计组复习(三):流水化的数据通路,流水线冒险检测与处理
目录
- 前言
- 流水线思想
-
- 加速比
- 流水化的数据通路
-
- lw指令的流水化数据通路
- 控制信号的传递
- 数据冒险
-
- 数据冒险的检测
-
- 1类冒险检测
- 2类冒险检测
- 完整的冒险判断
- 双重冒险
- 取数-使用 冒险
-
- 阻塞处理
- 分支冒险
- 中断异常
前言
昨天复(yu)习了单周期的 mips 流水线数据通路,知晓了硬件结构如何通过一系列的控制信号,完成不同指令的区别处理。
然而单周期的数据通路是一种理想化的情况,因为整个指令执行的过程,占用了全部的硬件。事实上,为了效率,流水化的硬件结构在同一时刻最多被 5 个指令分享(对应 mips 的 5 个阶段),这就带来了数据一致性的问题。
流水化的数据通路通过中间缓存的方式,避免了数据冲突,并且巧妙地将 5 个阶段的硬件使用,按照逻辑分隔,真正实现了流水化执行指令。
墙裂推荐先阅读:
- 计组实验3 mips冒险之流水线冒险
- 计组复习(二):单周期数据通路与控制信号

流水线思想
从逻辑上将一条指令分为 5 个阶段,分别是:
- 取指令(IF)
- 译码(ID)
- 执行(EX)
- 内存访问(MEM)
- 写回(WB)
因为任何一条指令都需要 5 个步骤,于是从硬件层面可以划分出 5 个不同的阶段。
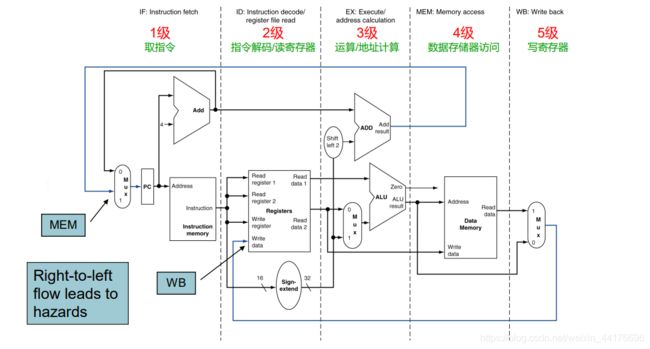
按照这种方式划分,只要某个部件完成了它的工作,马上就可以执行下一条指令的对应部分,这使得流水化得以实现,大大提高效率:
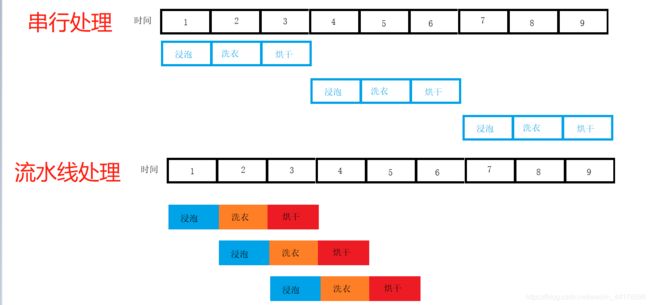
注:用的是我 之前博客 的图,以洗衣服为例(懒得画新图了
加速比
如上图,假设流水线各个级所花费的时间一致(假设都为 1 个时钟周期),并且没有什么冒险的情况(理想化),那么:
- 串行执行 n 条指令,需要 5n 个周期
- 流水化执行 n 条指令,需要 n+2 个周期(看上文的图就懂了为啥+2)
- 加速比为 5n÷(n+2)=5
如果每个指令花费的时间不等,并且指令序列不是无限长,那么加速比会进一步下降。(因为吞吐率减少,同时不能忽略+2)
流水化的数据通路
流水化意味着每个部件独立,可是事与愿违。同一条指令,下一个阶段的部件总需要依赖上一个部件的结果。
以 ID 和 EX 阶段为例,EX 阶段需要 ID 阶段给出的控制信号和寄存器数据,才能放进 ALU 中进行运算。
举个例子:流水化执行指令1,2。目前执行到指令 1 的 EX 阶段了,需要指令 1 ID 阶段的数据。但是因为只有一套硬件,此时 ID 部件已经填充了指令 2 的数据,再进行存取就会出错:

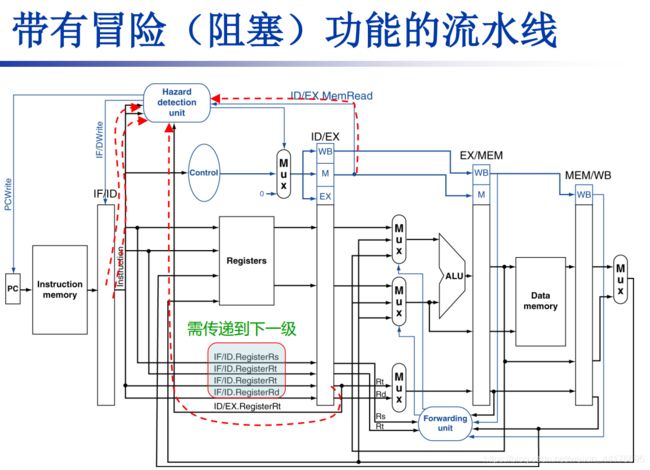
聪明的 莫菲特 mips 设计者,通过在每个不同阶段之间添加缓存,来保存前一条指令的运行结果(包括数据和控制信号),供下一个阶段的部件进行调用:
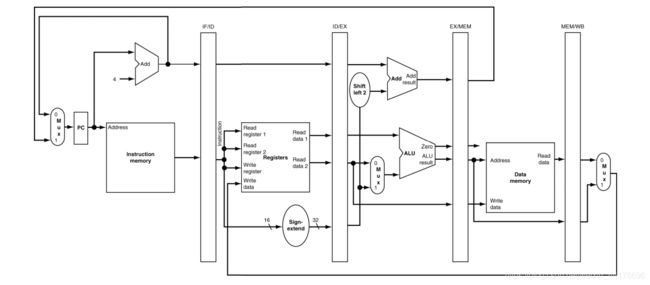
有 5 个阶段那么总共添加 4 个缓存即可完成所有数据和控制信号的 pass,他们分别是:
- IF/ID 缓存
- ID/EX 缓存
- EX/MEM 缓存
- MEM/WB 缓存
注
其实这些缓存都是寄存器
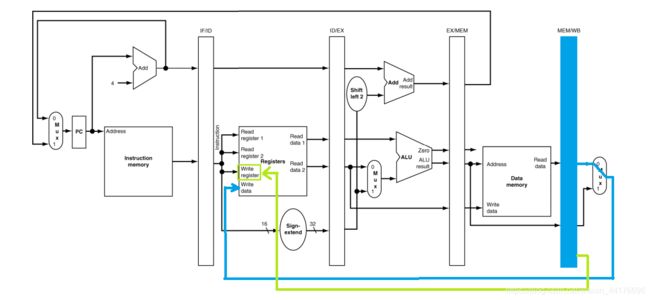
lw指令的流水化数据通路
下面通过 lw 指令的流水化数据通路来进行理解。在以下的图中,红色表示写,蓝色表示读。
首先是 IF 阶段,因为是一条新的指令,不需要读取任何缓存。直接读取指令二进制码,同时计算 PC+4,将结果写入 IF/ID 缓存:
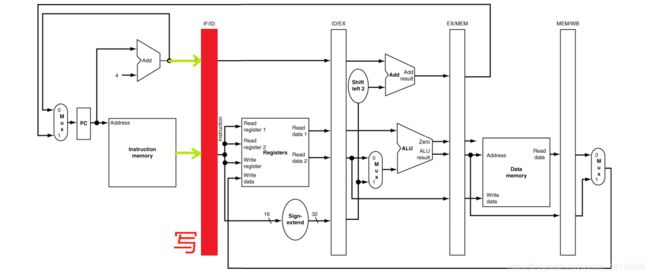
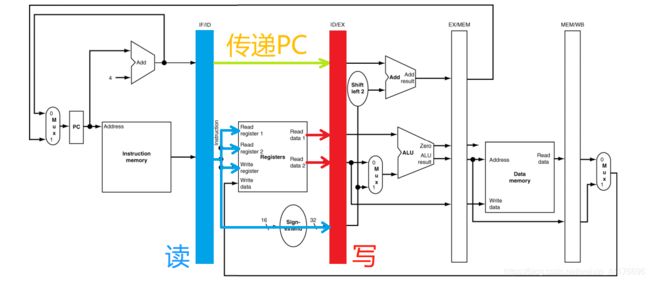
然后是 ID 阶段,从 IF/ID 缓存中,读取 IF 阶段的运行结果,并且给出 ID 阶段的运行结果,存入 ID/EX 缓存。这里读取指令给出的源目寄存器号,并且从寄存器中读取实际数据,别忘了传递 PC。如下图:
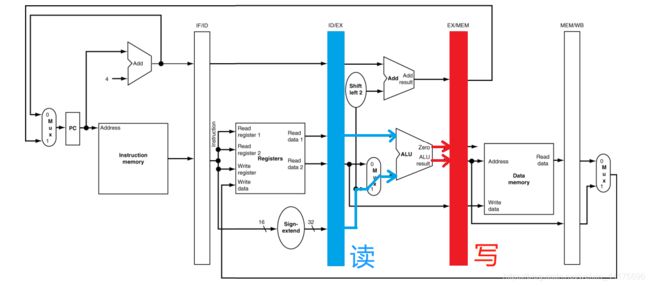
再然后是 EX 阶段,同样重复之前的操作(从上一个阶段的缓存读取数据,写运行结果到下一个阶段)。这里读取目标地址和立即数给出的偏移量,然后送入 EX/MEM 缓存,供下一个阶段读取内存使用:
MEM 阶段,从 EX/MEM 缓存中读取 EX 阶段计算出的地址,然后访问内存,得出的数据写入 MEM/WB 缓存:
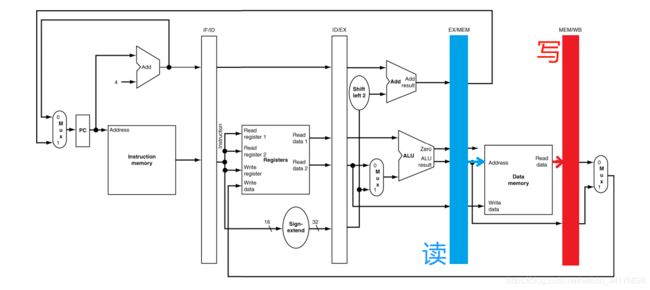
WB 阶段读取 MEM/WB 缓存中,lw 指令读取的目标数据(下图蓝色箭头),同时要从 MEM/WB 缓存中 读取 lw 的目标寄存器号(下图绿色箭头),再根据目标寄存器号,将数据写回到正确的目标寄存器。如下图:
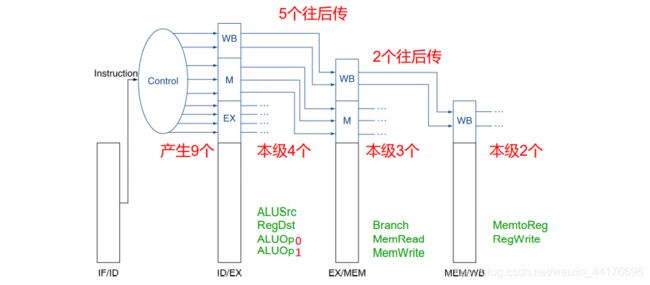
控制信号的传递
和数据一样,译码阶段产生的 9 bit 的控制信号,也需要向后传递!其中
- ALUSrc,RegDst,ALUOp 在 EX 阶段被使用
- MemRead,MemWrite,Branch 在 MEM 阶段被使用
- MemtoReg,RegWrite 在 WB 阶段被使用
数据通路需要逐级递减地向后传递每一级必要的控制信号:
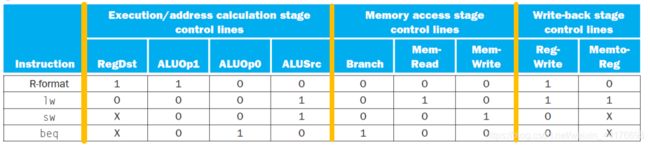
下面的表格表示了这种分级控制信号的传递关系:
数据冒险
数据冒险指两个连续的指令 1,2 其中指令 2 依赖指令 1 的计算结果,那么必须等待指令 1 的 WB 阶段之后,才能从目标寄存器中读取正确的数据。
这里引一下 我之前的博客 的内容(偷懒了:
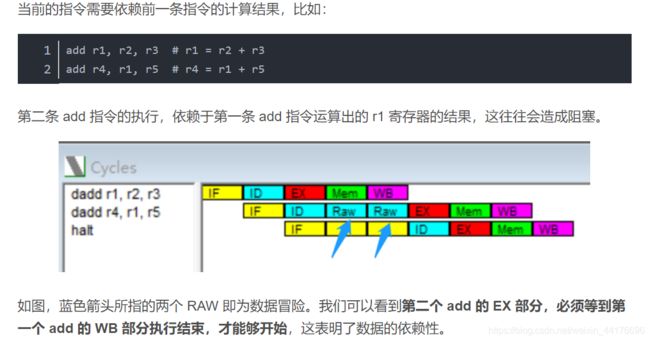
通过前推(forwarding)策略可以解决数据冒险,即在指令 1 的 EX 之后,马上将数据送给指令 2 的 EX 阶段,这样无需多余的等待就可以让指令 2 继续。
数据冒险的检测
数据冒险分两种情况,即:
- 连续的两条指令之间发生数据冒险,称作 1 类数据冒险
- 隔了一条指令,仍然发生数据冒险,称作 2 类数据冒险
如图:
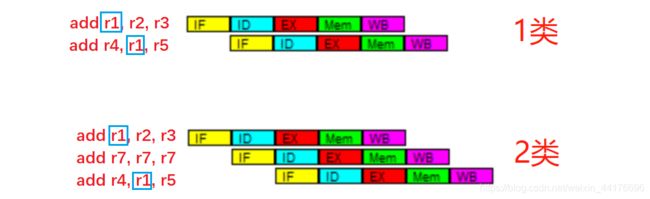
根据上面数据通路中缓存的思路,我们将指令的源目寄存器也顺势传递下去,这样能够检测数据冒险。
1类冒险检测
先来看 1 类冒险,即紧紧相邻的两条指令之间的数据冒险,假设有如下的代码:
指令1
指令2
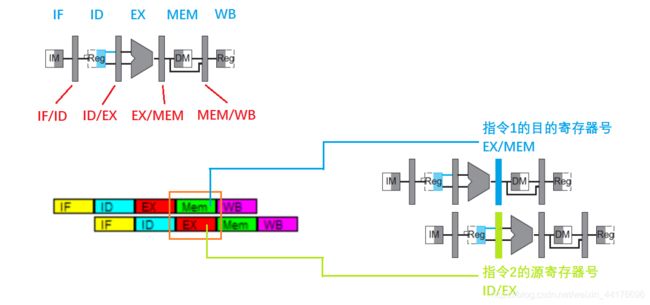
那么指令 2 的 EX 阶段执行之前,就需要指令 1 的 EX 阶段执行之后的结果。根据数据通路,可以知晓:
- ID/EX 缓存中存储了指令 2 的源寄存器号
- EX/MEM 缓存存储了指令 1 的计算结果,以及指令 1 的目的寄存器号
那么通过判断【ID/EX 缓存中的源寄存器号】和【EX/MEM 缓存中的目的寄存器号】是否相等,我们就能够检测 1 类型的数据冒险了!原理如下图:
2类冒险检测
同样的,2 类数据冒险也是相似的原理。两条间隔的指令之间发生数据冒险,那么代码有:
指令1
指令2(无关指令)
指令3
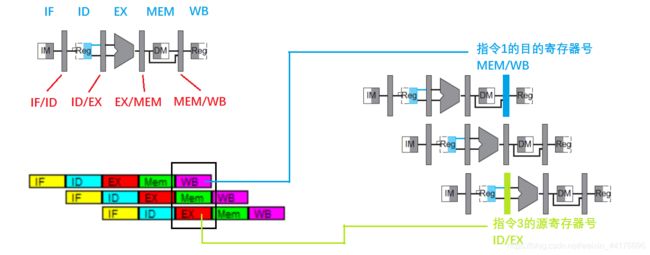
指令 3 的 EX 阶段同样需要指令 1 的 EX 执行之后的结果。那么通过数据通路可以看出:
- 指令 3 执行到 EX 阶段时,指令 1 已经完成 MEM,准备进入 WB 阶段,那么指令 1 的目的寄存器号,必定存在于 MEM/WB 缓存
- 指令 3 执行到 EX 阶段,则 ID/EX 缓存中会携带指令 3 的源寄存器号
于是我们可以通过判断 【ID/EX 缓存中的源寄存器号】和【MEM/WB 缓存中的目的寄存器号】是否相等,我们就能够检测 2 类型的数据冒险了!原理如下图:
完整的冒险判断
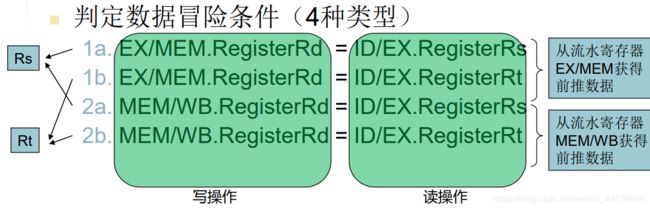
上文提到的思路是判断读和写寄存器是否是同一个,是则发生冒险。事实上因为 R 型指令和 I 型指令都需要读取 2 个寄存器的数据:

即 rs 和 rt 寄存器,那么每种冒险,需要有 2 个情况的判断,一共 4 种情况,即:
双重冒险
双重冒险就是同时满足 1 类和 2 类冒险,解决方案很简单,就是只有 1 类冒险(EX 时冒险)不发生,才执行 2 类冒险(MEM 时冒险)的前推,详细的解释如下:

取数-使用 冒险
和数据冒险不同,”取数-使用“ 冒险是后一条指令的源操作数依赖于前一条指令从内存中读取的数据,例:
lw r2, 2(r3)
add r1, r1, r2
这意味着前推不再发生在 EX 之后,相反,前推操作只能发生在取数指令的 MEM 阶段之后。而且再怎么前推,总要延迟一个周期:
还是以:
lw r2, 2(r3)
add r1, r1, r2
为例:因为无论如何都要延迟一个周期,我们不能等到 add 指令 EX 的时候才判断 “取数-使用“ 冒险,因为 IF 和 ID 部件已经做了没有延迟的错误操作(即顺序执行 add 之后的指令)
相反,我们在 add 指令 ID 阶段就要开始检测是否存在 “取数-使用“ 冒险。同样通过判断
- ID/EX 缓存中,lw 指令的 目的 寄存器号 rd
- IF/ID 缓存中,add 指令的 源 寄存器号 rs / rt
是否相等,来判断是否发生 “取数-使用“ 冒险。如下图:

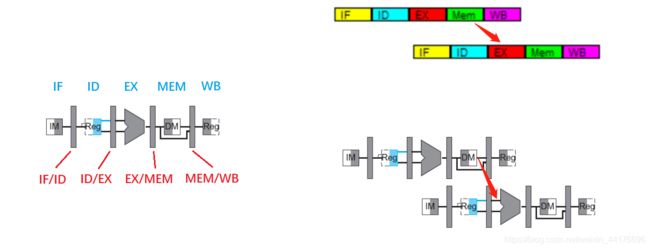
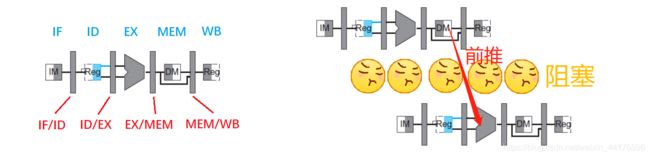
阻塞处理
“取数-使用“ 冒险一定会延迟一个周期,我们通过阻塞流水线来实现,我们干三件事:
- ID/EX 缓存中,控制信号全部置0,这样接下来的 EX,MEM,WB 都是空操作(nop)
- PC,IF/ID 缓存维持不变
流水线阻塞+前推解决 “取数-使用“ 冒险,图例如下:
还是以:
lw r2, 2(r3)
add r1, r1, r2
为例:在 IF 执行之后,将 IF/ID 缓存的数据(对应 add),和 ID/EX 缓存的数据(对应 lw)传入阻塞单元,随后阻塞单元判断是否发生 “取数-使用“ 冒险,并且将 PC 保持原样,以阻塞一个时钟周期,如下图:
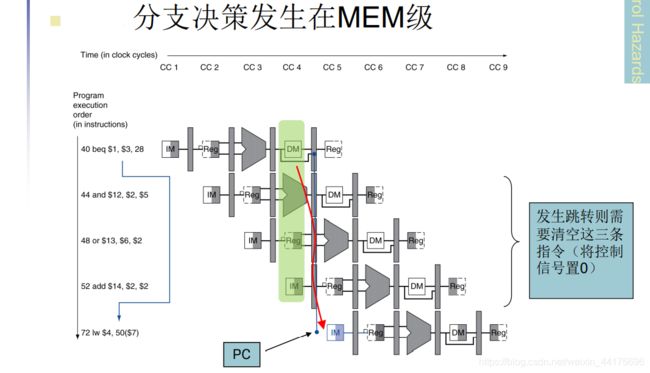
分支冒险
mips 分支预测恒不跳转,此外,分支指令一般是 beq,在 EX 阶段,ALU 计算两个操作数是否相等,并且给出控制信号。但是实际执行分支,还是在 MEM 阶段。
至于为啥是 MEM 阶段,可以看我之前的博客:计组复习(二):单周期数据通路与控制信号
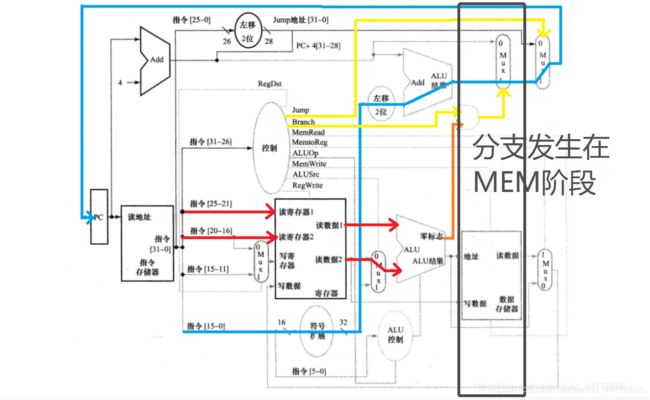
这就需要撤销一些指令,如果分支跳转的指令距离 beq 足够远,那么我们最多撤销 3 条指令。因为 beq 处于 MEM 阶段,意味着后面的 IF,ID,EX 三个阶段都是下 3 条指令的,而且最多只能有 3 条指令!
和阻塞一样,我们把控制信号全部置 0 就可以了。
中断异常
内鬼说这里要考。但是我觉得应该没啥好注意的,主要是跳转后的中断服务程序地址为 8000 00180

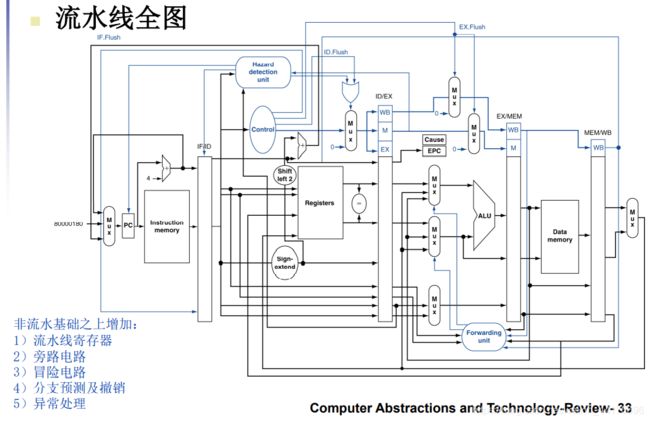
然后是流水线全图: