聊聊哪些mysql引擎和索引的那些事
聊聊哪些mysql引擎和索引的那些事
一、MySQL架构及引擎
1.1 mysql架构
MySQL的架构跟我们javaweb开发是非常类似的,前排发送一个请求到controller->service->dao,在由dao去访问数据库,这就是web开发的三层架构,再看MySQL架构

执行流程
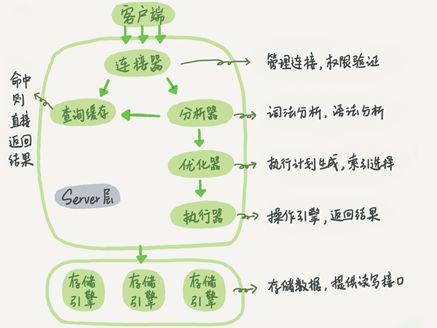
1.3 引擎区别
| 功能 | MyISAM | MEMORY | InnoDB | Archive |
|---|---|---|---|---|
| 存储限制 | 256TB | RAM | 64TB | None |
| 支持事务 | No | No | Yes | No |
| 支持全文索引 | Yes | No | No | No |
| 支持树索引 | Yes | Yes | Yes | No |
| 支持哈希索引 | No | Yes | No | No |
| 支持数据缓存 | No | N/A | Yes | No |
| 支持外键 | No | No | Yes | No |
详见: http://dev.mysql.com/doc/refman/5.6/en/storage-engines.html
另见MySQL旗下的NDB集群: https://cloud.tencent.com/developer/article/1707955
InnoDB 事务型数据库的首选引擎,支持事务(ACID),支持行级锁和外键。支持数据恢复。MySQL 5.5.5 之后,InnoDB 作为默认存储引擎。
MyISAM 是基于 ISAM 的存储引擎,并对其进行扩展,是在 Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM 拥有较高的插入、查询速度,但不支持事务。支持全文索引
MEMORY 存储引擎将表中的数据存储到内存中,为查询和引用其他数据提供快速访问, MySQL 中使用该引擎作为临时表,存放查询的中间结果。
mysql的全局功能在核心服务层实现,特性功能在数据库引擎层实现。
二、存储引擎
2.1存储引擎概述
和大多数的数据库不同, MySQL中有一个存储弓|擎的概念,针对不同的存储需求可以选择最优的存储引擎。
存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式。存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型。
Oracle , SqIServer等数据库只有一种存储引擎。 MySQL提供 了插件式的存储引擎架构。所以MySQL存在多种存储引擎,可以根据需要使用相应引擎,或者编写存储引擎。
MySQL5.0支持的存储引擎包含: InnoDB 、MyISAM 、BDB、MEMORY、 MERGE、EXAMPLE、 NDB Cluster、ARCHIVE、 CSV、
BLACKHOLE、FEDERATED等 ,其中InnoDB和BDB提供事务安全表,其他存储引擎是非事务安全表。
可以通过指定show engines,来查询当 前数据库支持的存储引擎
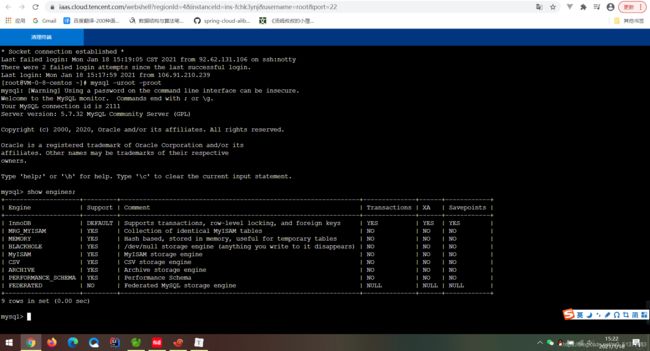
创建新表时如果不指定存储引擎,那么系统就会使用默认的存储引擎, MySQL5.5之前的默认存储引擎是MylSAM,5.5之后就改为了InnoDB。
- engine:引擎类型
- support:是否支持
- comment:注释
- transaction:是否支持事务
只有innoDB支持行级锁,并且支持外键,本文重点讲innoDB
隔离级别…
事务特性…
查看数据库的默认存储引擎:show variables like ’ storage_engine% ’
### 2.2 InnoDB
InnoDB存储予|擎是Mysq|的默认存储引擎。InnoDB存储弓 |擎提供了具有提交、回滚、崩溃恢复能力的事务安全。但是对比MyISAM的存储引擎, InnoDB写的处理效率差一些,并且会占用更多的磁盘空间以保留数据和索引。
测试:先准备一个表city

创建两个服务在顺便插入一条数据

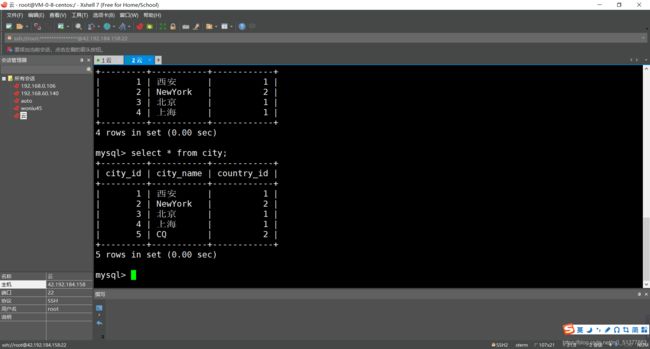
- 此时我们能够发现MySQL事务是自动提交的,云1已提交,云2立马就能收到
接下来我们要验证一下事务是否真的存在
首先手动开启事务
start transaction
在插入一条数据


这是因为mysql数据库默认的隔离级别是可重复读,所以这个时候你并没有提交,需要自己手动提交

这就是事务控制,它的特点之一
2.3 外键约束
MySQL支持外键的存储引擎只有InnoDB,在创建外键的时候,要求父表必须有对应的索引, 子表在创建外键的时候,也会自动的创建对
应的索引。由于篇幅关系,本文暂且不讲外键约束事例
三、索引
索引(在MySQL中也叫做"键key") 是存储引擎用于快速找到记录的一种数据结构。索引相当于书的目录,快速定位到记录所在位置,用额外的数据存储来加快查询。
索引需要额外的数据存储,索引是在数据之外的一份独立存储。具体来说,innodb的数据文件和索引文件都是统一存放在ibdata文件table_name.ibd)中。因此查询和维护索引都是需要额外的运算和IO。
当然,索引本身的数据结构也极大影响索引的查询速度的。
索引优点如下:
1.索引大大减少了服务器需要扫描的数据量。
2.索引可以帮助服务器避免排序和临时表。
3.索引可以将随机I/O变为顺序I/O.
缺点如下:
- 影响数据修改的速度,因为需要同步维护索引数据
- 占用磁盘空间,一般问题不大,但如果在一张大表上建立了多个组合索引,索引文件将会迅速增加
索引是存储引擎层的,而常用的数据引擎是innodb,因此以下讨论都是以innodb为例。
索引分类
从存储形式分为:聚簇和非聚簇索引(区分在于是否是主键,主键就是聚簇)
从数据结构分为:B-tree索引,哈希索引,空间数据索引,全文索引等
从附加约束分为:普通索引、唯一索引、主键索引
从涉及到的列分为:单列索引,多列索引(或称组合索引)
从效果来看还有 覆盖索引(多列索引时索引列覆盖了查询条件和返回值)
注意,不同角度对索引的定义是不同的,不可混在一起讨论。
怎么创建索引?
drop table if exists emp;
-- 创建时添加 可以选择unique 或者不写, primary key也是主键索引
create table emp(
emp_id int not null auto_increment primary key comment '自增ID',
emp_no int not null comment '工号',
name varchar(256) not null comment '名字',
unique key (emp_no,name)
);
-- 事后加唯一索引,这里是多个字段的联合索引
create unique index emp_no_name_idx on emp2(emp_no,name);
drop table if exists emp;
create table emp(
emp_id int not null auto_increment primary key comment '自增ID',
emp_no int not null comment '工号',
name varchar(256) not null comment '名字',
index(emp_no,name(10))
);
-- 加普通索引,这里是多个字段的联合索引,name是前缀索引
create index emp_no_name_idx on emp2(emp_no,name(10));
--修改
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
--删除
DROP INDEX index_name ON table
聚簇索引是什么?
innodb使用的是聚簇索引来存储数据。聚簇索引 不是一种独立的索引类型,而是一种存储方式。具体的细节依赖于实现方式,但innodb的聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。
**当表有聚簇索引时,它的数据行实际上存放在索引所在的叶子页上。**术语“聚簇”表示数据行与相邻的索引紧凑的存储在一起,另一种说法是索引组织表。一个表只能有一个聚簇索引,因为不能把数据行放在两个地方。
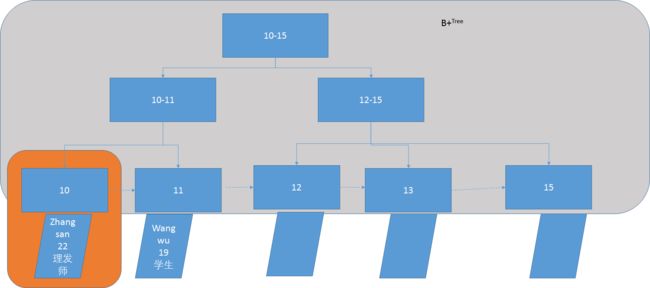
innodb默认以主键为聚簇索引。如果没有主键,则选择一个唯一的非空索引代替,如果也没有,innodb会隐式定义一个主键来作为聚簇索引。
innodb只支持主键作为聚簇索引,因此聚簇索引主键索引,非聚簇索引或称二级索引非主键索引。
为了搞清楚聚簇与非聚簇的区别,我们以下一张图来讨论,左边是innodb的聚簇索引,右边是非聚簇索引
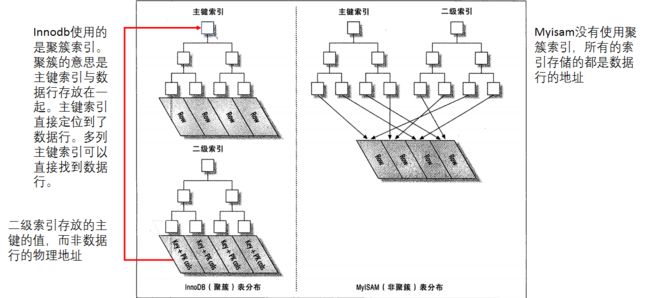
二级索引和主键索引
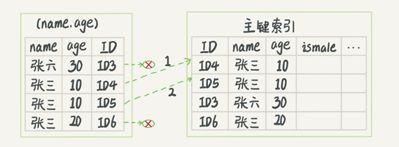
二级索引是相对主键索引而言的,本质上的区别是聚簇与非聚簇。主键索引的索引和数据行是放在一起的,而二级索引的索引和数据行是分开,所以当在二级索引定位到数据,需要重新去主键索引(聚簇索引)里去定位数据行,这个过程称为“回表”。回表多了一次磁盘IO,所以性能必然是大大小于不回表的。
因此,高性能索引策略之一,就是能用主键索引查询就一定要用主键索引。在特定业务情况下创建多列索引作为主键索引,也可以显著提高性能,但不是普遍适用。

回表图示
聚簇索引的缺点
innodb的聚簇索引指的是主键和数据行存放在一起,所以会按照主键顺序插入数据。
如果插入的主键不是顺序的,那么一方面需要遍历查找,如果不在内存中则需要进行磁盘IO;而且,随机插入会导致数据移动,在innodb的聚簇索引实现上,会造成页分裂,即造成大量的数据移动,性能消耗极大。
这里补充下,“页分裂”中的页其实是innodb的物理存储单位。引发页分裂的原因是:因为主键的值是顺序的,所以InnoDB把每一条记录都存储在上一条记录的后面。当达到页的最大填充因子时(InnoDB默认的最大填充因子是页大小的15/16,留出部分空间用于以后修改),下一条记录就会写人新的页中。一旦数据按照这种顺序的方式加载,主键页就会近似于被顺序的记录填满,这也正是所期望的结果(然而,二级索引页可能是不一样的)。
如果主键不是顺序的(比如用UUID),因为新行的主键值不一定比之前插入的大,所以InnoDB无法简单地总是把新行插人到索引的最后,而是需要为新的行寻找合适的位置一通 常是已有数据的中间位置一并且分配空间。这会增加很多的额外工作,并导致数据分布不够优化。
关于具体存储结构查考文章:https://www.percona.com/blog/2017/04/10/innodb-page-merging-and-page-splitting/
译文:https://blog.csdn.net/gududedabai/article/details/103782590
更新的代价也很大,如果将主键从1改为100那就需要强制将整个主键索引和数据行一起移动,其他数据行也需要相应变动。
另外,刚刚提到 二级索引(非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列。而且每次查找都需要回表,性能会受影响。
所以高性能索引策略之二
- 使用连续的主键值,一般而言,最佳实践是为表新建独立的与业务无关的自增int主键,保证数据是顺序的
B-Tree索引是什么?
B-Tree是一种数据结构,是一种平衡搜索树(B不是Binary而是Balance)。作为树,它的搜索(比链表高很多)和更新(比数组高很多)的效率都比较高。
如下图:

图摘自《高性能MySQL(第三版)》
- key1-keyN 这段 是索引,索引指向了具体的叶子节点(Val1.1…Val1.m , Val2.1…Val2.m, ValN.1…ValN.m),就是数据行。
- 同时根据B+树的规则,叶子页也是顺序排列的,第一个叶子页都能找到下一个叶子页的存储位置
另一个例子:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50)not null,
dob date not null,
gender enum( 'm','f') not null,
primary key(last_name, first_name, dob) --添加多列索引
);

为何innodb选择B+Tree索引?
补充下硬盘物理存储的相关知识
- 磁盘物理存储最小单位为块(block),之上是磁盘扇区(selector),机械读写需要移动磁盘头来寻道,这个过程会有性能消耗。如果物理上保证连续,则不需要移动磁头,可以提高性能

- innodb的数据存储通过自定义数据页(page,innodb概念)来对应多个磁盘块,每次读写都是基于数据页来实现。
- innodb使用b+tree结构的聚簇索引,保证了数据页的连续,因此磁盘头不需要额外的寻道,需要读取的磁盘IO次数也更少。
- b+tree的数据存储是连续的,所以更适用于范围查询(><=)
为什么MySQL选择B+树做索引
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向PrimaryKey具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的主键存放在同一盘块中,那么盘块所能容纳的主键数量也越多,一次性读入内存的需要查找的主键也就越多,相对IO读写次数就降低了。
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中主键的索引。所以任何主键的查找必须走一条从根结点到叶子结点的路。所有主键查询的路径长度相同,导致每一个数据的查询效率相当。
3、B+树更便于遍历:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
4、B+树更适合基于范围的查询:B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
参考:
Mysql索引BTree、B+Tree详解:https://www.jianshu.com/p/d67c637776d6
【动画】B-tree来由与运作: https://blog.csdn.net/qq_42146775/article/details/101449444
B树与B+树的区别: https://www.jianshu.com/p/7ce804f97967
B+Tree的适用范围和失效场景
可以使用B-Tree索引的查询类型。B-Tree 索引适用于全键值、键值范围或键前缀查找。其中键前缀查找只适用于根据最左前缀的查找生了。前面所述的索引对如下类型的查询有效。
全值匹配
全值匹配指的是和索引中的所有列进行匹配,例如前面提到的索引可用于查找姓名为Cuba Allen、出生于1960-01-01的人。
匹配最左前缀
前面提到的索引可用于查找所有姓为Allen的人,即只使用索引的第一列。
key(lastname,firstname,dob)
where lastname=‘Allen’ √
where lastname=‘Allen’ and firstname=‘Cuba’ √
where firstname=‘Cuba’ x
匹配列前缀
也可以只匹配某一列的值的开头部分。例如前面提到的索引可用于查找所有以J开头的姓的人。这里也只使用了索引的第一列。Aus Auster Austing EllenAusting
like Aus% like %Aus
匹配范围值
例如前面提到的索引可用于查找姓在Allen和Barrymore之间的人。这里也只使用了索引的第一列。
精确匹配某一列并范围匹配另外一列
前面提到的索引也可用于查找所有姓为Allen,并且名字是字母K开头(比如Kim、Karl等)的人。即第一列last_name全匹配,第二列first_name 范围匹配。
where lastname=‘Allen’ and firstname like ‘Barr%’ √
where lastname=‘Allen’ and dob = ‘1960-01-01’
只访问索引的查询
B-Tree通常可以支持“只访问索引的查询”,即查询只需要访问索引,而无须访问数据行。后面我们将单独讨论这种“覆盖索引”的优化。
在多列索引情况下,索引失效的情况就是:
- 根据匹配最左前缀规则,没有使用第一列而使用第二列等等,索引无效
- 根据精确匹配某一列并范围匹配另外一列规则,中间跳了列,索引无效
- 根据匹配列前缀规则,我们可以只使用索引的一部分,但索引匹配是从左边开始,所以
name like 'J%'可以有效,但是name like '%ames'则是无效的,这种情况可以通过新建一个列存入反转后的值来优化 (semaJ sema%)
唯一索引和主键索引是不是索引?
唯一索引主键索引是索引吗?是索引,在索引基础上加上了唯一或者主键的限制
高效索引策略总结:
-
适合的数量级才建索引,数据量很小的表(几千)不需要建索引,全表扫描性能最高
-
使用单独业务无关的自增主键,主键索引需要保证连续性,一般创建一个单纯的自增的int字段作为主键是很好地实践。查询时能用主键的一定要用主键,性能与其他字段差距极大
-
频繁查询字段考虑加索引,但不是机械的加单列索引,根据业务分析及排序、分组需要添加合适索引(索引用来排序和分组是非常快的,分组或者排序条件的字段也要考虑进来)
-
优先考虑多列索引而不是单列索引,优点是可能会达到极高效率
-
- 可以使用覆盖索引,按非主键索引查询时,需要“回表”,如果要查询的内容已经在索引中了,那么就可以省去回表这一步,性能就高了,这种称为覆盖索引。例如员工表中给工号(不是主键)和名字建了联合索引,按工号查询名字时是不需要“回表” 的。
- 索引下推是指,如果索引中数据已经可以判断出不符合条件则不会执行回表操作。
-
考虑合适的索引列顺序,根据最左前缀原则,B+ 树这种索引结构,索引项是按照索引定义里面出现的字段顺序排序的,每次先用最左边的字段来匹配,然后是第二个左边的。字符串的也是一样。所以我们根据具体应用场景通过合理的调整索引顺序,可以提高索引的效率。
-
对于长字符串考虑前缀索引(不是索引前缀),如果字符串过长,直接索引会造成很大成本影响效率,可以考虑创建一个前缀索引,可以大大提高索引效率,但是会降低索引的选择性。
-
- 为何会提高效率?因为索引是独立的存储,索引操作(插入更新及查找定位)仍然需要有开销,前缀索引减少了存储的量,所以索引操作的效率就会增高。
- 为何会降低索引选择性呢?所谓选择性,就是 索引值不同的行数 与 总行数 的比值,例如有1000行数据,其中有200行时重复的,那就剩下800不重复,选择性就是0.8,索引的选择性越高,则sql的查询效率就越高。因为选择性越高,索引可以过滤更多的行。假设在选择性很低的列上加索引,那么值重复很多,索引筛选完后还是要去每个列检查,极端情况如果选择性为0,所有的行的值都一样,那么索引就等于无效了,就是需要全表扫描了。另一种情况,选择性为1,则为唯一索引,那么索引可以直接定位到某一行,直接获取值而不需要再过滤。
-
选择性(唯一性)太差的字段不适合单独创建索引,即使频繁作为查询条件,因为索引筛选结束后仍然访问大量数据行;
-
- 比如性别是不合适建索引的,因为经过索引筛选仍然有大量的数据行,索引读取跟直接全表扫描的区别性能消耗就差不多了
-
更新非常频繁的字段不适合创建索引,因为的索引的创建和维护也需要工作量,更新频繁所带来的索引维护工作的性能消耗也很大
何时索引会失效?
- 索引只能对独立的列起作用,独立的列是指索引列不能是表达式的一部分,也不能是函数的参数。以下是反例
-- actor+1 已经不是单独的列了,改写成actor_id=4就可以
SELECT actor_id FROM sakila.actor WHERE actor_id+1=5;
-- 用作了函数参数
SELECT ... WHERE TO DAYS(CURRENT.DATE) - TO_DAYS(date_col) <= 10;
- 根据匹配最左前缀规则,没有使用第一列而使用第二列等等,索引无效
- 根据精确匹配某一列并范围匹配另外一列规则,中间跳了列,索引无效
- 根据匹配列前缀规则,我们可以只使用索引的一部分,但索引匹配是从左边开始,所以
name like 'J%'可以有效,但是name like '%ames'则是无效的,这种情况可以通过新建一个列存入反转后的值来优化