Java中高级核心知识全面解析——Redis(亿级数据过滤和布隆过滤器【代码实现、Guava】、GeoHash查找附近的人【算法简述、如何获取】、持久化【简介、如何保证安全】)3
目录
- 一、亿级数据过滤和布隆过滤器
-
- 1.布隆过滤器
- 2.布隆过滤器代码实现
-
- 1)自己简单模拟实现
- 2)手动实现参考
- 3)使用 Google 开源的 Guava 中自带的布隆过滤器
- 二、GeoHash查找附近的人
-
- 1.使用数据库实现查找附近的人
- 2.GeoHash 算法简述
- 3.在Redis中使用Geo
-
- 1)增加
- 2)距离
- 3)获取元素位置
- 4)获取元素的 hash 值
- 5)附近的公司
- 6)注意事项
- 三、持久化
-
- 1.持久化简介
-
- 1)持久化发生了什么 | 从内存到磁盘
- 2)如何尽可能保证持久化的安全
- 2.Redis 中的两种持久化方式
-
- 1)方式一:快照
-
- ①、使用系统多进程 COW(Copy On Write) 机制 | fork 函数
- 2)方式二:AOF
-
- ①、AOF 重写
- ②、fsync
- 3)Redis 4.0 混合持久化
一、亿级数据过滤和布隆过滤器
1.布隆过滤器
布隆过滤器已在这篇文章中做过详细解读,感兴趣的同学可以点击这里跳转》》》》》
2.布隆过滤器代码实现
1)自己简单模拟实现
根据上面的基础理论,我们很容易就可以自己实现一个用于 简单模拟 的布隆过滤器数据结构:
public static class BloomFilter {
private byte[] data;
public BloomFilter(int initSize) {
this.data = new byte[initSize * 2]; // 默认创建大小 * 2 的空间
}
public void add(int key) {
int location1 = Math.abs(hash1(key) % data.length);
int location2 = Math.abs(hash2(key) % data.length);
int location3 = Math.abs(hash3(key) % data.length);
data[location1] = data[location2] = data[location3] = 1;
}
public boolean contains(int key) {
int location1 = Math.abs(hash1(key) % data.length);
int location2 = Math.abs(hash2(key) % data.length);
int location3 = Math.abs(hash3(key) % data.length);
return data[location1] * data[location2] * data[location3] == 1;
}
private int hash1(Integer key) {
return key.hashCode();
}
private int hash2(Integer key) {
int hashCode = key.hashCode();
return hashCode ^ (hashCode >>> 3);
}
private int hash3(Integer key) {
int hashCode = key.hashCode();
return hashCode ^ (hashCode >>> 16);
}
}
这里很简单,内部仅维护了一个 byte 类型的 data 数组,实际上 byte 仍然占有一个字节之多,可以优化成 bit来代替,这里也仅仅是用于方便模拟。另外我也创建了三个不同的hash函数,其实也就是借鉴HashMap哈希抖动的办法,分别使用自身的 hash和右移不同位数相异或的结果。并且提供了基础的 add 和 contains 方法。
下面我们来简单测试一下这个布隆过滤器的效果如何:
public static void main(String[] args) {
Random random = new Random();
// 假设我们的数据有 1 百万
int size = 1_000_000;
// 用一个数据结构保存一下所有实际存在的值
LinkedList<Integer> existentNumbers = new LinkedList<>();
BloomFilter bloomFilter = new BloomFilter(size);
for (int i = 0; i < size; i++) {
int randomKey = random.nextInt();
existentNumbers.add(randomKey);
bloomFilter.add(randomKey);
}
// 验证已存在的数是否都存在
AtomicInteger count = new AtomicInteger();
AtomicInteger finalCount = count;
existentNumbers.forEach(number -> {
if (bloomFilter.contains(number)) {
finalCount.incrementAndGet();
}
});
System.out.printf("实际的数据量: %d, 判断存在的数据量: %d \n", size, count.get());
// 验证10个不存在的数
count = new AtomicInteger();
while (count.get() < 10) {
int key = random.nextInt();
if (existentNumbers.contains(key)) {
continue;
} else {
// 这里一定是不存在的数
System.out.println(bloomFilter.contains(key));
count.incrementAndGet();
}
}
}
输出如下:
实际的数据量: 1000000, 判断存在的数据量: 1000000
false
true
false
true
true
true
false
false
true
false
这就是前面说到的,当布隆过滤器说某个值 存在时,这个值 可能不存在,当它说某个值不存在时,那就 肯定不存在,并且还有一定的误判率…
2)手动实现参考
当然上面的版本特别 low,不过主体思想是不差的,这里也给出一个好一些的版本用作自己实现测试的参考:
import java.util.BitSet;
public class MyBloomFilter {
/**
* 位数组的大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组可以创建 6 个不同的哈希函数
*/
private static final int[] SEEDS = new int[]{
3, 13, 46, 71, 91, 134};
/**
* 位数组。数组中的元素只能是 0 或者 1
*/
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* 存放包含 hash 函数的类的数组
*/
private SimpleHash[] func = new SimpleHash[SEEDS.length];
/**
* 初始化多个包含 hash 函数的类的数组,每个类中的 hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/**
* 静态内部类。用于 hash 操作!
*/
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 hash 值
*/
public int hash(Object value) {
int h;
return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h =
value.hashCode()) ^ (h >>> 16)));
}
}
}
3)使用 Google 开源的 Guava 中自带的布隆过滤器
自己实现的目的主要是为了让自己搞懂布隆过滤器的原理,Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器。
首先我们需要在项目中引入 Guava 的依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
实际使用如下:
我们创建了一个最多存放 最多 1500 个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之(0.01)
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
1500,
0.01);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
在我们的示例中,当 mightContain()方法返回 true 时,我们可以 99% 确定该元素在过滤器中,当过滤器返回 false 时,我们可以 100% 确定该元素不存在于过滤器中。
Guava 提供的布隆过滤器的实现还是很不错的 (想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用 (另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了。
小插曲:
更多阿里、腾讯、美团、京东等一线互联网大厂Java面试真题;包含:基础、并发、锁、JVM、设计模式、数据结构、反射/IO、数据库、Redis、Spring、消息队列、分布式、Zookeeper、Dubbo、Mybatis、Maven、面经等。
更多Java程序员技术进阶小技巧;例如高效学习(如何学习和阅读代码、面对枯燥和量大的知识)高效沟通(沟通方式及技巧、沟通技术)
更多Java大牛分享的一些职业生涯分享文档
请点击这里添加》》》》》》》》》社群,免费获取
比你优秀的对手在学习,你的仇人在磨刀,你的闺蜜在减肥,隔壁老王在练腰, 我们必须不断学习,否则我们将被学习者超越!
趁年轻,使劲拼,给未来的自己一个交代!
二、GeoHash查找附近的人
像微信 “附近的人”,美团 “附近的餐厅”,支付宝共享单车 “附近的车” 是怎么设计实现的呢?
1.使用数据库实现查找附近的人
我们都知道,地球上的任何一个位置都可以使用二维的 经纬度 来表示,经度范围 [-180, 180],纬度范围 [-90, 90],纬度正负以赤道为界,北正南负,经度正负以本初子午线 (英国格林尼治天文台) 为界,东正西负。比如说,北京人民英雄纪念碑的经纬度坐标就是 (39.904610, 116.397724),都是正数,因为中国位于东北半球。
所以,当我们使用数据库存储了所有人的 经纬度 信息之后,我们就可以基于当前的坐标节点,来划分出一个矩形的范围,来得知附近的人,如下图:
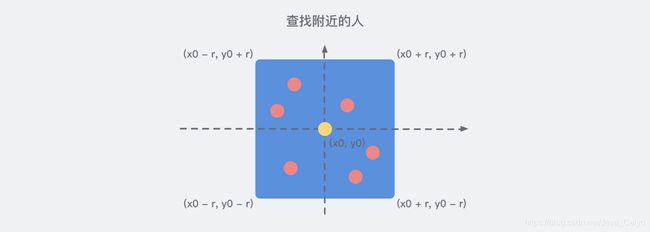
所以,我们很容易写出下列的伪 SQL 语句:
SELECT id FROM positions WHERE x0 - r < x < x0 + r AND y0 - r < y < y0 + r
如果我们还想进一步地知道与每个坐标元素的距离并排序的话,就需要一定的计算。
当两个坐标元素的距离不是很远的时候,我们就可以简单利用 勾股定理 就能够得出他们之间的 距离。不过需要注意的是,地球不是一个标准的球体,经纬度的密度 是 不一样 的,所以我们使用勾股定理计算平方之后再求和时,需要按照一定的系数 加权 再进行求和。当然,如果不准求精确的话,加权也不必了。
参考下方 参考资料 2 我们能够差不多能写出如下优化之后的 SQL 语句来:(仅供参考)
SELECT
*
FROM
users_location
WHERE
latitude > '.$lat.' - 1
AND latitude < '.$lat.' + 1
AND longitude > '.$lon.' - 1
AND longitude < '.$lon.' + 1
ORDER BY
ACOS(SIN( ( '.$lat.' * 3.1415 ) / 180 ) * SIN( ( latitude * 3.1415 ) / 180 ) + COS( ( '.$lat.' * 3.1415 ) / 180 ) *
COS( ( latitude * 3.1415 ) / 180 ) * COS( ( '.$lon.' * 3.1415 ) / 180 - ( longitude * 3.1415 ) / 180 ) ) * 6380 ASC LIMIT 10 ';
为了满足高性能的矩形区域算法,数据表也需要把经纬度坐标加上 双向复合索引 (x, y),这样可以满足最大优化查询性能。
2.GeoHash 算法简述
这是业界比较通用的,用于 地理位置距离排序 的一个算法,Redis 也采用了这样的算法。GeoHash算法将 二维的经纬度 数据映射到 一维 的整数,这样所有的元素都将在挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。当我们想要计算 「附近的人时」,首先将目标位置映射到这条线上,然后在这个一维的线上获取附近的点就行了。
它的核心思想就是把整个地球看成是一个 二维的平面,然后把这个平面不断地等分成一个一个小的方格,每一个 坐标元素都位于其中的 唯一一个方格 中,等分之后的 方格越小,那么坐标也就越精确,类似下图:
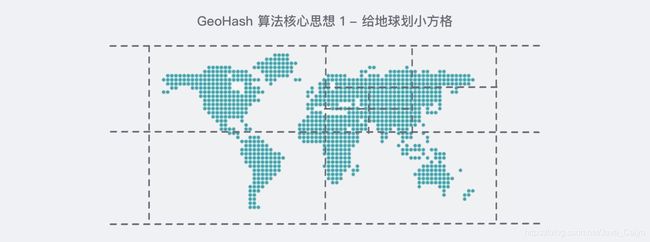
经过划分的地球,我们需要对其进行编码:
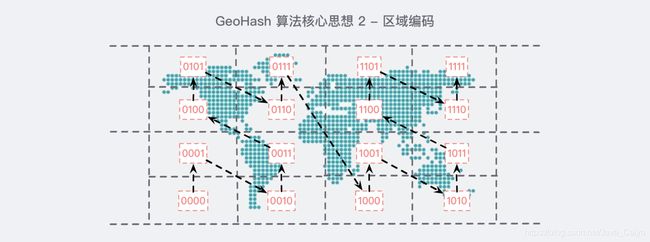
经过这样顺序的编码之后,如果你仔细观察一会儿,你就会发现一些规律:
- 横着的所有编码中,第 2 位和第 4 位都是一样的,例如第一排第一个
0101和第二个0111,他们的第 2 位和第 4 位都是1; - 竖着的所有编码中,第 1 位和第 3 位是递增的,例如第一排第一个
0101,如果单独把第 1 位和第 3 位拎出来的话,那就是 00 ,同理看第一排第二个0111,同样的方法第 1 位和第 3 位拎出来是01,刚好是00递增一个;
通过这样的规律我们就把每一个小方块儿进行了一定顺序的编码,这样做的 好处 是显而易见的:每一个元素坐标既能够被 唯一标识 在这张被编码的地图上,也不至于 暴露特别的具体的位置,因为区域是共享的,我可以告诉你我就在公园附近,但是在具体的哪个地方你就无从得知了。
总之,我们通过上面的思想,能够把任意坐标变成一串二进制的编码了,类似于11010010110001000100这样 (注意经度和维度是交替出现的哦…),通过这个整数我们就可以还原出元素的坐标,整数越长,还原出来的坐标值的损失程序就越小。对于 “附近的人” 这个功能来说,损失的一点经度可以忽略不计。
最后就是一个 Base32 (0~9, a~z, 去掉 a/i/l/o 四个字母) 的编码操作,让它变成一个字符串,例如上面那一串儿就变成了 wx4g0ec1 。
在 Redis 中,经纬度使用 52 位的整数进行编码,放进了 zset 里面,zset的 value 是元素的 key, score 是 GeoHash 的 52 位整数值。zset 的score虽然是浮点数,但是对于 52 位的整数值来说,它可以无损存储。
3.在Redis中使用Geo
下方内容引自 参考资料 1 - 《Redis 深度历险》
在使用 Redis 进行 Geo 查询 时,我们要时刻想到它的内部结构实际上只是一个 zset(skiplist)。通过zset 的 score 排序就可以得到坐标附近的其他元素 (实际情况要复杂一些,不过这样理解足够了),通过将 score 还原成坐标值就可以得到元素的原始坐标了。
Redis 提供的 Geo 指令只有 6 个,很容易就可以掌握。
1)增加
geoadd指令携带集合名称以及多个经纬度名称三元组,注意这里可以加入多个三元组。
127.0.0.1:6379> geoadd company 116.48105 39.996794 juejin
(integer) 1
127.0.0.1:6379> geoadd company 116.514203 39.905409 ireader
(integer) 1
127.0.0.1:6379> geoadd company 116.489033 40.007669 meituan
(integer) 1
127.0.0.1:6379> geoadd company 116.562108 39.787602 jd 116.334255 40.027400
xiaomi
(integer) 2
不过很奇怪… Redis 没有直接提供 Geo 的删除指令,但是我们可以通过 zset 相关的指令来操作 Geo 数据,所以元素删除可以使用 zrem 指令即可。
2)距离
geodist指令可以用来计算两个元素之间的距离,携带集合名称、2 个名称和距离单位。
127.0.0.1:6379> geodist company juejin ireader km
"10.5501"
127.0.0.1:6379> geodist company juejin meituan km
"1.3878"
127.0.0.1:6379> geodist company juejin jd km
"24.2739"
127.0.0.1:6379> geodist company juejin xiaomi km
"12.9606"
127.0.0.1:6379> geodist company juejin juejin km
"0.0000"
我们可以看到掘金离美团最近,因为它们都在望京。距离单位可以是 m 、 km 、 ml 、 ft ,分别代表米、千米、英里和尺。
3)获取元素位置
geopos指令可以获取集合中任意元素的经纬度坐标,可以一次获取多个。
127.0.0.1:6379> geopos company juejin
1) 1) "116.48104995489120483"
2) "39.99679348858259686"
127.0.0.1:6379> geopos company ireader
1) 1) "116.5142020583152771"
2) "39.90540918662494363"
127.0.0.1:6379> geopos company juejin ireader
1) 1) "116.48104995489120483"
2) "39.99679348858259686"
2) 1) "116.5142020583152771"
2) "39.90540918662494363"
我们观察到获取的经纬度坐标和 geoadd 进去的坐标有轻微的误差,原因是 Geohash 对二维坐标进行的一维映射是有损的,通过映射再还原回来的值会出现较小的差别。对于 「附近的人」 这种功能来说,这点误差根本不是事。
4)获取元素的 hash 值
geohash 可以获取元素的经纬度编码字符串,上面已经提到,它是 base32编码。 你可以使用这个编码值去 http://geohash.org/${hash} 中进行直接定位,它是 Geohash 的标准编码值。
127.0.0.1:6379> geohash company ireader
1) "wx4g52e1ce0"
127.0.0.1:6379> geohash company juejin
1) "wx4gd94yjn0"
让我们打开地址 http://geohash.org/wx4g52e1ce0 ,观察地图指向的位置是否正确:

很好,就是这个位置,非常准确。
5)附近的公司
georadiusbymember指令是最为关键的指令,它可以用来查询指定元素附近的其它元素,它的参数非常复杂。
# 范围 20 公里以内最多 3 个元素按距离正排,它不会排除自身
127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 asc
1) "ireader"
2) "juejin"
3) "meituan"
# 范围 20 公里以内最多 3 个元素按距离倒排
127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 desc
1) "jd"
2) "meituan"
3) "juejin"
# 三个可选参数 withcoord withdist withhash 用来携带附加参数
# withdist 很有用,它可以用来显示距离
127.0.0.1:6379> georadiusbymember company ireader 20 km withcoord withdist withhash count 3 asc
1) 1) "ireader"
2) "0.0000"
3) (integer) 4069886008361398
4) 1) "116.5142020583152771"
2) "39.90540918662494363"
2) 1) "juejin"
2) "10.5501"
3) (integer) 4069887154388167
4) 1) "116.48104995489120483"
2) "39.99679348858259686"
3) 1) "meituan"
2) "11.5748"
3) (integer) 4069887179083478
4) 1) "116.48903220891952515"
2) "40.00766997707732031"
除了georadiusbymember指令根据元素查询附近的元素,Redis 还提供了根据坐标值来查询附近的元素,这个指令更加有用,它可以根据用户的定位来计算「附近的车」,「附近的餐馆」等。它的参数和georadiusbymember基本一致,除了将目标元素改成经纬度坐标值:
127.0.0.1:6379> georadius company 116.514202 39.905409 20 km withdist count 3 asc
1) 1) "ireader"
2) "0.0000"
2) 1) "juejin"
2) "10.5501"
3) 1) "meituan"
2) "11.5748"
6)注意事项
在一个地图应用中,车的数据、餐馆的数据、人的数据可能会有百万千万条,如果使用 Redis 的Geo数据结构,它们将 全部放在一个 zset 集合中。在 Redis 的集群环境中,集合可能会从一个节点迁移到另一个节点,如果单个 key 的数据过大,会对集群的迁移工作造成较大的影响,在集群环境中单个 key对应的数据量不宜超过 1M,否则会导致集群迁移出现卡顿现象,影响线上服务的正常运行。
所以,这里建议 Geo 的数据使用 单独的 Redis 实例部署,不使用集群环境。
如果数据量过亿甚至更大,就需要对 Geo 数据进行拆分,按国家拆分、按省拆分,按市拆分,在人口特大城市甚至可以按区拆分。这样就可以显著降低单个 zset 集合的大小。
小插曲:
更多阿里、腾讯、美团、京东等一线互联网大厂Java面试真题;包含:基础、并发、锁、JVM、设计模式、数据结构、反射/IO、数据库、Redis、Spring、消息队列、分布式、Zookeeper、Dubbo、Mybatis、Maven、面经等。
更多Java程序员技术进阶小技巧;例如高效学习(如何学习和阅读代码、面对枯燥和量大的知识)高效沟通(沟通方式及技巧、沟通技术)
更多Java大牛分享的一些职业生涯分享文档
请点击这里添加》》》》》》》》》社群,免费获取
比你优秀的对手在学习,你的仇人在磨刀,你的闺蜜在减肥,隔壁老王在练腰, 我们必须不断学习,否则我们将被学习者超越!
趁年轻,使劲拼,给未来的自己一个交代!
三、持久化
1.持久化简介
Redis 的数据 全部存储 在 内存 中,如果 突然宕机,数据就会全部丢失,因此必须有一套机制来保证Redis的数据不会因为故障而丢失,这种机制就是 Redis 的 持久化机制,它会将内存中的数据库状态保存到磁盘中。
1)持久化发生了什么 | 从内存到磁盘
我们来稍微考虑一下 Redis 作为一个 “内存数据库” 要做的关于持久化的事情。通常来说,从客户端发起请求开始,到服务器真实地写入磁盘,需要发生如下几件事情:
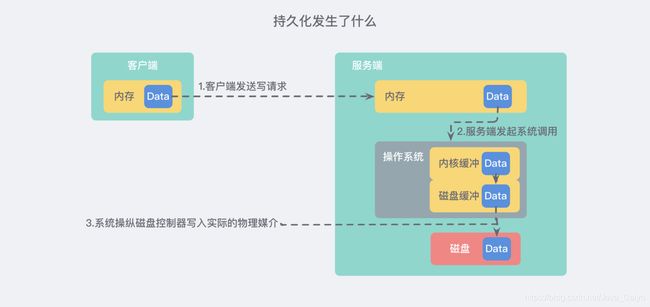
详细版 的文字描述大概就是下面这样:
- 客户端向数据库 发送写命令 (数据在客户端的内存中)
- 数据库 接收 到客户端的 写请求 (数据在服务器的内存中)
- 数据库 调用系统 API 将数据写入磁盘 (数据在内核缓冲区中)
- 操作系统将 写缓冲区 传输到 磁盘控控制器 (数据在磁盘缓存中)
- 操作系统的磁盘控制器将数据 写入实际的物理媒介 中 (数据在磁盘中)
注意: 上面的过程其实是 极度精简 的,在实际的操作系统中,缓存 和缓冲区会比这多得多…
2)如何尽可能保证持久化的安全
如果我们故障仅仅涉及到 软件层面 (该进程被管理员终止或程序崩溃) 并且没有接触到内核,那么在 上 述步骤 3 成功返回之后,我们就认为成功了。即使进程崩溃,操作系统仍然会帮助我们把数据正确地写入磁盘。
如果我们考虑 停电/ 火灾 等 更具灾难性 的事情,那么只有在完成了第 5 步之后,才是安全的。
所以我们可以总结得出数据安全最重要的阶段是:步骤三、四、五,即:
- 数据库软件调用写操作将用户空间的缓冲区转移到内核缓冲区的频率是多少?
- 内核多久从缓冲区取数据刷新到磁盘控制器?
- 磁盘控制器多久把数据写入物理媒介一次?
- 注意: 如果真的发生灾难性的事件,我们可以从上图的过程中看到,任何一步都可能被意外打断丢失,所以只能 尽可能地保证 数据的安全,这对于所有数据库来说都是一样的。
我们从 第三步 开始。Linux 系统提供了清晰、易用的用于操作文件的 POSIX file API , 20 多年过去,仍然还有很多人对于这一套 API 的设计津津乐道,我想其中一个原因就是因为你光从API 的命名就能够很清晰地知道这一套 API 的用途:
int open(const char *path, int oflag, .../*,mode_t mode */);
int close (int filedes);int remove( const char *fname );
ssize_t write(int fildes, const void *buf, size_t nbyte);
ssize_t read(int fildes, void *buf, size_t nbyte);
所以,我们有很好的可用的 API 来完成 第三步,但是对于成功返回之前,我们对系统调用花费的时间没有太多的控制权。
然后我们来说说 第四步。我们知道,除了早期对电脑特别了解那帮人 (操作系统就这帮人搞的),实际的物理硬件都不是我们能够 直接操作 的,都是通过 操作系统调用 来达到目的的。为了防止过慢的 I/O 操作拖慢整个系统的运行,操作系统层面做了很多的努力,譬如说 上述第四步 提到的 写缓冲区,并不是所有的写操作都会被立即写入磁盘,而是要先经过一个缓冲区,默认情况下,Linux 将在 30 秒 后实际提交写入。
但是很明显,30 秒 并不是 Redis 能够承受的,这意味着,如果发生故障,那么最近 30 秒内写入的所有数据都可能会丢失。幸好 PROSIX API 提供了另一个解决方案:fsync ,该命令会 强制 内核将 缓冲区 写入 磁盘,但这是一个非常消耗性能的操作,每次调用都会 阻塞等待 直到设备报告 IO 完成,所以一般在生产环境的服务器中,Redis 通常是每隔 1s 左右执行一次 fsync 操作。
到目前为止,我们了解到了如何控制 第三步 和 第四步 ,但是对于第五步,我们 完全无法控制。也许一些内核实现将试图告诉驱动实际提交物理介质上的数据,或者控制器可能会为了提高速度而重新排序写操作,不会尽快将数据真正写到磁盘上,而是会等待几个多毫秒。这完全是我们无法控制的。
2.Redis 中的两种持久化方式
1)方式一:快照
Redis 快照 是最简单的 Redis 持久性模式。当满足特定条件时,它将生成数据集的时间点快照,例如,如果先前的快照是在2分钟前创建的,并且现在已经至少有 100 次新写入,则将创建一个新的快照。此条件可以由用户配置 Redis 实例来控制,也可以在运行时修改而无需重新启动服务器。快照作为包含整个数据集的单个 .rdb 文件生成。
但我们知道,Redis 是一个 单线程 的程序,这意味着,我们不仅仅要响应用户的请求,还需要进行内存快照。而后者要求 Redis 必须进行 IO 操作,这会严重拖累服务器的性能。
还有一个重要的问题是,我们在 持久化的同时,内存数据结构 还可能在 变化,比如一个大型的 hash字典正在持久化,结果一个请求过来把它删除了,可是这才刚持久化结束,咋办?
①、使用系统多进程 COW(Copy On Write) 机制 | fork 函数
操作系统多进程 COW(Copy On Write) 机制 拯救了我们。Redis 在持久化时会调用 glibc 的函数fork产生一个子进程,简单理解也就是基于当前进程 复制 了一个进程,主进程和子进程会共享内存里面的代码块和数据段:
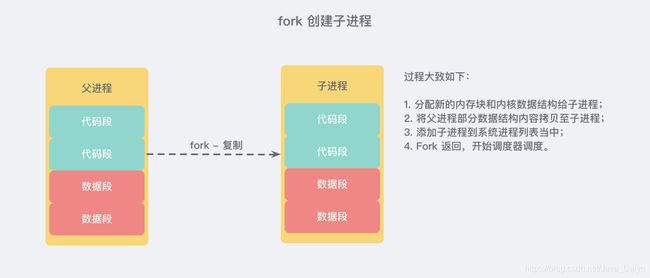
这里多说一点,为什么 fork 成功调用后会有两个返回值呢? 因为子进程在复制时复制了父进程的堆栈段,所以两个进程都停留在了 fork 函数中 (都在同一个地方往下继续"同时"执行),等待返回,所以一次在父进程中返回子进程的 pid,另一次在子进程中返回零,系统资源不够时返回负数。 (伪代码如下)
pid = os.fork()
if pid > 0:
handle_client_request() # 父进程继续处理客户端请求
if pid == 0:
handle_snapshot_write() # 子进程处理快照写磁盘
if pid < 0:
# fork error
所以 快照持久化 可以完全交给 子进程 来处理,父进程 则继续 处理客户端请求。子进程 做数据持久化,它 不会修改现有的内存数据结构,它只是对数据结构进行遍历读取,然后序列化写到磁盘中。但是父进程 不一样,它必须持续服务客户端请求,然后对 内存数据结构进行不间断的修改。
这个时候就会使用操作系统的 COW 机制来进行 数据段页面 的分离。数据段是由很多操作系统的页面组合而成,当父进程对其中一个页面的数据进行修改时,会将被共享的页面复制一份分离出来,然后 对这个复制的页面进行修改。这时 子进程 相应的页面是 没有变化的,还是进程产生时那一瞬间的数据。
子进程因为数据没有变化,它能看到的内存里的数据在进程产生的一瞬间就凝固了,再也不会改变,这也是为什么 Redis 的持久化 叫「快照」的原因。接下来子进程就可以非常安心的遍历数据了进行序列化写磁盘了。
2)方式二:AOF
快照不是很持久。如果运行 Redis 的计算机停止运行,电源线出现故障或者您 kill -9 的实例意外发生,则写入 Redis 的最新数据将丢失。尽管这对于某些应用程序可能不是什么大问题,但有些使用案例具有充分的耐用性,在这些情况下,快照并不是可行的选择。
AOF(Append Only File - 仅追加文件) 它的工作方式非常简单:每次执行 修改内存 中数据集的写操作时,都会 记录 该操作。假设 AOF 日志记录了自 Redis 实例创建以来 所有的修改性指令序列,那么就可以通过对一个空的 Redis 实例 顺序执行所有的指令,也就是 「重放」,来恢复 Redis 当前实例的内存数据结构的状态。
为了展示 AOF 在实际中的工作方式,我们来做一个简单的实验:
./redis-server --appendonly yes # 设置一个新实例为 AOF 模式
然后我们执行一些写操作:
redis 127.0.0.1:6379> set key1 Hello
OK
redis 127.0.0.1:6379> append key1 " World!"
(integer) 12
redis 127.0.0.1:6379> del key1
(integer) 1
redis 127.0.0.1:6379> del non_existing_key
(integer) 0
前三个操作实际上修改了数据集,第四个操作没有修改,因为没有指定名称的键。这是 AOF 日志保存的文本:
$ cat appendonly.aof
*2
$6
SELECT
$1
0
*3
$3
set
$4
key1
$5
Hello
*3
$6
append
$4
key1
$7
World!
*2
$3
del
$4
key1
如您所见,最后的那一条 DEL` 指令不见了,因为它没有对数据集进行任何修改。
就是这么简单。当 Redis 收到客户端修改指令后,会先进行参数校验、逻辑处理,如果没问题,就 立即将该指令文本 存储 到 AOF 日志中,也就是说,先执行指令再将日志存盘。这一点不同于 MySQL 、LevelDB、 HBase 等存储引擎,如果我们先存储日志再做逻辑处理,这样就可以保证即使宕机了,我们仍然可以通过之前保存的日志恢复到之前的数据状态,但是 Redis 为什么没有这么做呢?
Emmm… 没找到特别满意的答案,引用一条来自知乎上的回答吧:
- @缘于专注 - 我甚至觉得没有什么特别的原因。仅仅是因为,由于AOF文件会比较大,为了避免写入无效指令(错误指令),必须先做指令检查?如何检查,只能先执行了。因为语法级别检查并不能保证指令的有效性,比如删除一个不存在的key。而MySQL这种是因为它本身就维护了所有的表的信息,所以可以语法检查后过滤掉大部分无效指令直接记录日志,然后再执行。
①、AOF 重写
Redis 在长期运行的过程中,AOF 的日志会越变越长。如果实例宕机重启,重放整个 AOF 日志会非常耗时,导致长时间 Redis 无法对外提供服务。所以需要对 AOF 日志 “瘦身”。
Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身。其 原理 就是 开辟一个子进程 对内存进行 遍历 转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件 中。序列化完毕后再将操作期间发生的 增量 AOF 日志 追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了,瘦身工作就完成了。
②、fsync
AOF 日志是以文件的形式存在的,当程序对 AOF 日志文件进行写操作时,实际上是将内容写到了内核为文件描述符分配的一个内存缓存中,然后内核会异步将脏数据刷回到磁盘的。
就像我们 上方第四步 描述的那样,我们需要借助glibc 提供的fsync(int fd)函数来讲指定的文件内容强制从内核缓存刷到磁盘。但 “强制开车” 仍然是一个很消耗资源的一个过程,需要 “节制”!通常来说,生产环境的服务器,Redis 每隔 1s 左右执行一次 fsync 操作就可以了。
Redis 同样也提供了另外两种策略,一个是 永不 fsync ,来让操作系统来决定合适同步磁盘,很不安全,另一个是 来一个指令就 fsync一次,非常慢。但是在生产环境基本不会使用,了解一下即可。
3)Redis 4.0 混合持久化
重启 Redis 时,我们很少使用 rdb 来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重放,但是重放 AOF 日志性能相对 rdb 来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很长的时间。
Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是 自持久化开始到持久化结束 的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小:
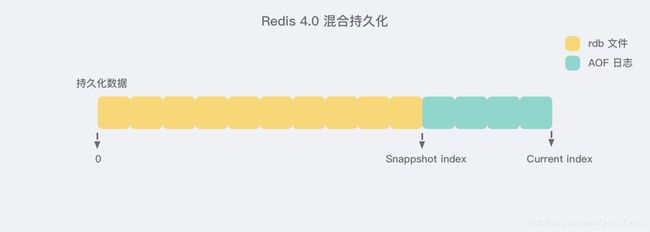
于是在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的AOF全量文件重放,重启效率因此大幅得到提升。
参考资料:《Java中高级核心知识全面解析》限量100份,有一些人已经通过我之前的文章获取了哦!
名额有限先到先得!!!
有想要获取这份学习资料的同学可以点击这里免费获取》》》》》》》