Linux内核自旋锁(spinlock)使用与源码分析
一. spinlock_t结构体定义
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAK
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;#define TICKET_SHIFT 16
typedef struct {
union {
u32 slock;
struct __raw_tickets {
#ifdef __ARMEB__
u16 next;
u16 owner;
#else
u16 owner;
u16 next;
#endif
} tickets;
};
} arch_spinlock_t;二. spinlock常用的API:
spin_lock_init(spinlock_t* lock); // 初始化自旋锁
spin_lock(spinlock_t *lock); // 获取自旋锁
spin_trylock(spinlock_t *lock); // 尝试获取自旋锁
spin_unlock(spinlock_t *lock); // 释放自旋锁
spin_lock_irq(lock);
spin_unlock_irq(lock);
spin_lock_irqsave(lock, flags);
spin_unlock_irqrestore(lock, flags);三. lock操作, 以spin_lock为例:
static inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}#define raw_spin_lock(lock) _raw_spin_lock(lock)void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable(); // preempt_disable()是用来关闭掉抢占的
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_); // 内核用来调试用的
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}static inline void do_raw_spin_lock(raw_spinlock_t *lock) __acquires(lock)
{
__acquire(lock);
arch_spin_lock(&lock->raw_lock);
}static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"
" teq %2, #0\n"
" bne 1b"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
while (lockval.tickets.next != lockval.tickets.owner) {
wfe();
lockval.tickets.owner = ACCESS_ONCE(lock->tickets.owner);
}
smp_mb();
}
=======================================================================
__asm__ __volatile__(
[0]. "1: ldrex %0, [%3]\n"
[1]. " add %1, %0, %4\n"
[2]. " strex %2, %1, [%3]\n"
[3]. " teq %2, #0\n"
[4]. " bne 1b"
[5]. : "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
[6]. : "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
[7]. : "cc");
[8]. while (lockval.tickets.next != lockval.tickets.owner) {
[9]. wfe();
[10]. lockval.tickets.owner = ACCESS_ONCE(lock->tickets.owner);
}
=======================================================================
%0 --> lockval
%1 --> newval
%2 --> tmp
%3 --> &lock->slock
%4 --> (1<<16)
[0]: 将lock->slock的数值赋值给lockval, 同时标记&lock->slock地址, 独占访问;
[1]. newval = lockval + (1<<16); 其实就是local.next + 1 -> newval;
[2]. 将newval的数值保存给lock->slock, 操作结果存放在tmp中, 独占访问的方式;
[3]. 监测[2]的操作结果, tmp==0, 独占读写成功; tmp!=0, 独占读写失败, 返回1b;
[4]. tmp!=0 back to 1b 循环重新开始操作;
[8]. 比较lockval.next与lockval.owner是否相等, 不相等则volatile读取lock.owner
到lockval.owner中去, 一直循环读取判断;
========================================================================
四. unlock操作, 以spin_unlock为例:
static inline void spin_unlock(spinlock_t *lock)
{
raw_spin_unlock(&lock->rlock);
}
#define raw_spin_unlock(lock) _raw_spin_unlock(lock)void __lockfunc _raw_spin_unlock(raw_spinlock_t *lock)
{
__raw_spin_unlock(lock);
}static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
spin_release(&lock->dep_map, 1, _RET_IP_);
do_raw_spin_unlock(lock);
preempt_enable();
}static inline void do_raw_spin_unlock(raw_spinlock_t *lock) __releases(lock)
{
arch_spin_unlock(&lock->raw_lock);
__release(lock);
}
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
smp_mb();
lock->tickets.owner++;
dsb_sev();
}五. 分析流程图:
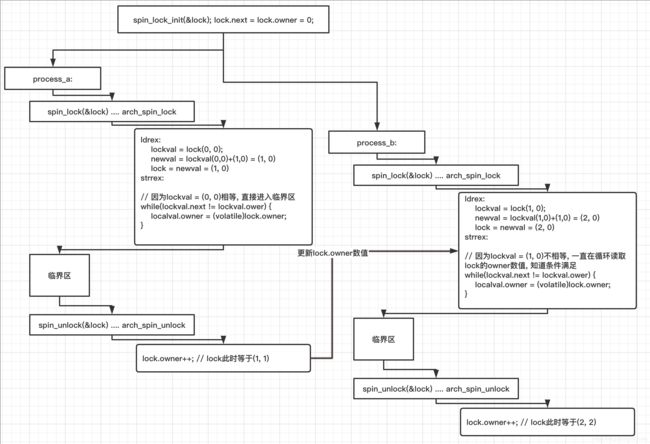
六. 使用说明
单核处理器:
1. 系统不支持内核抢占: 此时自旋锁什么也不做, 因为单核处理器任何时候只有一个线程在执行, 又不支持内核抢占, 因此资源不可能被其他线程访问到;
2. 系统支持内核抢占: 此时自旋锁加锁就是禁止了内核抢占, 解锁则是重新开启了内核抢占;
以上两种情况下,在获取自旋锁后可能发生中断, 若中断处理程序中去获取自旋锁时,则会发生死锁。因此Linux内核提供了spin_lock_irq() 和spin_lock_irqsave(), 这两个函数会在获取自旋锁的同时(同时禁止内核抢占), 禁止本地外部可屏蔽中断, 从而保证自旋锁的原子操作;