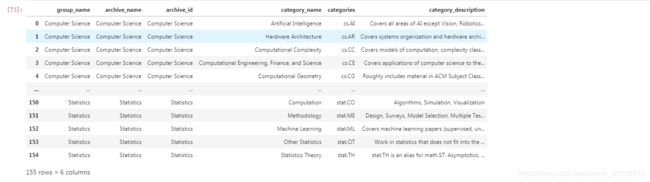
#根据以上信息生成dataframe格式的数据
df_taxonomy = pd.DataFrame({
'group_name' : level_1_names,
'archive_name' : level_2_names,
'archive_id' : level_2_codes,
'category_name' : level_3_names,
'categories' : level_3_codes,
'category_description': level_3_notes
})
#按照 "group_name" 进行分组,在组内使用 "archive_name" 进行排序
df_taxonomy.groupby(["group_name","archive_name"])
df_taxonomy
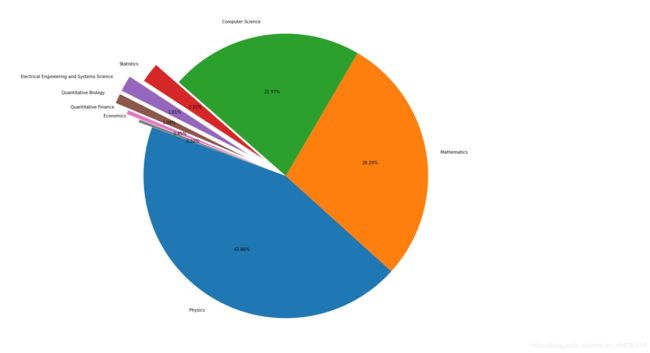
三、数据分析与可视化
_df = data.merge(df_taxonomy, on="categories", how="left").drop_duplicates(["id","group_name"]).groupby("group_name").agg({
"id":"count"}).sort_values(by="id",ascending=False).reset_index()
_df

fig = plt.figure(figsize=(15,12))
explode = (0, 0, 0, 0.2, 0.3, 0.3, 0.2, 0.1)
plt.pie(_df["id"], labels=_df["group_name"], autopct='%1.2f%%', startangle=160, explode=explode)
plt.tight_layout()
plt.show()