机器学习算法原理系列篇4:建模流程(上)
精彩人工智能相关文章,微信搜索 : robot-learner , 或扫码

机器学习建模流程涉及到几个重要的步骤,如下图所示。在下面的篇章中,我们就每一个步骤展开讨论。

-
- 数据收集
获得有效的数据是建模的第一个步骤。这个过程可能是一次性的,也有可能是长期的,需要仔细的计划和执行。具体而言,建模人员应该从下面几个方面来考虑数据的获取问题:
- 数据源
- 业务类型决定了数据的来源,信用贷款和车贷涉及的数据可能大不相同。
- 考虑数据涉及业务是成熟业务还是新业务。成熟业务意味这数据的归集已经规范化,而新业务意味数据字段可能都要重新开始设计。
- 了解要具体解决的问题,比如需求是反欺诈,那么可能数据来源包含了用户在app上的点击行为;如果需求是信用预测,那么需要对接大量第三方外部数据。
- 数据格式
- 数据涉及字段的类型可能多种多样,比如数值型,文本型,图像,音频和视频。不同的类型需要不同的处理手段。
- 数据的获取是通过批量的方式还是流式处理。批量的获取可能会导致数据量特别大,需要用到大数据处理工具;而流式处理通常有成熟的流式计算方式。
- 数据文件的类型多种多样,比如csv,parquet, excel, database 表格等。
- 数据存储
- 如果数据储存在传统的关系型数据库,需要通过SQL查询的方式获得数据。
- 越来愈多的非关系型数据库,比如HBase, Elastics Search 等也是存储数据的有效方式,为我们获得数据提供了新的途径。
-
- 数据清洗和转换
数据清洗和转换的主要目的在于检测数据的质量,做出合理的改进,从而避免在模型实施阶段产生不必要的误差和提高质量。
首先查看和了解待建模的数据,可以通过统计分析和探索性的数据分析方法,和EDA (exploratory data analysis)等不同的方法。统计分析主要是通过统计手段,得到数据不同维度的主要统计特征,比如数据量,均值,方差,缺失值数量,最小值,最大值等。通过统计分析,可以对数据有一个基本的了解。EDA主要通过可视化的方法,更加直观查看数据的分布等特性。基本的数据可视化手段包括折线图(line chart),直方图(histogram),散点图(scatter plot),箱线图(box plot)等。如果数据量太大,可以通过随机抽样的方式,挑选数据进行可视化的分析。下面几张图展示的就是的常用的鸢尾花(iris flower)数据的四个特征的可视化展示。
下图是三种不同的鸢尾花(setosa, versicolor, virginica)的四个特征的折线图分布。四个特征分别为:sepal length (萼片长度), sepal width (萼片宽度), petal length (花瓣长度), petal width (花瓣宽度)。从这些折线图中可以清楚的看到,花瓣长度和花瓣宽度对种类有比较好的区分程度,而萼片宽度的区分程度最弱。
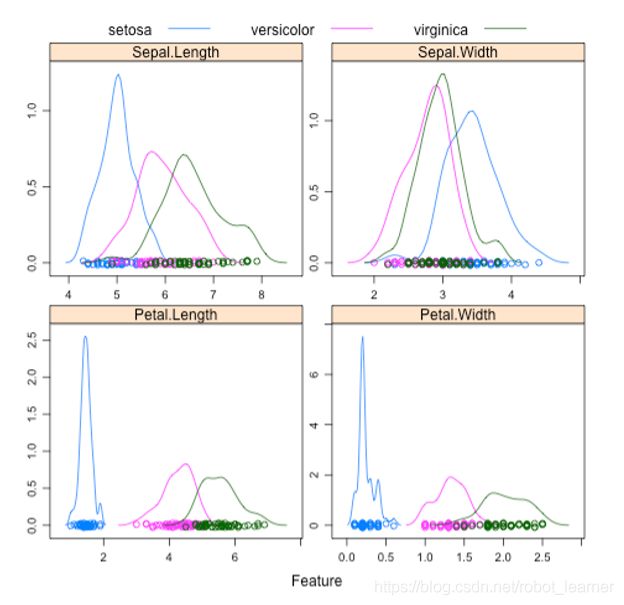
下图是鸢尾花四个特征的散点图,从二维平面进一步展示了特征两两组合对种类的区分性。

下图展示了鸢尾花四个特征的箱线图。箱线图是一个直观的查看特征分布是否正太分布(normal distribution)的有效手段。

-
-
- 数据偏度和峰度
-
偏度(skewness)是统计学上用来统计数据分布非对称程度的量化方法。下图分布显示了正偏态,正态,和负偏态的几种分布情形。

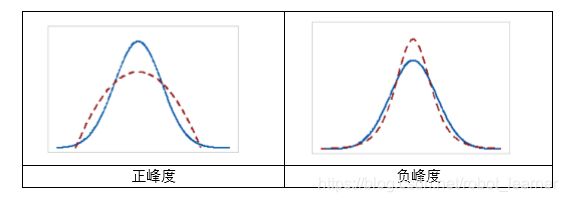
峰度(kurtosis)能够反映数据分布和正态分布相比,其峰部和尾部的区别。如果数据峰度值显著偏离0,则表明数据不服从正态分布。下图分别显示了正峰度和负峰度的两种情况。
在数据清洗过程中,我们之所以查看数据的偏度和峰度,是因为这些指标都和数据都是衡量数据是否正态分布的方法。而数据符合正态分布特性,一方面是某些算法的基本假设,因此我们运用相应算法时候有必要提前检查假设是否成立。另一方面,数据分布满足正态分布是一个优良特性,对于算法的收敛性和可解释性都很有好处。在实际建模过程中,如果某些数据维度的分布显著偏离正态,我们可以通过数据转化的手段使之尽量向正态分布靠近。一般说来,如果偏度为低中程度,比如偏度为标准误差的2-3倍,可以通过根号取值来转换。如果高度偏度,可以取自然对数或者10为基数的对数。以收入这个数据维度为例,下图示展示了正态转换的结果。

-
-
- 数据归一化
-
数据归一化的背景是指建模时候涉及的数据维度或者特征有很多,但是这些特征通常在不同的尺度上。比如收入可能在1千到几万,但是年龄的范围则在0-100之间。把数据归一化就是通过转换手段把所有的特征转换到相同的尺度范围以内。数据归一化的最大好处是能够让许多机器学习算法优化速度更快,比如梯度下降涉及的算法。当然有些算法,比如决策树本身对数据归一化并不敏感。是否进行数据归一化,取决模型具体运用的算法和建模人员对问题的理解和评判。
常用的数据归一化方法有两种:
- min-max 标准化

其中x是待归一化的特征变量,xmin是特征变量的最小值,xmax是特征变量的最小值,x*是归一化后的新特征值,且范围在0到1之间。需要注意的是,xmin 和xmax是在历史数据的找到的最小值和最大值。当模型被应用到预测新数据时候,需要考虑出现超过历史最小值和最大值的特殊情况,从而使归一化后的新特征超出0到1的范围。因此需要事先考虑这种偶然的越界会不会对模型预测产生不利的影响,如果有潜在的风险,需要进行相应的异常处理。比如把超过1的数值设定为1。
- Z-score 标准化

其中x是待归一化的特征变量,μ是特征变量的均值,δ是特征变量的标准差。如果x的分布接近正态分布,则归一化后的新特征变量则近似平均值为0,方差为1的标准正态分布。
-
-
- 数据缺失值的处理
-
实际业务中,数据或多或少的存在缺失值,而建立的模型通常只能处理完整的数据。因此数据缺失值的合理处理至关重要。缺失值的处理应该考虑以下几个步骤和方法:
- 首先要深入理解造成数据缺失的原因,不能一味的追求补全缺失值。缺失值造成的原因有可能是业务的原因,比如有些字段本身有可能存在默认空值的情况。也有可能是数据前期处理过程中造成的失误,一旦找到原因,缺失值就会重新完整。因此真正的了解缺失值形成的原因以后,才能用技术的手段加以正确处理,而不会导致额外的偏差。
- 在某些线下的一次性分析中,如果数据量比较大,并且舍弃有缺失值的数据点不会造成任何系统偏差,可以考虑简单的去掉有缺失值得数据,从而简化缺失值处理流程。
- 查看出现缺失值的特征变量,统计缺失值比例,如果缺失值比例过大,补全缺失值的收益将会减小,甚至会造成偏差。对这种缺失值比例过大的特征变量,应该考虑在建模过程完全舍弃。
- 对于确定需要补全缺失值的特征变量,分以下两种情况:
- 对于数值型特征变量,可以用平均值,中位数,众数,或者任何符合业务需求的值来填补。如果特征变量分布接近正态,那么平均值,中位数,众数都不会相差太大,但是如果分布偏离正态较多,需要注意平均值不能代表最典型的数据。这个时候中位数或者众数会更有代表意义。
- 对于枚举型特征变量,通常用最常见的枚举值去代替缺失值。
- 补全缺失值的其他注意事项:
- 对于枚举型特征变量,需要结合实际业务,有可能缺失值本身是非常有意义的,并不需要用其他值来代替。比如有一个让用户填写的是否有房产的特征,如果用户选择不填,那么会出现缺失值。但是这种不填写的行为本身有意义。在这种情况下,创一个表示空值的枚举值 (比如 NA)可以很好的规避缺失值的问题,也能更好的提高模型效果。
- 对于数值型特征,除了用平均数,中位数等值来代替以外,可以建立一个新的模型来预测。比如把待补全缺失值的特征作为目标变量,其他所有特征作为自变量,建立一个新模型,用训练好的模型来自动预测缺失值。另一个方法是考虑用相邻数据点的特征变量值来补全缺失值。
- 对于缺失值处理过的特征变量,可以考虑创造一个新的布尔特征变量,用来专门表示该特征的值是否是缺失处理得到的。把这新的特征加入模型,可能更好的反映实际情况,从而提高模型效果。
-
-
- 数据不平衡的处理
-
数据不平衡的现象是在分类预测的问题中,数据本身的分布使得各个类别的比例相差非常大。不平衡的现象是比较普遍的,比如反欺诈业务中,欺诈客户的比例要远远小于正常客户的比例,可以达到1:1000的水平。在数据建模时候,比较理想的情况是数据的种类相差不大,因为平衡的数据使得算法的收敛和算法的评价都相对容易和准确。在前面的模型评价章节我们曾经介绍过,不平衡的数据种类可能使得某些评价指标具有误导性。比如只看准确率的话,一个随机模型在不平衡的反欺诈业务中,准确率都可以达到99.9%。
在数据清洗的过程中,我们可以通过以下的一些手段来处理数据,从而使数据的种类相对平衡。需要指出的是,平衡数据只需要在训练模型时候使用。在评价模型的时候,用数据的真实比例更加贴近实际情况,从而更加准确。
- 数据重新抽样
根据对不同种类的处理,可以有两种不同方法:
-
- Under-sampling (欠采样):如果数据量足够大,可以对数量比较多的种类数据(大类)进行随机抽样,减少其数量,使其和数量比较小的种类(小类)数据量大概匹配。
- Over-sampling (过采样): 如果数据量比较小,不能再减小总的数据量,可以对小类数据进行有放回的随机采样,从而增加其数据量,使其和大类数据量相当。除了随机复制已有数据以外,也可以人工合成新数据,即原样本中不存在的数据,从而避免数据出现重复。如何合理的合成数据是另一个课题,最简单的方法就是对每一特征分布进行拟合,从而用得到的单个特征分布随机产生新的数据的每一个特征。还有另一种方法称作SMOTE(Synthetic Minority Over-sampling Technique)。该方法基于距离选择邻居样本,用邻居样本对选择样本的一个属性增加噪声,每次处理一个属性。这样就构造了更多的新生数据。
- 选择合适算法
不同的算法对数据不平衡的处理效果是不一样的,通常而言,决策树相关的算法能更好的处理不平衡数据。这是因为决策树是基于规则,它的结构决定了它可以自动学习不同种类的特征,而不完全依赖于数据量。
3. 调整算法惩罚权重
通过改变算法中对每个类别的惩罚权重,可以对分类器的小类样本数据增加权值,降低大类样本的权值。这种算法比如penalized-SVM和penalized-LDA算法。