Python爬虫:苏宁Ajax页面爬取
文章目录
- 杂
- 参考
- 什么是Ajax
- 为什么要应对Ajax作处理
- Ajax的原理
- 爬取思路分析
- 代码实现
杂
本来是应付一下课设,做过算过,但是做着做着发现对于技术的热情早已在半年的高数政治中磨灭殆尽。所以将此博客作为回归后的第一篇博客,尽力耕耘。I’ m back.
参考
博客园:爬虫—Ajax数据爬取
什么是Ajax
Ajax(Asynchronous JavaScript and XML)是一种异步刷新的技术,在网页中的体现为:很多网页都有下滑查看更多的选项。比如,就拿新浪微博主页来说。一直往下滑,看到几个微博之后内容暂时就没有了,但是会出现一个加载的动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程。
为什么要应对Ajax作处理
用requests库对url发起一次GET请求,响应的HTML一共有2592行
 在浏览器上查看相同页面,一直往下拉,直到不能加载更多
在浏览器上查看相同页面,一直往下拉,直到不能加载更多
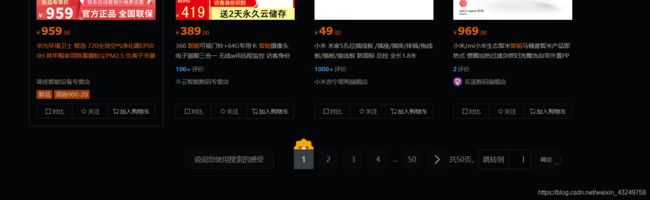 此时用view-resource查看当前页面的HTML,一共有3697行
此时用view-resource查看当前页面的HTML,一共有3697行

也就是说,如果只是简单的对url发起一次GET请求,实际上是无法拿到这个页面的全部信息的,因此需要对使用了Ajax的网页作处理。
Ajax的原理
发送Ajax请求到网页更新的过程可以简单的分为三步:
1.发送请求
2.解析内容
3.渲染页面

爬取思路分析
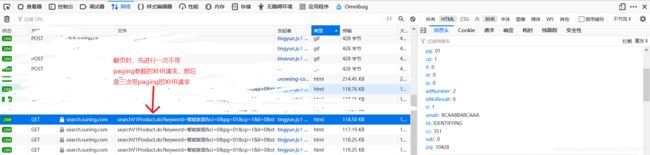
使用Firefox浏览器,F12,网络,请求类型选 XHR,即可看到所有的XHR请求
 上一步的加载更多页面,一共发起了三次对HTML的XHR请求
上一步的加载更多页面,一共发起了三次对HTML的XHR请求
选中第一个
查看其响应内容和载荷
 在网页上显示的是这部分
在网页上显示的是这部分
 其中,XHR的GET请求的参数是
其中,XHR的GET请求的参数是
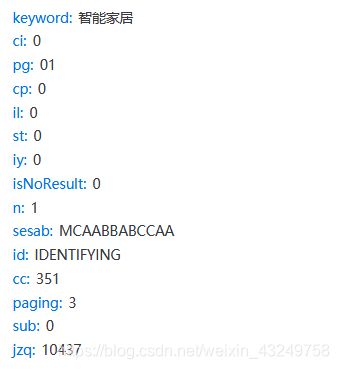
参数中最重要的是
cp:代表商品搜索结果的页数
paging:每一页中XHR请求的次数
对同一搜索结果的其他页面进行XHR请求时,还有一些不同的参数,稍后统一整合一下
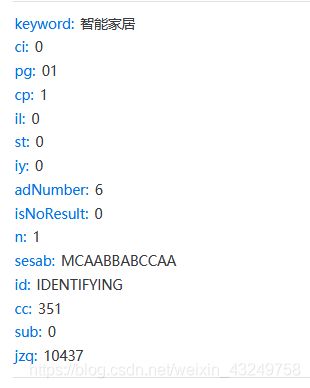
如果是搜索结果的第一页,浏览器首先对一个原始url进行GET请求,随着鼠标下拉,进行三次加载页面,即XHR请求。

点击翻页时,浏览器先发起一次XHR请求,这次请求没有paging参数,随着鼠标下拉,进行三次加载页面,即XHR请求。
 查看XHR响应的payload,我想要的商品详情页的url存放在:
查看XHR响应的payload,我想要的商品详情页的url存放在:
class为sellPoint的a标签的href属性值,稍后用pyquery对其进行提取

代码实现
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author: 无名Joker
@time:2021/01/10
Purpose:
Arguments:
Outputs:
"""
import requests
from requests.exceptions import HTTPError
from pyquery import PyQuery as pq
import time
# 爬虫头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.1'
'32 Safari/537.36 QIHU 360SE'}
# 关键词列表
keywords = ['智能家居', '智能手环', '智能手表', '扫地机器人']
# 苏宁网址
su_ning_url = 'https://search.suning.com'
# ajax请求的url
ajax_url = su_ning_url + '/emall/searchV1Product.do'
# hrefs
hrefs = []
# 封装了错误处理的请求方法,返回响应文本
def get_response(url, params=None):
try:
response = requests.get(url, params=params, headers=headers, verify=False)
# 延时1s,防止IP被ban
time.sleep(1)
return response.text
except HTTPError:
print("HTTP Error!")
except ConnectionError:
print("Failed to connect!")
# 输入:html
# 输出:符合条件的节点的href值
def href_data_wash(html):
# 用得到的html文本生成一个pq对象
doc = pq(html)
# 找子节点中所有class为sellPoint的节点,生成迭代器
items = doc.find('.sellPoint').items()
for item in items:
# 将节点中href属性的值添加至列表
hrefs.append(item.attr('href'))
# 参数:搜索关键字、页号
def get_hrefs(keyword, page):
hrefs = []
# 如果是搜索结果的第一页
if page is 1:
original_url = su_ning_url + '/' + keyword + '/'
# 先拿到原始页面的html
response_html = get_response(original_url)
href_data_wash(response_html)
# 如果不是搜索结果的第一页,则此页的首次ajax请求没有paging参数
else:
params = {
'keyword': keyword,
'ci': '0',
'pg': '01',
'cp': page-1,
'il': '0',
'st': '0',
'iy': '0',
'isNoResult': '0',
'adNumber': '6',
'n': '1',
'sesab': 'ACAABBABCAAA',
'id': 'IDENTIFYING',
'cc': '351',
'sub': '0',
'jzq': '10437',
}
response_html = get_response(ajax_url, params)
href_data_wash(response_html)
# 无论是不是第一页,都有每页三次的Ajax响应
for paging in range(1, 4, 1):
params = {
'keyword': keyword,
'ci': '0',
'pg': '01',
'cp': page-1,
'il': '0',
'st': '0',
'iy': '0',
'isNoResult': '0',
'adNumber': '6',
'n': '1',
'sesab': 'ACAABBABCAAA',
'id': 'IDENTIFYING',
'cc': '351',
'paging': paging, # Ajax页号
'sub': '0',
'jzq': '10437',
}
response_html = get_response(ajax_url, params)
href_data_wash(response_html)
return hrefs
if __name__ == '__main__':
get_hrefs(keywords[0], 1)
for i in hrefs:
print(i)
print(len(hrefs))
如:对第五页进行href提取
 结果为
结果为
 共120个商品详情页URL提取成功
共120个商品详情页URL提取成功