预训练模型专题_Bart_论文学习笔记
Bart模型作为一种Seq2Seq结构的预训练模型,是由Facebook在ACL 2020上提出。
Bart模型的论文为:《BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension》
Bart模型代码:transformers库Bart模型
Bart模型为一种基于去噪自编码器seq2seq结构的预训练模型。Bart模型在预训练阶段,核心的预训练过程为:
<1> 使用任意的噪声函数(Token Masking、Token Deletion、Text Infilling、Sentence Permutation、Document Rotation 五种噪声函数方法)来破坏预训练时输入Bart模型中的原始文本(文档);
<2> Bart模型在编码器encoder部分对输入的被破坏文本(文档)进行编码、计算与特征提取;解码器decoder则会利用交叉多头注意力聚合操作(Cross_Attention)与编码器最后一层的隐藏状态结果进行注意力聚合计算,进而以自回归的方式对被破坏的文本(文档)进行复原重建。
现如今,预训练模型大致分为三大类:
<1> 单向特征表示的自回归预训练语言模型
这类模型的代表为GPT1/GPT2/GPT3、ELMO、ULMFiT、SiATL等。
<2> 双向特征表示的自编码预训练语言模型
这类模型的代表有Bert、MASS、UniLM(微软)、ERNIE1.0/ERNIE2.0、ERNIE(清华)、MTDNN、SpanBERT、RoBERTa等。
<3> 双向特征表示的自回归预训练语言模型
XLNet等。
而Bart模型则相当于一个综合了双向特征表示的自编码Bert模型与单向特征表示的自回归GPT模型的模型框架。接下来将对Bart模型进行详细介绍。
一、Bart模型
1. Bart模型结构

Bart模型的结构如上图c中所示,图a与图b为双向特征表示的自编码Bert模型与单向特征表示的自回归GPT模型的结构对比。
从图中可以看出,Bart模型的编码器encoder部分为一个双向特征表示的自编码模型,其结构类似Bert模型,包含6层或12层transformer block; 而Bart模型的解码器decoder部分则为一个单向特征表示的自回归模型,其结构类似GPT2模型,也包含6层或12层transformer block。
而在训练阶段,决定模型是双向特征表示(自编码)还是单向特征表示(自回归)的主要因素之一,便为模型中的注意力矩阵,注意力矩阵能够决定输入模型中的文本序列位置 i i i 处的token能够获得其前向或者后向token的编码信息的多少;而attention_mask矩阵则能够决定输入模型中的文本序列位置 i i i 处的token是否能获得其前向或者后向token的编码信息。
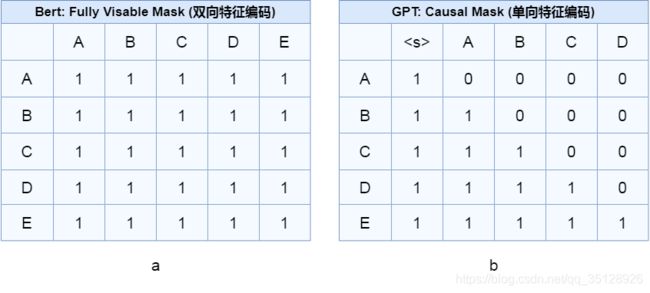
双向特征表示的自编码模型Bert的attention_mask矩阵如上图中a所示,单向特征表示的自回归模型GPT的attention_mask矩阵如上图中b所示。
由此可以看出,在Bart模型的结构中,解码器encoder负责对输入的文本(文档)进行双向特征表示编码、计算与特征提取;而解码器decoder则会利用交叉多头注意力聚合操作(Cross_Attention)与编码器最后一层的隐藏状态结果进行注意力聚合计算,进而以单向特征表示的自回归方式生成文本。
特别注意的是,若为预训练阶段,则此时输入解码器encoder中的为被任意的噪声函数(Token Masking、Token Deletion、Text Infilling、Sentence Permutation、Document Rotation)破坏的文本(文档);而解码器decoder则会以单向特征表示的自回归方式对被破坏的文本(文档)进行复原重建。
从模型结构上来说,MASS模型与Bart模型较为相似,然而MASS模型在判别式任务(discriminative tasks)上的效果不如Bart模型,这是因为在MASS模型预训练时,输入编码器encoder中的文本(文档)序列中一些连续的文本片段(span)会被选中并被遮罩掉(mask);而在解码器decoder中,其它词(在编码器端未被遮罩掉的词)都会被遮罩掉(如下图所示),以这种方式来鼓励解码器decoder只预测在编码器端被遮罩的文本片段(span)中的词,而为了给解码器decoder提供更有用的信息,编码器encoder则被强制去抽取未被遮罩掉的词的语义,以提升编码器encoder理解源序列文本的能力。
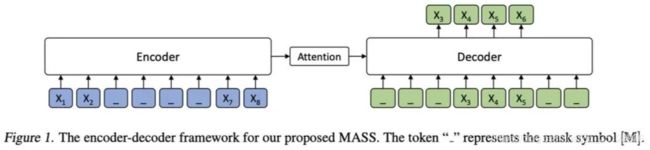
然而,MASS模型这种预训练方式会造成分别输入进编码器encoder与解码器decoder中词集合(sets of tokens)的割裂与不连贯。因此,MASS模型在判别式任务上的效果不如Bart模型。
而一些双向特征表示的自编码模型如XLNet、Bert、RoBERTa等在做生成式任务(generative tasks)时,文本序列中预测位置 i i i 处的token可同时获得其前向或者后向token的编码信息,而文本生成阶段(generation)的过程实际更符合从左向右单向特征表示的自回归编码过程。
而Bart模型中,预训练阶段(pre-training)时,其中的解码器decoder就是以从左向右单向自回归编码的方式生成文本(tokens),而这种方式与文本生成阶段(generation)生成文本(tokens)的方式一致,因此Bart模型的这种结构减弱了预训练阶段(pre-training)与文本生成阶段(generation)的不匹配度与割裂性。
此外,Bart模型的结构也与谷歌2019年提出的T5模型、2021年提出的DeBERTa模型相似,感兴趣的读者可以对比性地学习这三种模型。
2. Bart模型的预训练方法(pre-training)
正如前文所述,Bart模型在预训练阶段的两个核心过程为:
<1> 使用任意的噪声函数(Token Masking、Token Deletion、Text Infilling、Sentence Permutation、Document Rotation 五种噪声函数方法)来破坏预训练时输入Bart模型中的原始文本(文档);
<2> Bart模型在编码器encoder部分对输入的被破坏文本(文档)进行编码、计算与特征提取;解码器decoder则会利用交叉多头注意力聚合操作(Cross_Attention)与编码器最后一层的隐藏状态结果进行注意力聚合计算,进而以自回归的方式对被破坏的文本(文档)进行复原重建。模型利用此时解码器decoder的输出与未被噪声函数破坏前的原始文本(文档)计算交叉熵损失(cross-entropy loss),进而利用此交叉熵损失来优化整个Bart模型。
而在Bart模型的预训练阶段,使用的5种用于破坏原始输入文本(文档)、为原始输入文本(文档)添加噪声的噪声函数如下图所示:

2.1 Token Masking 方法
Token Masking方法为:在原始输入文本(文档)中随机抽样token并替换为[MASK]特殊符,之后预训练时Bart模型会对这些被替换为[MASK]特殊符处的原token进行预测,对被破坏的输入文本(文档)进行复原重建。
2.2 Token Deletion 方法
Token Deletion方法为:在原始输入文本(文档)中随机抽样token并删除,之后预训练时Bart模型会对被破坏的输入文本(文档)进行复原重建,包括复原被删除的token。
2.3 Text Infilling 方法
Text Infilling方法为:随机将原始输入文本(文档)中的"几个token组成的小文本片段(span)“用一个[MASK]特殊符进行替换,被替换的文本片段(span)中的token长度从泊松分布( λ \lambda λ=3)中随机抽样选取。如果此时被替换的文本片段(span)的token长度为0,则相当于直接往原始输入文本(文档)中插入一个[MASK]特殊符。
在谷歌的T5模型论文的实验中发现,被替换的文本片段(span)的token长度为3时,模型的预训练效果最好。
之后预训练时,Bart模型的解码器decoder会将被破坏的输入文本(文档)中的[MASK]特殊符复原重建为原始输入文本(文档)中被替换的"几个token组成的文本片段(span)”。
Text Infilling方法的灵感来源于SpanBERT模型,但是在SpanBERT模型中,被替换的文本片段(span)中的token长度是从另一种分布(clamped geometric)中随机抽样选取,且"几个token组成的小文本片段(span)"会被与此文本片段(span)同样token数量的[MASK]特殊符遮罩。
因此SpanBERT模型中,原始输入文本(文档)与被遮罩了文本片段(span)的文本(文档)的长度相同。
2.4 Sentence Permutation 方法
Sentence Permutation方法为:将原始输入文本(文档)按照句号拆分为一个个子句,再将这些子句打乱顺序、重新排列为新的文本(文档), 之后预训练时Bart模型会将被打乱子句顺序、并按子句重新排列的输入文本(文档)进行复原,重建为原始输入文本(文档)中的子句顺序。
2.5 Document Rotation 方法
Document Rotation方法为:从原始输入文本(文档)中均匀且随机地抽样一个token,将此token之前所有的文本(文档)内容,轮转到此token之后所有文本(文档)内容的后面,这样新的文本(文档)便以这个被选中的token开头, 之后预训练时Bart模型会将被按选中的token打乱顺序、重新排列的输入文本(文档)进行复原,重建为原始输入文本(文档)。
以上5种Bart模型预训练阶段使用的用于破坏原始输入文本(文档)、为原始文本(文档)添加噪声的噪声函数的具体方法过程参见上方 F i g u r e 2 Figure 2 Figure2。
经过对比实验发现,最有助于提升Bart模型预训练效果的噪声函数方法为Text Infilling方法与Sentence Permutation方法。
3. Bart模型的微调阶段(fine-tuning)
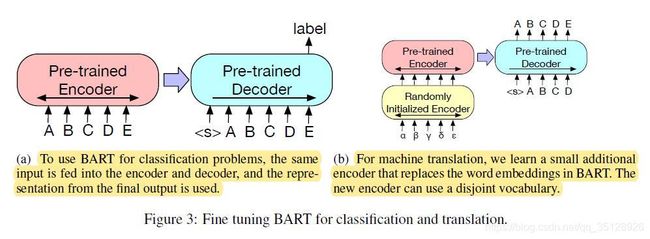
预训练阶段结束之后,经过预训练的Bart模型以及Bart模型输出的序列特征表示可在不同的下游任务中进行微调(fine-tuning)。Bart模型在不同的下游任务中进行微调的过程如下图所示。
3.1 Sequence Classification 任务
Sequence Classification任务为序列分类任务。在Sequence Classification下游任务中,文本(文档)的序列索引编码会被同时输入进Bart模型的编码器encoder与解码器decoder中,之后取解码器decoder最后一层transformer block中的最后一个token的隐藏层状态的特征表示向量输入进一个额外的线性多分类器(multi-class linear classifier)中进行分类即可。
Sequence Classification下游任务的过程可参见上图 F i g u r e 3 Figure 3 Figure3中的a图。
3.2 Token Classification 任务
Token Classification任务包含token序列分类、序列标注任务等。在Token Classification下游任务中,文本(文档)的序列索引编码会被同时输入进Bart模型的编码器encoder与解码器decoder中,之后获取解码器decoder最后一层transformer block输出的所有tokens序列的隐藏层状态的特征表示向量,再将其输入进额外的线性多分类器中进行分类,即可完成token序列分类或者序列标注等的下游任务。
这类任务比较有代表性的为对斯坦福问答数据集(SQuAD)进行答案终结点的分类(answer endpoint classification for SQuAD)。
3.3 Sequence Generation 任务
Sequence Generation任务为序列文本生成任务。由于Bart模型拥有自回归结构的解码器decoder(autoregressive decoder,在预训练时采用自回归形式进行训练),因此Bart模型很适合在 Sequence Generation(序列文本生成) 这类下游任务(如抽象问答、概括)中进行微调。
在Sequence Generation下游任务中,文本(文档)的序列索引编码会被输入进Bart模型的编码器encoder中,之后解码器decoder会以自回归的形式生成序列文本(文档)。
但需要注意的是,在微调阶段,解码器decoder以自回归的形式生成文本(文档)时,所有文本(文档)的序列索引编码也会被输入进解码器decoder中进行计算与指导(teacher模式);但在之后的测试推理阶段,解码器decoder则会以完全自回归的形式生成文本(文档),且只会有之前生成的所有文本(文档)的隐藏状态的特征表示向量(即为 layer_past 张量)输入进本次解码器decoder的迭代中,以进行下一个token的生成(此即为 layer_past 张量的方式),详细过程可参考一篇GPT2模型代码的解析中有关于 layer_past 张量使用的解析部分内容:预训练模型专题_GPT2_模型代码学习笔记
3.4 Machine Translation 任务
Machine Translation任务为机器翻译任务。而Bart模型在Machine Translation下游任务中使用了一种新的微调方法。在文章中,作者提出了一种新的机器翻译方案,即Bart模型堆叠在其他几个额外的transformer层之上。 这些额外的transformer层被称为randomly_initialized_encoder,其经过训练后,可以在Bart模型优化的同时进行反向传播优化。
randomly_initialized_encoder实质上是在Bart模型之前先将外语转换为带噪声的英语,这样便相当于将整个Bart模型用作为一个预训练的目标方语言模型(pre-trained target-side language model),此时整个Bart模型结构(包括其中的编码器与解码器)都相当于一个机器翻译任务中的解码器。
此时,Machine Translation下游任务中新的微调方法的详细过程为:去掉Bart模型中编码器encoder中的嵌入层(encoder embedding layer,需注意的是此时Bart模型的解码器中也有嵌入层),取而代之的是在整个Bart模型的编码器encoder之前再加一个额外的编码器(additional transformer layers),这个额外的编码器中的权重参数采用随机初始化,因此这一额外编码器也称为randomly_initialized_encoder。
如上图 F i g u r e 3 Figure 3 Figure3中的b图,新的额外编码器randomly_initialized_encoder将会在Bart模型之前对输入的外语文本(文档)索引进行编码计算, 这样实质上是利用额外编码器randomly_initialized_encoder将输入的外语文本(文档)先投影为noised English(带有噪声的英文文本)的隐藏状态向量;而且额外编码器randomly_initialized_encoder可以使用与Bart模型分离的词汇表(separate vocabulary)。
之后,额外编码器randomly_initialized_encoder中输出的noised English(带有噪声的英文文本)的隐藏状态特征表示向量将会被先输入进Bart模型的编码器encoder中计算,接着Bart模型编码器encoder的计算结果会被输入进Bart模型的解码器decoder中进行解码计算。
综上,此时的Bart模型堆叠在额外编码器randomly_initialized_encoder之上,且Bart模型整体(包括Bart模型中的编码器部分与解码器部分)相当于一整个解码器。
而在这种Machine Translation下游任务中,额外编码器randomly_initialized_encoder与Bart模型的微调训练过程分为两步, 每一步都是使用由Bart模型的最终输出所计算得出的交叉熵损失来反向传播优化模型参数的。
第一步:只更新Bart模型编码器encoder中第一层transformer block的自注意力(Masked_Multi_Self_Attention)层的参数、BART模型的位置嵌入参数(positional embeddings)、与额外编码器randomly_initialized_encoder中的参数,即第一步只更新这三部分的参数,其他Bart模型中的参数都被冻结。
第二步:仅以小次数的迭代,来更新额外编码器randomly_initialized_encoder与Bart模型中的所有参数。
二、Bart模型与其他预训练方法的效果对比
在与其他预训练方法进行效果对比时,此时使用的Bart模型为包含6层编码器层(encoder layers)、6层解码器层(decoder layers)、隐藏状态维度为768维的base_size的Bart模型。
此时Bart模型会使用前文详述的5种用于破坏原始输入文本(文档)、为原始输入文本(文档)添加噪声的噪声函数:Token Masking、Token Deletion、Text Infilling、Sentence Permutation、Document Rotation 来与其他5种基于Bert模型的预训练方法进行效果对比。
作者在复现这些基于Bert模型的预训练方法时特别强调在复现时尽量控制与预训练目标无关的变量,且令学习率与Layer Normalization层基本不做改变,以此达到与Bart模型预训练过程基本一致的目的。
1. 用于效果对比的其他预训练方法
1.1 Language Model
Language Model预训练方法为训练一个类似GPT2这种从左向右单向编码的自回归语言模型,相当于Bart模型中的解码器decoder部分不加交叉多头注意力聚合操作(Cross_Attention)。
1.2 Permuted Language Model
在Permuted Language Model预训练方法中,会随机从原始输入文本(文档)中抽样六分之一的tokens,再以自回归的随机顺序生成这些tokens。并且,为了与其他预训练模型保持一致,并未对此处的 Permuted Language Model 采用与XLNet模型中相同的相对位置编码(relative positional embeddings)与跨片段注意力机制(attention across segments)。
1.3 Masked Language Model
在Masked Language Model预训练方法中,会随机将原始输入文本(文本)中15%的tokens替换为[MASK]遮罩特殊符,再训练遮罩语言模型(masked language model)去独立地预测原始的tokens(即未被遮罩特殊符[MASK]遮罩前的tokens)。
1.4 Multitask Masked Language Model
在使用Multitask Masked Language Model预训练方法时,会仿照微软的UniLM模型中的方法,使用一个额外的自注意力遮罩矩阵(self-attention masks,即用来遮罩注意力分数的矩阵)来训练模型。而UniLM模型中最核心的自注意力遮罩矩阵Self-attention Masks的详细用法如下图所示:

在Multitask Masked Language Model预训练方法中,对于原始输入文本(文档)的batch样本,将利用自注意力遮罩矩阵(self-attention masks) (1) 随机将六分之一的样本按从左向右的方向遮罩注意力分数;(2) 随机将六分之一的样本按从右向左的方向遮罩注意力分数;(3) 随机将三分之一的样本不进行遮罩;(4) 随机将剩余的最后三分之一的样本中前50%的样本不遮罩,剩余的样本按从左向右的方向遮罩注意力分数。
1.5 Masked Seq-to-Seq
在使用Multitask Masked Language Model预训练方法时,会仿照MASS模型,随机在原始输入文本(文档)中选择一个文本片段(span)进行遮罩,这个被遮罩的文本片段(span)应包含原始输入文本(文档)中50%的tokens,之后会训练seq2seq形式的模型来预测(复原重建)这些被遮罩的文本片段(span)中的tokens。
对Permuted Language Model、Masked Language Model、Multitask Masked Language Model 这三个对比性预训练方法来说,将会使用双流注意力(two-stream attention)去更有效地计算预训练模型输出的结果文本索引序列的似然。此外,此时对预训练模型输出的结果文本索引序列使用对角线自注意力遮罩矩阵(diagonal self-attention mask)来实现"从左向右"形式的预测。
2. 下游任务数据集
在用前文Bart模型的5种预训练方法与上述其他5种基于Bert模型的预训练方法进行效果对比时,所使用到的下游任务数据集为以下罗列的6种数据集,这些数据集涉及抽取式问答(Extractive Question Answering)、抽象问答(Abstractive Question Answering)、文本蕴含(Text Entailment)、对话响应生成(Dialogue Response Generation)、文本概括(Summarization)这五种任务。
2.1 SQuAD数据集
斯坦福问答数据集SQuAD为基于维基百科网页构建的抽取式问答数据集,数据集中的回答(answer)文本都是从数据集中给定的文档上下文(document context)中抽取出来的文本片段(text span)。
即斯坦福问答数据集SQuAD中有三种文本:(1) 文档上下文(document context)文本;(2) 问题(question)文本;(3) 答案(answer)文本。
在使用斯坦福问答数据集SQuAD进行下游任务微调时,文档上下文(document context)与问题(question)文本会被拼接到一起输入进Bart模型的编码器encoder中,而答案(answer)文本则会被输入进Bart模型的解码器decoder中进行计算与指导(teacher模式)。
此外,在使用斯坦福问答数据集SQuAD进行下游任务微调时,Bart模型还会额外包含并训练一个预测模型输出的文本序列中的token是否为start标志或者end标志的分类层(相当于三分类)。
2.2 ELI5数据集
ELI5数据集为一个长文本形式的抽象问答(Abstractive Question Answering)数据集。
在使用长文本抽象问答数据集ELI5进行下游任务微调时,文档上下文(document context)与问题(question)文本会被拼接到一起输入进Bart模型的编码器encoder中,而答案(answer)文本则会被输入进Bart模型的解码器decoder中进行计算与指导(teacher模式)。在进行测试/推理时,解码器decoder用于生成答案(answer)文本。
2.3 MNLI数据集
MNLI数据集为一个双文本分类的数据集,其任务是预测这两个文本中,一个文本是否蕴含另一个文本的含义,即文本蕴含任务(Text Entailment)。
在使用文本蕴含数据集MNLI进行下游任务微调时,两个文本句子将会被拼接到一起,并在这个拼接的文本最后再拼接一个EOS结束标志特殊符,之后会将这个拼接长文本输入进Bart模型的编码器encoder与解码器decoder中。
与Bert模型中不同的是,在用Bart模型进行文本蕴含(text entailment)下游任务微调时,是使用最后Bart模型输出的EOS结束标志特殊符处的隐藏状态特征表示向量来进行最终的分类 (即将EOS结束标志特殊符处的隐藏状态特征表示向量输入进分类层中进行二分类)。
2.4 XSum数据集
XSum数据集为一个具有高度抽象摘要文本(highly abstractive summaries)的新闻摘要数据集。
在使用摘要(Summarization)任务数据集XSum进行下游任务微调时,文档上下文(document context)会被输入进Bart模型的编码器encoder中,而对应的摘要(summarization)文本则会被输入进Bart模型的解码器decoder中进行计算与指导(teacher模式)。在进行测试/推理时,解码器decoder则用于生成文档上下文(document context)对应的摘要(summarization)文本。
2.5 CNN/DM数据集
CNN/DM数据集为新闻摘要数据集。CNN/DM数据集中的摘要文本(summaries)通常与其文档上下文(document context)中的句子紧密相关或相似(closely related)。
在使用摘要(Summarization)任务数据集CNN/DM进行下游任务微调时,文档上下文(document context)会被输入进Bart模型的编码器encoder中,而对应的摘要(summarization)文本则会被输入进Bart模型的解码器decoder中进行计算与指导(teacher模式)。在进行测试/推理时,解码器decoder则用于生成文档上下文(document context)对应的摘要(summarization)文本。
2.6 ConvAI2数据集
ConvAI2数据集为一个对话响应生成任务(Dialogue Response Generation)数据集,其文本数据取决于上下文(context)和角色(persona)。
3. Bart模型与其他预训练方法的对比结果

上图为基于Bart模型的6种预训练方法(增加了一种组合方法Text Infilling + Sentence Shuffing)与基于Bert模型的5种预训练方法在上述的6个下游任务数据集上的效果对比结果表。
基于上表中的效果对比,得出如下结论:
(1) Performance of pre-training methods varies significantly across tasks
不同的预训练方法在不同的下游任务数据集上效果的差异很明显,预训练方法的效果与其所使用的下游任务数据集具有强相关性。
简单自回归语言模型方法(simple language model)在长文本抽象问答数据集ELI5上可取得所有预训练方法中最好的效果,但其在斯坦福问答数据集SQuAD上却取得所有预训练方法中最差的效果。
(2) Token masking is crucial
在上表中( T a b l e 1 Table 1 Table1)所有的11种预训练方法中,单独使用Document Rotation预训练方法或Sentence Permutation预训练方法时,预训练模型在下游任务数据集上的效果都不理想。
而单独使用Token Masking预训练方法、Token Deletion预训练方法、Self-attention Masks预训练方法时,预训练模型在下游任务数据集上的效果都较好。
而使用Token Deletion预训练方法的预训练模型在文本生成类下游任务数据集上的效果比使用Token Masking预训练方法的预训练模型效果要好。
(3) Left-to-right pre-training improves generation
在用来进行效果对比的所有预训练方法之中,Masked Language Model预训练方法与Permuted Language Model预训练方法,在文本生成类下游任务数据集上的效果比其他预训练方法的效果都差,因此在使用Masked Language Model与Permuted Language Model这两种预训练方法时,在预训练阶段并未包含从左向右的自回归语言建模过程(not include left-to-right auto-regressive language modelling during pre-training)。
(4) Bidirectional encoders are crucial for SQuAD
在下游任务数据集SQuAD上,基于Language Model方法的预训练模型(从左向右的解码器形式, left-to-right decoder)表现的效果较差,因为在下游任务数据集SQuAD中,右向的未来上下文(future context)的编码对于分类的最终效果有很重要的影响。
然而,BART模型仅用一半层数的双向编码层(bidirectional layers)便实现了Bert模型相似的性能。
(5) The pre-training objective is not the only important factor
预训练方法并不是唯一重要的因素。在此处,使用Permuted Language Model方法的预训练模型(Bert模型)的效果较XLNet模型的效果要差,这是因为在使用Permuted Language Model方法的预训练模型中并未使用与XLNet模型相同的位置编码(relative positional embeddings)与跨片段注意力机制(attention across segments)。
(6) Pure language models perform best on ELI5
长文本抽象问答数据集ELI5是一个较为特殊的数据集,其数据集中的文本要比其他下游任务数据集中的文本更长、更为复杂、更为抽象。并且在下游任务数据集ELI5上,使用Pure Language Model方法的预训练模型的效果比使用其他预训练方法的预训练模型的效果都好。
此外,纯语言模型(Pure Language Model)方法的效果最好,这表明当输出仅受到输入的松散约束时,Bart模型的效果较差、较为低效。
(7) BART achieves the most consistently strong performance
综上所述,除了长文本抽象问答数据集ELI5,使用Text Infilling预训练方法的预训练Bart模型在其他下游任务数据集上都取得了较为一致的好的效果。
三、Large版本预训练Bart模型的对比实验
一些先前的研究提出,在模型预训练阶段使用大的batch size与大规模的语料库(copora)时,将会显著改善此预训练模型在下游任务上的效果。
因此,在Large版本预训练Bart模型(large-Bart)的对比实验这一部分,将使用具有12层编码器(12 encoder layers)与12层解码器(12 decoder layers)的large版本的Bart模型,模型中隐藏层状态的维度设为1024。同时这一部分其他预训练模型也使用其各自large版参数。
此外,仿照RoBERTa模型,此处的batch_size设为8000,让Bart模型在预训练阶段一共迭代500000次。
而此时的tokenization方法则使用与GPT2模型中一样的字节对编码(BPE: byte-pair encoding).
此时将Text Infilling预训练方法与Sentence Permutation预训练方法结合在一起,来对large版本的Bart模型进行预训练。此时,原始输入文本(文档)中30%的tokens会被随机遮罩(mask),并且置换重排原始输入文本(文档)中的所有句子(sentences)。
并且,为了让large版本的Bart模型在预训练时更好得拟合数据,在最后10%的预训练迭代次数中,会停用模型中的dropout层。
利用在上述条件下预训练好的large版本Bart模型(large-Bart)与其他large版本的预训练模型,在一些下游任务数据集上(如SQuAD、GLUE、CNN/DailyMail、XSum、ConvAI2、ELI5、RO-EN)进行效果对比,效果对比实验的结果如下所示。
1. 模型效果对比之判别式任务(Discriminative Tasks)
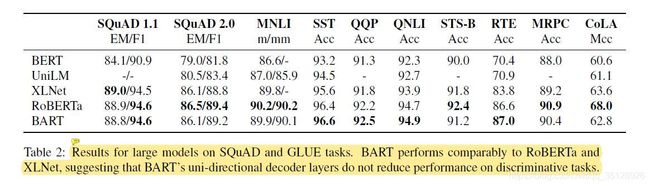
判别式任务(Discriminative Tasks)也为自然语言理解任务,上表( T a b l e 2 Table 2 Table2)为large版本的Bart预训练模型与其他4种预训练模型在下游数据集SQuAD与GLUE上的对比结果。
从上表中( T a b l e 2 Table 2 Table2)中可以发现,除了Bart模型以外,RoBERTa模型较之其余预训练模型在SQuAD与GLUE下游任务数据集上的效果都更好,且在此处RoBERTa模型与Bart模型预训练时使用的数据相同,因此在判别式任务(Discriminative Tasks)的下游数据集中(SQuAD与GLUE下游任务数据集),直接与Bart模型对比的baseline模型即为RoBERTa模型。在这里,Bart模型的效果可比肩RoBERTa模型与XLNet模型,甚至在GLUE上的几项任务中都超越了RoBERTa模型与XLNet模型的效果。
从上表中可以看出,large版本的Bart模型(large-Bart)中包含的单向特征编码(从左向右)的解码器decoder(uni-directional decoder)并未降低large-Bart模型在判别式任务(Discriminative Tasks)的下游数据集(SQuAD与GLUE下游任务数据集)上的效果。这证明large-Bart模型在文本生成式任务(Generation Tasks)上的改进(双向特征编码器encoder + 单向特征解码器decoder的改进)不会以降低判别式任务(Discriminative Tasks)上的性能效果为代价。
2. 模型效果对比之文本生成任务(Generation Tasks)
在文本生成任务(Generation Tasks)中,large版本Bart模型按照标准seq2seq模型的方式进行微调(fine-tuning)。同时,使用标签平滑交叉熵损失函数(label smoothed cross entropy)在微调时对所有预训练模型进行优化,此时平滑参数设置为0.1(即正确标签为0.9,其他所有标签加和为0.1)。
在文本生成时,将会使用Beam Search(集束搜索),此时Beam Search的beam_size参数设置为5(即每一轮时,取概率最高的前5个token作为本轮生成的候选token);同时将Beam Search结果中重复的trigrams(三元token)删除。
2.1 摘要生成任务(Summarization)
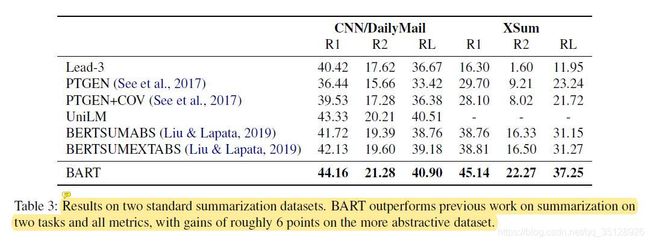
Bart预训练模型(large-Bart)与其他6种模型在摘要生成任务(Summarization)的下游数据集CNN/DailyMail与XSum上的对比结果如上表( T a b l e 3 Table 3 Table3)所示。
从上表中可以看出,在两个摘要生成任务下游数据集CNN/DailyMail与XSum上,Bart模型在所有度量指标上均优于其他模型,Bart模型在更加抽象的XSum数据集上要比之前sota模型的效果高出约6个点(单个ROUGE度量指标)。
在下游数据集CNN/DailyMail上,模型趋向于使用数据集样本中的集成句子来作为样本的摘要(summaries)。因此,下游数据集CNN/DailyMail更适合用来做抽取式摘要任务(Extractive Summarization)而非生成式摘要任务(Generative Summarization)。
此时,抽取式方法Lead-3(即抽取样本文档中的前三个句子的朴素方法)以及双向特征表示的自编码模型(如Bert、RoBERTa、XLNet等)更适合用来对数据集CNN/DailyMail进行摘要生成任务。
然而,Bart预训练模型(large-Bart)对于下游数据集CNN/DailyMail的摘要生成效果不亚于RoBERTa、XLNet等模型的摘要生成效果,这说明Bart模型也很适合用来进行抽取式摘要生成任务(Extractive Summarization)。
而下游数据集XSum的样本内容则比下游数据集CNN/DailyMail的样本内容更为抽象,因此在这里用抽取式方法Lead-3或双向特征表示自编码模型(Bert、RoBERTa、XLNet等)来对数据集XSum进行摘要生成的效果则会很差。
而此时,Bart模型由于其seq2seq的结构(双向特征编码的编码器encoder + 单向特征编码的解码器decoder),则会更加适合对样本内容更为抽象的XSum数据集来进行摘要生成任务。因此在上方 T a b l e 3 Table 3 Table3中,Bart模型在更加抽象的XSum数据集上才会比之前sota模型的效果高出约6个点。
2.2 对话响应生成任务(Dialogue Response Generation)
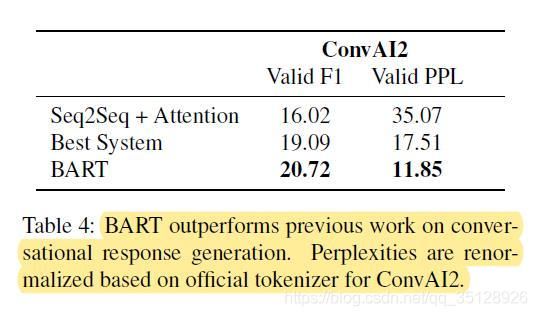
Bart预训练模型(large-Bart)与其他模型在对话响应生成任务(Dialogue Response Generation)下游数据集ConvAI2上的对比结果如上表( T a b l e 4 Table 4 Table4)所示。
从上表( T a b l e 4 Table 4 Table4)中可以看出,在下游数据集ConvAI2上,Bart模型的对话响应生成效果(F1与困惑度PPL指标)显著优于Best System与Seq2Seq + Attention模型。其中困惑度基于 ConvAI2 官方 tokenizer 进行了重新归一化。
2.3 抽象问答任务(Abstractive QA)
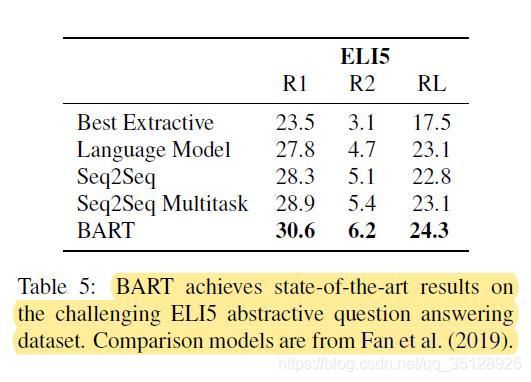
Bart预训练模型(large-Bart)与其他预训练模型在抽象问答任务(Abstractive QA)下游数据集ELI5上的对比结果如上表( T a b l e 5 Table 5 Table5)所示。
由于ELI5数据集为一个长文本形式的抽象问答(Abstractive Question Answering)数据集,因此在这里需要比较不同模型在ELI5数据集上自由格式的长答案(long free-form answers)文本的生成效果。
从上表( T a b l e 5 Table 5 Table5)中可以看出,Bart模型在长文本抽象问答数据集ELI5上的自由格式长答案(long free-form answers)的三个文本生成效果度量指标(R1、R2、RL)上平均优于之前的sota模型1.2个点。
3. 模型效果对比之机器翻译任务(Translation Tasks)

此时机器翻译任务(Translation Tasks)的下游数据集WMT16(RO-EN)为一个罗马尼亚语与英语之间的翻译数据集。
此时使用Baseline模型(large版的transformer模型)、Fixed-Bart(预训练的Bart模型)、Tuned-Bart(微调的Bart模型)三种模型,在WMT16数据集(罗马尼亚语翻为英语)和用于数据增强的回译数据集(英语翻为罗马尼亚语, Sennrich et al. 2016)上对比测试模型翻译的效果。
此时,在进行机器翻译任务(Translation Tasks)的Bart模型会使用上文中提到的新的微调方法,即Bart模型堆叠在拥有6层transformer block的额外编码器randomly_initialized_encoder之上,Bart模型整体(包括Bart模型中的编码器部分与解码器部分)相当于一整个解码器。
此时,额外编码器randomly_initialized_encoder实质上是将输入的外语文本(文档)先投影为noised English(带有噪声的英文文本)的隐藏状态向量,之后将noised English的隐藏状态特征向量输入进Bart模型的编码器encoder中进行编码计算,再将计算结果输入进Bart模型的解码器decoder中进行解码计算,此时整个Bart模型相当于被用作一个预训练的目标方语言模型(pre-trained target-side language model)。
上表( T a b l e 6 Table 6 Table6)为这三种模型在机器翻译任务(Translation Tasks)的下游数据集WMT16(RO-EN)加回译增强数据集上的性能对比结果。
虽然Bart模型的机器翻译效果比Baseline模型的效果要好,但是实验发现当Bart模型不使用回译增强数据集(英语翻为罗马尼亚语, Sennrich et al. 2016)时,模型的机器翻译效果就会变得不太理想且模型还会容易过拟合。因此在Bart模型的机器翻译任务上,应该探索额外的正则化技巧来防止Bart模型过拟合。
四、总结
综上所述,Bart模型为一种基于去噪自编码器seq2seq结构的预训练模型,其文章中的一些优点与不足总结如下:
优点:
- Text Infilling与Sentence Permutation这两种用于破坏原始输入文本(文档)、为原始输入文本(文档)添加噪声的预训练方法能够显著改进Bart模型在下游任务上的性能与效果。而使用Token Deletion预训练方法的预训练模型在文本生成类下游任务数据集上的效果比使用Token Masking预训练方法的预训练模型效果要好。
- Bart模型中包含的单向特征编码(从左向右)的解码器decoder(uni-directional decoder)并未降低Bart模型在判别式任务(自然语言理解)的下游数据集上的效果;其在文本生成式任务(Generation Tasks)上的改进(双向特征编码器encoder + 单向特征解码器decoder的改进)不会以降低判别式任务(Discriminative Tasks)上的性能效果为代价。
- Bart模型在文本生成任务(Generation Tasks)上的效果很好。并且,Bart模型因其seq2seq的结构(双向特征编码的编码器encoder + 单向特征编码的解码器decoder),更加适合对样本内容更为抽象的下游数据集进行摘要生成任务。
- Bart模型中,预训练阶段(pre-training)时,其中的解码器decoder就是以从左向右单向自回归编码的方式生成文本(tokens),而这种方式与文本生成阶段(generation)生成文本(tokens)的方式一致,因此Bart模型的这种结构减弱了预训练阶段(pre-training)与文本生成阶段(generation)的不匹配度与割裂性。
- 文章中提出了一种新的在机器翻译任务上的微调方法,即Bart模型堆叠在拥有6层transformer block的额外编码器randomly_initialized_encoder之上,Bart模型整体(包括Bart模型中的编码器部分与解码器部分)相当于一整个解码器,此时额外编码器randomly_initialized_encoder实质上是将输入的外语文本(文档)先投影为noised English(带有噪声的英文文本),再将其输入进Bart模型中进行计算并最终得出英文翻译文本。
不足:
- 在摘要生成任务(Summarization)上,Bart模型生成的文档摘要文本与人类的摘要结果相比仍然有一定差距。
- 在机器翻译任务(Translation Tasks)中,Bart模型不使用回译增强数据集(英语翻为罗马尼亚语, Sennrich et al. 2016)时,模型的机器翻译效果就会变得不太理想且模型还会容易过拟合。因此,应该探索额外的正则化技巧来防止Bart模型过拟合。
References
[1] Lewis M, Liu Y, Goyal N, et al. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension[J]. arXiv preprint arXiv:1910.13461, 2019.