深层钢筋学习讲解— 20(DEEP REINFORCEMENT LEARNING EXPLAINED — 20)
This is the post number 20 in the “Deep Reinforcement Learning Explained” series devoted to Reinforcement Learning frameworks.
这是职位号20 致力于强化学习框架的“深度强化学习解释”系列中的内容。
So far, in previous posts, we have been looking at a basic representation of the corpus of RL algorithms (although we have skipped several) that have been relatively easy to program. But from now on, we need to consider both the scale and complexity of the RL algorithms. In this scenario, programming a Reinforcement Learning implementation from scratch can become tedious work with a high risk of programming errors.
到目前为止,在以前的文章中,我们一直在研究相对容易编程的RL算法语料库的基本表示形式(尽管我们已经跳过了几个)。 但是从现在开始,我们需要同时考虑RL算法的规模和复杂性。 在这种情况下,从头开始编写Reinforcement Learning实施可能会变得很乏味,并且存在编程错误的高风险。
To address this, the RL community began to build frameworks and libraries to simplify the development of RL algorithms, both by creating new pieces and especially by involving the combination of various algorithmic components. In this post, we will make a general presentation of those frameworks and solving the previous problem of CartPole using the PPO algorithm with RLlib, an open-source library in Python, based on Ray framework.
为了解决这个问题,RL社区开始建立框架和库来简化RL算法的开发,包括创建新的片段,特别是涉及各种算法组件的组合。 在这篇文章中,我们将这些框架的总体介绍和使用PPO算法求解CartPole以前的问题RLlib ,在Python的开放源代码库的基础上,雷框架。
超越需求 (Beyond REINFORCE)
But before continuing, as a motivational example, let’s remember that in the previous post, we presented REINFORCE, a Monte Carlo variant of a policy gradient algorithm in Reinforcement Learning. The method collects samples of an episode using its current policy and directly updates the policy parameter. Since one full trajectory must be completed to construct a sample space, it is updated as an off-policy algorithm.
但是,在继续之前,作为一个激励示例,让我们记住在上一篇文章中,我们介绍了REINFORCE ,这是强化学习中策略梯度算法的蒙特卡洛变体。 该方法使用其当前策略来收集情节的样本,并直接更新策略参数。 由于必须完成一条完整的轨迹才能构建样本空间,因此将其更新为不合策略的算法。
However, there are some limitations associated with REINFORCE algorithm. Although we cannot go into more detail, we can highlight three of the main issues:
但是,REINFORCE算法存在一些限制。 尽管我们无法进一步详细介绍,但我们可以重点介绍三个主要问题:
The update process is very inefficient. We run the policy once, update once, and then throw away the trajectory.
更新过程效率很低。 我们运行一次策略,更新一次,然后丢弃轨迹。
The gradient estimate is very noisy. There is a possibility that the collected trajectory may not be representative of the policy.
梯度估计非常嘈杂。 收集的轨迹可能无法代表该策略。
There is no clear credit assignment. A trajectory may contain many good/bad actions and whether or not these actions are reinforced depends only on the final total output.
没有明确的学分分配。 一个轨迹可能包含许多好/坏动作,这些动作是否得到加强仅取决于最终的总产出。
As we have already advanced in the previous post, a proposal that solves these limitations is the PPO algorithm, introduced in the paper “Proximal Policy Optimization Algorithms” by John Schulman et al. (2017) at OpenAI. But understanding the PPO algorithm requires a more complex mathematical treatment, and its programming becomes more convoluted than that of REINFORCE. And this is going to happen with all the algorithms that we will present from now on in this series.
正如我们在上一篇文章中已经提出的那样,解决这些局限性的一个建议是PPO算法,该算法由John Schulman等人在“近端策略优化算法”一文中介绍。 (2017)在OpenAI。 但是了解PPO算法需要更复杂的数学处理,并且其编程比REINFORCE更加复杂。 从现在开始,我们将在本系列中介绍的所有算法中都会发生这种情况。
But actually, although we cannot avoid having to understand a specific algorithm well to see its suitability as a solution to a specific problem, its programming can be greatly simplified with the new Reinforcement Learning frameworks and libraries that the research community is creating and sharing.
但是实际上,尽管我们不能避免必须很好地理解特定算法才能将其适用性作为对特定问题的解决方案,但是可以使用研究团体正在创建和共享的新的强化学习框架和库,极大地简化其编程。
强化学习框架 (Reinforcement Learning frameworks)
Before presenting these RL frameworks, let’s see a bit of their context.
在介绍这些RL框架之前,让我们先了解一下它们的上下文。
从互动中学习而不是从例子中学习 (Learning from interactions instead of examples)
In the last several years pattern-recognition side has been the focus of much of the work and much of the discussion in the community of Deep Learning. We are using powerful supercomputers that process large labeled data sets (with expert-provided outputs for the training set), and apply gradient-based methods that find patterns in those data sets that can be used to predict or to try to find structures inside the data.
在过去的几年中,模式识别方面一直是深度学习社区中许多工作和讨论的重点。 我们正在使用功能强大的超级计算机来处理大型带标签的数据集(具有训练集的专家提供的输出),并应用基于梯度的方法在这些数据集中查找模式,这些模式可用于预测或尝试在模型内部查找结构。数据。
This contrasts with the fact that an important part of our knowledge of the world is acquired through interaction, without an external teacher telling us what the outcomes of every single action we take will be. Humans are able to discover solutions to new problems from interaction and experience, acquiring knowledge about the world by actively exploring it.
与此相反的事实是,我们对世界的了解的重要部分是通过互动获得的,而没有外部老师告诉我们我们采取的每一项行动的结果将是什么。 人们能够通过互动和经验来发现新问题的解决方案,并通过积极探索来获取有关世界的知识。
For this reason, current approaches will study the problem of learning from interaction with simulated environments through the lens of Deep Reinforcement Learning (DRL), a computational approach to goal-directed learning from the interaction that does not rely on expert supervision. I.e., a Reinforcement Learning Agent must interact with an Environment to generate its own training data.
因此,当前的方法将通过深度强化学习(DRL)的视角研究与模拟环境交互的学习问题,这是一种从交互中进行目标导向学习的计算方法,该方法不依赖专家的监督。 即,强化学习代理必须与环境交互以生成其自己的培训数据。
This motivates interacting with multiple instances of an Environment in parallel to generate faster more experience to learn from. This has led to the widespread use of increasingly large-scale distributed and parallel systems in RL training. This introduces numerous engineering and algorithmic challenges that can be fixed by these frameworks we are talking about.
这激发了与环境的多个实例并行交互的作用,从而产生了更快的学习经验。 这导致在RL培训中越来越广泛地使用越来越大规模的分布式和并行系统。 这引入了许多工程和算法挑战,这些挑战可以通过我们正在讨论的这些框架来解决。
开源救援 (Open source to the rescue)
In recent years, frameworks such as TensorFlow or PyTorch (we have spoken extensively about both in this blog) have arisen to help turn pattern recognition into a commodity, making deep learning easier to try and use for practitioners.
近年来,已经出现了诸如TensorFlow或PyTorch之类的框架(我们在本博客中对此进行了广泛讨论),以帮助将模式识别转化为商品,从而使深度学习更易于尝试并为从业者使用。
A similar pattern is beginning to play out in the Reinforcement Learning arena. We are beginning to see the emergence of many open source libraries and tools to address this both by helping in creating new pieces (not writing from scratch), and above all, involving the combination of various prebuild algorithmic components. As a result, these Reinforcement Learning frameworks help engineers by creating higher-level abstractions of the core components of an RL algorithm. In summary, this makes code easier to develop, more comfortable to read, and improves efficiency.
在强化学习领域也开始出现类似的模式。 我们开始看到许多开放源代码库和工具的出现,它们可以通过帮助创建新片段(而不是从头开始)来解决这个问题,最重要的是涉及各种预构建算法组件的组合。 结果,这些强化学习框架通过创建RL算法核心组件的高级抽象来帮助工程师。 总之,这使代码更易于开发,更易于阅读并提高了效率。
In this post, I provide some notes about the most popular RL frameworks available. I think the readers will benefit by using code from an already-established framework or library. At the time of writing this post, I could mention the most important ones (and I’m sure I’m leaving some of them out):
在这篇文章中,我提供了有关最流行的RL框架的一些说明。 我认为通过使用已经建立的框架或库中的代码,读者会从中受益。 在撰写本文时,我可以提到最重要的一些(而且我确定我会忽略其中的一些):
Keras-RL
Keras-RL
RL Coach
RL教练
ReAgent
代理商
Ray+RLlib
雷+ RLlib
Dopamine
多巴胺
Tensorforce
张量力
RLgraph
RL图
Garage
车库
DeeR
鹿
Acme
Acme
Baselines
基准线
Deciding which one of the RL frameworks listed here to use, depends on your preferences and what you want to do with it exactly. The reader can follow the links for more information.
确定要使用此处列出的RL框架之一,取决于您的首选项以及您要如何处理它。 读者可以点击链接获取更多信息。
RLlib:使用Ray进行可扩展的强化学习 (RLlib: Scalable Reinforcement Learning using Ray)
I have personally opted for RLlib based in Ray for several reasons that I will explain below.
我之所以选择基于Ray的RLlib ,有几个原因,我将在下面解释。
计算需求的增长 (Growth of computing requirements)
Deep Reinforcement Learning algorithms involve a large number of simulations adding another multiplicative factor to the computational complexity of Deep Learning in itself. Mostly this is required by the algorithms we have not yet seen in this series, such as the distributed actor-critic methods or multi-agents methods, among others.
深度强化学习算法涉及大量模拟,这为深度学习本身的计算复杂性增加了另一个乘性因子。 通常,这是我们在本系列文章中尚未看到的算法所必需的,例如分布式actor-critic方法或multi-agent方法。
But even finding the best model often requires hyperparameter tuning and searching among various hyperparameter settings; it can be costly. All this entails the need for high computing power provided by supercomputers based on distributed systems of heterogeneous servers (with multi-core CPUs and hardware accelerators as GPUs or TPUs).
但是,即使要找到最佳模型,也常常需要调整超参数并在各种超参数设置之间进行搜索。 它可能会很昂贵。 所有这些都需要基于异构服务器的分布式系统(具有多核CPU和诸如GPU或TPU的硬件加速器)的超级计算机提供的高性能计算能力。
Two years ago, when I debuted as an author on Medium, I already explained what this type of infrastructure is like in the article “Supercomputing”. In Barcelona, we now have a supercomputer, named Marenostrum 4, which has a computing power of 13 Petaflops.
两年前,当我作为Medium的作者首次亮相时,我已经在“超级计算”一文中解释了这种类型的基础架构。 在巴塞罗那,我们现在拥有一台名为Marenostrum 4的超级计算机,其计算能力为13 Petaflops。
Barcelona Supercomputing Center will host a new supercomputer next year, Marenostrum 5, which will multiply the computational power by a factor of x17.
巴塞罗那超级计算中心明年将托管一台新的超级计算机Marenostrum 5,它将使计算能力提高17倍。
The current supercomputer MareNostrum 4 is divided into two differentiated hardware blocks: a block of general-purpose and a block-based on an IBM system designed especially for Deep Learning and Artificial Intelligence applications.
当前的超级计算机MareNostrum 4被分为两个不同的硬件模块:一个通用模块和一个基于IBM系统的模块,该模块是专门为深度学习和人工智能应用程序设计的。
In terms of hardware, this part of the Marenostrum consists of a 54 node cluster based on IBM Power 9 and NVIDIA V100 with Linux operating system and interconnected by an Infiniband network at 100 Gigabits per second. Each node is equipped with 2 IBM POWER9 processors with 20 physical cores each and 512GB of memory. Each of these POWER9 processors is connected to two NVIDIA V100 (Volta) GPUs with 16GB of memory, a total of 4 GPUs per node.
在硬件方面,Marenostrum的这一部分包括一个基于IBM Power 9和NVIDIA V100的54节点群集,该群集具有Linux操作系统,并通过Infiniband网络以每秒100吉比特的速度互连。 每个节点配备2个IBM POWER9处理器,每个处理器具有20个物理核心和512GB内存。 每个POWER9处理器都连接到两个具有16GB内存的NVIDIA V100(Volta)GPU,每个节点总共4个GPU。
How can this hardware fabric be managed efficiently?
如何有效管理此硬件结构?
系统软件堆栈 (System Software Stack)
Accelerating Reinforcement Learning with distributed and parallel systems introduce several challenges in managing the parallelization and distribution of the programs’ execution. To address this growing complexity, new layers of software have begun to be proposed that we stack on existing ones in an attempt to maintain logically separate the different components of the layered software stack of the system
使用分布式和并行系统加速强化学习在管理程序执行的并行化和分布方面提出了一些挑战。 为了解决这种日益增加的复杂性,已经开始提出新的软件层,我们将它们堆叠在现有层上,以尝试在逻辑上保持系统分层软件栈的不同组件的分离。
Because of this key abstraction, we can focus on different software components that today supercomputers incorporate in order to perform complex tasks. I like to mention that Daniel Hillis, who co-founded Thinking Machines Corporation, a company that developed the parallel Connection Machine, says that the hierarchical structure of abstraction is our most important tool in understanding complex systems because it lets us focus on a single aspect of a problem at a time.
由于这种关键的抽象性,我们可以专注于当今超级计算机为了执行复杂任务而集成的不同软件组件。 我要提到的是,开发并行连接机器的公司Think Machines Corporation的共同创始人Daniel Hillis表示,抽象的层次结构是我们了解复杂系统的最重要工具,因为它使我们可以专注于单个方面一次出现问题。
And this is the case of RLlib, the framework for which I opted, that follows this divide and conquer philosophy with a layered design of the software stack.
我选择的框架RLlib就是这种情况,它遵循这种分而治之的理念,并具有软件堆栈的分层设计。
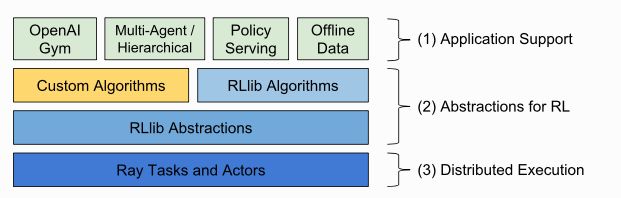
This hierarchical structure of abstraction that allows this functional abstraction is fundamental because it will let us manipulate information without worrying about its underlying representation. Daniel Hillis says that once we figure out how to accomplish a given function, we can put the mechanism inside a ”black box” of a ”building block” and stop thinking about it. The function embodied by the building block can be used over and over, without reference to the details of what’s inside.
允许这种功能抽象的抽象层次结构是基本的,因为它使我们可以操纵信息而不必担心其底层表示。 丹尼尔·希利斯(Daniel Hillis)表示,一旦我们弄清楚如何完成给定的功能,就可以将该机制放入“构建块”的“黑匣子”中,而不必再考虑它了。 可以重复使用构造块所体现的功能,而无需参考内部细节。
射线 (Ray)
In short, parallel and distributed computing is a staple of Reinforce Learning algorithms. We need to leverage multiple cores and accelerators (on multiple machines) to speed up RL applications, and Python’s multiprocessing module is not the solution. Some of the RL frameworks, like Ray can handle this challenge excellently.
简而言之,并行和分布式计算是强化学习算法的基础。 我们需要利用多个内核和加速器(在多台计算机上)来加速RL应用程序,而Python的多处理模块不是解决方案。 一些RL框架(例如Ray)可以很好地应对这一挑战。
On the official project page, Ray is defined as a fast and simple framework for building and running distributed applications:
在官方项目页面上,Ray被定义为构建和运行分布式应用程序的快速简单的框架:
- Providing simple primitives for building and running distributed applications. 提供用于构建和运行分布式应用程序的简单原语。
- Enabling end-users to parallelize single machine code, with little to zero code changes. 使最终用户能够并行化单个机器代码,而几乎没有代码更改到零。
- Including a large ecosystem of applications, libraries, and tools on top of the core Ray to enable complex applications. 在核心Ray之上包括一个大型的应用程序,库和工具生态系统,以支持复杂的应用程序。
Ray Core provides simple primitives for application building. On top of Ray Core, beside RLlib, there are other libraries for solving problems in machine learning: Tune (Scalable Hyperparameter Tuning), RaySGD (Distributed Training Wrappers), and Ray Serve (Scalable and Programmable Serving).
Ray Core提供了用于应用程序构建的简单原语。 在Ray Core的顶部,除了RLlib之外,还有其他解决机器学习问题的库: Tune(可伸缩超参数调整), RaySGD(分布式培训包装器)和Ray Serve(可伸缩和可编程服务)。
图书馆 (RLlib)
RLlib is an open-source library for reinforcement learning that offers both high scalability and a unified API for a variety of applications. RLlib natively supports TensorFlow, TensorFlow Eager, and PyTorch, but most of its internals are framework agnostic.
RLlib是用于增强学习的开源库,它为各种应用程序提供高可伸缩性和统一的API。 RLlib本机支持TensorFlow,TensorFlow Eager和PyTorch,但其大多数内部结构与框架无关。
At present, this library already has extensive documentation ( API documentation), offering a large number of built-in algorithms in addition to allowing the creation of custom algorithms.
目前,该库已拥有大量文档( API文档),除了允许创建自定义算法外,还提供了大量内置算法。
The key concepts in RLlib are Policies, Samples, and Trainers. In a nutshell, Policies are Python classes that define how an agent acts in an environment. All data interchange in RLlib is in the form of Sample batches that encode one or more fragments of a trajectory. Trainers are the boilerplate classes that put the above components together, managing algorithm configuration, optimizer, training metrics, the workflow of the execution parallel components, etc.
RLlib中的关键概念是策略,示例和培训师。 简而言之,策略是Python类,用于定义代理在环境中的行为。 RLlib中的所有数据交换均以“样品”批的形式进行,该“样品”批对一个或多个轨迹片段进行编码。 培训师是将上述组件组合在一起,管理算法配置,优化器,培训指标,执行并行组件的工作流程等的样板课程。
Later in this series, when we have advanced more in distributed and multi-agent algorithms, we will present in more detail these key components of RLlib.
在本系列后面的内容中,当我们对分布式和多主体算法进行更多改进时,我们将更详细地介绍RLlib的这些关键组件。
TensorFlow或PyTorch (TensorFlow or PyTorch)
In a previous post, TensorFlow vs. PyTorch: The battle continues, I showed that the battle between deep learning heavyweights TensorFlow and PyTorch is fully underway. And in this regard, the option taken by RLlib, allowing users to seamlessly switch between TensorFlow and PyTorch for their reinforcement learning work, also seems very appropriate.
在上一篇文章TensorFlow与PyTorch:战斗仍在继续中,我表明深度学习重量级TensorFlow与PyTorch之间的战斗正在进行中。 在这方面,RLlib采取的允许用户在TensorFlow和PyTorch之间无缝切换以进行强化学习工作的选项似乎也非常合适。
To allow users to easily switch between TensorFlow and PyTorch as a backend in RLlib, RLlib includes the “framework” trainer config. For example, to switch to the PyTorch version of an algorithm, we can specify {"framework":"torch"}. Internally, this tells RLlib to try to use the torch version of a policy for an algorithm (check out the examples of PPOTFPolicy vs. PPOTorchPolicy).
为了使用户可以轻松地在TensorFlow和PyTorch之间作为RLlib的后端进行切换,RLlib包括“框架”训练器配置。 例如,要切换到算法的PyTorch版本,我们可以指定{"framework":"torch"} 。 在内部,这告诉RLlib尝试对策略使用火炬版本的算法(请查看PPOTFPolicy与PPOTorchPolicy的示例)。
用RLlib编码PPO (Coding PPO with RLlib)
Now, we will show a toy example to get you started and show you how to solve OpenAI Gym’s Cartpole Environment with PPO algorithm using RLlib.
现在,我们将展示一个玩具示例,帮助您入门,并向您展示如何使用RLlib通过PPO算法解决OpenAI Gym的Cartpole Environment 。
The entire code of this post can be found on GitHub and can be run as a Colab google notebook using this link.
这篇文章的完整代码可以在GitHub上找到,也可以使用此链接作为Colab谷歌笔记本运行。
Given that we are executing our examples in Colab we need to restart the runtime after installing ray package and uninstall pyarrow.
鉴于我们正在Colab中执行示例,我们需要在安装ray软件包并卸载pyarrow之后重新启动运行时。
The various algorithms you can access are available through ray.rllib.agents. Here, you can find a long list of different implementations in both PyTorch and Tensorflow to begin playing with.
您可以通过ray.rllib.agents访问各种算法。 在这里,您可以在PyTorch和Tensorflow中找到一长串不同的实现,以开始使用。
If you want to use PPO you can run the following code:
如果要使用PPO,可以运行以下代码:
import ray
from ray.rllib.agents.ppo import PPOTrainer, DEFAULT_CONFIGray.init()The ray.init() command starts all of the relevant Ray processes. This must be done before we instantiate any RL agents, for instance PPOTrainer object in our example:
ray.init()命令启动所有相关的Ray进程。 必须在实例化任何RL代理之前完成此操作,例如在我们的示例中为PPOTrainer对象:
config = DEFAULT_CONFIG.copy()
config["num_gpus"] = 1 # in order to use the GPU
agent = PPOTrainer(config, 'CartPole-v0')We can pass in a config object many hyperparameters that specify how the network and training procedure should be configured. Changing hyperparameters is as easy as passing them as a dictionary to the config argument. A quick way to see what’s available is to call trainer.config to print out the options that are available for your chosen algorithm:
我们可以在config对象中传入许多超参数,这些超参数指定了应如何配置网络和训练过程。 更改超参数就像将它们作为字典传递给config参数一样容易。 快速查看可用功能的方法是调用trainer.config以打印出适用于所选算法的选项:
print(DEFAULT_CONFIG){
‘num_workers’: 2,
‘num_envs_per_worker’: 1,
‘rollout_fragment_length’: 200,
‘num_gpus’: 0,
‘train_batch_size’: 4000, .
.
.}Once we have specified our configuration, calling the train() method on our trainerobject will update and send the output to a new dictionary called results.
一旦指定了配置,在trainer对象上调用train()方法将更新并将输出发送到名为results的新字典中。
result = agent.train()All the algorithms follow the same basic construction alternating from lower case abbreviation to uppercase abbreviation followed by Trainer . For instance, if you want to try a DQN instead, you can call:
所有算法遵循相同的基本构造,从小写缩写到大写缩写,然后是Trainer 。 例如,如果您想尝试DQN,则可以致电:
from ray.rllib.agents.dqn import DQNTrainer, DEFAULT_CONFIG
agent = DQNTrainer(config=DEFAULT_CONFIG, env='CartPole-v0')The simplest way to programmatically compute actions from a trained agent is to use trainer.compute_action():
以编程方式从训练有素的代理计算动作的最简单方法是使用trainer.compute_action() :
action=agent.compute_action(state)This method preprocesses and filters the observation before passing it to the agent policy. Here is a simple example of how to watch the Agent that uses compute_action():
此方法在将观察结果传递给代理策略之前对其进行预处理和过滤。 这是一个简单的示例,说明如何监视使用compute_action()的代理:
def watch_agent(env):
state = env.reset()
rewards = []
img = plt.imshow(env.render(mode=’rgb_array’))
for t in range(2000):
action=agent.compute_action(state) img.set_data(env.render(mode=’rgb_array’))
plt.axis(‘off’)
display.display(plt.gcf())
display.clear_output(wait=True)
state, reward, done, _ = env.step(action)
rewards.append(reward)
if done:
print(“Reward:”, sum([r for r in rewards]))
break
env.close()Using watch_agent function, we can compare the behavior of the Agent before and after being trained running multiple updates calling the train() method for a given number:
使用watch_agent函数,我们可以比较在进行多次更新train()针对给定数字调用train()方法train()进行训练之前和之后Agent的行为:
for i in range(10):
result = agent.train()
print(f'Mean reward: {result["episode_reward_mean"]:4.1f}')The last line of code shows how we can monitor the training loop printing information included in the return of the method train().
代码的最后一行显示了如何监视方法train()返回中包含的训练循环打印信息。

概要(Summary)
Obviously, this is a toy implementation of a simple algorithm to show this framework very briefly. The actual value of the RLlib framework lies in its use in large infrastructures executing inherently parallel and, at the same time, complex algorithms were writing the code from scratch is totally unfeasible.
显然,这是一个简单算法的玩具实现,可以非常简要地显示此框架。 RLlib框架的实际价值在于其在大型基础架构中的使用,这些大型基础架构本质上是并行执行的,同时,复杂的算法从头开始编写代码是完全不可行的。
As I said, I opted for RLlib after taking a look at all the other frameworks mentioned above. The reasons are diverse; some are already presented in this post. Add that for me; it is relevant that it has already been included in major cloud providers such as AWS and AzureML. Or that there is a pushing company like ANYSCALE that has already raised 20 million and organizes the Ray Summit conference, which will be held online this week (September 30 through October 1) with great speakers (as our friend Oriol Vinyals ;-). Maybe add more context details, but for me, just as important as the above reasons is the fact that there are involved great researchers from the University of California at Berkeley, including the visionary Ion Stoica, whom I met about Spark, and they clearly got it right!
就像我说的那样,在看完上述所有其他框架之后,我选择了RLlib。 原因多种多样。 一些已经在这篇文章中介绍了。 给我加上; 与此相关的是,它已经包含在主要的云提供商中,例如AWS和AzureML 。 或者,还有像ANYSCALE这样的推动公司已经筹集了2000万美元,并组织了Ray Summit会议,该会议将于本周(9月30日至10月1日)在网上举行,演讲嘉宾(作为我们的朋友Oriol Vinyals ;-)。 也许添加更多上下文详细信息,但是对我来说,与上述原因同样重要的是,来自加州大学伯克利分校的优秀研究人员参与其中,包括我见过Spark的有远见的Ion Stoica ,他们显然得到了对的!
See you in the next!
下次见!
本系列内容 (Content of this series)
第1部分:强化学习和深度学习中的基本概念(Part 1: Essential concepts in Reinforcement Learning and Deep Learning)
01: A gentle introduction to Deep Reinforcement Learning (15/05/2020)
01:深度强化学习入门(15/05/2020)
02: Formalization of a Reinforcement Learning Problem (22/05/2020)
02:强化学习问题的形式化(22/05/2020)
03: Deep Learning Basics (27/05/2020)
03:深度学习基础(27/05/2020)
04: Deep Learning with PyTorch (01/06/2020)
04:使用PyTorch进行深度学习(01/06/2020)
05: PyTorch Performance Analysis with TensorBoard(03/06/2020)
05:使用TensorBoard进行PyTorch性能分析(03/06/2020)
06: Solving an RL Problem Using Cross-Entropy Method(04/06/2020)
06:使用交叉熵方法解决RL问题(04/06/2020)
07: Cross-Entropy Method Performance Analysis (08/06/2020)
07:交叉熵方法性能分析(08/06/2020)
08: The Bellman Equation(11/06/2020)
08:贝尔曼方程式(11/06/2020)
09: The Value Iteration Algorithm (13/06/2020)
09:值迭代算法(13/06/2020)
10: Value Iteration for V-function (14/06/2020)
10: V函数的值迭代(14/06/2020)
11: Value Iteration for Q-function(15/06/2020)
11: Q函数的值迭代(15/06/2020)
第2部分:强化学习经典方法的实现 (Part 2: Implementation of Reinforcement Learning classical methods)
12: Reviewing Essential Concepts from Part 1(12/07/2020)
12:复习第1部分中的基本概念(12/07/2020)
13: Monte Carlo Methods & Exploration-Exploitation Dilemma (22/07/2020)
13:蒙特卡洛方法与勘探开发困境(22/07/2020)
14: MC Control Methods and Temporal-Difference Methods (26/07/2020)
14: MC控制方法和时差方法(26/07/2020)
15: Deep Q-Network — I: Open AI Gym and Wrappers (16/08/2020)
15:深度Q网络-I:开放AI体育馆和包装(16/08/2020)
16: Deep Q-Network — II: Experience Replay & Target Network (16/08/2020)
16:深度Q网络-II:体验重播和目标网络(16/08/2020)
17: Deep Q-Network — III: Performance & Use (16/08/2020)
17:深度Q网络-III:性能和使用(16/08/2020)
18: Policy-based Methods (Hill Climbing algorithm) (07/09/2020)
18:基于策略的方法(爬山算法) (07/09/2020)
19: Policy-Gradient Methods (REINFORCE algorithm) (10/09/2020)
19:策略梯度方法(REINFORCE算法) (10/09/2020)
关于本系列 (About this series)
I started to write this series in May, during the period of lockdown in Barcelona. Honestly, writing these posts in my spare time helped me to #StayAtHome because of the lockdown. Thank you for reading this publication in those days; it justifies the effort I made, and since it has attracted readers’ interest, I decided to continue this series when I find some spare time in my schedule.
我在巴塞罗那锁定期间的五月份开始写这个系列。 老实说,由于锁定,我在业余时间写这些帖子有助于我进入#StayAtHome 。 感谢您在那时阅读该出版物。 它证明了我所做的努力是合理的,并且由于它吸引了读者的兴趣,因此当我在自己的日程安排中找到一些空闲时间时,我决定继续该系列。
我们在DRL中的研究 (Our research in DRL)
Our research group at UPC Barcelona Tech and Barcelona Supercomputing Center is doing research on this topic. Our latest paper in this area is “Explore, Discover and Learn: Unsupervised Discovery of State-Covering Skills” presented in the 37th International Conference on Machine Learning (ICML2020). The paper presents a novel paradigm for unsupervised skill discovery in Reinforcement Learning. It is the last contribution of @vcampos7, one of our Ph.D. students, co-advised with@DocXavi. This paper is co-authored with @alexrtrott, @CaimingXiong, @RichardSocher from Salesforce Research.
我们位于UPC Barcelona Tech和Barcelona Supercomputing Center的研究小组正在就此主题进行研究。 我们在该领域的最新论文是在第37届国际机器学习大会(ICML2020)上发表的“探索,发现和学习:状态管理技能的无监督发现”。 本文提出了一种新的范式,用于强化学习中无监督技能的发现。 这是我们的博士学位之一@ vcampos7的最后贡献。 学生,与@DocXavi共同建议。 本文由Salesforce Research的@ alexrtrott , @ CaimingXiong和@RichardSocher合着。
翻译自: https://towardsdatascience.com/reinforcement-learning-frameworks-e349de4f645a