缓存架构以及redis缓存过期和内存淘汰机制
目录
缓存架构
本地缓存:
外部缓存
redis缓存过期
缓存淘汰机制
配置使用
LRU近似算法
LFU算法
建议:
缓存架构
当数据请求很频繁,接口访问次数很多,如果每次都查询数据库,磁盘数据 库扛不住,影响性能,所以考虑减少磁盘数据库的查询次数,将数据改换到内存中这个时候就需要缓存。但是也不是所有的数据都可以放到缓存中的,主要遵循以下几点(自认为):
- 如果数据不经常变化,绝大多数都直接进行缓存处理
- 数据变化可能也很频繁,但是是产品的核心功能数据,也可以考虑进行缓存(这种情况要自行判断了,因为这种数据的更新非常频繁所以会导致你的缓存需要频繁的更新。)
下面上图(自己画的将就看吧)
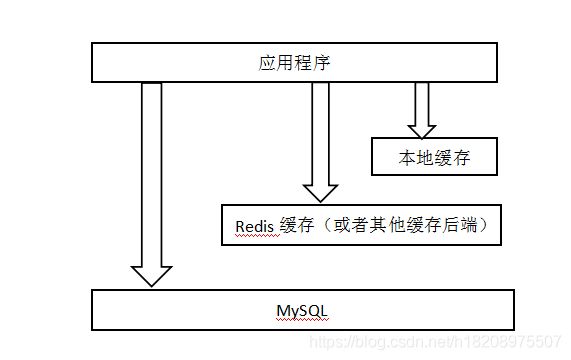
这是一个非常常见的多级缓存架设方式缓存由本地缓存 + 缓存后端构成流程是这样的。
- 首先程序先查寻本地缓存如果有数据直接返回
- 如果本地缓存没有想要的数据,就去查询外部缓存如果有数据直接返回
- 如果缓存中都没有数据去查询数据库
本地缓存:
本地缓存的存储是非常有限的,所以我们一定要存储一些非常热点的数据。我们把这种数据存在一个全局变量里用的时候直接拿就好了(一定记得数据变化时要更新他)。
demo:
# 构建一个全局变量
global cache_data= {
'user': {'name': , 'mobile':, },
.......
}另外SQLAlchemy起到一定的本地缓存作用,在同一请求中多次相同的查询只查询数据库一次,SQLAlchemy做了本地缓存,Django中的Queryset查询结果集也有同样的效果
外部缓存
以redis为例。外部缓存是可以假设多级的每级缓存数据的有效期不同,每一级的缓存又可以做成一个持久化高可用的集群这样就构成了一个稳定的外部缓存。
redis缓存过期
过期策略通常有以下三种(redis没有定时过期策略):
- 定时过期:
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
像这样:
setex('a', 300, 'AAA')
setex('b', 600, 'BBB')- 惰性过期:
只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,但是很消耗内存 许多的过期数据都还存在内存中。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
- 定期过期:
每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key(是随机的),并清除其中已过期的key。该策略是定时过期和惰性过期的折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
默认1秒钟10次检查.每次检查的时候,如果发现过期,则进行删除。 查看redis.conf 文件

hz默认设为10,提高它的值将会占用更多的cpu,当然相应的redis将会更快的处理同时到期的许多key,以及更精确的去处理超时。
hz的取值范围是1~500,通常不建议超过100,只有在请求延时非常低的情况下可以将值提升到100。
注意:当redis处于主从模式时只有主节点会触发上述的两种过期删除策略,然后把删除操作'del key'同步到从节点(这也是为什么redis中不会出现数据不一致的原因,他把DEL操作记录到了AOF文件中,然后才传递给了相关的slave从节点),也就是说过期删除操作会在master中统一进行然后再向下传递。
缓存淘汰机制
Redis自身实现了缓存淘汰
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。redis总共有如下几种内存淘汰策略:
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。(不推荐使用)
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
redis 4.x 后支持LFU策略,最少频率使用
-
allkeys-lfu
-
volatile-lfu
带volatile的策略确定了被淘汰的缓存仅从设置了过期时间的key中选择,如果没有任何key被设置过期时间,那么Volatile-lru,Volatile-random,Volatile-lfu表现得就分别和allkeys-lru,allkeys-random,allkey-lfu算法相同。
配置使用
通过redis.conf文件配置如下两个参数
maxmemory 100mb
maxmemory-policy noeviction
maxmemory-samples 5如果maxmemory被设置为0则代表无限制redis的内存使用,但是这种方案可能会导致redis耗尽内存从而造成磁盘数据交换,这种情况下可能会造成频繁的访问中断(基本没有这样用的),redis也失去了高性能的优势。
Redis上述的参数也支持运行情况下修改,比如使用如下命令将内存使用限制为110MB
CONFIG SET maxmemory 110MB当内存超过maxmemory设置的最大值时,所有的读写请求,都会触发redis.c/freeMemoryIfNeeded(void)函数以清理超出内存,注意这个清理的过程是堵塞的,知道清理出内存空间。所以如果在达到maxmemory还在不断写入时,可能会反复的触发主动清理策略,导致处于堵塞状态使请求出现一定的延迟。
LRU近似算法
LRU(Least recently used,最近最少使用)
LRU算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”(首先淘汰最长时间未被使用的数据)。
LFU算法
LFU(Least Frequently Used 最近最少使用算法)
它是基于“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小”的思路。(淘汰一定时期内被访问次数最少的数据)
当发生内存淘汰时会根据用户配置的maxmemory-policy(一般是LRU或ttl)进行清理,这里并不是根据redis中所有的key进行清理,而是以配置文件中maxmemory-samples中个key作为样本池进行抽样清理,如果增加会提高LRU或TTL的精度,但是这回导致在清理是会消耗更多的CPU时间
建议:
1、尽量不要达到maxmemory,应该是达到maxmemory的一定比例时通过调大淘汰任务的执行频率来加快淘汰,或者干脆集群扩容吧
2、如果redis是做LRU cache服务(这种服务基本上都是长时间处于maxmemory 状态,redis一直在做主动淘汰)可以适当地调大maxmemory-samples的值
3、缓存的过期时间不能集中在同一时间会造成内存雪崩的