python爬虫实战一:豆瓣电影top250爬虫+分析
豆瓣电影top250爬虫+分析
- 前言
- 爬取
-
- 思路
- 代码
- 分析
-
- 前期准备
- 三大年份
- 三大导演
- 最佳编剧
- 两大演员
- 后记
-
- 一点想法
- 参考资料
前言
本文主要介绍了对豆瓣电影top250的爬取与分析。爬虫时主要运用的库是re,request,Beautifulsoup,lxml,分析时主要运用的是pandas,matplotlib。最后介绍了爬虫相关的一些参考资料,有兴趣的读者可以自行参阅。
爬取
爬虫,我觉得就是用计算机来代替人力,让其模拟人搜索,进行大量重复枯燥的工作。
关于爬虫,现在网上都有比较全面的爬虫教程,这里不多做赘述。我学习的教材主要是 Web Scraping with Python Collecting More Data from the Modern Web 和 用Python写网络爬虫,然后有问题就百度谷歌。不过建议在学爬虫之前,先自行学习一下HTML1、Xpath2、正则表达式3的知识,可以事半功倍。
思路
首先要找到要爬虫的网页,这里是豆瓣电影top250。然后通过 F12 查看网页源代码,检查元素,定位要爬取的信息,这里可以右击复制xpath,用于爬虫定位。

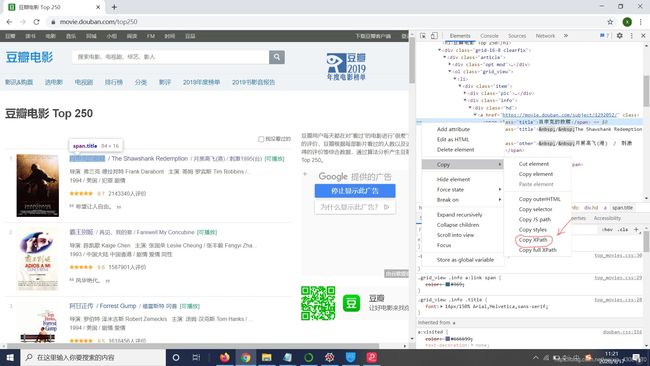 爬虫定位有三种方法:
爬虫定位有三种方法:
- 通过正则表达式定位
- 通过Beautifulsoup中find函数定位
- 通过lxml中Xpath定位
这里不多展开,具体可以参考 用Python写网络爬虫
观察一下网页,可以发现一共有10页,每页有25部电影,每页的域名有相似之处。所以,可以写一个循环,下载每一页的网站,得到该网站所有的电影链接,然后内部再写一个循环,下载每页的电影链接,爬取需要的内容信息。

最后将爬取的结果进行清洗,输出成csv文件。
代码
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 15 09:35:01 2020
@author: zxw
"""
# 引入库
import re
import pandas as pd
import time
import urllib.request
from lxml.html import fromstring
from bs4 import BeautifulSoup
# 下载链接
def download(url):
print('Downloading:', url)
request = urllib.request.Request(url)
request.add_header('User-agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36') #进行伪装
resp = urllib.request.urlopen(request)
html = resp.read().decode('utf-8')
return html
# 待爬取内容
name = []
year = []
rate = []
director = []
scriptwriter = []
protagonist = []
genre = []
country = []
language = []
length = []
# 循环爬取每页内容
for k in range(10):
url = download('https://movie.douban.com/top250?start={}&filter='.format(k*25))
time.sleep(5) #间隔5s,防止被封禁
#找出该页所有电影链接
Links = re.findall('https://movie\.douban\.com/subject/[0-9]+/', url)
movie_list = sorted(set(Links),key=Links.index)
for movie in movie_list:
url = download(movie)
time.sleep(5)
tree = fromstring(url)
soup = BeautifulSoup(url)
#利用正则表达式定位爬取
name.append(re.search('(?<=()).*(?=())',url).group())
year.append(re.search('(?<=(\()).*(?=(\)))', url).group())
rate.append(re.search('(?<=()).*(?=())', url).group())
#利用xpath定位爬取
director.append(tree.xpath('//*[@id="info"]/span[1]')[0].text_content())
scriptwriter.append(tree.xpath('//*[@id="info"]/span[2]')[0].text_content())
protagonist.append(tree.xpath('//*[@id="info"]/span[3]')[0].text_content())
#利用find_all爬取
genres = soup.find_all('span',{
'property':'v:genre'})
#将类型用'/'拼接
temp = []
for each in genres:
temp.append(each.get_text())
genre.append('/'.join(temp))
#利用find定位爬取
country.append(soup.find(text='制片国家/地区:').parent.next_sibling) #兄弟节点
language.append(soup.find(text='语言:').parent.next_sibling)
length.append(soup.find('span',{
'property':'v:runtime'}).get_text())
# 将list转化为dataframe
name_pd = pd.DataFrame(name)
year_pd = pd.DataFrame(year)
rate_pd = pd.DataFrame(rate)
director_pd = pd.DataFrame(director)
scriptwriter_pd = pd.DataFrame(scriptwriter)
protagonist_pd = pd.DataFrame(protagonist)
genre_pd = pd.DataFrame(genre)
country_pd = pd.DataFrame(country)
language_pd = pd.DataFrame(language)
length_pd = pd.DataFrame(length)
# 拼接
movie_data = pd.concat([name_pd,year_pd,rate_pd,director_pd,scriptwriter_pd,protagonist_pd,genre_pd,country_pd,language_pd,length_pd],axis=1)
movie_data.columns=['电影','年份','评分','导演','编剧','主演','类型','国家/地区','语言','时长']
#保留电影中文名
f = lambda x: re.split(' ',x)[0]
movie_data['电影'] = movie_data['电影'].apply(f)
#删去冗余部分
g = lambda x: x[4:-1] + x[-1]
movie_data['导演'] = movie_data['导演'].apply(g)
movie_data['编剧'] = movie_data['编剧'].apply(g)
movie_data['主演'] = movie_data['主演'].apply(g)
movie_data.head()
# 输出
outputpath='c:/Users/zxw/Desktop/修身/与自己/数据分析/数据分析/爬虫/豆瓣/data/movie.csv' ##这里需要改路径名
movie_data.to_csv(outputpath,sep=',',index=False,header=True,encoding='utf_8_sig')
结果展示如下,数据集见附件4

分析
本文接下来对爬取的电影数据做了一些简单的分析
前期准备
#引入库
import pandas as pd
import matplotlib.pyplot as plt
import re
#读取数据
movie_data = pd.read_csv('c:/Users/zxw/Desktop/修身/与自己/数据分析/数据分析/爬虫/豆瓣/data/movie.csv')
movie_data.head()
三大年份
year_counts = movie_data['年份'].value_counts()
year_counts.columns=['年份','次数']
plt.figure(figsize=(15, 6.5))
year_counts.sort_index().plot(kind='bar')

1994,2004,2010 是豆瓣电影top250出现最多的三个年份
三大导演
f = lambda x: re.split('/',x)
director_list = movie_data['导演'].apply(f)
directors = []
for element in director_list:
for director in element:
director = director.replace(" ", "")
directors.append(director)
directors_pd = pd.Series(directors)
directors_pd.value_counts().head(10)
史蒂文·斯皮尔伯格 7
克里斯托弗·诺兰 7
宫崎骏 7
李安 5
王家卫 5
大卫·芬奇 4
是枝裕和 4
李·昂克里奇 3
詹姆斯·卡梅隆 3
姜文 3
dtype: int64
斯皮尔伯格,诺兰,宫崎骏处于第一档,李安和王家卫是中国导演中上榜次数最多的
最佳编剧
scriptwriter_list = movie_data['编剧'].apply(f)
scriptwriters = []
for element in scriptwriter_list:
for scriptwriter in element:
scriptwriter = scriptwriter.replace(" ", "")
scriptwriters.append(scriptwriter)
scriptwriter_pd = pd.Series(scriptwriters)
scriptwriter_pd.value_counts().head(10)
宫崎骏 9
克里斯托弗·诺兰 7
史蒂夫·克洛夫斯 5
王家卫 5
J·K·罗琳 5
乔纳森·诺兰 5
安德鲁·尼科尔 4
彼特·道格特 4
是枝裕和 4
詹姆斯·卡梅隆 3
dtype: int64
宫崎骏nb
两大演员
actor_list = movie_data['主演'].apply(f)
actors = []
for element in actor_list:
for actor in element:
actor = actor.replace(" ", "")
actors.append(actor)
actors_pd = pd.Series(actors)
actors_pd.value_counts().head(10)
梁朝伟 8
张国荣 8
雨果·维文 7
张曼玉 7
艾伦·瑞克曼 7
加里·奥德曼 6
周星驰 6
马特·达蒙 6
莱昂纳多·迪卡普里奥 6
汤姆·汉克斯 6
dtype: int64
梁朝伟和张国荣上榜次数最多
具体的代码详见附件4
后记
一点想法
这是我个人的第一篇文章。我本人目前大四,数学应用数学专业,有志于从事数据科学相关的研究,正在几乎从零开始学习。最近学习了一周爬虫,完成了这个入门级爬虫实战项目,多有不足之处,欢迎各位读者不吝赐教。
以后我会不定期地更新一点我学习的内容,一来是对自己学习的一个总结,二来也希望可以帮助到别人。
千里之行,始于足下。路漫漫其修远兮,吾将上下而求索。
参考资料
HTML教程 ↩︎
Xpath教程 ↩︎
正则表达式 ↩︎
提取码:fim3 ↩︎ ↩︎