“达观杯”文本智能处理挑战赛练习
记录一下项目练习过程
task1
比赛提供的数据
数据包含2个csv文件:
-
train_set.csv:此数据集用于训练模型,每一行对应一篇文章。文章分别在“字”和“词”的级别上做了脱敏处理。共有四列:
第一列是文章的索引(id),第二列是文章正文在“字”级别上的表示,即字符相隔正文(article);第三列是在“词”级别上的表示,即词语相隔正文(word_seg);第四列是这篇文章的标注(class)。
注:每一个数字对应一个“字”,或“词”,或“标点符号”。“字”的编号与“词”的编号是独立的! -
test_set.csv:此数据用于测试。数据格式同train_set.csv,但不包含class。
注:test_set与train_test中文章id的编号是独立的。
读取数据
import pandas as pd
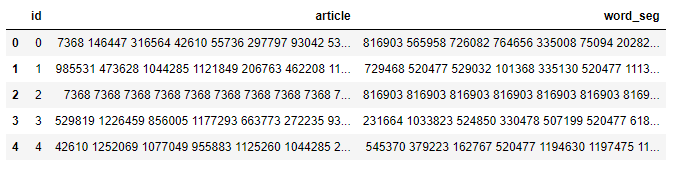
df_train = pd.read_csv('train_set.csv')
df_train.head()
train_set前五行数据

df_test = pd.read_csv('test_set.csv')
df_test.head()
test_set前五行数据
各列文件类型数量有无缺失。
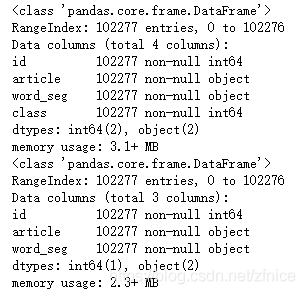
df_train.info()
df_test.info()
各个类别数据是否分布不均:
df_train['class'].describe()
df_train['class'].value_counts()


文本分类共19类,各类别数据均在2000条以上。没有严重的类别不均。
数据拆分
参考 GreatXiang888 .
数据说明中显示:
'article’是字级别上的,'word_seg’是词级别上的。
也就是说,比赛举办方已经把单词给我们切好了,不需要自己手动分词(如用“结巴分词”等工具),而且他已经把单词数字化(脱敏),这其实也省了我们一些工作。
一般的比赛我们是要自己分词,而且分词的效果对模型和结果影响较大。而这分好词了,那么就直接使用’word_seg’即可。
当然这只是一个比较简略的版本,如果要进行后续工作的话,我觉得可以把’article’也用上,至少可以用来做模型融合,投票选最优等工作。
因此数据划分中X以df_train[[‘word_seg’]进行即可。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_train[['word_seg']], df_train[['class']], test_size=0.3, random_state=2019)
print(X_train.shape)
print(X_test.shape)
(71593, 1)
(30684, 1)
task2
TF-IDF理论
词袋模型
把每篇文章看成一个词袋,忽略单词顺序,每篇文章表示一个长向量,每一维就是一个单词,权重表示这个单词在文章中的重要程度。TF-IDF用来表示权重。
TF-IDF(t,d)=TF(t,d)xIDF(t)
TF(t,d) 表示单词t在文档d中出现的频率,
IDF(t) 表示逆文档频率,衡量单词t对表达语义的重要性程度。
I D F ( t ) = l o g 文 章 总 数 包 含 单 词 t 的 文 章 总 数 + 1 IDF(t)=log\frac{文章总数}{包含单词t的文章总数+1}\ IDF(t)=log包含单词t的文章总数+1文章总数
如果t在多篇文章中均有出现,那么他对于区分文章语义贡献较小,因此权重需要做一定的惩罚。
N-gram模型
将连续出现的n个单词组成的词组(N-gram)作为一个单独的特征放到向量表示中的模型。
词嵌入
词嵌入是一类将词向量化的模型的统称,核心思想是把每个词都映射到低维空间上的一个稠密向量。K维空间的每一维可以看作一个隐含的主题。
词嵌入将每个词映射成一个K维向量,一篇文章N个词,可以用NxK维的矩阵表示这篇文章。
Word2Vec
Word2Vec&Doc2Vec总结 - Magician的博客 .
Word2Vec是一种浅层的神经网络模型,有两种网络结构。分别是CBOW和Skip-gram。
CBOW的目标是根据上下文出现的词语预测当前词出现的概率。Skip-gram是根据当前词预测上下文中各词的生成概率。
sklearn.feature_extraction.text.TfidfVectorizer函数
sklearn.feature_extraction.text.TfidfVectorizer(input=’content’, encoding=’utf-8’, decode_error=’strict’, strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, analyzer=’word’, stop_words=None, token_pattern=’(?u)\b\w\w+\b’, ngram_range=(1, 1), max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=, norm=’l2’, use_idf=True, smooth_idf=True, sublinear_tf=False)
各参数含义:
input : string {‘filename’, ‘file’, ‘content’}
文件名,文件路径,直接分析的文本内容。
decode_error : {‘strict’, ‘ignore’, ‘replace’} (default=’strict’)
解码错误设置。当出现分析字节序列是包含的字符而不是给定编码的字符该怎么做。
strip_accents : {‘ascii’, ‘unicode’, None} (default=None)
在预处理步骤中删除重音符号并执行其他字符规格化。“ascii”是一种快速方法,只适用于具有直接ascii映射的字符。“unicode”是一种速度稍慢的方法,适用于任何字符。
lowercase : boolean (default=True)
标记化之前将所有字符转化为小写。
preprocessor : callable or None (default=None)
重写预处理(字符串转换)阶段,保留标记化和n-gram生成步骤。
tokenizer : callable or None (default=None)
在保留预处理和N-grams生成步骤的同时重写字符串标记化技术步骤。仅适用于Analyzer==“Word”。
analyzer : string, {‘word’, ‘char’, ‘char_wb’} or callable
无论该功能是由单词还是字符n-grams组成。选项“char_wb”只从单词边界内的文本创建字符n-grams;单词边缘的n-gram都用空格填充。
stop_words : string {‘english’}, list, or None (default=None)
停止词。
token_pattern : string
表示什么构成了“标记”的正则表达式,只使用difAnalyzer==“word”。默认regexp选择2个或更多字母数字字符的标记(标点符号完全被忽略,并始终被视为标记分隔符)。
ngram_range : tuple (min_n, max_n) (default=(1, 1))
n值范围的上下限。n的所有值,以便使用min_n<=n<=max_。
max_df : float in range [0.0, 1.0] or int (default=1.0)
构建词汇表时,忽略文档频率严格高于给定阈值(corpus-specificstop-words)的词汇。如果为float,则参数表示文档的比例,积分绝对数。如果词汇表不是none,则忽略此参数。
min_df : float in range [0.0, 1.0] or int (default=1)
构建词汇表时,忽略文档频率严格低于给定阈值的术语。此值在文献中也被定义为截止值。如果为float,则参数表示文档的一部分,整数卷计数。如果词汇表不是none,则忽略此参数。
max_features : int or None (default=None)
如果不是“无”,那么构建一个词汇表,该词汇表只考虑按词条频率在整个语料库中排序的最大特性。
dtype : type, optional (default=float64)
fit_transform()或transform()返回的矩阵类型。
norm : ‘l1’, ‘l2’ or None, optional (default=’l2’)
每个输出行都有单位范数,要么是:‘l2’:向量元素的平方和为1。当应用l2范数时,两个矢量之间的余弦关系是它们的点积。“l1”:矢量元素的绝对值之和为1。
use_idf : boolean (default=True)
启用反向文档频率重新加权。
smooth_idf : boolean (default=True)
通过在文档频率中添加一个来平滑IDF权重,就好像看到一个extra文档包含了集合中的每个术语一次。防止零刻度。
sublinear_tf : boolean (default=False)
应用 sublinear tf 缩放, 用 1 + log(tf)替换tf。
Methods
gensim.models.word2vec.Word2Vec函数
gensim.models.word2vec.Word2Vec(sentences=None, corpus_file=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=, iter=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000, compute_loss=False, callbacks=(), max_final_vocab=None)
各参数含义
sentences (iterable of iterables, optional)
训练的句子。
corpus_file (str, optional)
以linesentence格式指向语料库文件的路径
size (int, optional)
词向量维度
window (int, optional)
句子中当前单词和预测单词之间的最大距离。
min_count (int, optional)
忽略出现频率低于min_count的词
workers (int, optional)
使用多核机器进行更快的训练。
sg ({0, 1}, optional)
训练算法:1表示跳格,否则为cbow。
hs ({0, 1}, optional)
如果是1,则将使用分层SoftMax进行模型培训。如果0,负为非零,则采用负采样。
negative (int, optional)
如果大于0,将使用负采样,int表示负指定应绘制多少“噪声词”(通常在5-20之间)。如果设置为0,则不使用负采样。
ns_exponent (float, optional)
用于形成负采样分布的指数。一个值为1.0的样本与频率成正比例,0.0的样本对所有单词都是一样的,而一个负值样本对低频单词的样本多于高频单词的样本。最常用的默认值0.75是由原来的word2vec文件选择的。
cbow_mean ({0, 1}, optional)
如果为0,则使用上下文词向量的和。如果1,使用平均值,仅在使用cbow时适用。
alpha (float, optional)
初始学习率
min_alpha (float, optional)
随着培训的进行,学习率将线性下降至_min alpha。
max_vocab_size (int, optional)
词汇构建期间限制RAM;如果有比这更多的唯一单词,则删减不经常出现的单词。每1000万字类型需要大约1GB的RAM。设置为无表示无限制。
max_final_vocab (int, optional)
通过自动选择匹配的min_计数,将vocab限制为目标vocab大小。如果指定的最小计数大于计算的最小计数,则将使用指定的最小计数。如果不需要,设置为无。
sample (float, optional)
配置哪些高频字随机降采样的阈值,有用范围是(0,1e-5。
hashfxn (function, optional)
用于随机初始化权重的哈希函数,以提高训练的再现性。
iter (int, optional)
语料库上的迭代次数(epoch)。
sorted_vocab ({0, 1}, optional)
如果是1,请在分配单词索引之前按降序频率对词汇进行排序。请参见Sort_vocab()。
batch_words (int, optional)
传递给工作线程(因此是cython例程)的一批示例的目标大小(以字为单位)。(如果单个文本超过10000个字,将传递更大的批处理,但标准cython代码截断到最大值。)
compute_loss (bool, optional)
如果为真,则计算并存储损失值,可使用gget_latest_training_loss()检索该值。
TfidfVectorizer函数应用
“达观杯”文本分类–baseline - 温良Miner - 博客园 .
vectorizer = TfidfVectorizer(ngram_range=(1, 2), min_df=3, max_df=0.9)
vectorizer.fit(df_train['word_seg']) # 构造tfidf矩阵
X_train = vectorizer.transform(df_train['word_seg']) # 构造训练集的tfidf矩阵
X_test = vectorizer.transform(df_test['word_seg']) # 构造测试的tfidf矩阵
X_train = df_train['class'] #训练集的类别标签
将词转化为向量表示。
word2vec函数应用
构造训练所用的语料库。
def sentence2list(sentence):
return sentence.strip().split()
#组成语料库
sentences_train = list(df_train['word_seg'].apply(sentence2list))
sentences_test = list(df_test['word_seg'].apply(sentence2list))
sentences = sentences_train + sentences_test
将构造好的语料库进行训练,转为word2vec模型。
model = gensim.models.Word2Vec(sentences=sentences, size=vector_size, window=5, min_count=5, workers=8, sg=0, iter=5)
可以后续对模型进行进一步的分析应用。
task3
LR模型
逻辑回归处理的是分类问题,因变量取值是一个二元分布,学习得到的是给定自变量和超参数以后因变量的期望。基于期望来处理预测分类问题。
具体参考细品 - 逻辑回归(LR)* - ML小菜鸟 - 博客园.
后面发现全部数据所需的时间太久,因此便采取20000条数据进行联系学习。
导入所需包后进行lr训练。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2019)
lr=LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
lr.fit(X_train,y_train)
print('准确率:',lr.score(X_test, y_test))
准确率: 0.6746666666666666
进行交叉验证:
start_time=time.time()
scores = cross_val_score(lr,X,y, cv=5) #cv为迭代次数。
end_time=time.time()
print("耗时:{}s ".format(end_time - start_time))
print(scores) # 打印输出每次迭代的度量值(准确度)
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2)) # 获取置信区间。(也就是均值和方差)
耗时:1084.5898168087006s
[0.68445997 0.67274544 0.69275 0.68618619 0.69539078]
Accuracy: 0.69 (+/- 0.02)
使用lsa特征得到的结果要比使用原始的tfidf特征准确率稍高一些。
start_time=time.time()
scores = cross_val_score(lr,x_train_lsa,y, cv=3) #cv为迭代次数。
end_time=time.time()
print("耗时:{}s ".format(end_time - start_time))
print(scores) # 打印输出每次迭代的度量值(准确度)
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2)) # 获取置信区间。(也就是均值和方差)
耗时:76.02445268630981s
[0.69893601 0.69761512 0.69804805]
Accuracy: 0.70 (+/- 0.00)
svm模型
读了一些博客觉得写的比较好的关于svm理解的博客。
对SVM的个人理解—浅显易懂 - 止战 - 博客园
用svm进行评估发现使用tfidf特征速度慢且一直不出结果。就将tfidf特征lsa降维,使用降维后的特征进行训练。
start_time=time.time()
clf = svm.SVC(kernel='linear', C=1)
scores = cross_val_score(clf,x_train_lsa,y, cv=3) #cv为迭代次数。
end_time=time.time()
print("耗时:{}s ".format(end_time - start_time))
print(scores) # 打印输出每次迭代的度量值(准确度)
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2)) # 获取置信区间。(也就是均值和方差)
耗时:316.12110233306885s
[0.67016334 0.67136643 0.67672673]
Accuracy: 0.67 (+/- 0.01)
对于提取出来的20000条数据进行分析,使用降维后的lsa特征的lr模型准确率更高一些。电脑跑起来有点慢,后续的程序总是没有完整跑完,代码附上。
学习曲线
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
title = "Learning Curves (Random Forest, n_estimators = 100)"
cv = ShuffleSplit(n_splits=10,test_size=0.2, random_state=0)
estimator = svm.SVC()
plot_learning_curve(estimator, title, X, y, (0.0, 1.01), cv=cv, n_jobs=4)
plt.show()
grid search寻参
from sklearn.pipeline import Pipeline
from operator import itemgetter
import collections
from sklearn.metrics import classification_report
def report(grid_scores, n_top=3):
top_scores = sorted(grid_scores, key=itemgetter(1), reverse=True)[:n_top]
for i, score in enumerate(top_scores):
print("Model with rank: {0}".format(i + 1))
print("Mean validation score: {0:.3f} (std: {1:.3f})".format(
score.mean_validation_score,
np.std(score.cv_validation_scores)))
print("Parameters: {0}".format(score.parameters))
print("")
X_train, X_test, Y_train, Y_test = train_test_split(x_train_lsa,y, test_size=0.2,random_state=0)
#初始化分类器
clf=RandomForestClassifier(n_estimators=500, criterion='entropy', max_depth=5, min_samples_split=2,
min_samples_leaf=1, max_features='auto', bootstrap=False, oob_score=False, n_jobs=1, random_state=0,
verbose=0)
###grid search找到最好的参数
param_grid = dict( )
##创建分类pipeline
pipeline=Pipeline([ ('clf',clf) ])
grid_search = GridSearchCV(pipeline, param_grid=param_grid, verbose=3,scoring='accuracy',\
cv=StratifiedShuffleSplit(n_splits=10,test_size=0.2, random_state=0)).fit(X_train, Y_train)
# 对结果打分
print(("Best score: %0.3f" % grid_search.best_score_))
print((grid_search.best_estimator_))
#report(grid_search.best_score_)
print('-----grid search end------------')
print ('on all train set')
scores = cross_val_score(grid_search.best_estimator_, X_train, y_train,cv=3,scoring='accuracy')
print(scores.mean(),scores)
print ('on test set')
scores = cross_val_score(grid_search.best_estimator_, X_test, Y_test,cv=3,scoring='accuracy')
print(scores.mean(),scores)
# 对结果打分
print((classification_report(Y_train, grid_search.best_estimator_.predict(X_train) )))
print('test data')
print((classification_report(Y_test, grid_search.best_estimator_.predict(X_test) )))
得到最好的模型后,训练预测保存需要提交的数据。
clf.fit(X,y)
y_pred =clf.predict(test_df)
pd.DataFrame({"id": id_data, "class": y_pred}).to_csv('submission.csv',index=False)
lsa降维以及一些特征处理主要参考下面博客。
文本分类任务的基础实现(一)——机器学习部分_特征工程_代码分解 -
task4
关于lightgbm的介绍以及原理参考:开源|LightGBM基本原理,以及调用形式_慕课手记
lightGBM从参数调优到背景理论 - 简书
使用过程。
首先用lgb包的DataSet类包装一下需要测试的数据;
将lightgbm的参数构成一个dict字典格式的变量
将参数字典,训练样本,测试样本,评价指标一股脑的塞进lgb.train()方法的参数中去
上一步的方法会自觉地得到最佳参数和最佳的模型,保存模型
使用模型进行测试集的预测
在文件保存过程中发现pickle对于保存大型数据有时候不能够使用,因此使用joblib来进行数据的保存和模型的固化。
f2 = open('feature_file/data_tfidf_lsa.pkl', 'rb')
x_train_lsa, train_Y,x_test_lsa=joblib.load(f2)
X=train_X
y=train_Y
X_train, X_vali, y_train, y_vali = train_test_split(X, y, test_size=0.3, random_state=2019)
导入降维后的lsa特征作为训练数据。
数据一定要转换为要求的数据类型。
lgb_train = lgb.Dataset(data=X_train, label=y_train)
lgb_vali = lgb.Dataset(data=X_vali, label=y_vali)
定义评价标准F1指标
def f1_score_vali(preds, data_vali):
labels = data_vali.get_label()
preds = np.argmax(preds.reshape(20, -1), axis=0)//将输出的概率模型转为要求的整数数据
score_vali = f1_score(y_true=labels, y_pred=preds, average='macro')
return 'f1_score', score_vali, True
设置参数进行训练,训练过程设置了两百次迭代已经耗时2个多小时。
### 开始训练
start_time=time.time()
print('设置参数')
params = {
'boosting': 'gbdt',
'application': 'multiclassova',
'num_class': 20,
'learning_rate': 0.1,
'num_leaves':31,
'max_depth':-1,
'lambda_l1': 0,
'lambda_l2': 0.5,
'bagging_fraction' :1.0,
'feature_fraction': 1.0
}
print("开始训练")
gbm = lgb.train(params, # 参数字典
lgb_train, # 训练集
num_boost_round=200, # 迭代次数
valid_sets=lgb_vali, # 验证集
feval=f1_score_vali,
early_stopping_rounds=None, # 早停系数
verbose_eval=True)
end_time=time.time()
print("耗时:{}s ".format(end_time - start_time))
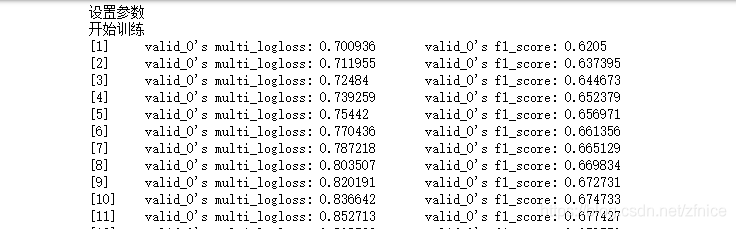
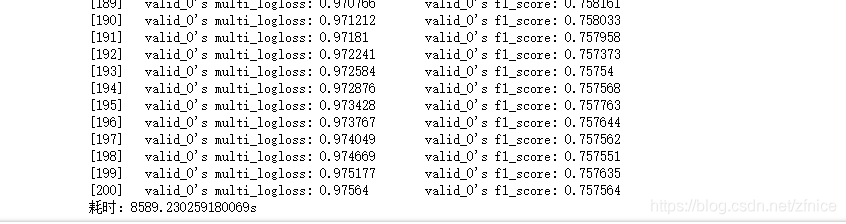
迭代过程中可以看到模型的F1指标是在逐渐变好的。由于电脑原因就没有继续迭代下去。就利用了本次的模型进行预测。
### 保存模型
joblib.dump(gbm,'gbm.pkl')
### 预测
y_preds = np.argmax(gbm.predict(x_test_lsa, num_iteration=gbm.best_iteration), axis=1) + 1 # 输出概率
pd.DataFrame({"id":id_data,"class":y_preds}).to_csv('submission.csv',index=False)
关于调参:`
首先设置初始参数–不含交叉验证参数
### 设置初始参数--不含交叉验证参数
print('设置参数')
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'binary_logloss',
}
### 交叉验证(调参)
print('交叉验证')
min_merror = float('Inf')
best_params = {}
准确率
print("调参1:提高准确率")
for num_leaves in range(20,200,5):
for max_depth in range(3,8,1):
params['num_leaves'] = num_leaves
params['max_depth'] = max_depth
cv_results = lgb.cv(
params,
lgb_train,
seed=2018,
nfold=3,
metrics=['binary_error'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_merror = pd.Series(cv_results['binary_error-mean']).min()
boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
if mean_merror < min_merror:
min_merror = mean_merror
best_params['num_leaves'] = num_leaves
best_params['max_depth'] = max_depth
params['num_leaves'] = best_params['num_leaves']
params['max_depth'] = best_params['max_depth']
降低过拟合
print("调参2:降低过拟合")
for max_bin in range(1,255,5):
for min_data_in_leaf in range(10,200,5):
params['max_bin'] = max_bin
params['min_data_in_leaf'] = min_data_in_leaf
cv_results = lgb.cv(
params,
lgb_train,
seed=42,
nfold=3,
metrics=['binary_error'],
early_stopping_rounds=3,
verbose_eval=True
)
mean_merror = pd.Series(cv_results['binary_error-mean']).min()
boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
if mean_merror < min_merror:
min_merror = mean_merror
best_params['max_bin']= max_bin
best_params['min_data_in_leaf'] = min_data_in_leaf
params['min_data_in_leaf'] = best_params['min_data_in_leaf']
params['max_bin'] = best_params['max_bin']
保存test的预测结果提交
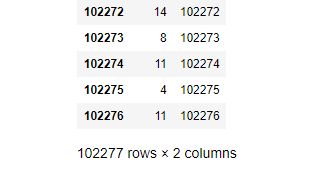
102277行test数据得到102277个预测数据。保存为csv文件提交,结果总是失败。
不知道怎么回事,暂时未提交成功。
Task5
CoLaboratory确实很好用但是存在一些问题,总是会自动断开。
Keras模型保存和加载的两种方式 - 葡萄家 - CSDN博客
RCNN 简介 - This is bill的专属博客 - CSDN博客
TextCnn原理及实践 - JohnSon - CSDN博客
kears模型的保存和重载。
保存
model.save('modelname.h5')
载入
from keras.models import load_model
model = load_model('modelname.h5')
RCNN代买来自 Heitao5200/DGB
自身电脑配置较差,使用谷歌提供的CoLaboratory,确实很好用但是存在一些问题,总是会自动断开。
使用CoLaboratory训练好模型并保存,进行预测的一步骤时连接出现问题。于是把
保存kears训练好的模型再重新载入出现这样的问题,暂时没找到解决办法。‘name ‘backend’ is not defined’。无奈只能重新再一次训练模型。
## 先把原始的文本处理成2000维的向量,太长的截断,不够的补0
## 生成300维的嵌入
## CNN,3个256的卷积,池化以后,flatten,输入给softmax
## 输出分类的one hot编码
读入部分训练集和全部test集。出于时间考虑用部分训练的模型做全部的预测,结果不够理想是可以预见的。
df_train = pd.read_csv('train_set1.csv',engine='python',encoding='gbk')
df_test = pd.read_csv( 'test_set.csv',engine='python',encoding='gbk')
print (df_train.shape)
#df_train=df_train[0:500]
df_train.drop(df_train.columns[0],axis=1,inplace=True)
#df_train["word_seg"] = df_train["article"].map(str) +' '+ df_train["word_seg"].map(str)
#df_test["word_seg"] = df_test["article"].map(str) +' ' + df_test["word_seg"].map(str)
word_seg = df_train['word_seg']
label = df_train['class'] - 1
X_train, X_test, y_train, y_test = train_test_split(word_seg, label, test_size=0.1, random_state=42)
数据的处理阶段
X_train_word_ids = tokenizer.texts_to_sequences(X_train)
X_test_word_ids = tokenizer.texts_to_sequences(X_test)
X_train_padded_seqs = pad_sequences(X_train_word_ids, maxlen=doc_len)
X_test_padded_seqs = pad_sequences(X_test_word_ids, maxlen=doc_len)
left_train_word_ids = [[len(vocab)] + x[:-1] for x in X_train_word_ids]
left_test_word_ids = [[len(vocab)] + x[:-1] for x in X_test_word_ids]
right_train_word_ids = [x[1:] + [len(vocab)] for x in X_train_word_ids]
right_test_word_ids = [x[1:] + [len(vocab)] for x in X_test_word_ids]
# 分别对左边和右边的词进行编码
left_train_padded_seqs = pad_sequences(left_train_word_ids, maxlen=doc_len)
left_test_padded_seqs = pad_sequences(left_test_word_ids, maxlen=doc_len)
right_train_padded_seqs = pad_sequences(right_train_word_ids, maxlen=doc_len)
right_test_padded_seqs = pad_sequences(right_test_word_ids, maxlen=doc_len)
# 模型共有三个输入,分别是左词,右词和中心词
document = Input(shape = (doc_len, ), dtype = "int32")
left_context = Input(shape = (doc_len, ), dtype = "int32")
right_context = Input(shape = (doc_len, ), dtype = "int32")
# 构建词向量
embedder = Embedding(len(vocab) + 1, embedding_dim, input_length = doc_len)
doc_embedding = embedder(document)
l_embedding = embedder(left_context)
r_embedding = embedder(right_context)
模型的构建
forward = LSTM(256, return_sequences = True)(l_embedding) # 等式(1)
# 等式(2)
backward = LSTM(256, return_sequences = True, go_backwards = True)(r_embedding)
together = concatenate([forward, doc_embedding, backward], axis = 2) # 等式(3)
semantic = TimeDistributed(Dense(128, activation = "tanh"))(together) # 等式(4)
# 等式(5)
pool_rnn = Lambda(lambda x: backend.max(x, axis = 1), output_shape = (128, ))(semantic)
output = Dense(19, activation = "softmax")(pool_rnn) # 等式(6)和(7)
model = Model(inputs = [document, left_context, right_context], outputs = output)
模型训练和保存
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit([X_train_padded_seqs, left_train_padded_seqs, right_train_padded_seqs],y_train,
batch_size=32,
epochs=1,
validation_data=([X_test_padded_seqs, left_test_padded_seqs, right_test_padded_seqs], y_test))
model.save(model_path + 'rcnn.h5')
如果将全部数据进行训练则会花费较大时间,因此只用了一部分代码进行训练。
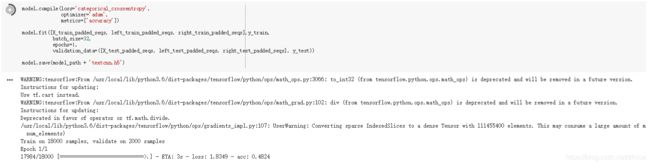
因为使用数据集较少,最后的精度不是很高只有0.48.如果用全部数据集训练相信精度可以提高。
# 评价
score = model.evaluate(X_test_padded_seqs, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
## 特征转换
xx_test_word_ids = tokenizer.texts_to_sequences(df_test['word_seg'])
xx_test_padded_seqs = pad_sequences(xx_test_word_ids, maxlen=doc_len)
## 预测
pred_prob = model.predict(xx_test_padded_seqs)
pred = pred_prob.argmax(axis=1)
## 结果保存
df_test['class'] = pred.tolist()
df_test['class'] = df_test['class'] + 1
df_result = df_test.loc[:, ['id','class']]
df_result.to_csv(result_path +'RCNN.csv',index=False)
最后的提交结果,好羞耻。等后续有时间再继续完善和尝试其他的模型。

task6
模型融合
机器学习系列之七】模型调优与模型融合(代码应用篇) - 多元思考力 - CSDN博客
Ensemble Learning-模型融合-Python实现 - AaronChou的博客 - CSDN博客
集成学习stacking - winycg的博客 - CSDN博客
机器学习中的Stacking模型融合 - 小码仔 - CSDN博客
首先尝试了以下代码进行stacking模型融合,该代码是没有用第三方库,程序也比较老,有一些接口已经改变,在测试后后已经不能够运行,自己尝试修正,没有成功。
# coding=utf8
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier
from sklearn.cross_validation import train_test_split
from sklearn.cross_validation import StratifiedKFold
import numpy as np
from sklearn.metrics import roc_auc_score
from sklearn.datasets.samples_generator import make_blobs
'''创建训练的数据集'''
data, target = make_blobs(n_samples=50000, centers=2, random_state=0, cluster_std=0.60)
'''模型融合中使用到的各个单模型'''
clfs = [RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
'''切分一部分数据作为测试集'''
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.33, random_state=2017)
dataset_blend_train = np.zeros((X.shape[0], len(clfs)))
dataset_blend_test = np.zeros((X_predict.shape[0], len(clfs)))
'''5折stacking'''
n_folds = 5
skf = list(StratifiedKFold(y, n_folds))
for j, clf in enumerate(clfs):
'''依次训练各个单模型'''
# print(j, clf)
dataset_blend_test_j = np.zeros((X_predict.shape[0], len(skf)))
for i, (train, test) in enumerate(skf):
'''使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。'''
# print("Fold", i)
X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]
clf.fit(X_train, y_train)
y_submission = clf.predict_proba(X_test)[:, 1]
dataset_blend_train[test, j] = y_submission
dataset_blend_test_j[:, i] = clf.predict_proba(X_predict)[:, 1]
'''对于测试集,直接用这k个模型的预测值均值作为新的特征。'''
dataset_blend_test[:, j] = dataset_blend_test_j.mean(1)
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_blend_test[:, j]))
# clf = LogisticRegression()
clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=30)
clf.fit(dataset_blend_train, y)
y_submission = clf.predict_proba(dataset_blend_test)[:, 1]
print("Linear stretch of predictions to [0,1]")
y_submission = (y_submission - y_submission.min()) / (y_submission.max() - y_submission.min())
print("blend result")
print("val auc Score: %f" % (roc_auc_score(y_predict, y_submission)))
来自github
尝试使用第三方库mlxtend实现stacking
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
use_probas=True,
average_probas=False,
meta_classifier=lr)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores =cross_val_score(clf, X, y,cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
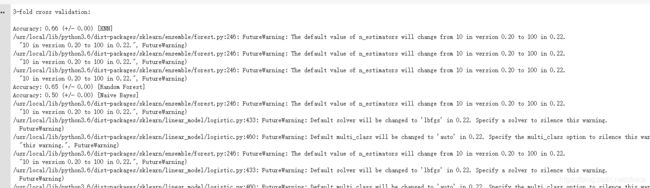
来自集成学习总结&Stacking利器(mlxtend库) - 法相的博客 - CSDN博客
集成学习还是要花费很长时间的,调参由于时间原因就没有进行。模型融合的效果并没有特别好。
看到其他博客有写道最开始对数据进行预处理时候词向量转化的参数不同对最后的结果影响很大。
“达观杯”文本智能处理挑战赛心得体会 - 丶小祖宗的博客 - CSDN博客
![]() 记录一下 下次尝试一下这个参数进行特征处理。
记录一下 下次尝试一下这个参数进行特征处理。
最后提交结果,比较纳闷的是训练的好好准确率也还可以,预测数据居然出现这么大的偏差,只比上次进步了一丁点。有点没搞明白。
