想在Kaggle比赛中进入前4%,你需要掌握哪些诀窍?
全文共5055字,预计学习时长13分钟

图源:unsplash
如果你一直关注Kaggle新闻,那对Mechanisms of Action竞赛应该不陌生,该比赛由哈佛创新科学实验室举办,近日刚刚落下帷幕。在这场比赛中,我和搭档Andy Wang成功进入前4%——在4373支队伍中排第152名,对此我感到十分骄傲。
其实我们对于Kaggle比赛挺陌生的。我们不是机器学习领域的专业人士,只是在网上在线课程学习了Python和机器学习而已。
毋庸置疑,我们并没有拿到金牌。整场比赛前10名才有资格获得金牌,难度非同一般。金牌选手需要给出的方案往往非常复杂。下面这幅图就是排名第一的队伍所提出的7-model方案中的一部分:
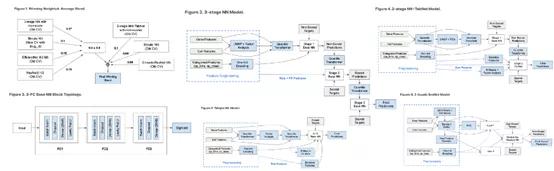
图中有很多复杂网络拓扑结构
Kaggle通常会采访获胜者,从而深入了解他们的解决方案(大多都是非常优秀的方案)。但是,我发现这些获胜者很少提及如何能在这种类型的竞赛中做到“高效”。花费大量的时间设计方案,一点一点地提高成绩,或许能让参赛者获得金牌以及数量可观的现金。但是对于大多数人来说,这种方式的实操性并不高。
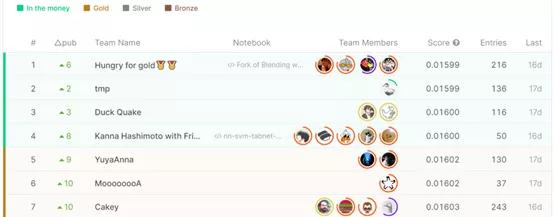
获得金牌与获得3万美元奖金也许只有0.0002分之差。
这篇文章中,我会列出我和搭档所学、所用的秘诀和小技巧。我们还在不断地学习和摸索,希望这篇文章能够给大家带来助益。
总的来说,我们的秘诀有两点,分别是技能普适性和方式高效性,之后还可以再细分到技术层面和策略层面。

技术层面技巧
下面的技巧偏向技术层面。这些比较具体的专业技巧可以用于编程方案,在Kaggle比赛优秀的参赛作品中也很常用。
完美无缺的特征工程
如果说我从这次比赛中学到了什么,那就是“特征工程是关键”。简单来说,特征工程就是提取已有特征并不断添加新的特征,这可以是简单的将两列相乘。
在常用的机器学习方法中,神经网络可视为神奇的万能方案,据说神经网络可以从数据中学习任何东西。不过事实并非如此,大多数时候,一个模型要想通过数据学习的话,还需要人类从旁协助。
模型的优劣取决于数据的好坏,最好提供尽可能多的信息让原始数据有意义。对特征工程有帮助的两个观点:
· 主成分分析法/特征降维。我们常说"这些都是数据中最重要的结构因素",并为模型设计付出很多时间和心血,因此特征降维是很好的特征工程策略。主成分分析缩减版可以用来替换数据,或者将主成分分析缩减版的特征并联到数据中(可能更成功)。除此之外,局部线性嵌入等流性学习/特征降维算法也同样适用。
· 添加数据。若多列之间的规模相当,则可以添加简单的数据,如平均值和方差,也可以添加更高阶的数据,如峰度或偏度。例如,数据点之间的方差# of cars moving in Los Angeles,# of cars movingin Santa Monica,# of cars moving in Beverley Hills等等,可以提供有用的信息,来观察天气带来的不同影响。如果方差较小,那么天气对所有城市的影响都非常相似。模型可以对此进行解释,并帮助预测。
特征工程是一门艺术。最重要的是要记住在进行特征工程时要考虑到数据环境。如果数据在现实生活中没有意义(例如将两个彼此没有关系的列相乘),很可能不会帮助模型更好地理解数据。

图源:unsplash
严格把控功能选择
全力以赴地进行特征工程是很好的做法,但同样重要的是要记住,过多的数据会让模型不堪重负,给学习重要内容带来困难。精确判断哪些特征要留存,又有哪些特征要剔除,可以对模型大有裨益。
通常,删除列时要尽量保守一些。数据不可多得,所以只有当你确定数据不会有什么用处时,才可以把它删除。
· 仔细观察数据。特别是有很多分类变量的时候,可能会有多余的列出现。例如,比赛中偶尔会有“对照组”样本的目标总是0,去掉这一数据往往会更好。
· 获取信息。你可以计算每个特征对最终模型的预测提供的信息增益,然后删除几乎不提供任何信息的特征。
· 方差阈值。这是吸引力较小的信息增益版本(但有时更实用),计算每一列的方差,并删除方差小的列(做必要的缩放后)。
· 特征降维。若出现较多高度相关的特征,那么使用降维的特征可能会有帮助。一般需要尽量不删除而只是减少那些不太“重要”的特征。如此一来,你仍能保留该有的信息。
先理解指标,再设计方案。
Kaggle会按照一定的指标来评估参赛方案,并以此决定参赛者的名次。有时候会用模型评估指标(AUC),有时也可能会用对数损失函数(logloss)。Kaggle一般会在竞赛概览的“评估”部分提供其用到的公式。
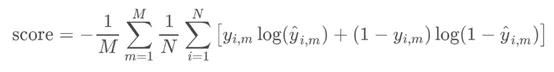
Kaggle为Mechanismsof Action竞赛提供的公式。
你需要留意这些指标,因为它们往往决定了参赛者该如何构造方案。比如,使用一个与评估函数非常相似的特定损失函数,将提高模型在该指标下的性能。
以对数损失函数为例。对互联网进行深挖能够带来很多有用信息,而对数损失函数会惩罚自信且错误的预测。也就是说,在预测中,模型越自信,对其错误性的罚分也会上升的越快。关于这一点还有很多需要仔细斟酌:
· 首先,如果系统性错误(即模型不能对数据进行理解)使得模型在对数损失方面非常糟糕,那么此时让模型变得更“迟钝”可能会有帮助。至少在即将要得出错误答案之前,它不会显得自信。
可以通过增加数据(依情况而定)或者降低模型的自信来完善模型。若是想偷懒,也可以只使用“目标裁剪”:如果预测小于1%或大于99%,那么只需要分别将其裁剪在1%和99%。这样就避免了任何过度自信的答案(当然了,还有另一个方向就是如何让模型的系统误差更小,更好的理解数据)。
· 其次,也许模型能够较好地理解数据。但是模型过于迟钝,那么与其说是有系统性错误,不如说是有精确性错误。这就提供了一个新思路:可以尝试套袋法或其他集成方法,稳定预测的可信度,增强预测自信。
这些思维方式使得数学知识能够转化为实际的技术,并给数据科学带来无限的创造性与趣味性。
接下来是建模的相关策略
建模单调乏味,是因为我们通常把建模过程视为完成任务:
· 构建
· 微调
· 评估
· 重复
看起来似乎只有有限的建模顺序,特别是在你经验有限且不习惯使用低层代码的情况下。其实建模艺术中也有很多乐趣和学问。下面是一些可行建议:
· 预训练。如果有无人监管或无人评分的数据(在训练集合中提供的但是没被测试集合使用过的数据),就可以通过模型运行数据来做预训练。同理,也可以利用Keras的预训练和预构建模型。这些方法都没什么难度,而且能够很大程度减轻工作量。
· 非线性拓扑结构。这是种神经网络并不是连续性的;相反,每一层可以有多个分支,且在后续阶段分支之间也能够续连。利用Keras的API函数式就能很容易做到。例如,图像数据可以分割成两个不同过滤器大小的卷积层。它们在不同的尺度上学习表征,而后再联合起来。
· 古怪、疯狂的科学方案。DeepInsight模型就是很好的例子。这一方法在Mechanisms of Action竞赛中非常受欢迎,它使用了t-SNE(一种降低视觉维度的方式)将表格数据转换为图像,然后使用卷积神经网络加以训练。
最后,还有些方法值得一试:将集合中的预测结果创造性地结合在一起;除ReLU以外的激活函数(比如,Leaky ReLU,Swish);对非树形模型的‘boosting’(将对一个模型的预测输入到另一个模型中用以学习错误)等等。
每个人都能建模,不会写TensorFlow的源代码也能开发出复杂且成功的模型,开发模型只需要拥有创造力和实现想法的意愿。

图源:unsplash

策略技巧层面
这部分提到的技巧更多与参赛者在竞赛中的策略使用和心理状态相关。
经常查看讨论区
我必须承认,想出新的思路太难了。能够站在愿意分享信息的巨人肩上也挺好的,这值得鼓励。这里有太多值得一试的想法,定期查看讨论区有助于了解哪些有用,哪些没用。
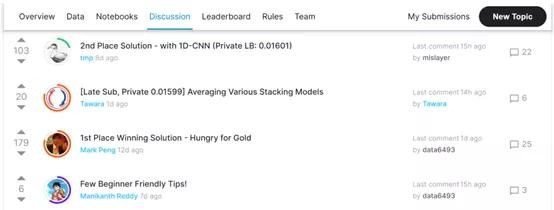
Kaggle竞赛讨论区中一些有帮助的帖子。
比赛中,一个名为TabNet的模型获得了前所未有的成功。这个模型弥补了神经网络在处理表格数据上的缺陷。因此,我们对其进行了研究并将之纳入了我们的最后一版方案,其中就包括了TabNet的两种变体。但是,要记住,不能把别人的想法作为探索的终点,而是要作为一个跳板。有以下两点原因:
· 复制-粘贴不会让你学习和成长。
· 请记住,你能看到的方案或许别人也能看到。如果想要在竞争中占有一席之地,就需要发挥出自己的优势。
不要过于关注公开的排行榜
Kaggle有一个公开的排行榜系统和一个非公开的排行榜系统。
· 公开的排行榜包含了参赛者在比赛期间的分数。该分数只基于测试数据的25%。
· 非公开的排行榜则代表了最终排名,并且由测试数据的75%计算得出。
从最终确定的排行榜中不难发现,公开的排行榜和非公开的排行榜之间有很大的差异,参赛者名次可能会前后移动数百个位次。Kaggle可能是用这种系统来防止作弊。
参赛者在公开的排行榜上的名次更多的只是一个范围,而不是确定的位次。很有可能最终的名次会比公开的排行榜上的名次上下浮动5%。因此,这能很好的估量排名所在的范围,但是离最终的名次还有一定距离。
不要因为公开的排行榜上的分数而灰心丧气(或备受鼓舞)。在比赛中设计方案时一定要记住所给出的测试数据也只是真实的测试数据的一小部分而已。
请铭记这一切都是为了增长见识!

图源:unsplash
在比赛中,照搬照抄他人辛苦所得的方案很容易就让人掉入圈套,只为了疯狂追求增加那一点点分数的零头。
Kaggle真的是一场以增长见识、经验为目的竞赛。对于大多数人来说,不管是微调复杂模型,还是为了神经网络仔细琢磨优化器的具体变种,都不值得花费数小时的时间,但正是这种大量的试验和经验才是最最重要的。
只要我们专注于学习和思考,我们就有可能取得很大的进步。这就是高效成功学的核心:利用有限的精力和时间获得最大的学习效果。
Kaggle的排名本身就代表着在数据科学领域学习的巨大成就。然而,除非你已经有很大希望获得奖金(这很不错),那么这个排名仅仅只是一个里程碑,并不能保证为参赛者带来任何工作。
正如Monolith AI的高级数据科学家Gareth Jones在一篇文章中所写的:“最近,我发现至少有两位雇佣我从事现今工作的人完全不知道我在Kaggle的资料,尽管在我的简历还有领英的顶部都有链接。”
“话虽如此,在面试的过程中,我能够详细的讨论各种Kaggle的项目。因此,Kaggle竞赛在这方面肯定是非常有用的。在我现在所从事的工作之前,我的大部分的机器学习和实践经验都是从Kaggle中获得的。我想不论如何得来的经验都弥足珍贵。”
想要通过Kaggle获得经验,有以下几个要点需要注意:
· 遵守规则——这也是挑战的一部分。获得优胜的方案需至少由八个以上的模型组成。由于Kaggle的笔记本有时间限制,大多数的参赛者会提前将模型在个人电脑上运行几十个小时,再上传模型权重。这需要大量的工作,而且这不是打破规则,而是尝试挑战使用Kaggle的计算模式,是想要获得经验的必经之路。
· 尝试同时参加两场比赛。我认为这有助于提高个人能力。如果需要同时完成两场比赛(或更多,如果你有野心的话),那么一定会让人更注意力集中在总体思路和解决问题上,不会再关心那些只会影响到一百分点的细节。除此之外,若是你对其中一场比赛感到失望,还能立马切换到另一场比赛之中。
· 记住“三日原则”。如果某项任务花了超过三天时间还没有显著进步,那就别管它了!在整个机器学习过程中还有很多要花时间研究的地方,比如特征工程和创意建模。比起去寻找藏在互联网暗角里的某个小文件,思考的过程才更有价值。
下面是要点总结。
技术学习:
· 完美无缺的特征工程
· 严格把控功能选择
· 先理解方案,再设计方案。
· 探索模型中无限的可能性与创造性。
策略学习:
· 经常查看讨论区。
· 不要过于关注公开的排行榜。
· 请铭记一切都是为了增长见识!
希望你学有所思、有所获。

一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)