隐私保护与生成模型: 差分隐私GAN的梯度脱敏方法
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
大规模数据的收集和利用大幅提升了机器学习算法的性能,但同时也令个人隐私保护面临更大的风险与挑战。为此,我们提出一种满足差分隐私(Differential Privacy)的生成对抗网络(GAN) 训练方法,用于拟合高维数据分布、生成具有严格隐私保护的数据集。我们的框架适用于集成式(centralized) 和分布式/联邦式(decentralized/federated)环境。实验表明,我们的方法可以提高生成样本的准确性,并在多个指标(例如样品视觉质量,通信效率)取得了最优的性能。

陈丁凡:本科毕业于德国图宾根大学计算机系,现为德国CISPA亥姆霍兹信息安全中心的博士生,导师为Mario Fritz。主要研究方向为机器学习(差分)隐私,以及深度生成模型。

一、差分隐私是什么?
这篇文章以差分隐私和生成模型为主要研究对象,针对面临的问题,先介绍相关的背景知识和现有研究方法,后展示解决方案和实验结果。
机器学习模型的训练需要大量的数据喂食,而这些数据的应用就会涉及到个人隐私的问题。而随着数据规模越来越大,隐私问题也获得了更多的关注,而如何保护隐私也逐渐成为了比较热门的研究方向。一个直观的想法是能否利用生成模型来生成数据,既满足了隐私保障,不损害用户的个人隐私,也能满足模型训练对于数据规模的需求,还可以通过机器学习算法的验证。因此这篇文章的主要任务就是实现privacy preserving data generation,即隐私保护的数据生成,具体来说就是结合了差分隐私(differential privacy)和生成对抗网络(GAN),其中差分隐私可以提供严格的隐私保障,而GAN可以用于拟合数据分布,特别是拟合高维数据的数据分布。与传统的privacy preserving data generation方法需要对后续任务做假设相比,使用基于神经网络的生成模型可以避免对后续的任务做假设。鉴于传统方法往往只能处理简单的后续任务,使用GAN可以很好的避免这个局限。
综上所述,本文提出了一个满足差分隐私定义的生成模型训练方法,这个方法能够获得带有隐私保障的生成模型,进而获得生成数据。生成的数据可以用于后续的一系列操作和任务,例如训练机器学习模型,而且又不会损害个人隐私。

首先,我们来了解一下差分隐私的概念。差分隐私是目前机器学习领域用的最广泛的隐私的定义。上图显示了差分隐私的定义,可以看到差分隐私将隐私的概念抽象化成了数学语言,并且提供了量化指标。差分隐私把一个mechanism(算法)M,能提供的隐私保障能力,量化成了ε和δ两个数值。这两个数字都是非负的,数字越小就代表M能够提供的隐私保障越强。
具体来看定义公式,上述不等式两边的S和S’表示相邻数据集,即这两个数据集有且仅有一个数据点的差别。而公式两边的概率表示:当算法M输入不同的,且相应的数据集的时候,输出保持不变的概率。当ε和δ的值越小越接近于0的话,不等号两边的概率越接近。这意味着即便输入M的数据集有小的改变,但其输出依然很相似。
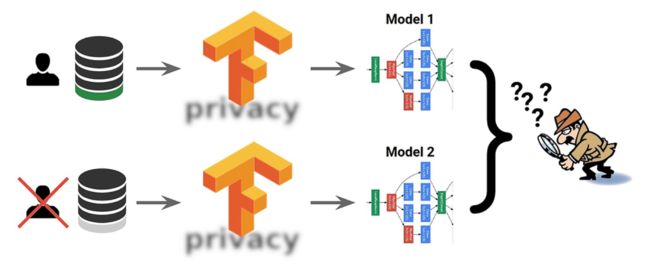
那么这又是怎样和隐私保护相关联的呢?通过上图来直观的解释一下,上下两个相邻数据集为算法的输入,其中只相差一个用户的数据,即其中绿色的部分。当算法的输出结果相近或相同的情况下就很难通过输出结果来判断输入的数据集是这两个中的哪一个,也就不可能得知是否包含绿色用户的隐私信息,这种情况下就保护了这个用户数据的隐私。
而上面的差分隐私的定义不等式对于所有可能相邻数据集都成立,这意味着无论输入的数据中相差的是哪一个用户的数据,都无法通过输出结果获得其输入的数据集,这样就实现了对用户数据的隐私保护。式中的算法M就是模型的训练算法,而输出的结果就是训练好的模型,而在本文中GAN就是训练好的模型。
二、GAN和差分隐私

在正式将GAN和差分隐私联系起来之前,先介绍一个常用的且比较简单的满足差分隐私的方法,Gaussian Mechanism,直观上理解就是给原始输出增加高斯噪声。在这之中重点在于sensitivity,指一个函数/算法f在相邻数据集上输出的最大的距离,并且这个距离通过二范数来衡量,即每一个用户对输出所能造成的最大影响。当确定了sensitivity之后就能对算法添加随机性,即添加足够大的噪声,换言之,噪声的大小需要与sensitivity成正相关。总的来说就是当噪声足够大的时候,就可以掩盖每个样本带来的影响,也就保护了样本个体的隐私信息。

接下来先介绍两个相关的基本性质。第一个是composition:当数据集被一系列算法处理之后,总隐私损失即为所有子算法隐私损失的总和。直观上,每对数据集进行一次操作,模型就有可能泄露一部分的隐私。利用这个性质可以统计迭代训练算法的总隐私损失值。第二个性质是post processing invariance,它代表的是对差分隐私算法输出结果做后处理时,如果不会重复使用数据集信息就不会泄露更多的隐私信息,即不会增加privacy risk。
然后回到问题,怎样把差分隐私和GAN结合起来。这里先不考虑隐私,了解一下GAN是如何训练的。

上图的左图展示了两个模块,左边是generator生成器,右边是discriminator判别器。Generator输入噪声,输出生成的数据样本。Discriminator输入生成的或真实的样本,其需要判断输入的样本是真还是假,同时把对应的gradient(梯度)回传给generator,用来更新generator的参数,然后使得generator生成的数据越来越逼近真实数据。
实现了GAN,要怎么满足差分隐私的需求呢?现有方法属于比较直接的Gauss mechanism应用,直接给梯度添加高斯噪声,称为Gradient Sanitization,即梯度脱敏/梯度去隐私化。其首先对梯度进行裁剪,使得所有样本的梯度二范数都小于clipping bound C,再给裁剪后的梯度添加足够大的高斯噪声,就能实现差分隐私。而clipping bound C相当于之前提及的sensitivity概念,即每个样本能引起的最大影响不会超过C,当给梯度添加了足够大的与C正相关的噪声,就能够使得样本被隐藏起来,满足差分隐私的要求。
这个方法中的难点在于clipping bound的确定,并且处于GAN这样的本身训练就不稳定的模型时,clipping bound的选择会很大程度地影响模型训练的效果。

分析上面的原理,虽然GAN有generator和discriminator两个模块,但是discriminator只有在模型训练时使用,而生成数据仅需要generator,所以只需要使得generator满足差分隐私的需求,即可得到满足隐私保护的生成数据。
针对以上特征,作者提出了保持discriminator正常训练,即不对discriminator的梯度做任何改变。而仅对discriminator传递给generator的部分梯度进行sanitization,这里利用了前面提到的post processing invariance性质。可以看到generator的参数可以写作两项乘积,其中第一项是discriminator传递的部分,也是sanitization的部分;第二项是generator自身的Jacobian,其不依赖于数据集。
另外一个重要操作是,当使用Wasserstein distance作为GAN的目标函数时,可以得到discriminator的一个Lipschitz property,而Lipschitz property可用于对梯度二范数进行估计。因此梯度裁剪的clipping bound就不需要通过手动选择,而是可以直接使用这个理论上的估值。

对比多种解决方法,图a是现有方法的处理梯度的二范数的分布,较大的方差意味着选择一个较好的clipping bound是比较困难的。图c则是本文提出的方法,其梯度二范数分布是比较接近理论值的。这表明使用理论上的估值避免了手动调参选择clipping bound的问题,实现方便且降低了clipping引入的bias(偏置)。
简单的总结一下,与现有方法相比,本文需要处理的梯度只有一个,即discriminator传递给generator的梯度,避免了对其他梯度进行操作造成额外的信息损耗。而且对梯度的处理直接利用了discriminator的 Lipschitz property,方便地获得了梯度的二范数理论估值,大大简化了获得clipping bound的过程和难度。并且由于估值是理论上的最优值,所以这一步带来的bias要比现有方法小。

接下来考虑Decentralized(去中心化)或federative learning(联邦学习)的setting。在这个情况下数据集分散于各个客户端,中心的服务器端训练模型时不会直接接触数据,而是利用各个客户端上传的梯度进行模型更新。面对这种情况,作者提出将generator和discriminator分别置于中心服务器端和客户端。具体来说,每个客户端维持一个local discriminator,即这个discriminator通过客户端的独立数据集以及服务器提供的生成数据进行训练和更新,之后将去隐私化的梯度上传给服务器端进行generator模型的更新。
综上所述,首先在这个框架下,客户端仅需将去隐私化的梯度传递给服务器,即便在服务器不可靠(untrusted)的情况下也能提供隐私保障。另外,传递的梯度实质上是对样本的梯度,其维度与模型参数梯度的维度相比低很多,与现有的联邦学习方法相比,可以有效提高传递效率。
三、差分隐私保护的效果
接下来是对模型效果的实验验证,为了验证其在高维数据集上的表现,本文在图像数据上进行了评估。评价指标中考虑了privacy和utility,其中privacy部分采用了两种量化指标,即ε和δ。而utility(样本的生成质量)考虑了两部分,首先是Inception score (IS), Frechet Inception Distance (FID) 这两个衡量样本真实性的指标。其次是样本对于后续任务的可用性:使用生成的数据集训练classifier(分类模型),后用真实数据做测试集评估classification accuracy,即评估能否仅使用生成数据训练分类模型。
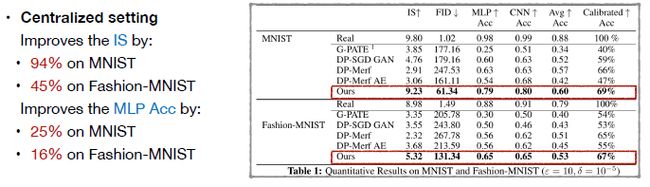
首先是Quantitative Results on MNIST and Fashion-MNIST,可以看到在正常的中心化数据集上,在提供相同的隐私保障前提下,即所有的方法拥有相同的ε和δ值,本文的方法能够显著的提高生成样本的质量。

第二个是在去中心化的情况下,本文方法同样能够比较显著地提高生成样本质量,同时也能够比较明显的减低传递梯度的维度/规模,即提高了传递效率。此外这个提升效果在不同数据集上和所有评价指标上比较一致。
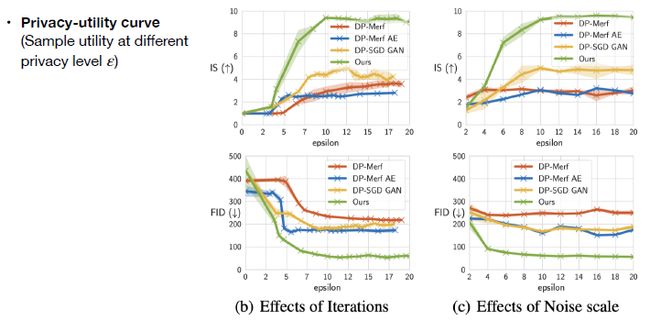
接下来是privacy-utility curve: 横坐标代表不同的privacy level,即不同的隐私保护程度。纵坐标为生成样本质量的指标,上图中上面部分是Inception Score(IS),其值越高越好,下面是FID,其值越低越好。可以看到在大多数情况下,代表本文方法的绿线能够比其他baseline方法表现要好。

最后是生成样本的可视化,可以看到本文方法生成样本的视觉效果比其他的baseline生成样本要清晰。但是也能看到给GAN加上差分隐私约束之后,生成质量很明显受到了影响。即便是在最简单的MNIST数据集上,生成质量都不算是完美。可以看到在privacy preserving data generation方向,特别是在高维数据类型方向依然有非常大的提升空间。
相关资料
论文链接:
https://arxiv.org/abs/2006.08265
模型链接:
https://github.com/DingfanChen/GS-WGAN
e m t
往期精彩
AI i

整理:闫 昊
审稿:陈丁凡
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://b23.tv/NMZ2BH)
(点击“阅读原文”下载本次报告ppt)