转自微信公众号: 前端时空;
来源于微信公众号: 更了不起的前端;
作者: shenfq
写在开头
写过 Vue 的同学肯定体验过, .vue 这种单文件组件有多么方便。但是我们也知道,Vue 底层是通过虚拟 DOM 来进行渲染的,那么 .vue 文件的模板到底是怎么转换成虚拟 DOM 的呢?这一块对我来说一直是个黑盒,之前也没有深入研究过,今天打算一探究竟。
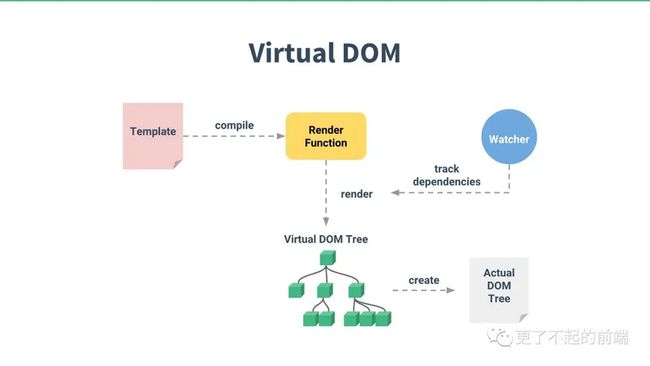
Vue 3 发布之后,本来想着直接看看 Vue 3 的模板编译,但是我打开 Vue 3 源码的时候,发现我好像连 Vue 2 是怎么编译模板的都不知道。从小鲁迅就告诉我们,不能一口吃成一个胖子,那我只能回头看看 Vue 2 的模板编译源码,至于 Vue 3 就留到正式发布的时候再看。
Vue 的版本
很多人使用 Vue 的时候,都是直接通过 vue-cli 生成的模板代码,并不知道 Vue 其实提供了两个构建版本。
vue.js:完整版本,包含了模板编译的能力;vue.runtime.js:运行时版本,不提供模板编译能力,需要通过 vue-loader 进行提前编译。
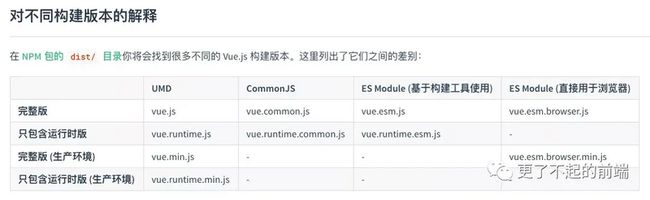

简单来说,就是如果你用了 vue-loader ,就可以使用 vue.runtime.min.js,将模板编译的过程交过 vue-loader,如果你是在浏览器中直接通过 script 标签引入 Vue,需要使用 vue.min.js,运行的时候编译模板。
编译入口
了解了 Vue 的版本,我们看看 Vue 完整版的入口文件(src/platforms/web/entry-runtime-with-compiler.js)。
// 省略了部分代码,只保留了关键部分
import { compileToFunctions } from './compiler/index'
const mount = Vue.prototype.$mount
Vue.prototype.$mount = function (el) {
const options = this.$options
// 如果没有 render 方法,则进行 template 编译
if (!options.render) {
let template = options.template
if (template) {
// 调用 compileToFunctions,编译 template,得到 render 方法
const { render, staticRenderFns } = compileToFunctions(
template,
{
shouldDecodeNewlines,
shouldDecodeNewlinesForHref,
delimiters: options.delimiters,
comments: options.comments,
},
this
)
// 这里的 render 方法就是生成生成虚拟 DOM 的方法
options.render = render
}
}
return mount.call(this, el, hydrating)
}再看看 ./compiler/index 文件的 compileToFunctions 方法从何而来。
import { baseOptions } from './options'
import { createCompiler } from 'compiler/index'
// 通过 createCompiler 方法生成编译函数
const { compile, compileToFunctions } = createCompiler(baseOptions)
export { compile, compileToFunctions }后续的主要逻辑都在 compiler 模块中,这一块有些绕,因为本文不是做源码分析,就不贴整段源码了。简单看看这一段的逻辑是怎么样的。
export function createCompiler(baseOptions) {
const baseCompile = (template, options) => {
// 解析 html,转化为 ast
const ast = parse(template.trim(), options)
// 优化 ast,标记静态节点
optimize(ast, options)
// 将 ast 转化为可执行代码
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns,
}
}
const compile = (template, options) => {
const tips = []
const errors = []
// 收集编译过程中的错误信息
options.warn = (msg, tip) => {
;(tip ? tips : errors).push(msg)
}
// 编译
const compiled = baseCompile(template, options)
compiled.errors = errors
compiled.tips = tips
return compiled
}
const createCompileToFunctionFn = () => {
// 编译缓存
const cache = Object.create(null)
return (template, options, vm) => {
// 已编译模板直接走缓存
if (cache[template]) {
return cache[template]
}
const compiled = compile(template, options)
return (cache[key] = compiled)
}
}
return {
compile,
compileToFunctions: createCompileToFunctionFn(compile),
}
}主流程
可以看到主要的编译逻辑基本都在 baseCompile 方法内,主要分为三个步骤:
- 模板编译,将模板代码转化为 AST;
- 优化 AST,方便后续虚拟 DOM 更新;
- 生成代码,将 AST 转化为可执行的代码;
const baseCompile = (template, options) => {
// 解析 html,转化为 ast
const ast = parse(template.trim(), options)
// 优化 ast,标记静态节点
optimize(ast, options)
// 将 ast 转化为可执行代码
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns,
}
}parse
AST
首先看到 parse 方法,该方法的主要作用就是解析 HTML,并转化为 AST(抽象语法树),接触过 ESLint、Babel 的同学肯定对 AST 不陌生,我们可以先看看经过 parse 之后的 AST 长什么样。
下面是一段普普通通的 Vue 模板:
new Vue({
el: '#app',
template: ` {{message}}
`,
data: {
name: 'shenfq',
message: 'Hello Vue!',
},
methods: {
showName() {
alert(this.name)
},
},
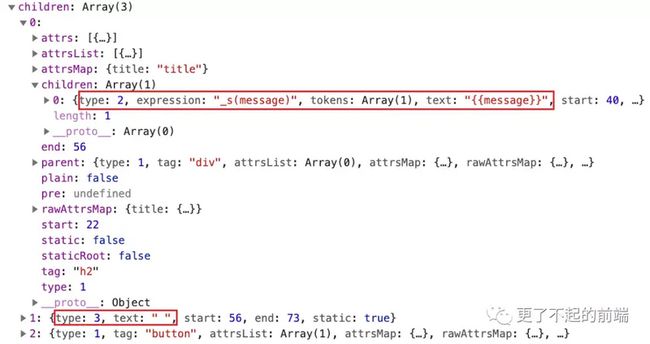
})经过 parse 之后的 AST:
AST 为一个树形结构的对象,每一层表示一个节点,第一层就是 div(tag: "div")。div 的子节点都在 children 属性中,分别是 h2 标签、空行、button 标签。我们还可以注意到有一个用来标记节点类型的属性:type,这里 div 的 type 为 1,表示是一个元素节点,type 一共有三种类型:
- 元素节点;
- 表达式;
- 文本;
在h2和button标签之间的空行就是 type 为 3 的文本节点,而 h2 标签下就是一个表达式节点。
解析 HTML
parse 的整体逻辑较为复杂,我们可以先简化一下代码,看看 parse 的流程。
import { parseHTML } from './html-parser'
export function parse(template, options) {
let root
parseHTML(template, {
// some options...
start() {}, // 解析到标签位置开始的回调
end() {}, // 解析到标签位置结束的回调
chars() {}, // 解析到文本时的回调
comment() {}, // 解析到注释时的回调
})
return root
}可以看到 parse 主要通过 parseHTML 进行工作,这个 parseHTML 本身来自于开源库:simple html parser,只不过经过了 Vue 团队的一些修改,修复了相关 issue。

HTML parser
下面我们一起来理一理 parseHTML 的逻辑。
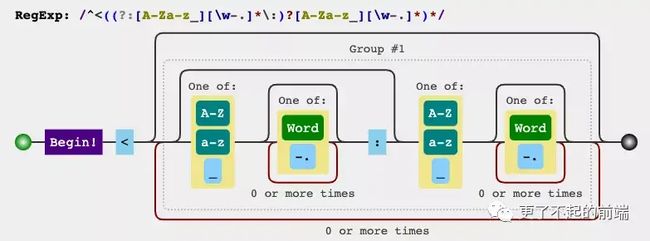
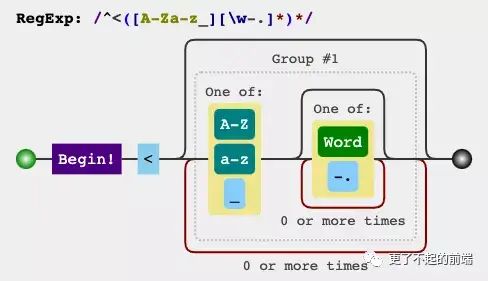
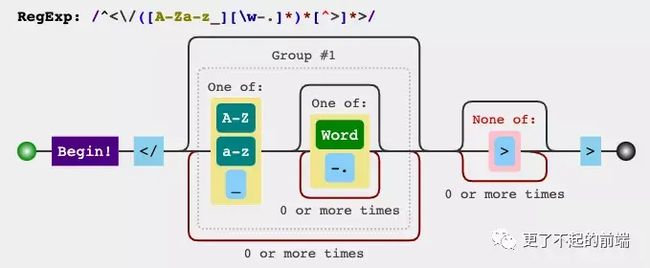
export function parseHTML(html, options) {
let index = 0
let last, lastTag
const stack = []
while (html) {
last = html
let textEnd = html.indexOf('<')
// "<" 字符在当前 html 字符串开始位置
if (textEnd === 0) {
// 1、匹配到注释:
if (/^')
if (commentEnd >= 0) {
// 调用 options.comment 回调,传入注释内容
options.comment(html.substring(4, commentEnd))
// 裁切掉注释部分
advance(commentEnd + 3)
continue
}
}
// 2、匹配到条件注释:
if (/^
const doctypeMatch = html.match(/^]+>/i)
if (doctypeMatch) {
// ... 逻辑与匹配到注释类似
}
// 4、匹配到结束标签: