作者 | Kabuto
编辑 | CV君
报道 | 我爱计算机视觉(微信id:aicvml)
分享一篇 2020CVPR 录用论文:Deep Face Super-Resolution with Iterative Collaboration between Attentive Recovery and Landmark Estimation,其提出了一种基于迭代合作的人脸超分辨算法。
该方法将 16x16 的低分辨率图片超分辨率为 128x128,在 CelebA 和 Helen数据集上的 PSNR 指标分别达到了 27.37 和 26.69,超过了当前已有的人脸超分辨率算法。
目前代码已经开源:
https://github.com/Maclory/De...
(目前已有72星标)
论文作者信息:

作者来自清华大学自动化学院、智能技术与系统国家重点实验室、北京信息科学与技术国家研究中心和清华大学深圳国际研究生院。
01Motivation
在以往的一些人脸超分辨率算法中,人脸先验信息(facial prior)如面部关键点通常被引入,用于辅助网络生成更加真实的超分辨率图像。但是这些方法存在两个问题:
- 通过低分辨率图片LR或者粗超分辨率图片SR得到的人脸先验信息不一定准确
- 大部分方法使用人脸先验的方式为简单的 concatenate 操作,不能充分利用先验信息
为了解决上述的两个问题,作者提出了一个基于迭代合作的人脸超分辨率算法DIC,为了让生成的图片更加真实,也给出了该网络的 GAN 版本:DICGAN。
02Method

从网络结构图可以看出,为了解决先验网络不能从 coarse SR 中得到准确的先验信息,作者设计了一个反馈迭代网络,,使得生产的超分辨率图片越来越趋近于真实图片,而更加真实的图片通过先验网络可以提取更加准确的先验信息以再次提升图片的质量。
下图展示了该迭代的机制的优势,随着迭代次数的增加,关键点预测的也越来越准确,生成的图像质量也越来越好。作者也通过实验证明了,当迭代次数超过 3次时,网络性能的提升有限。


另一方面,为了充分利用人脸先验信息,作者提出了一个 Attentive Fusion 模块如下图所示:
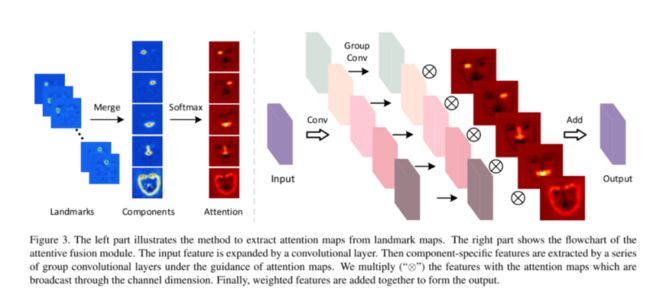
可以看出,作者将面部关键点预测网络(网络结构图中的 Face Alignment 模块)输出的特征图分成五组:左眼、右眼、嘴、鼻子和面部轮廓。再将每个组的特征图通过 softmax 后相加得到每个注意力矩阵(Attention matrix)。
用这 5 个注意力矩阵分别去 reweight 网络中的五个分支的 feature maps,再加在一起得到融合特征。那么作者如何确定关键点预测网络输出的特征图那几个channel 是左眼,哪些 channel 是右眼呢?从作者开源的代码中可以看出,这些 channel 是人为指定的,如规定第 32 到第 41 个通道是左眼的关键点。
if heatmap.size(1) == 5:
return heatmap.detach() if detach else heatmap
elif heatmap.size(1) == 68:
new\_heatmap = torch.zeros\_like(heatmap\[:, :5\])
new\_heatmap\[:, 0\] = heatmap\[:, 36:42\].sum(1) # left eye
new\_heatmap\[:, 1\] = heatmap\[:, 42:48\].sum(1) # right eye
new\_heatmap\[:, 2\] = heatmap\[:, 27:36\].sum(1) # nose
new\_heatmap\[:, 3\] = heatmap\[:, 48:68\].sum(1) # mouse
new\_heatmap\[:, 4\] = heatmap\[:, :27\].sum(1) # face silhouette
return new\_heatmap.detach() if detach else new\_heatmap
elif heatmap.size(1) == 194: # Helen
new\_heatmap = torch.zeros\_like(heatmap\[:, :5\])
tmp\_id = torch.cat((torch.arange(134, 153), torch.arange(174, 193)))
new\_heatmap\[:, 0\] = heatmap\[:, tmp\_id\].sum(1) # left eye
tmp\_id = torch.cat((torch.arange(114, 133), torch.arange(154, 173)))
new\_heatmap\[:, 1\] = heatmap\[:, tmp\_id\].sum(1) # right eye
tmp\_id = torch.arange(41, 57)
new\_heatmap\[:, 2\] = heatmap\[:, tmp\_id\].sum(1) # nose
tmp\_id = torch.arange(58, 113)
new\_heatmap\[:, 3\] = heatmap\[:, tmp\_id\].sum(1) # mouse
tmp\_id = torch.arange(0, 40)
new\_heatmap\[:, 4\] = heatmap\[:, tmp\_id\].sum(1) # face silhouette
return new\_heatmap.detach() if detach else new\_heatmap
else:
raise NotImplementedError('Fusion for face landmark number %d not implemented!' % heatmap.size(1))
以上就是本篇论文最为核心的两个创新点。了解了整个网络运行的原理之后,网络的损失函数就很好理解了:

该网络的损失函数主要由两个部分组成,一个生成图片的重构损失![]()
。其中 N 代表网络的迭代次数,也就是说重构误差和关键点误差是每轮迭代的误差之和。两个误差的计算方式都是基于 pixel-wise 的。
此外,作者引入了一个预训练的人脸识别模型 LightCNN 用于求取感知损失:

加入一个简单的判别器,就能得到 DICGAN,其对抗误差为:

最后 DICGAN 的总 loss 为:

当 
, 时就是 DIC 的损失函数了。
03Result
下图为 DIC/DICGAN 与其他方法的结果对比图:

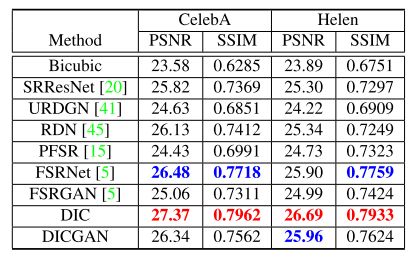
可以看出 DIC/DICGAN 生成的图片恢复了更多的细节,更加真实。由于DICGAN 是基于 GAN 的方法,相较于基于 PSNR 方法的 FSRNet,指标略低,但是生成的图像更加真实。这也是当前超分辨率任务中存在的一个问题:基于 GAN 的方法生成的图像视觉质量更好,但是 PSNR 指标低。