【菜鸡新手 - 剑指offer 03】[2021/1/17一刷] 找出数组中重复的数字 -三种解法|| 物归原主,测试碰撞法 || hash表测试碰撞法 || 排序+遍历法 ||python
文章目录
- 题目解读
- A. 书籍推荐解法:我起名为“ 物归原主,测试碰撞”法
- B. 基础尝试1:hash表 + 碰撞测试 (效果还行)
- C. 基础尝试2:排序+遍历 (效果差)
-
-
- C.1 排序:
-
-
- 1. 手撸的递归快排 (时长过长,失败):
- 2. 调用python自带排序函数 list.sort() (成功)
-
- C.2 遍历:
-
- 1. 找到任意一个重复数:
- 2. 找到所有的重复数:
-
本博客为辛苦原创,代码与思想参照与剑指Offer,但是解读 与 图 与 代码 均出自原创,
这篇博客可以参考,禁止转载!
@author =yhr
题目解读
在一个 长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内
数组中 某些数字是重复 的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
老规矩 抓题目关键点:
- 长度为N的数组,取值范围却只有0~N-1 —> 全是正数哦
- —> 要么完全无重复 range(0,N),否则必重复!
- 只要找出 任意一个 重复的数字 就可以 —> 不需要列出所有的。
![【菜鸡新手 - 剑指offer 03】[2021/1/17一刷] 找出数组中重复的数字 -三种解法|| 物归原主,测试碰撞法 || hash表测试碰撞法 || 排序+遍历法 ||python_第1张图片](http://img.e-com-net.com/image/info8/3cb2d03704f04365976f075e3f56c17e.png)
A. 书籍推荐解法:我起名为“ 物归原主,测试碰撞”法
- 从i=0 开始遍历,直到遍历完整个数组
- 对于每个位置, 测试 nums[i] 是否等于 i – > hash 的味道
- 如果 nums[i] 不等于 i,则把nums[i] 放到 他本来的位置nums[i] 上, --> 物归原主;
- 此时如果 nums[i] 等于 他本来位置上鸠占鹊巢的 nums[nums[i]], 说明存在重复 --> 测试碰撞;
- 如果nums[i] 等不等于 鸠占鹊巢的 nums[nums[i]], 顺利交换。
- nums[nums[i]]被放到第i位置上了,继续2,1。
看起来挺绕口的,大家可以看下图(自己画的,有点丑,见谅),自己琢磨一下,
- 首先 ,箭头指向 i= 0 ,发现 nums[0]就等于0 ,符合hash规则(0mod4=0),箭头后移。
- 然后,箭头指向 i=1 ,发现 nums[1] 不等于1,不符合hash规则(1mod4=10),开始物归原主+测试碰撞。
![【菜鸡新手 - 剑指offer 03】[2021/1/17一刷] 找出数组中重复的数字 -三种解法|| 物归原主,测试碰撞法 || hash表测试碰撞法 || 排序+遍历法 ||python_第2张图片](http://img.e-com-net.com/image/info8/5e1d7afbbd0447beb2bceec5c40c6612.jpg)
废话不多说,直接上代码:
异常情况处理:
def method(self, nums):
if len(nums) < 1:
return -1
for _ in nums:
if _ < 0 or _ > len(nums) - 1:
# 保证数组里面的数字,都0<= x <=n-1
return -1
物归原主, 测试碰撞关键部分
for _ in range(0, len(nums)):
while nums[_] != _:
if nums[_] == nums[nums[_]]:
# 测试碰撞
return nums[_]
self.swap(nums, _, nums[_]) # 物归原主
return -1
交换函数
def swap(self, nums, posi, posj):
temp = nums[posi]
nums[posi] = nums[posj]
nums[posj] = temp
以上办法真的很nice, 但是会修改原数组。
但是书上另外一个,不修改原数组的方法,我不喜欢,就没看,用的二分法。。希望二刷的时候能有耐心看吧!
B. 基础尝试1:hash表 + 碰撞测试 (效果还行)
hash表我不想介绍了,这里略过基础知识的介绍吧,大家可以看看数据结构这本书。
碰撞其实广义上来说是指: 模相等 而非必须要数字本身相等。
但是介于题目是长度为 N, 但取值范围为 0~N-1,所以可以直接判定,当 X1 mod N 与 X2 mod N 相等的时候,在本题里,一定是 X1==X2 --> 出现重复。
废话不多说,上代码
异常情况处理:
def method(self, nums):
if len(nums) < 1:
return -1
for _ in nums:
if _ < 0 or _ > len(nums) - 1:
return -1
哈希表测试碰撞程序
length = len(nums)
hashTable = []
# 建立长度为N的哈希表,默认为-1
for _ in range(length):
hashTable.append(-1)
for _ in range(length):
m = np.mod(nums[_], length)
if hashTable[m] != -1:
# 当前位置已经有人在了,说明出现了碰撞
return nums[_]
else:
# 当前位置还未空,可以插入哦
hashTable[m] = nums[_]
return -1
唯一缺点呢,就是需要新开一个 N 长的哈希表数组。空间较浪费
C. 基础尝试2:排序+遍历 (效果差)
思路:
- 把数组排序为升序/降序数组
- 只要一个重复的: 遍历数组,凡是有 A[i] == A[i-1] 的, break
- 所有重复的:a. 设计dict记载每个数出现的次数,初始化为1。 b. 遍历数组,凡是有 A[i] == A[i-1] 的, 把dict[A[i]] +=1。 (略)
C.1 排序:
1. 手撸的递归快排 (时长过长,失败):
![【菜鸡新手 - 剑指offer 03】[2021/1/17一刷] 找出数组中重复的数字 -三种解法|| 物归原主,测试碰撞法 || hash表测试碰撞法 || 排序+遍历法 ||python_第3张图片](http://img.e-com-net.com/image/info8/fb0a74ed20f0462080473a3297a1443f.jpg)
但是 very sad。。。。
运行以后超过限制时长,查看原因,是因为大数组的时候,递归估计占用的时间太长了。而且快排最差的时间复杂度是O(N^2)…
2. 调用python自带排序函数 list.sort() (成功)
C.2 遍历:
1. 找到任意一个重复数:
初始数组: [2, 3, 1, 0, 2, 5, 3]
意外情况处理:
def findAllRepeatNum_sortAndTraverse(self, nums):
if len(nums) < 1:
return -1
for _ in nums:
if _ < 0 or _ > len(nums) - 1:
return -1
遍历升序数组,一旦发现有 A[i] == A[i-1] 的, break, return A[i]; 否则不存在重复数,return-1
nums.sort()
for _ in range(1, len(nums)):
if nums[_] == nums[_ - 1]:
return nums[_]
return -1
2. 找到所有的重复数:
a. 设计dict记载每个数出现的次数,初始化为1;
初始数组: [2, 3, 1, 0, 2, 5, 3]
def findAllRepeatNum_sortAndTraverse(self, nums):
copyflag= False
d = {
}
if len(nums) < 1:
return -1
for _ in nums:
if _ < 0 or _ > len(nums) - 1:
return -1
d[_] = 1
print(d)
字典初始化:
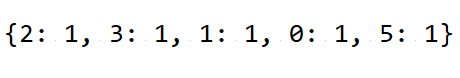
b. 遍历数组,凡是有 A[i] == A[i-1] 的, 把dict[A[i]] +=1。
nums.sort()
for _ in range(1, len(nums)):
if nums[_] == nums[_ - 1]:
copyflag=True # 确保确实有重复数出现!
d[nums[_]] += 1
if copyflag:
copyL = list(k for k,v in d.items() if v>1 )
# 关键: 找到所有出现次数k 大于1的数,就是重复数。
# 重复数汇聚成列表:copyL
return (copyL)
else:
# 没有重复数,返回-1
return -1
重复数汇聚成列表:copyL

唯一缺点呢,就是时间会比较长诺