前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于Python进击者 ,作者kuls
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542
小红书
首先,我们打开之前大家配置好的charles
我们来简单抓包一下小红书小程序(注意这里是小程序,不是app)
不选择app的原因是,小红书的App有点难度,参照网上的一些思路,还是选择了小程序
1、通过charles抓包对小程序进行分析
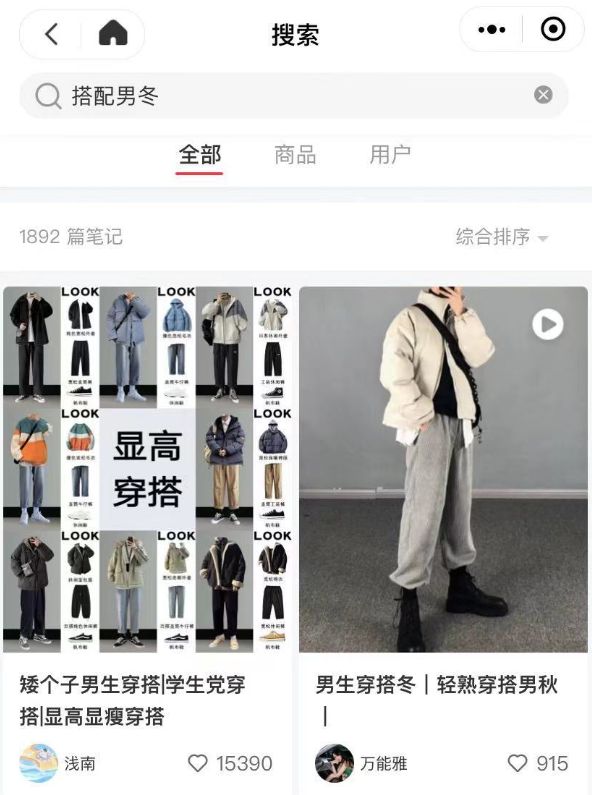
我们打开小红书小程序,随意搜索一个关键词
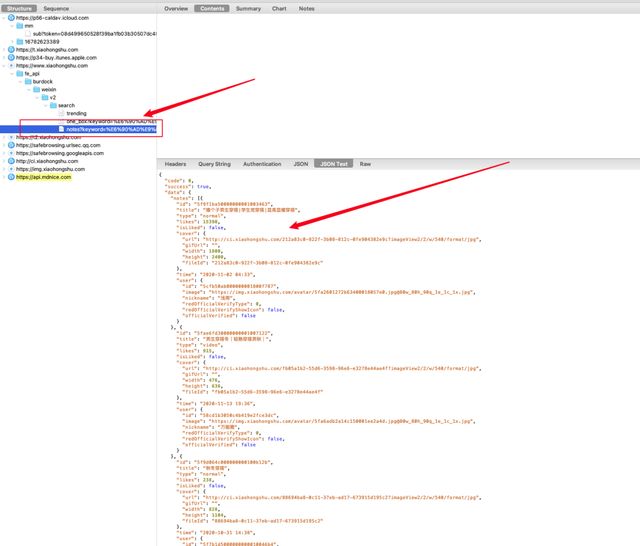
按照我的路径,你可以发现列表中的数据已经被我们抓到了。
但是你以为这就结束了?
不不不
通过这次抓包,我们知道了可以通过这个api接口获取到数据
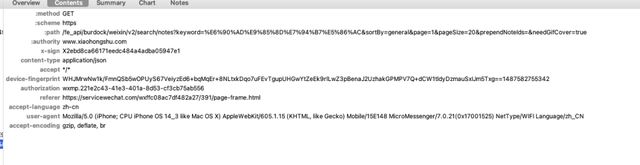
但是当我们把爬虫都写好时,我们会发现headers里面有两个很难处理的参数
"authorization"和"x-sign"
这两个玩意,一直在变化,而且不知道从何获取。
所以
2、使用mitmproxy来进行抓包
其实通过charles抓包,整体的抓取思路我们已经清晰
就是获取到"authorization"和"x-sign"两个参数,然后对url进行get请求
这里用到的mitmproxy,其实和charles差不多,都是抓包工具
但是mitmproxy能够跟Python一起执行
这就舒服很多啊
简单给大家举例子
def request(flow): print(flow.request.headers)
在mitmproxy中提供这样的方法给我们,我们可以通过request对象截取到request headers中的url、cookies、host、method、port、scheme等属性
这不正是我们想要的吗?
我们直接截取"authorization"和"x-sign" 这两个参数
然后往headers里填入
整个就完成了。
以上是我们整个的爬取思路,下面给大家讲解一下代码怎么写
其实代码写起来并不难
首先,我们必须截取到搜索api的流,这样我们才能够对其进行获取信息
if 'https://www.xiaohongshu.com/fe_api/burdock/weixin/v2/search/notes' in flow.request.url:
我们通过判断flow的request里面是否存在搜索api的url
来确定我们需要抓取的请求
authorization=re.findall("authorization',.*?'(.*?)'\)",str(flow.request.headers))[0]
x_sign=re.findall("x-sign',.*?'(.*?)'\)",str(flow.request.headers))[0]
url=flow.request.url
通过上述代码,我们就能够把最关键的三个参数拿到手了,接下来就是一些普通的解析json了。
最终,我们可以拿到自己想要的数据了
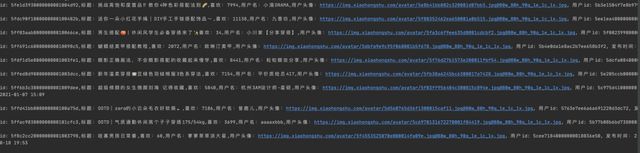
如果你想要获取到单篇数据,可以拿到文章id后抓取
"https://www.xiaohongshu.com/discovery/item/" + str(id)
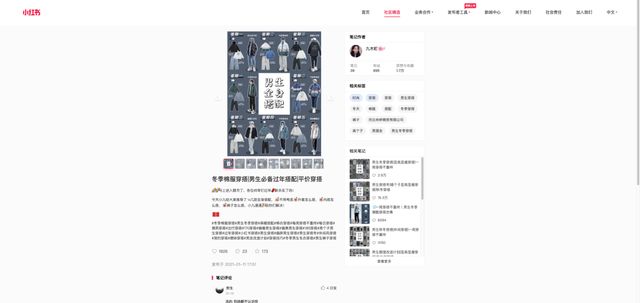
这个页面headers里需要带有cookie,你随意访问一个网站都可以拿到cookie,目前看来好像是固定的
最后,可以把数据放入csv
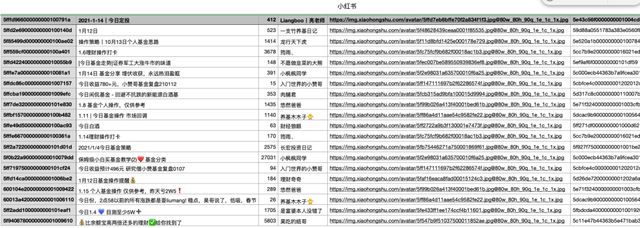
总结
其实小红书爬虫的抓取并不是特别的难,关键在于思路以及使用的方法是什么。
到此这篇关于使用Python爬虫爬取小红书完完整整的全过程的文章就介绍到这了,更多相关Python爬取小红书内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!