记一次生产MongoDB聚合游标遍历计数导致CPU过高及解决方案
在项目前期,为了赶业务需求进度,保证系统先上线,赢取用户,提前占领市场份额,开发的代码往往比较粗糙,考虑的问题不够全面。当用户慢慢变多,数据量上来之后,很多问题就会慢慢暴露出来。这些问题无论是在编码细节上、整体架构设计上以及技术选型上都会存在或多或少的问题。
来看一下MongoDB游标遍历导致的应用主机CPU使用率高问题,数据存放在MongoDB数据库中,该表数据量有100W左右。

在本次业务场景中,给用户展示的数据需要进行对聚合查询,由于数据量大,还需要分页,需要分页的话,每次聚合查询都需要进行总数查询,以及该次分页查询的量。
由于MongoDB聚合之后返回的是一个游标,没有总数量,前期的做法是聚合查询之后,为了获取聚合查询的数量,遍历游标,然后计数。伪代码如下:
BasicDBObject match = new BasicDBObject();
BasicDBObject sort = new BasicDBObject();
BasicDBObject group = new BasicDBObject();
BasicDBObject skip = new BasicDBObject();
BasicDBObject limit = new BasicDBObject();
int count;
AggregationOptions aggregationOptions = AggregationOptions.builder().allowDiskUse(true).build();
List basicDBObjects = Arrays.asList(match, sort, group, sort, skip, limit);
Cursor cursor = mongoTemplate.getCollection("test").aggregate(new ArrayList(), aggregationOptions);
if(cursor != null) {
while (cursor.hasNext()) {
cursor.next();
count++;
}
} 当用户在线人数多,数据量大的时候,CPU消耗飙高。通过dump日志文件分析,在进行游标遍历的时候消耗了较长时间,定位到问题代码块,因为每次游标遍历,都会进行应用与数据库的交互,从而消耗了CPU。
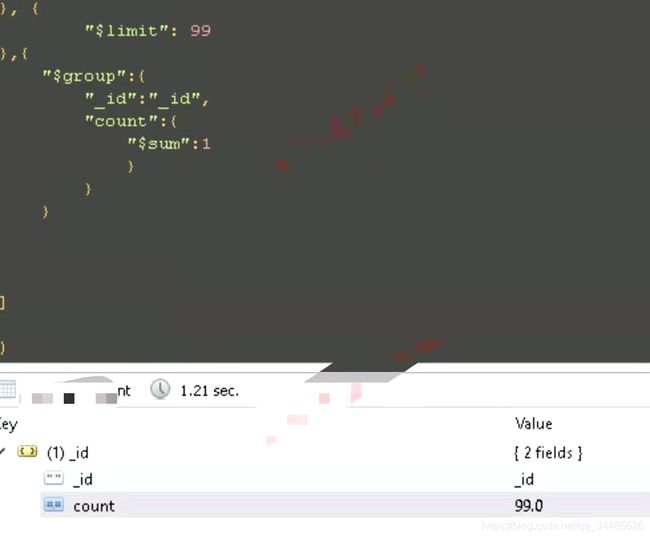
其实计数只需要对在聚合管道中对前面的聚合id再进行一次聚合sum统计即可,伪代码如下:
BasicDBObject basicDBObject = new BasicDBObject("_id", "_id");
basicDBObject.put("count", new BasicDBObject("$sum", 1));
DBObject countDBObject = new BasicDBObject("$group", basicDBObject);
List basicDBObjects = Arrays.asList(match, sort, group, sort, skip, limit, countDBObject);
Cursor countCur = mongoTemplate.getCollection("test").aggregate(basicDBObjects, aggregationOptions);
if(countCur != null) {
DBObject next = countCur.next();
if(next != null) {
if(null != next.get("count")) {
count = (Integer) next.get("count");
}
}
} match来匹配符合条件的数据,然后进行sort排序,之后对某个字段进行group组合,再进行一次排序,接着就是分页所需的skip和limit,最后对前面的_id进行sum统计,对得到的聚合结果取count值即可。
[
{
"$match": {}
},
{
"$sort": {
}
},
{
"$group": {
"id": {
"field": "$field"
}
}
},
{
"$sort": {}
},
{
"$skip": 0
},
{
"$limit": 99
},
{
"$group": {
"_id": "_id",
"count": {
"$sum": 1
}
}
}
]