五、Python复习教程(重点)-爬虫框架实战
目录导航:
文章目录
- 目录导航:
- 九、Python网络爬虫进阶实战(上)
-
- 1. Scrapy框架介绍与安装
-
- 1.1.认识Scrapy框架
-
- Scrapy框架介绍:
- Scrapy框架的运行原理:
- Scrapy主要包括了以下组件:
-
- Scrapy运行流程大概如下:
- 1.2 Scrapy的安装:
- 1.3 Scrapy爬虫框架的具体使用步骤如下:
- 2. Scrapy框架的使用
-
- 2.1 Scrapy框架的命令介绍
-
- Scrapy 命令 分为两种:`全局命令` 和 `项目命令`。
-
- 全局命令
- 项目命令:
- Scrapy框架的命令使用:
-
- shell命令, 进入scrpay交互环境
- 2.2 Scrapy框架的使用:
-
- ① 创建项目
- ② 进入demo项目目录,创建爬虫spider类文件
- ③ 创建Item
- ④ 解析Response
- ⑤ 使用Item Pipeline
- ⑥ 运行:
- 2.3 Scrapy框架中的POST提交:
- 3. Selector选择器
-
- 3.1 直接使用:
- 3.2 Scrapy shell
- 3.3 Xpath选择器:
- 3.4 CSS选择器:
- 3.5 正则匹配:
- 4. Spider的使用
-
- 4.1 Spider运行流程:
- 4.2 Spider类分析:
- 4.3 实战案例:
- 5. Downloader Middleware的使用
-
- 5.1 使用说明:
- 5.2 自定义Downloader Middleware中间件
-
- ① process_request(request,spider)
- ② process_response(request, response, spider)
- ③ process_exception(request, exception, spider)
- 5.3 实战案例:
- 6. Spider Middleware的使用
-
- 6.1 激活spider中间件
- 6.2 编写您自己的spider中间件
-
- process_spider_input(response, spider)
- process_spider_output(response, result, spider)
- process_spider_exception(response, exception, spider)
- process_start_requests(start_requests, spider)
- Scrapy框架的配置Settings
-
- 内置设置参考手册
- 7. ItemPipeline的使用
-
- 7.1 如何编写你自己的item pipeline
-
- ① `process_item(item, spider)`
- ② `open_spider(spider)`
- ③ `close_spider(spider)`
- 7.2 样例:
-
- 验证价格,同时丢弃没有价格的item
- 将item写入JSON文件:
- 去重
- 启用一个Item Pipeline组件:
- 7.3 Scrapy框架案例实战:
-
- ① 创建项目
- ② 进入educsdn项目目录,创建爬虫spider类文件(courses课程)
- ③ 创建Item
- ④ 解析Response
- ⑤、创建数据库和表:
- ⑥、使用Item Pipeline
- ⑦ 修改配置文件
- ⑧、运行爬取:
- ① ImagesPipeline介绍
- ② 具体使用:
- 8. Scrapy爬虫案例实战
-
-
- ① 创建项目
- ② 进入tencent项目目录,创建爬虫spider类文件(hr招聘信息)
- ③ 创建Item
- ④ 解析Response
- ⑤、创建数据库和表:
- ⑥、使用Item Pipeline
- ⑦ 修改配置文件
- ⑧、运行爬取:
-
- 9. Scrapy扩展
-
- 1. 如何使scrapy爬取信息不打印在命令窗口中
- 2. Scrapy中的日志处理
- 十、Python网络爬虫进阶实战(中)
-
- 09. Selenium的使用
-
- 9.1 动态渲染页面爬取
- 9.2 Selenium的介绍
- 9.3 Selenium的使用
-
-
- ① 初次体验:模拟谷歌浏览器访问百度首页,并输入python关键字搜索
- ② 声明浏览器对象
- ③ 访问页面
- ④ 查找节点:
- ⑤ 节点交互:
- ⑥ 动态链:
- ⑦ 执行JavaScript:
- ⑧ 获取节点信息:
- ⑨ 切换Frame:
- ⑩ 延迟等待:
- 11 前进和后退:
- 12 Cookies:
- 13 选项卡管理:
- 14 异常处理:
-
- 10. Selenium爬取淘宝商品
-
- ① 案例要求
- ② 案例分析:
- ③ 具体代码实现
- 11. MongoDB数据库
-
- 1.1 RDBMS与NoSQL区别:
- 1.2 Windows下安装MongoDB:
- 1.3 数据库的操作
-
- ① MongoDB的数据库操作
- ② MongoDB的集合操作:
- ③ 数据类型:
- ④ 数据的操作
- 11.4 备份与恢复
- 11.5 与python交互
- 12. Scrapy框架使用Selenium
-
-
- ① 创建项目
- ② 定义Item类
- ③ 解析页面
- ④ 对接Selenium
- ⑤ 解析页面信息
- ⑥ 存储结果
-
- 13. 代理的使用
-
- 13.1 代理服务的介绍:
- 13.2 代理的设置:
-
- ① urllib的代理设置
- ② requests的代理设置
- ③ Selenium的代理使用
- ④ 在Scrapy使用代理
- 13.3 免费代理IP的使用
- 13.4 收费代理IP的使用
- 14. 使用代理爬取信息实战
-
- 14.1 实战目标:
- 14.2 准备工作:
- 14.3 具体实现:
-
- ① 创建项目
- ② 定义Item类
- ③ 解析页面
- ④ 存储结果
- ⑤ 执行爬虫文件开始信息爬取
- ⑥ 在中间件中使用付费代理服务来解决上面错误:
- 15. Redis数据库
-
- 15.1 Redis简介
- 15.2 Redis的安装:
- 15.3 Redis的操作:
-
- ① String(子串类型)
- ② hash类型:
- ③ list类型(双向链表结构)
- ④ sets类型和操作:
- ⑤ 有序集合(sorted set):
- ⑥ Redis常用命令:
- 15.4 Redis高级实用特性
- 15.5 Python使用Redis
-
- redis操作hash哈希
- redis操作list链表
- redis操作set集合
- 16. 分布式爬虫原理
-
- 16.1 分布式爬虫架构
- 16.2 维护爬取队列
- 16.3 如何去重
- 16.4 防止中断
- 16.5 架构实现
- 17. Scrapy分布式实战
-
- 17.1 准备
- 17.2 Scrapy-redis各个组件介绍
-
- ① connection.py
- ② dupefilter.py
- ③ queue.py
- ④ pipelines.py
- ⑤ scheduler.py
- ⑥ spider.py
- 17.3 具体使用(对Scrapy改造):
-
- 1.首先在settings.py中配置redis(在scrapy-redis 自带的例子中已经配置好)
- 2.item.py的改造
- 3.spider的改造。star_turls变成了redis_key从redis中获得request,继承的scrapy.spider变成RedisSpider。
- **启动爬虫:**
- **更多关于配置Scrapy框架中配置:settings.py**
- 17.4 实战案例:
-
- ① 编写slave(从)项目代码:
- ② 编写master(主)项目代码:
- 17.5 处理的Redis里的数据:
-
- 存入的MongoDB
- 十一、Python网络爬虫进阶实战(下)
-
- 18. App的信息爬取
-
- 18.1 Charles的介绍
-
- Charles主要功能:
- 18.2 Charles的配置
-
- ① 网络共享配置:
- ② 代理设置:
- ③ 证书配置:
- ⑤ Charles 配置 HTTPS 代理的乱码问题
- 18.3 Charles的运行原理和具体使用
-
- ① 运行原理:
- ② 具体使用
- 19. mitmproxy的使用
-
- 19.1 安装和配置:
- 19.2 mitmproxy的使用:
- 19.3 mitmdump的使用:
- 20. App信息抓取实战
-
-
- ① 抓取目标:
- ② 准备工作和抓取分析
- ③ 代码编写:
-
- 21. 从API爬取天气预报数据
-
- 21.1 注册免费API和阅读文档
- 21.2 提取全国城市信息
- 21.3 获取指定城市的天气信息
- 21.4 综合实例
- 22. 滑动验证码的识别
-
- 22.1 滑动验证码的识别介绍
- 22.2 实现步骤:
-
- ① 初始化
- ② 模拟登录填写,点开滑块验证
- ③ 获取并储存有无缺口的两张图片
- ④ 获取缺口位置
- ⑤ 获取移动轨迹
- ⑥ 按照轨迹拖动,完全验证
- ⑦ 完成登录
- 22.3 完整代码:
- 23. 爬虫项目需求分析
-
-
- 1 项目名称
- 2 项目描述:
- 3 爬取网站过程分析:
- 4 运行环境要求:
- 5 项目中的建议:
-
- 24. 爬虫项目架构设计
-
-
- 1. 数据库设计:
- 2. 项目结构:
- 3. 具体实施描述
- 4. 项目中的规范:
-
- 25. 爬虫项目的代码实现
-
- 25.1 数据库的准备:
- 25.2 模块1的实现:
- 25.3 模块2的实现:
- 25.4 模块3的实现:
- 25.5 模块4的实现:
- 25.6 反爬处理:
- 26. 使用web展示爬取信息
-
- 26.1 创建项目myweb和应用web
- 26.2 执行数据库连接配置,网站配置
- 26.3 定义Model类
- 26.4 URL路由配置:
- 26.5 编写视图处理文件
- 26.5 编写模板输出文件
- 26.6 启动服务测试:
- 26.7 练习:
- [Published with GitBook](https://www.gitbook.com/)
九、Python网络爬虫进阶实战(上)
1. Scrapy框架介绍与安装
2. Scrapy框架的使用
3. Selector选择器
4. Spider的使用
5. Downloader Middleware的使用
6. Spider Middleware的使用
7. ItemPipeline的使用
8. Scrapy实战案例
1. Scrapy框架介绍与安装
1.1.认识Scrapy框架
Scrapy框架介绍:
Scrapy是: 由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。- Scrapy用途广泛,可以用于
数据挖掘、监测和自动化测试。
 ]
]
- Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
- Scrap,是碎片的意思,这个Python的爬虫框架叫Scrapy。
Scrapy框架的运行原理:
 ]
]
Scrapy主要包括了以下组件:
- 引擎(Scrapy Engine)
- 用来处理整个系统的数据流处理, 触发事务(框架核心)
- Item 项目,它定义了爬取结果的数据结构,爬取的数据会赋值成改Item对象
- 调度器(Scheduler)
- 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回.
- 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
- 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
- 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
- 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
- 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares)
- 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares)
- 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
数据处理流程
- Scrapy的整个数据处理流程有Scrapy引擎进行控制,其主要的运行方式为:
- 引擎打开一个域名,时蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL。
- 引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
- 引擎从调度那获取接下来进行爬取的页面。
- 调度将下一个爬取的URL返回给引擎,引擎将它们通过下载中间件发送到下载器。
- 当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
- 引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
- 蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
- 引擎将抓取到的项目项目管道,并向调度发送请求。
- 系统重复第二部后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系。
1.2 Scrapy的安装:
- 第一种:在命令行模式下使用pip命令即可安装:
$ pip install scrapy
F:\Python02\demo>scrapy version
Scrapy 1.5.0
- 第二种:首先下载,然后再安装:
$ pip download scrapy -d ./
# 通过指定国内镜像源下载
$pip download -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy -d ./
- 具体文件如下:
 ]
]
- 进入下载目录后执行下面命令安装:
$ pip install Scrapy-1.5.0-py2.py3-none-any.whl
- 注意安装过程中由于缺少
Microsoft Visual C++ 14.0那么请先安装此软件后再执行上面的命令安装就可以了。
 ]
]
- 下载软件如下:visualcppbuildtools_full.exe
 ]
]
1.3 Scrapy爬虫框架的具体使用步骤如下:
 ]
]
2. Scrapy框架的使用
2.1 Scrapy框架的命令介绍
Scrapy 命令 分为两种:全局命令 和 项目命令。
全局命令:在哪里都能使用。项目命令:必须在爬虫项目里面才能使用。
全局命令
C:\Users\AOBO>scrapy -h
Scrapy 1.2.1 - no active project
使用格式:
scrapy [options] [args]
可用的命令:
bench 测试本地硬件性能(工作原理:):scrapy bench
commands
fetch 取URL使用Scrapy下载
genspider 产生新的蜘蛛使用预先定义的模板
runspider 运用单独一个爬虫文件:scrapy runspider abc.py
settings 获取设置值
shell 进入交互终端,用于爬虫的调试(如果你不调试,那么就不常用):scrapy shell http://www.baidu.com --nolog(--nolog 不显示日志信息)
startproject 创建一个爬虫项目,如:scrapy startproject demo(demo 创建的爬虫项目的名字)
version 查看版本:(scrapy version)
view 下载一个网页的源代码,并在默认的文本编辑器中打开这个源代码:scrapy view http://www.aobossir.com/
[ more ] 从项目目录运行时可获得更多命令
使用 "scrapy -h" 要查看有关命令的更多信息
项目命令:
D:\BaiduYunDownload\first>scrapy -h
Scrapy 1.2.1 - project: first
Usage:
scrapy [options] [args]
Available commands:
bench Run quick benchmark test
check Check spider contracts
commands
crawl 运行一个爬虫文件。:scrapy crawl f1 或者 scrapy crawl f1 --nolog
edit 使用编辑器打开爬虫文件 (Windows上似乎有问题,Linux上没有问题):scrapy edit f1
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list 列出当前爬虫项目下所有的爬虫文件: scrapy list
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings 获取设置值
shell 进入交互终端,用于爬虫的调试(如果你不调试,那么就不常用)
startproject 创建一个爬虫项目,如:scrapy startproject demo(demo 创建的爬虫项目的名字)
version 查看版本:(scrapy version)
view 下载一个网页的源代码,并在默认的文本编辑器中打开这个源代码
Use "scrapy -h" to see more info about a command
注意:Scrapy运行ImportError: No module named win32api错误。请安装:pip install pypiwin32
Scrapy框架的命令使用:
-
查看所有命令
scrapy -h -
查看帮助信息:
scapy --help -
查看版本信息:
(venv)ql@ql:~$ scrapy version Scrapy 1.1.2 (venv)ql@ql:~$ (venv)ql@ql:~$ scrapy version -v Scrapy : 1.1.2 lxml : 3.6.4.0 libxml2 : 2.9.4 Twisted : 16.4.0 Python : 2.7.12 (default, Jul 1 2016, 15:12:24) - [GCC 5.4.0 20160609] pyOpenSSL : 16.1.0 (OpenSSL 1.0.2g-fips 1 Mar 2016) Platform : Linux-4.4.0-36-generic-x86_64-with-Ubuntu-16.04-xenial (venv)ql@ql:~$ -
新建一个工程
scrapy startproject spider_name
-
构建爬虫genspider(generator spider)
-
一个工程中可以存在多个spider, 但是名字必须唯一
scrapy genspider name domain #如: #scrapy genspider sohu sohu.org -
查看当前项目内有多少爬虫
scrapy list -
view使用浏览器打开网页
scrapy view http://www.baidu.com
shell命令, 进入scrpay交互环境
# 进入该url的交互环境
scrapy shell http://www.dmoz.org/Computers/Programming/Languages/Python/Books/
-
之后便进入交互环境,我们主要使用这里面的response命令, 例如可以使用
response.xpath() #括号里直接加xpath路径 -
runspider命令用于直接运行创建的爬虫, 并不会运行整个项目
scrapy runspider 爬虫名称
2.2 Scrapy框架的使用:
- 接下来通过一个简单的项目,完成一遍Scrapy抓取流程。
- 具体流程如下:
- 创建一个scrapy项目:
- 创键一个Spider来抓取站点和处理数据。
- 到过命令行将抓取的抓取内容导出
① 创建项目
- 爬取我爱我家的楼盘信息:
- 网址: https://fang.5i5j.com/bj/loupan/
- 在命令行编写下面命令,创建项目demo
scrapy startproject demo
- 项目目录结构:
demo
├── demo
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py # Items的定义,定义抓取的数据结构
│ ├── middlewares.py # 定义Spider和DownLoader的Middlewares中间件实现。
│ ├── pipelines.py # 它定义Item Pipeline的实现,即定义数据管道
│ ├── settings.py # 它定义项目的全局配置
│ └── spiders # 其中包含一个个Spider的实现,每个Spider都有一个文件
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg #Scrapy部署时的配置文件,定义了配置文件路径、部署相关信息等内容
② 进入demo项目目录,创建爬虫spider类文件
- 执行genspider命令,第一个参数是Spider的名称,第二个参数是网站域名。
scrapy genspider fang fang.5i5j.com
$ tree
├── demo
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ └── settings.cpython-36.pyc
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ ├── __pycache__
│ │ └── __init__.cpython-36.pyc
│ └── fang.py #在spiders目录下有了一个爬虫类文件fang.py
└── scrapy.cfg
# fang.py的文件代码如下:
# -*- coding: utf-8 -*-
import scrapy
class FangSpider(scrapy.Spider):
name = 'fang'
allowed_domains = ['fang.5i5j.com']
start_urls = ['http://fang.5i5j.com/']
def parse(self, response):
pass
- Spider是自己定义的类,Scrapy用它来从网页中抓取内容,并解析抓取结果。
- 此类继承Scrapy提供的Spider类scrapy.Spider,类中有三个属性:name、allowed_domains、start_urls和方法parse。
- name:是每个项目唯一名字,用于区分不同Spider。
- allowed_domains: 它是允许爬取的域名,如果初始或后续的请求链接不是这个域名,则请求链接会被过滤掉
- start_urls: 它包含了Spider在启动时爬取的URL列表,初始请求是由它来定义的。
- parse方法: 调用start_urls链接请求下载执行后则调用parse方法,并将结果传入此方法。
③ 创建Item
- Item是保存爬取数据的容器,它的使用方法和字典类型,但相比字典多了些保护机制。
- 创建Item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段:(标题、地址、开盘时间、浏览次数、单价)
- 具体代码如下:
import scrapy
class FangItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
address = scrapy.Field()
time = scrapy.Field()
clicks = scrapy.Field()
price = scrapy.Field()
#pass
④ 解析Response
- 在fang.py文件中,parse()方法的参数response是start_urls里面的链接爬取后的结果。
- 提取的方式可以是CSS选择器、XPath选择器或者是re正则表达式。
# -*- coding: utf-8 -*-
import scrapy
from demo.items import FangItem
class FangSpider(scrapy.Spider):
name = 'fang'
allowed_domains = ['fang.5i5j.com']
#start_urls = ['http://fang.5i5j.com/']
start_urls = ['https://fang.5i5j.com/bj/loupan/']
def parse(self, response):
hlist = response.css("div.houseList_list")
for vo in hlist:
item = FangItem()
item['title'] = vo.css("h3.fontS20 a::text").extract_first()
item['address'] = vo.css("span.addressName::text").extract_first()
item['time'] = vo.re("(.*?)开盘")[0]
item['clicks'] = vo.re("([0-9]+)浏览")[0]
item['price'] = vo.css("i.fontS24::text").extract_first()
#print(item)
yield item
⑤ 使用Item Pipeline
- Item Pipeline为项目管道,当Item生产后,他会自动被送到Item Pipeline进行处理:
- 我们常用Item Pipeline来做如下操作:
- 清理HTML数据
- 验证抓取数据,检查抓取字段
- 查重并丢弃重复内容
- 将爬取结果保存到数据库里。
class DemoPipeline(object):
def process_item(self, item, spider):
print(item)
return item
- 进入配置settings中开启Item Pipelines的使用
⑥ 运行:
-
执行如下命令来启用数据爬取
scrapy crawl fang -
将结果保存到文件中: 格式:json、csv、xml、pickle、marshal等
scrapy crawl fang -o fangs.json
scrapy crawl fang -o fangs.csv
scrapy crawl fang -o fangs.xml
scrapy crawl fang -o fangs.pickle
scrapy crawl fang -o fangs.marshal
2.3 Scrapy框架中的POST提交:
- 在Scrapy框架中默认都是GET的提交方式,但是我们可以使用
FormRequest来完成POST提交,并可以携带参数。 - 如下案例为有道词典的翻译信息爬取案例,网址:
http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule - 首先创建一个
youdao有道的爬虫文件:
scrapy genspider youdao fanyi.youdao.com
- 编写爬虫文件,注意返回的是json格式,具体代码如下:
# -*- coding: utf-8 -*-
import scrapy,json
class YoudaoSpider(scrapy.Spider):
name = 'youdao'
allowed_domains = ['fanyi.youdao.com']
#start_urls = ['http://fanyi.youdao.com']
def start_requests(self):
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
keyword = input("请输入要翻译的单词:")
data = {
'i':keyword,'doctype': 'json',}
# FormRequest 是Scrapy发送POST请求的方法
yield scrapy.FormRequest(
url = url,
formdata = data,
callback = self.parse
)
def parse(self, response):
res = json.loads(response.body)
print(res['translateResult'][0][0]['tgt'])
input("按任意键继续")
3. Selector选择器
- 对用爬取信息的解析,我们在之前已经介绍了正则re、Xpath、Beautiful Soup和PyQuery。
- 而Scrapy还给我们提供自己的数据解析方法,即Selector(选择器)。
- Selector(选择器)是基于lxml来构建的,支持XPath、CSS选择器以及正则表达式,功能全面,解析速度和准确度非常高。
3.1 直接使用:
- Selector(选择器)是一个可以独立使用模块。 直接导入模块,就可以实例化使用,如下所示:
from scrapy import Selector
content="My html Hello Word!
"
selector = Selector(text=content)
print(selector.xpath('/html/head/title/text()').extract_first())
print(selector.css('h3::text').extract_first())
3.2 Scrapy shell
- 我们借助于Scrapy shell来模拟请求的过程,然后把一些可操作的变量传递给我们,如request、response等。
zhangtaodeMacBook-Pro:scrapydemo zhangtao$ scrapy shell http://www.baidu.com
2018-05-08 14:46:29 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: scrapybot)
2018-05-08 14:46:29 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.6.4 (default, Jan 6 2018, 11:49:38) - [GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.42.1)], pyOpenSSL 17.5.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Darwin-15.6.0-x86_64-i386-64bit
2018-05-08 14:46:29 [scrapy.crawler] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0}
2018-05-08 14:46:29 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage']
2018-05-08 14:46:29 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-05-08 14:46:29 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-05-08 14:46:29 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-05-08 14:46:29 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-05-08 14:46:29 [scrapy.core.engine] INFO: Spider opened
2018-05-08 14:46:29 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler
[s] item {}
[s] request
[s] response <200 http://www.baidu.com>
[s] settings
[s] spider
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>> response.url
'http://www.baidu.com'
>>> response.status
200
>>> response.xpath('/html/head/title/text()').extract_first()
'百度一下,你就知道'
>>> response.xpath('//a/text()').extract_first()
'新闻'
>>> response.xpath('//a/text()').extract()
['新闻', 'hao123', '地图', '视频', '贴吧', '登录', '更多产品', '关于百度', 'About Baidu', '使用百度前必读', '意见反馈']
>>> response.xpath('//a/@href').extract()
['http://news.baidu.com', 'http://www.hao123.com', 'http://map.baidu.com', 'http://v.baidu.com', 'http://tieba.baidu.com', 'http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1', '//www.baidu.com/more/', 'http://home.baidu.com', 'http://ir.baidu.com', 'http://www.baidu.com/duty/', 'http://jianyi.baidu.com/']
3.3 Xpath选择器:
- response.selector属性返回内容相当于response的body构造了一个Selector对象。
- Selector对象可以调用xpath()方法实现信息的解析提取。
- 在xpath()后使用extract()可以返回所有的元素结果。
- 若xpath()有问题,那么extract()会返回一个空列表。
- 在xpath()后使用extract_first()可以返回第一个元素结果。
- 使用scrapy shell 爬取"淘宝网"->“商品分类”->"特色市场"的信息。
$ scrapy shell https://www.taobao.com/tbhome/page/special-markets
... ...
>>> response.url
'https://www.taobao.com/tbhome/page/special-markets'
>>> response.status
200
>>> response.selector.xpath("//dt/text()")
[, ,
, ]
>>> response.selector.xpath("//dt/text()").extract()
['时尚爆料王', '品质生活家', '特色玩味控', '实惠专业户']
>>> dllist = response.selector.xpath("//dl[@class='market-list']")
>>> for v in dllist:
... print(v.xpath("./dt/text()").extract_first())
...
时尚爆料王
品质生活家
特色玩味控
实惠专业户
>>> for v in dllist:
... print(v.xpath("./dt/text()").extract_first())
... print("="*50)
... alist = v.xpath(".//a")
... for a in alist:
... print(a.xpath("./@href").extract_first(),end=":")
... print(a.xpath("./span/img/@alt").extract_first())
...
时尚爆料王
==================================================
https://if.taobao.com/:潮流从这里开始
https://guang.taobao.com/:外貌协会の逛街指南
https://mei.taobao.com/:妆 出你的腔调
https://g.taobao.com/:探索全球美好生活
//star.taobao.com/:全球明星在这里
https://mm.taobao.com/:美女红人集中地
https://www.taobao.com/markets/designer/stylish:全球创意设计师平台
品质生活家
==================================================
https://chi.taobao.com/chi/:食尚全球 地道中国
//q.taobao.com:懂得好生活
https://www.jiyoujia.com/:过我想要的生活
https://www.taobao.com/markets/sph/sph/sy:尖货奢品品味选择
https://www.taobao.com/markets/qbb/index:享受育儿生活新方式
//car.taobao.com/:买车省钱,用车省心
//sport.taobao.com/:爱上运动每一天
//zj.taobao.com:匠心所在 物有所值
//wt.taobao.com/:畅享优质通信生活
https://www.alitrip.com/:比梦想走更远
特色玩味控
==================================================
https://china.taobao.com:地道才够味!
https://www.taobao.com/markets/3c/tbdc:为你开启潮流新生活
https://acg.taobao.com/:ACGN 好玩好看
https://izhongchou.taobao.com/index.htm:认真对待每一个梦想。
//enjoy.taobao.com/:园艺宠物爱好者集中营
https://sf.taobao.com/:法院处置资产,0佣金捡漏
https://zc-paimai.taobao.com/:超值资产,投资首选
https://paimai.taobao.com/:想淘宝上拍卖
//xue.taobao.com/:给你未来的学习体验
//2.taobao.com:让你的闲置游起来
https://ny.taobao.com/:价格实惠品类齐全
实惠专业户
==================================================
//tejia.taobao.com/:优质好货 特价专区
https://qing.taobao.com/:品牌尾货365天最低价
https://ju.taobao.com/jusp/other/mingpin/tp.htm:奢侈品团购第一站
https://ju.taobao.com/jusp/other/juliangfan/tp.htm?spm=608.5847457.102202.5.jO4uZI:重新定义家庭生活方式
https://qiang.taobao.com/:抢到就是赚到!
https://ju.taobao.com/jusp/nv/fcdppc/tp.htm:大牌正品 底价特惠
https://ju.taobao.com/jusp/shh/life/tp.htm?:惠聚身边精选好货
https://ju.taobao.com/jusp/sp/global/tp.htm?spm=0.0.0.0.biIDGB:10点上新 全球底价
https://try.taobao.com/index.htm:总有新奇等你发现
3.4 CSS选择器:
- 同xpath()一样。
- 使用scrapy shell 爬取"淘宝网"->“商品分类”->"主题市场"的信息。
>>> response.url
'https://www.taobao.com/tbhome/page/market-list'
>>> response.status
200
>>> response.css("a.category-name-level1::text").extract()
['女装男装', '鞋类箱包', '母婴用品', '护肤彩妆', '汇吃美食', '珠宝配饰', '家装建材', '家居家纺', '百货市场', '汽车·用品', '手机数码', '家电办公', '更多服务', '生活服务', '运动户外', '花鸟文娱', '农资采购']
#获取淘宝页面中所有分类信息
>>> dlist = response.css("div.home-category-list")
>>> for dd in dlist:
print(dd.css("a.category-name-level1::text").extract_first())
print("="*50)
alist = dd.css("li.category-list-item")
for v in alist:
print(v.xpath("./a/text()").extract_first())
print("-"*50)
talist = v.css("div.category-items a")
for a in talist:
print(a.css("::text").extract_first(),end=" ")
print()
>>>女装男装
==================================================
潮流女装
--------------------------------------------------
羽绒服 毛呢大衣 毛衣 冬季外套 新品 裤子 连衣裙 腔调
时尚男装
--------------------------------------------------
秋冬新品 淘特莱斯 淘先生 拾货 秋冬外套 时尚套装 潮牌 爸爸装
性感内衣
--------------------------------------------------
春新品 性感诱惑 甜美清新 简约优雅 奢华高贵 运动风 塑身 基础内衣
...
注:css中获取属性:a.css("::attr(href)").extract_first()
3.5 正则匹配:
>>> response.xpath("//head").re("(.*?) ")
['淘宝首页行业市场']
>>> response.selector.re("(.*?)")
4. Spider的使用
- 在Scrapy中,要抓取网站的链接配置、抓取逻辑、解析逻辑里其实都是在Spider中配置的。
- Spider要做的事就是有两件:
定义抓取网站的动作和分析爬取下来的网页。
4.1 Spider运行流程:
- 整个抓取循环过程如下所述:
- 以初始的URL初始化Request,并设置回调函数。请求成功时Response生成并作为参数传给该回调函数。
- 在回调函数内分析返回的网页内容。返回结果两种形式,一种为字典或Item数据对象;另一种是解析到下一个链接。
- 如果返回的是字典或Item对象,我们可以将结果存入文件,也可以使用Pipeline处理并保存。
- 如果返回Request,Response会被传递给Request中定义的回调函数参数,即再次使用选择器来分析生成数据Item。
4.2 Spider类分析:
- Spider类源代码:打开文件
Python36/Lib/site-packages/scrapy/spiders/__init__.py
import logging
import warnings
from scrapy import signals
from scrapy.http import Request
from scrapy.utils.trackref import object_ref
from scrapy.utils.url import url_is_from_spider
from scrapy.utils.deprecate import create_deprecated_class
from scrapy.exceptions import ScrapyDeprecationWarning
from scrapy.utils.deprecate import method_is_overridden
#所有爬虫的基类,自定义的爬虫必须从继承此类
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 douban.com ,该spider通常会被命名为 douban
name = None
custom_settings = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
@property
def logger(self):
logger = logging.getLogger(self.name)
return logging.LoggerAdapter(logger, {
'spider': self})
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = cls(*args, **kwargs)
spider._set_crawler(crawler)
return spider
#判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._set_crawler(crawler)
def _set_crawler(self, crawler):
self.crawler = crawler
self.settings = crawler.settings
crawler.signals.connect(self.close, signals.spider_closed)
#@property
#def crawler(self):
# assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
# return self._crawler
#@property
#def settings(self):
# return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
@staticmethod
def close(spider, reason):
closed = getattr(spider, 'closed', None)
if callable(closed):
return closed(reason)
def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
-
Spider类继承自scrapy.spiders.Spider. -
Spider类这个提供了start_requests()方法的默认实现,读取并请求start_urls属性,并调用parse()方法解析结果。 -
Spider类的属性和方法:
name:爬虫名称,必须唯一的,可以生成多个相同的Spider实例,数量没有限制。allowed_domains: 允许爬取的域名,是可选配置,不在此范围的链接不会被跟进爬取。start_urls: 它是起始URL列表,当我们没有实现start_requests()方法时,默认会从这个列表开始抓取。custom_settings: 它是一个字典,专属于Spider的配置,此设置会覆盖项目全局的设置,必须定义成类变量。crawler:它是由from_crawler()方法设置的,Crawler对象包含了很多项目组件,可以获取settings等配置信息。settings: 利用它我们可以直接获取项目的全局设置变量。start_requests(): 使用start_urls里面的URL来构造Request,而且Request是GET请求方法。parse(): 当Response没有指定回调函数时,该方法会默认被调用。closed(): 当Spider关闭时,该方法会调用。
4.3 实战案例:
- 任务:使用scrapy爬取关键字为
python信息的百度文库搜索信息(每页10条信息) - url地址分析:
https://wenku.baidu.com/search?word=python&pn=0第一页 - url地址分析:
https://wenku.baidu.com/search?word=python&pn=10第二页 - 具体实现:
- ① 使用scrapy命令创建爬虫项目dbwenku
$ scrapy startproject bdwenku
- ② 创建spider爬虫文件wenku:
$ cd bdwenku
$ scrapy genspider wenku wenku.baidu.com
- ③ 编辑
wenku.py爬虫文件,代码如下:
# -*- coding: utf-8 -*-
import scrapy
class WenkuSpider(scrapy.Spider):
name = 'wenku'
allowed_domains = ['wenku.baidu.com']
start_urls = ['https://wenku.baidu.com/search?word=python&pn=0']
def parse(self, response):
print("Hello Scrapy")
print(response)
- ④ 运行测试:
$ scrapy crawl wenku
- 爬取数据出现错误:
DEBUG: Forbidden by robots.txt:请求被拒绝了 - 也就是百度文库的robots.txt设置了禁止外部爬取信息。
- 解决办法:在settings.py配置文件中,将ROBOTSTXT_OBEY的值设为False,忽略robot协议,继续爬取。
...
2018-05-11 11:00:54 [scrapy.core.engine] INFO: Spider opened
2018-05-11 11:00:54 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-05-11 11:00:54 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6027
2018-05-11 11:00:56 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2018-05-11 11:00:56 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt:
2018-05-11 11:00:56 [scrapy.core.engine] INFO: Closing spider (finished)
2018-05-11 11:00:56 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/exception_count': 1,
'downloader/exception_type_count/scrapy.exceptions.IgnoreRequest': 1,
...
- ⑤ Spider爬虫文件:
wenku.py的几种写法:
# 单请求的信息爬取
# -*- coding: utf-8 -*-
import scrapy
class WenkuSpider(scrapy.Spider):
name = 'wenku'
allowed_domains = ['wenku.baidu.com']
start_urls = ['https://wenku.baidu.com/search?word=python&pn=0']
def parse(self, response):
dllist = response.selector.xpath("//dl")
#print(len(dllist))
for dd in dllist:
print(dd.xpath("./dt/p/a/@title").extract_first())
# 多个请求的信息爬取
# -*- coding: utf-8 -*-
import scrapy
class WenkuSpider(scrapy.Spider):
name = 'wenku'
allowed_domains = ['wenku.baidu.com']
start_urls = ['https://wenku.baidu.com/search?word=python&pn=0','https://wenku.baidu.com/search?word=python&pn=10','https://wenku.baidu.com/search?word=python&pn=20']
def parse(self, response):
dllist = response.selector.xpath("//dl")
#print(len(dllist))
for dd in dllist:
print(dd.xpath("./dt/p/a/@title").extract_first())
print("="*70) #输出一条每个请求后分割线
# 实现一个爬取循环,获取10页信息
# -*- coding: utf-8 -*-
import scrapy
class WenkuSpider(scrapy.Spider):
name = 'wenku'
allowed_domains = ['wenku.baidu.com']
start_urls = ['https://wenku.baidu.com/search?word=python&pn=0']
p=0
def parse(self, response):
dllist = response.selector.xpath("//dl")
#print(len(dllist))
for dd in dllist:
print(dd.xpath("./dt/p/a/@title").extract_first())
print("="*70)
self.p += 1
if self.p < 10:
next_url = 'https://wenku.baidu.com/search?word=python&pn='+str(self.p*10)
url = response.urljoin(next_url) #构建绝对url地址(这里可省略)
yield scrapy.Request(url=url,callback=self.parse)
python
python教程
PYTHON测试题
简明_Python_教程
如何自学 Python(干货合集)
python
python
Python介绍(Introduction to Python)
Python编程入门(适合于零基础朋友)
Python教程
======================================================================
python
十分钟学会Python
Python 基础语法(一)
python基础分享
Python入门
python新手教程
python资源中文大全
python_笔记
Python与中文处理
python
======================================================================
python
python教程
PYTHON测试题
简明_Python_教程
如何自学 Python(干货合集)
python
python
Python介绍(Introduction to Python)
Python编程入门(适合于零基础朋友)
Python教程
======================================================================
5. Downloader Middleware的使用
- 在Downloader Middleware的功能十分强大:可以修改User-Agent、处理重定向、设置代理、失败重试、设置Cookies等。
- Downloader Middleware在整个架构中起作用的位置是以下两个。
- 在Scheduler调度出队列的Request发送给Doanloader下载之前,也就是我们可以在Request执行下载前对其进行修改。
- 在下载后生成的Response发送给Spider之前,也就是我们可以生成Resposne被Spider解析之前对其进行修改。
5.1 使用说明:
- 在Scrapy中已经提供了许多Downloader Middleware,如:负责失败重试、自动重定向等中间件:
- 它们都被定义到DOWNLOADER_MIDDLEWARES_BASE变量中。
# 在python3.6/site-packages/scrapy/settings/default_settings.py默认配置中
DOWNLOADER_MIDDLEWARES_BASE = {
# Engine side
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
# Downloader side
}
- 字典格式,其中数字为优先级,越小的优先调用。
5.2 自定义Downloader Middleware中间件
- 我们可以通过项目的DOWNLOADER_MIDDLEWARES变量设置来添加自己定义的Downloader Middleware。
- 其中Downloader Middleware有三个核心方法:
- process_request(request,spider)
- process_response(request,response,spider)
- process_exception(request,exception,spider)
① process_request(request,spider)
- 当每个request通过下载中间件时,该方法被调用,这里有一个要求,该方法必须返回以下三种中的任意一种:
None,返回一个Response对象、返回一个Request对象或raise IgnoreRequest。三种返回值的作用是不同的。 None:Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用,该request被执行(其response被下载)。Response对象:Scrapy将不会调用任何其他的process_request()或process_exception() 方法,或相应地下载函数;其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。Request对象:Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。raise一个IgnoreRequest异常:则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常,则该异常被忽略且不记录。
② process_response(request, response, spider)
- process_response的返回值也是有三种:
response对象,request对象,或者raise一个IgnoreRequest异常 - 如果其返回一个Response(可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
- 如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
- 如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。
- 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
- 这里我们写一个简单的例子还是上面的项目,我们在中间件中继续添加如下代码:
...
def process_response(self, request, response, spider):
response.status = 201
return response
...
③ process_exception(request, exception, spider)
- 当下载处理器(download handler)或 process_request() (下载中间件)抛出异常(包括 IgnoreRequest 异常)时,Scrapy调用 process_exception()。
- process_exception() 也是返回三者中的一个: 返回 None 、 一个 Response 对象、或者一个 Request 对象。
- 如果其返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
- 如果其返回一个 Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
5.3 实战案例:
- 任务测试:使用scrapy爬取豆瓣图书Top250信息
- 网址:https://book.douban.com/top250?start=0
- 使用shell命令直接爬取报403错误
# 在命令行下直接运行scrapy shell命令爬取信息,报403错误
$ scrapy shell https://book.douban.com/top250
>>> response.status
>>> 403
- ① 新建一个项目douban,命令如下所示:
scrapy startproject douban
- ② 新建一个Spider类,名字为dbbook,命令如下所示:
cd douban
scrapy genspider dbbook book.douban.com
- 编写爬虫代码。如下:
# -*- coding: utf-8 -*-
import scrapy
class DbbookSpider(scrapy.Spider):
name = 'dbbook'
allowed_domains = ['book.douban.com']
start_urls = ['https://book.douban.com/top250?start=0']
def parse(self, response):
#print("状态:")
pass
- ③ 执行爬虫命令,排除错误。
$ scrapy crawl dbbook #结果返回403错误(服务器端拒绝访问)。
原因分析:默认scrapy框架请求信息中的User-Agent的值为:Scrapy/1.5.0(http://scrapy.org).
解决方案:我们可以在settings.py配置文件中:设置 USER_AGENT 或者DEFAULT_REQUEST_HEADERS信息:
USER_AGENT = 'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11'
或者
...
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
}
...
- ④ 开启Downloader Middleware中间件
- 在项目的settings.py配置文件中:开启设置
DOWNLOADER_MIDDLEWARES信息:
DOWNLOADER_MIDDLEWARES = {
'douban.middlewares.DoubanDownloaderMiddleware': 543,
}
def process_request(self, request, spider):
#输出header头信息
print(request.headers)
#伪装浏览器用户
request.headers['user-agent']='Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
return None
6. Spider Middleware的使用
- Spider中间件是介入到Scrapy的spider处理机制的钩子框架,您可以添加代码来处理发送给 Spiders 的response及spider产生的item和request。
6.1 激活spider中间件
- 要启用spider中间件,您可以将其加入到 SPIDER_MIDDLEWARES 设置中。 该设置是一个字典,键位中间件的路径,值为中间件的顺序(order)。
- 样例:
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
}
- SPIDER_MIDDLEWARES 设置会与Scrapy定义的 SPIDER_MIDDLEWARES_BASE 设置合并(但不是覆盖), 而后根据顺序(order)进行排序,最后得到启用中间件的有序列表: 第一个中间件是最靠近引擎的,最后一个中间件是最靠近spider的。
- 关于如何分配中间件的顺序请查看 SPIDER_MIDDLEWARES_BASE 设置,而后根据您想要放置中间件的位置选择一个值。 由于每个中间件执行不同的动作,您的中间件可能会依赖于之前(或者之后)执行的中间件,因此顺序是很重要的。
- 如果您想禁止内置的(在 SPIDER_MIDDLEWARES_BASE 中设置并默认启用的)中间件, 您必须在项目的 SPIDER_MIDDLEWARES 设置中定义该中间件,并将其值赋为 None 。 例如,如果您想要关闭off-site中间件:
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': None,
}
- 最后,请注意,有些中间件需要通过特定的设置来启用。更多内容请查看相关中间件文档。
6.2 编写您自己的spider中间件
- 编写spider中间件十分简单。每个中间件组件是一个定义了以下一个或多个方法的Python类:
- 来自类:class scrapy.contrib.spidermiddleware.SpiderMiddleware
process_spider_input(response, spider)
当response通过spider中间件时,该方法被调用,处理该response。
`process_spider_input()` 应该返回 None 或者抛出一个异常。
如果其返回 None ,Scrapy将会继续处理该response,调用所有其他的中间件直到spider处理该response。
如果其跑出一个异常(exception),Scrapy将不会调用任何其他中间件的 process_spider_input() 方法,并调用request的errback。 errback的输出将会以另一个方向被重新输入到中间件链中,使用 process_spider_output() 方法来处理,当其抛出异常时则带调用 process_spider_exception() 。
参数:
response (Response 对象) – 被处理的response
spider (Spider 对象) – 该response对应的spider
process_spider_output(response, result, spider)
当Spider处理response返回result时,该方法被调用。
`process_spider_output()` 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)。
参数:
response (Response 对象) – 生成该输出的response
result (包含 Request 或 Item 对象的可迭代对象(iterable)) – spider返回的result
spider (Spider 对象) – 其结果被处理的spider
process_spider_exception(response, exception, spider)
当spider或(其他spider中间件的) process_spider_input() 跑出异常时, 该方法被调用。
`process_spider_exception()` 必须要么返回 None , 要么返回一个包含 Response 或 Item 对象的可迭代对象(iterable)。
如果其返回 None ,Scrapy将继续处理该异常,调用中间件链中的其他中间件的 process_spider_exception() 方法,直到所有中间件都被调用,该异常到达引擎(异常将被记录并被忽略)。
如果其返回一个可迭代对象,则中间件链的 process_spider_output() 方法被调用, 其他的 process_spider_exception() 将不会被调用。
参数:
response (Response 对象) – 异常被抛出时被处理的response
exception (Exception 对象) – 被跑出的异常
spider (Spider 对象) – 抛出该异常的spider
process_start_requests(start_requests, spider)
0.15 新版功能.
该方法以spider 启动的request为参数被调用,执行的过程类似于 process_spider_output() ,只不过其没有相关联的response并且必须返回request(不是item)。
其接受一个可迭代的对象(start_requests 参数)且必须返回另一个包含 Request 对象的可迭代对象。
注解
当在您的spider中间件实现该方法时, 您必须返回一个可迭代对象(类似于参数start_requests)且不要遍历所有的 start_requests。 该迭代器会很大(甚至是无限),进而导致内存溢出。 Scrapy引擎在其具有能力处理start request时将会拉起request, 因此start request迭代器会变得无限,而由其他参数来停止spider( 例如时间限制或者item/page记数)。
参数:
start_requests (包含 Request 的可迭代对象) – start requests
spider (Spider 对象) – start requests所属的spider
Scrapy框架的配置Settings
- Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。
- 参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/settings.html#topics-settings-ref
内置设置参考手册
-
BOT_NAME- 默认: ‘scrapybot’
- 当您使用 startproject 命令创建项目时其也被自动赋值。
-
CONCURRENT_ITEMS- 默认: 100
- Item Processor(即 Item Pipeline) 同时处理(每个response的)item的最大值。
-
CONCURRENT_REQUESTS- 默认: 16
- Scrapy downloader 并发请求(concurrent requests)的最大值。
-
DEFAULT_REQUEST_HEADERS-
默认: 如下
{ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } -
Scrapy HTTP Request使用的默认header。
-
-
DEPTH_LIMIT- 默认: 0
- 爬取网站最大允许的深度(depth)值。如果为0,则没有限制。
-
DOWNLOAD_DELAY- 默认: 0
- 下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压力。同时也支持小数:
-
DOWNLOAD_DELAY = 0.25 # 250 ms of delay- 默认情况下,Scrapy在两个请求间不等待一个固定的值, 而是使用0.5到1.5之间的一个随机值 * DOWNLOAD_DELAY 的结果作为等待间隔。
-
DOWNLOAD_TIMEOUT- 默认: 180
- 下载器超时时间(单位: 秒)。
-
ITEM_PIPELINES-
默认: {}
-
保存项目中启用的pipeline及其顺序的字典。该字典默认为空,值(value)任意,不过值(value)习惯设置在0-1000范围内,值越小优先级越高。
ITEM_PIPELINES = { 'mySpider.pipelines.SomethingPipeline': 300, 'mySpider.pipelines.ItcastJsonPipeline': 800, }
-
-
LOG_ENABLED- 默认: True
- 是否启用logging。
-
LOG_ENCODING- 默认: ‘utf-8’
- logging使用的编码。
-
LOG_LEVEL- 默认: ‘DEBUG’
- log的最低级别。可选的级别有: CRITICAL、 ERROR、WARNING、INFO、DEBUG 。
-
USER_AGENT- 默认: “Scrapy/VERSION (+http://scrapy.org)”
- 爬取的默认User-Agent,除非被覆盖。
-
PROXIES:代理设置-
示例:
PROXIES = [ {'ip_port': '111.11.228.75:80', 'password': ''}, {'ip_port': '120.198.243.22:80', 'password': ''}, {'ip_port': '111.8.60.9:8123', 'password': ''}, {'ip_port': '101.71.27.120:80', 'password': ''}, {'ip_port': '122.96.59.104:80', 'password': ''}, {'ip_port': '122.224.249.122:8088', 'password':''}, ]
-
-
COOKIES_ENABLED = False- 禁用Cookies
7. ItemPipeline的使用
- 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
- 每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
- 以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
7.1 如何编写你自己的item pipeline
- 编写你自己的item pipeline很简单,每个item pipiline组件是一个独立的Python类,同时必须实现以下方法:
① process_item(item, spider)
- 每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的item将不会被之后的pipeline组件所处理。
- 参数:
- item (Item 对象) – 被爬取的item
- spider (Spider 对象) – 爬取该item的spider
- 此外,他们也可以实现以下方法:
② open_spider(spider)
- 当spider被开启时,这个方法被调用。
- 参数: spider (Spider 对象) – 被开启的spider
③ close_spider(spider)
- 当spider被关闭时,这个方法被调用
- 参数: spider (Spider 对象) – 被关闭的spider
7.2 样例:
验证价格,同时丢弃没有价格的item
- 让我们来看一下以下这个假设的pipeline,它为那些不含税(price_excludes_vat 属性)的item调整了 price 属性,同时丢弃了那些没有价格的item:
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
将item写入JSON文件:
- 以下pipeline将所有(从所有spider中)爬取到的item,存储到一个独立地 items.jl 文件,每行包含一个序列化为JSON格式的item:
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
- 注解:JsonWriterPipeline的目的只是为了介绍怎样编写item pipeline,如果你想要将所有爬取的item都保存到同一个JSON文件, 你需要使用 Feed exports 。
去重
- 一个用于去重的过滤器,丢弃那些已经被处理过的item。让我们假设我们的item有一个唯一的id,但是我们spider返回的多个item中包含有相同的id:
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个Item Pipeline组件:
- 为了启用一个Item Pipeline组件,你必须将它的类添加到 ITEM_PIPELINES 配置,就像下面这个例子:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
- 分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
7.3 Scrapy框架案例实战:
- 任务:爬取csdn学院中的课程信息(编程语言的)
- 网址:
https://edu.csdn.net/courses/o280/p1(第一页) https://edu.csdn.net/courses/o280/p2(第二页)
① 创建项目
- 在命令行编写下面命令,创建项目demo
scrapy startproject educsdn
- 项目目录结构:
educsdn
├── educsdn
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py # Items的定义,定义抓取的数据结构
│ ├── middlewares.py # 定义Spider和DownLoader的Middlewares中间件实现。
│ ├── pipelines.py # 它定义Item Pipeline的实现,即定义数据管道
│ ├── settings.py # 它定义项目的全局配置
│ └── spiders # 其中包含一个个Spider的实现,每个Spider都有一个文件
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg #Scrapy部署时的配置文件,定义了配置文件路径、部署相关信息等内容
② 进入educsdn项目目录,创建爬虫spider类文件(courses课程)
- 执行genspider命令,第一个参数是Spider的名称,第二个参数是网站域名。
scrapy genspider courses edu.csdn.net
$ tree
├── demo
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ └── settings.cpython-36.pyc
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ ├── __pycache__
│ │ └── __init__.cpython-36.pyc
│ └── courses.py #在spiders目录下有了一个爬虫类文件courses.py
└── scrapy.cfg
# courses.py的文件代码如下:
# -*- coding: utf-8 -*-
import scrapy
class CoursesSpider(scrapy.Spider):
name = 'courses'
allowed_domains = ['edu.csdn.net']
start_urls = ['http://edu.csdn.net/']
def parse(self, response):
pass
③ 创建Item
- Item是保存爬取数据的容器,它的使用方法和字典类型,但相比字典多了些保护机制。
- 创建Item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段:(课程标题、课程地址、图片、授课老师,视频时长、价格)
- 具体代码如下:(修改类名为CoursesItem)
import scrapy
class CoursesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
pic = scrapy.Field()
teacher = scrapy.Field()
time = scrapy.Field()
price = scrapy.Field()
#pass
④ 解析Response
- 在fang.py文件中,parse()方法的参数response是start_urls里面的链接爬取后的结果。
- 提取的方式可以是CSS选择器、XPath选择器或者是re正则表达式。
# -*- coding: utf-8 -*-
import scrapy
from educsdn.items import CoursesItem
class CoursesSpider(scrapy.Spider):
name = 'courses'
allowed_domains = ['edu.csdn.net']
start_urls = ['https://edu.csdn.net/courses/o280/p1']
p=1
def parse(self, response):
#解析并输出课程标题
#print(response.selector.css("div.course_dl_list span.title::text").extract())
#获取所有课程
dlist = response.selector.css("div.course_dl_list")
#遍历课程,并解析信息后封装到item容器中
for dd in dlist:
item = CoursesItem()
item['title'] = dd.css("span.title::text").extract_first()
item['url'] = dd.css("a::attr(href)").extract_first()
item['pic'] = dd.css("img::attr(src)").extract_first()
item['teacher'] = dd.re_first("讲师:(.*?)
")
item['time'] = dd.re_first("([0-9]+)课时")
item['price'] = dd.re_first("¥([0-9\.]+)")
#print(item)
#print("="*70)
yield item
#获取前10页的课程信息
self.p += 1
if self.p <= 10:
next_url = 'https://edu.csdn.net/courses/o280/p'+str(self.p)
url = response.urljoin(next_url) #构建绝对url地址(这里可省略)
yield scrapy.Request(url=url,callback=self.parse)
⑤、创建数据库和表:
- 在mysql中创建数据库
csdndb和数据表courses
CREATE TABLE `courses` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL,
`url` varchar(255) DEFAULT NULL,
`pic` varchar(255) DEFAULT NULL,
`teacher` varchar(32) DEFAULT NULL,
`time` varchar(16) DEFAULT NULL,
`price` varchar(16) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
⑥、使用Item Pipeline
- Item Pipeline为项目管道,当Item生产后,他会自动被送到Item Pipeline进行处理:
- 我们常用Item Pipeline来做如下操作:
- 清理HTML数据
- 验证抓取数据,检查抓取字段
- 查重并丢弃重复内容
- 将爬取结果保存到数据库里。
import pymysql
from scrapy.exceptions import DropItem
class EducsdnPipeline(object):
def process_item(self, item, spider):
if item['price'] == None:
raise DropItem("Drop item found: %s" % item)
else:
return item
class MysqlPipeline(object):
def __init__(self,host,database,user,password,port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
self.db=None
self.cursor=None
@classmethod
def from_crawler(cls,crawler):
return cls(
host = crawler.settings.get("MYSQL_HOST"),
database = crawler.settings.get("MYSQL_DATABASE"),
user = crawler.settings.get("MYSQL_USER"),
password = crawler.settings.get("MYSQL_PASS"),
port = crawler.settings.get("MYSQL_PORT")
)
def open_spider(self,spider):
self.db = pymysql.connect(self.host,self.user,self.password,self.database,charset='utf8',port=self.port)
self.cursor = self.db.cursor()
def process_item(self, item, spider):
sql = "insert into courses(title,url,pic,teacher,time,price) values('%s','%s','%s','%s','%s','%s')"%(item['title'],item['url'],item['pic'],item['teacher'],str(item['time']),str(item['price']))
#print(item)
self.cursor.execute(sql)
self.db.commit()
return item
def close_spider(self,spider):
self.db.close()
⑦ 修改配置文件
- 打开配置文件:settings.py 开启并配置ITEM_PIPELINES信息,配置数据库连接信息
ITEM_PIPELINES = {
'educsdn.pipelines.EducsdnPipeline': 300,
'educsdn.pipelines.MysqlPipeline': 301,
}
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'csdndb'
MYSQL_USER = 'root'
MYSQL_PASS = ''
MYSQL_PORT = 3306
⑧、运行爬取:
-
执行如下命令来启用数据爬取
scrapy crawl courses
7.4 下载和处理文件和图像:
① ImagesPipeline介绍
- Scrapy提供了专门处理下载的Pipeline,包含文件下载和图片下载,其原理与抓取页面的原理一样。
- 下载过程支持异步和多线程,下载十分高效。
- 网址:https://docs.scrapy.org/en/latest/topics/media-pipeline.html
- 实现方式:定义一个
ItemPipeline类继承scrapy.pipelines.images.ImagesPipeline。
② 具体使用:
- 首先定义存储文件的路径,在settings.py配置文件中添加代码:
IMAGES_STORE = './images' - 并在项目目录下创建
images文件夹 (与scrapy.cfg文件同级)。 - 要在pipelines.py文件中定义一个‘ImagePipeline’类,其代码如下:
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class ImagePipeline(ImagesPipeline):
'''自定义图片存储类'''
def get_media_requests(self, item, info):
'''通过抓取的item对象获取图片信息,并创建Request请求对象添加调度队列,等待调度执行下载'''
yield Request(item['pic'])
def file_path(self,request,response=None,info=None):
'''返回图片下载后保存的名称,没有此方法Scrapy则自动给一个唯一值作为图片名称'''
url = request.url
file_name = url.split("/")[-1]
return file_name
def item_completed(self, results, item, info):
''' 下载完成后的处理方法,其中results内容结构如下说明'''
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
#item['image_paths'] = image_paths
return item
-
在item_completed()方法中,results参数内容结构如下:
print(results) [(True, {'url': 'https://img-bss.csdn.net/201803191642534078.png', 'path': '201803191642534078.png', 'checksum': 'cc1368dbc122b6762f3e26ccef0dd105'} )] -
在settings.py文件中配置如下(启用下载):
...
ITEM_PIPELINES = {
'educsdn.pipelines.EducsdnPipeline': 300,
'educsdn.pipelines.ImagePipeline': 301,
'educsdn.pipelines.MysqlPipeline': 302,
}
MYSQL_HOST = "localhost"
MYSQL_DATABASE = "csdndb"
MYSQL_USER = "root"
MYSQL_PASS = ""
MYSQL_PORT = 3306
IMAGES_STORE = "./images"
...
8. Scrapy爬虫案例实战
- 任务:爬取腾讯网中关于指定条件的所有
社会招聘信息,搜索条件为北京地区,Python关键字的就业岗位,并将信息存储到MySql数据库中。 - 网址:https://hr.tencent.com/position.php?keywords=python&lid=2156
- 实现思路:首先爬取每页的招聘信息列表,再爬取对应的招聘详情信息
① 创建项目
- 在命令行编写下面命令,创建项目tencent
scrapy startproject tencent
- 项目目录结构:
tencent
├── tencent
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py # Items的定义,定义抓取的数据结构
│ ├── middlewares.py # 定义Spider和DownLoader的Middlewares中间件实现。
│ ├── pipelines.py # 它定义Item Pipeline的实现,即定义数据管道
│ ├── settings.py # 它定义项目的全局配置
│ └── spiders # 其中包含一个个Spider的实现,每个Spider都有一个文件
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg #Scrapy部署时的配置文件,定义了配置文件路径、部署相关信息等内容
② 进入tencent项目目录,创建爬虫spider类文件(hr招聘信息)
- 执行genspider命令,第一个参数是Spider的名称,第二个参数是网站域名。
scrapy genspider hr hr.tencent.com
$ tree
├── tencent
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-36.pyc
│ │ └── settings.cpython-36.pyc
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ ├── __pycache__
│ │ └── __init__.cpython-36.pyc
│ └── hr.py #在spiders目录下有了一个爬虫类文件hr.py
└── scrapy.cfg
# hr.py的文件代码如下:
# -*- coding: utf-8 -*-
import scrapy
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['hr.tencent.com']
start_urls = ['https://hr.tencent.com/position.php?keywords=python&lid=2156']
def parse(self, response):
#解析当前招聘列表信息的url地址:
detail_urls = response.css('tr.even a::attr(href),tr.odd a::attr(href)').extract()
#遍历url地址
for url in detail_urls:
#fullurl = 'http://hr.tencent.com/' + url
#构建绝对的url地址,效果同上(域名加相对地址)
fullurl = response.urljoin(url)
print(fullurl)
- 测试一下获取第一页的招聘详情url地址信息
③ 创建Item
- Item是保存爬取数据的容器,它的使用方法和字典类型,但相比字典多了些保护机制。
- 创建Item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段:
- 职位id号,名称、位置、类别、要求、人数、工作职责、工作要求
- 具体代码如下:(创建一个类名为HrItem)
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class HrItem(scrapy.Item):
'''
人事招聘信息封装类
(职位id号,名称、位置、类别、要求、人数、职责和要求)
'''
table = "hr" #表名
id = scrapy.Field()
title = scrapy.Field()
location = scrapy.Field()
type = scrapy.Field()
number = scrapy.Field()
duty = scrapy.Field()
requirement = scrapy.Field()
④ 解析Response
- 在hr.py文件中,parse()方法的参数response是start_urls里面的链接爬取后的结果。
- 提取的方式可以是CSS选择器、XPath选择器或者是re正则表达式。
# -*- coding: utf-8 -*-
import scrapy
from tencent.items import HrItem
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['hr.tencent.com']
start_urls = ['https://hr.tencent.com/position.php?keywords=python&lid=2156']
def parse(self, response):
#解析当前招聘列表信息的url地址:
detail_urls = response.css('tr.even a::attr(href),tr.odd a::attr(href)').extract()
#遍历url地址
for url in detail_urls:
#fullurl = 'http://hr.tencent.com/' + url
#构建绝对的url地址,效果同上(域名加相对地址)
fullurl = response.urljoin(url)
#print(fullurl)
# 构造请求准备爬取招聘详情信息,并指定由parse_page()方法解析回调函数
yield scrapy.Request(url=fullurl,callback=self.parse_page)
#获取下一页的url地址
next_url = response.css("#next::attr(href)").extract_first()
#判断若不是最后一页
if next_url != "javascript:;":
url = response.urljoin(next_url)
#构造下一页招聘列表信息的爬取
yield scrapy.Request(url=url,callback=self.parse)
# 解析详情页
def parse_page(self,response):
#构造招聘信息的Item容器对象
item = HrItem()
# 解析id号信息,并封装到Item中
item["id"] = response.selector.re_first('οnclick="applyPosition\(([0-9]+)\);"')
#标题
item["title"] = response.css('#sharetitle::text').extract_first()
#位置
item["location"] = response.selector.re_first('工作地点:(.*?)')
#类别
item["type"] = response.selector.re_first('职位类别:(.*?)')
#人数
item["number"] = response.selector.re_first('招聘人数:([0-9]+)人')
#工作职责
duty = response.xpath('//table//tr[3]//li/text()').extract()
item["duty"] = ''.join(duty)
#工作要求
requirement = response.xpath('//table//tr[4]//li/text()').extract()
item["requirement"] = ''.join(requirement)
#print(item)
#交给管道文件
yield item
⑤、创建数据库和表:
- 在mysql中创建数据库
mydb和数据表hr
CREATE TABLE `hr` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL,
`location` varchar(32) DEFAULT NULL,
`type` varchar(32) DEFAULT NULL,
`number` varchar(32) DEFAULT NULL,
`duty` text DEFAULT NULL,
`requirement` text DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
⑥、使用Item Pipeline
- 在Item管道文件中,定义一个MysqlPipeline,负责连接数据库并执行信息写入操作
import pymysql
class TencentPipeline(object):
def process_item(self, item, spider):
return item
class MysqlPipeline(object):
def __init__(self,host,user,password,database,port):
self.host = host
self.user = user
self.password = password
self.database = database
self.port = port
@classmethod
def from_crawler(cls,crawler):
return cls(
host = crawler.settings.get("MYSQL_HOST"),
user = crawler.settings.get("MYSQL_USER"),
password = crawler.settings.get("MYSQL_PASS"),
database = crawler.settings.get("MYSQL_DATABASE"),
port = crawler.settings.get("MYSQL_PORT"),
)
def open_spider(self, spider):
'''负责连接数据库'''
self.db = pymysql.connect(self.host,self.user,self.password,self.database,charset="utf8",port=self.port)
self.cursor = self.db.cursor()
def process_item(self, item, spider):
'''执行数据表的写入操作'''
#组装sql语句
data = dict(item)
keys = ','.join(data.keys())
values=','.join(['%s']*len(data))
sql = "insert into %s(%s) values(%s)"%(item.table,keys,values)
#指定参数,并执行sql添加
self.cursor.execute(sql,tuple(data.values()))
#事务提交
self.db.commit()
return item
def close_spider(self, spider):
'''关闭连接数据库'''
self.db.close()
⑦ 修改配置文件
- 打开配置文件:settings.py 开启并配置ITEM_PIPELINES信息,配置数据库连接信息
- 当有CONCURRENT_REQUESTS,没有DOWNLOAD_DELAY 时,服务器会在同一时间收到大量的请求。
- 当有CONCURRENT_REQUESTS,有DOWNLOAD_DELAY 时,服务器不会在同一时间收到大量的请求。
# 忽略爬虫协议
ROBOTSTXT_OBEY = False
# 并发量
CONCURRENT_REQUESTS = 1
#下载延迟
DOWNLOAD_DELAY = 0
ITEM_PIPELINES = {
#'educsdn.pipelines.EducsdnPipeline': 300,
'educsdn.pipelines.MysqlPipeline': 301,
}
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'mydb'
MYSQL_USER = 'root'
MYSQL_PASS = ''
MYSQL_PORT = 3306
⑧、运行爬取:
-
执行如下命令来启用数据爬取
scrapy crawl hr
9. Scrapy扩展
1. 如何使scrapy爬取信息不打印在命令窗口中
- 通常,我们使用这条命令运行自己的scrapy爬虫:
scrapy crawl spider_name
- 但是,由这条命令启动的爬虫,会将所有爬虫运行中的debug信息及抓取到的信息打印在运行窗口中。
- 很乱,也不方便查询。所以,可使用该命令代替:
scrpay crawl spider_name -s LOG_FILE=all.log
2. Scrapy中的日志处理
- Scrapy提供了log功能,可以通过 logging 模块使用
- 可以修改配置文件settings.py,任意位置添加下面两行
LOG_FILE = "mySpider.log"
LOG_LEVEL = "INFO"
- Scrapy提供5层logging级别:
CRITICAL - 严重错误(critical)
ERROR - 一般错误(regular errors)
WARNING - 警告信息(warning messages)
INFO - 一般信息(informational messages)
DEBUG - 调试信息(debugging messages)
- logging设置
- 通过在setting.py中进行以下设置可以被用来配置logging:
LOG_ENABLED 默认: True,启用logging
LOG_ENCODING 默认: 'utf-8',logging使用的编码
LOG_FILE 默认: None,在当前目录里创建logging输出文件的文件名
LOG_LEVEL 默认: 'DEBUG',log的最低级别
LOG_STDOUT 默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print "hello" ,其将会在Scrapy log中显示
- 记录信息
- 下面给出如何使用WARING级别来记录信息
from scrapy import log
log.msg("This is a warning", level=log.WARNING)
十、Python网络爬虫进阶实战(中)
09. Selenium的使用
9.1 动态渲染页面爬取
- 对于访问Web时直接响应的数据(就是response内容可见),我们使用urllib、requests或Scrapy框架爬取。
- 对应一般的JavaScript动态渲染的页面信息(Ajax加载),我们可以通过分析Ajax请求来抓取信息。
- 即使通过Ajax获取数据,但还有会部分加密参数,后期经过JavaScript计算生成内容,导致我们难以直接找到规律,如淘宝页面。
- 为了解决这些问题,我们可以直接使用模拟浏览器运行的方式来实现信息获取。
- 在Python中有许多模拟浏览器运行库,如:Selenium、Splash、PyV8、Ghost等。
9.2 Selenium的介绍
- Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击,下拉,等操作。
- Selenium可以获取浏览器当前呈现的页面源代码,做到可见既可爬,对应JavaScript动态渲染的信息爬取非常有效。
- 官方网址:http://www.seleniumhq.org
- 官方文档:http://selenium-python.readthedocs.io
- 中文文档:http://selenium-python-zh.readthedocs.io
- 安装:
pip install selenium - Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还支持无界面浏览器PhantomJS。
- ChromeDriver浏览器驱动的安装:(注意浏览器版本:)
- 首先查看当前谷歌Chrome浏览器的版本V61V67(对应2.352.38),再到下面网址下载
- 网址:
https://chromedriver.storage.googleapis.com/index.html - Windows安装:将解压的文件:
chromedriver.exe放置到Python的Scripts目录下。 - Mac/Linux安装:将解压的文件:
chromedriver放置到/usr/local/bin/目录下
- PhantomJS驱动的下载地址:http://phantomjs.org/download.html
9.3 Selenium的使用
① 初次体验:模拟谷歌浏览器访问百度首页,并输入python关键字搜索
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
#初始化一个浏览器(如:谷歌,使用Chrome需安装chromedriver)
driver = webdriver.Chrome()
#driver = webdriver.PhantomJS() #无界面浏览器
try:
#请求网页
driver.get("https://www.baidu.com")
#查找id值为kw的节点对象(搜索输入框)
input = driver.find_element_by_id("kw")
#模拟键盘输入字串内容
input.send_keys("python")
#模拟键盘点击回车键
input.send_keys(Keys.ENTER)
#显式等待,最长10秒
wait = WebDriverWait(driver,10)
#等待条件:10秒内必须有个id属性值为content_left的节点加载出来,否则抛异常。
wait.until(EC.presence_of_element_located((By.ID,'content_left')))
# 输出响应信息
print(driver.current_url)
print(driver.get_cookies())
print(driver.page_source)
finally:
#关闭浏览器
#driver.close()
pass
② 声明浏览器对象
from selenium import webdriver
driver = webdriver.Chrome() #谷歌 需:ChromeDriver驱动
driver = webdriver.FireFox() #火狐 需:GeckoDriver驱动
driver = webdriver.Edge()
driver = webdriver.Safari()
driver = webdriver.PhantomJS() #无界面浏览器
③ 访问页面
from selenium import webdriver
driver = webdriver.Chrome()
#driver = webdriver.PhantomJS()
driver.get("http://www.taobao.com")
print(driver.page_source)
#driver.close()
④ 查找节点:
- 获取单个节点的方法:
- find_element_by_id()
- find_element_by_name()
- find_element_by_xpath()
- find_element_by_link_text()
- find_element_by_partial_link_text()
- find_element_by_tag_name()
- find_element_by_class_name()
- find_element_by_css_seletor()
from selenium import webdriver
from selenium.webdriver.common.by import By
#创建浏览器对象
driver = webdriver.Chrome()
#driver = webdriver.PhantomJS()
driver.get("http://www.taobao.com")
#下面都是获取id属性值为q的节点对象
input = driver.find_element_by_id("q")
print(input)
input = driver.find_element_by_css_selector("#q")
print(input)
input = driver.find_element_by_xpath("//*[@id='q']")
print(input)
#效果同上
input = driver.find_element(By.ID,"q")
print(input)
#driver.close()
- 获取多个节点的方法:
- find_elements_by_id()
- find_elements_by_name()
- find_elements_by_xpath()
- find_elements_by_link_text()
- find_elements_by_partial_link_text()
- find_elements_by_tag_name()
- find_elements_by_class_name()
- find_elements_by_css_seletor()
⑤ 节点交互:
from selenium import webdriver
import time
#创建浏览器对象
driver = webdriver.Chrome()
#driver = webdriver.PhantomJS()
driver.get("http://www.taobao.com")
#下面都是获取id属性值为q的节点对象
input = driver.find_element_by_id("q")
#模拟键盘输入iphone
input.send_keys('iphone')
time.sleep(3)
#清空输入框
input.clear()
#模拟键盘输入iPad
input.send_keys('iPad')
#获取搜索按钮节点
botton = driver.find_element_by_class_name("btn-search")
#触发点击动作
botton.click()
#driver.close()
⑥ 动态链:
- ActionChains是一种自动化低级别交互的方法,如鼠标移动,鼠标按钮操作,按键操作和上下文菜单交互。
- 这对于执行更复杂的操作(如悬停和拖放)很有用.
- move_to_element(to_element )-- 将鼠标移到元素的中间
- move_by_offset(xoffset,yoffset )-- 将鼠标移至当前鼠标位置的偏移量
- drag_and_drop(源,目标)-- 然后移动到目标元素并释放鼠标按钮。
- pause(秒)-- 以秒为单位暂停指定持续时间的所有输入
- perform()-- 执行所有存储的操作。
- release(on_element = None )释放元素上的一个持有鼠标按钮。
- reset_actions()-- 清除已存储在远程端的操作。
- send_keys(* keys_to_send )-- 将键发送到当前的焦点元素。
- send_keys_to_element(element,* keys_to_send )-- 将键发送到一个元素。
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
#创建浏览器对象
driver = webdriver.Chrome()
#加载指定url地址
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
driver.get(url)
# 切换Frame窗口
driver.switch_to.frame('iframeResult')
#获取两个div节点对象
source = driver.find_element_by_css_selector("#draggable")
target = driver.find_element_by_css_selector("#droppable")
#创建一个动作链对象
actions = ActionChains(driver)
#将一个拖拽操作添加到动作链队列中
actions.drag_and_drop(source,target)
time.sleep(3)
#执行所有存储的操作(顺序被触发)
actions.perform()
#driver.close()
⑦ 执行JavaScript:
from selenium import webdriver
#创建浏览器对象
driver = webdriver.Chrome()
#加载指定url地址
driver.get("https://www.zhihu.com/explore")
#执行javascript程序将页面滚动移至底部
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
#执行javascript实现一个弹框操作
driver.execute_script('window.alert("Hello Selenium!")')
#driver.close()
⑧ 获取节点信息:
from selenium import webdriver
from selenium.webdriver import ActionChains
#创建浏览器对象
driver = webdriver.Chrome()
#加载请求指定url地址
driver.get("https://www.zhihu.com/explore")
#获取id属性值为zh-top-link-logo的节点(logo)
logo = driver.find_element_by_id("zh-top-link-logo")
print(logo) #输出节点对象
print(logo.get_attribute('class')) #节点的class属性值
#获取id属性值为zu-top-add-question节点(提问按钮)
input = driver.find_element_by_id("zu-top-add-question")
print(input.text) #获取节点间内容
print(input.id) #获取id属性值
print(input.location) #节点在页面中的相对位置
print(input.tag_name) #节点标签名称
print(input.size) #获取节点的大小
#driver.close()
⑨ 切换Frame:
- 网页中有一种节点叫做
iframe,也就是子Frame,他可以将一个页面分成多个子父界面。 - 我们可以使用switch_to.frame()来切换Frame界面,实例详见
第⑥的动态链案例
⑩ 延迟等待:
- 浏览器加载网页是需要时间的,Selenium也不例外,若要获取完整网页内容,就要延时等待。
- 在Selenium中延迟等待方式有两种:一种是隐式等待,一种是显式等待(推荐)。
from selenium import webdriver
#创建浏览器对象
driver = webdriver.Chrome()
#使用隐式等待(固定时间)
driver.implicitly_wait(2)
#加载请求指定url地址
driver.get("https://www.zhihu.com/explore")
#获取节点
input = driver.find_element_by_id("zu-top-add-question")
print(input.text) #获取节点间内容
#driver.close()
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
#创建浏览器对象
driver = webdriver.Chrome()
#加载请求指定url地址
driver.get("https://www.zhihu.com/explore")
#显式等待,最长10秒
wait = WebDriverWait(driver,10)
#等待条件:10秒内必须有个id属性值为zu-top-add-question的节点加载出来,否则抛异常。
input = wait.until(EC.presence_of_element_located((By.ID,'zu-top-add-question')))
print(input.text) #获取节点间内容
#driver.close()
11 前进和后退:
from selenium import webdriver
import time
#创建浏览器对象
driver = webdriver.Chrome()
#加载请求指定url地址
driver.get("https://www.baidu.com")
driver.get("https://www.taobao.com")
driver.get("https://www.jd.com")
time.sleep(2)
driver.back() #后退
time.sleep(2) #前进
driver.forward()
#driver.close()
12 Cookies:
from selenium import webdriver
from selenium.webdriver import ActionChains
#创建浏览器对象
driver = webdriver.Chrome()
#加载请求指定url地址
driver.get("https://www.zhihu.com/explore")
print(driver.get_cookies())
driver.add_cookie({
'name':'namne','domain':'www.zhihu.com','value':'zhangsan'})
print(driver.get_cookies())
driver.delete_all_cookies()
print(driver.get_cookies())
#driver.close()
13 选项卡管理:
from selenium import webdriver
import time
#创建浏览器对象
driver = webdriver.Chrome()
#加载请求指定url地址
driver.get("https://www.baidu.com")
#使用JavaScript开启一个新的选型卡
driver.execute_script('window.open()')
print(driver.window_handles)
#切换到第二个选项卡,并打开url地址
driver.switch_to_window(driver.window_handles[1])
driver.get("https://www.taobao.com")
time.sleep(2)
#切换到第一个选项卡,并打开url地址
driver.switch_to_window(driver.window_handles[0])
driver.get("https://www.jd.com")
#driver.close()
14 异常处理:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException
#创建浏览器对象
driver = webdriver.Chrome()
try:
#加载请求指定url地址
driver.get("https://www.baidu.com")
except TimeoutException:
print('Time Out')
try:
#加载请求指定url地址
driver.find_element_by_id("demo")
except NoSuchElementException:
print('No Element')
finally:
#driver.close()
pass
10. Selenium爬取淘宝商品
① 案例要求
- 使用Selenium爬取淘宝商品,指定关键字和指定页码信息来进行爬取
② 案例分析:
- url地址:https://s.taobao.com/search?q=ipad
③ 具体代码实现
'''通过关键字爬取淘宝网站的信息数据'''
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from pyquery import PyQuery as pq
from urllib.parse import quote
KEYWORD = "ipad"
MAX_PAGE = 10
# browser = webdriver.Chrome()
# browser = webdriver.PhantomJS()
#创建谷歌浏览器对象,启用Chrome的Headless无界面模式
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
#显式等待:
wait = WebDriverWait(browser, 10)
def index_page(page):
'''抓取索引页 :param page: 页码'''
print('正在爬取第', page, '页')
try:
url = 'https://s.taobao.com/search?q=' + quote(KEYWORD)
browser.get(url)
if page > 1:
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager div.form > input')))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page)
submit.click()
#等待条件:显示当前页号,显式商品
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)))
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.m-itemlist .items .item')))
get_products()
except TimeoutException:
index_page(page)
def get_products():
'''提取商品数据'''
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('data-src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text(),
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
save_data(product)
def save_data(result):
'''保存数据'''
pass
def main():
'''遍历每一页'''
for i in range(1, MAX_PAGE + 1):
index_page(i)
browser.close()
# 主程序入口
if __name__ == '__main__':
main()
11. MongoDB数据库
- MongoDB 是一个
基于分布式文件存储的数据库。由C++语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。 - MongoDB 是一个
介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。 - 参考地址:
- MongoDB 官网地址:https://www.mongodb.com/
- MongoDB 官方英文文档:https://docs.mongodb.com/manual/
- MongoDB 各平台下载地址:https://www.mongodb.com/download-center#community
1.1 RDBMS与NoSQL区别:
- 关系数据库管理系统(RDBMS)
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
- 非关系型数据库(NoSQL)
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
- RDBMS 与 MongoDB 对应的术语区别:
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
1.2 Windows下安装MongoDB:
- 下载地址:https://www.mongodb.org/dl/win32/x86_64-2008plus-ssl
- 最新版的在安装过程中出现卡死现象,建议选择版本3.4版本(测试过)。
- 安装图形界面,一步一步的安装即可:
- 创建数据库目录:
c:\>cd c:\
c:\>mkdir data
c:\>cd data
c:\data>mkdir db
c:\data>cd db
c:\data\db>
- 启动MongoDB服务:
C:\Program Files\MongoDB\Server\3.4\bin>mongod --dbpath c:\data\db
- 连接MongoDB
C:\Program Files\MongoDB\Server\3.4\bin>mongo
1.3 数据库的操作
① MongoDB的数据库操作
- 查看当前数据库名称
db
- 查看所有数据库名称
- 列出所有在物理上存在的数据库
show dbs
·
- 切换数据库
- 如果数据库不存在,则指向数据库,但不创建,直到插入数据或创建集合时数据库才被创建
use 数据库名称
默认的数据库为测试,如果你没有创建新的数据库,集合将存放在测试数据库中
- 数据库删除
- 删除当前指向的数据库
- 如果数据库不存在,则什么也不做
db.dropDatabase()
② MongoDB的集合操作:
- 创建集合:
db.createCollection(name, options)
- name是要创建的集合的名称
- options是一个文档,用于指定集合的配置
- 选项参数是可选的,所以只需要到指定的集合名称。以下是可以使用的选项列表:
- 例1:不限制集合大小
- db.createCollection(“stu”)
- 例2:限制集合大小,后面学会插入语句后可以查看效果
- 参数capped:默认值为false表示不设置上限,值为true表示设置上限
- 参数size:当capped值为true时,需要指定此参数,表示上限大小,当文档达到上限时,会将之前的数据覆盖,单位为字节
- db.createCollection(“sub”, { capped : true, size : 10 } )
- 查看当前数据库的集合
show collections
删除集合:
db.集合名称.drop()
③ 数据类型:
- 下表为MongoDB中常用的几种数据类型:
- Object ID:文档ID
- String:字符串,最常用,必须是有效的UTF-8
- Boolean:存储一个布尔值,true或false
- Integer:整数可以是32位或64位,这取决于服务器
- Double:存储浮点值
- Arrays:数组或列表,多个值存储到一个键
- Object:用于嵌入式的文档,即一个值为一个文档
- Null:存储Null值
- Timestamp:时间戳
- Date:存储当前日期或时间的UNIX时间格式
- object id
- 每个文档都有一个属性,为_id,保证每个文档的唯一性
- 可以自己去设置_id插入文档
- 如果没有提供,那么MongoDB为每个文档提供了一个独特的_id,类型为objectID
- objectID是一个12字节的十六进制数
- 前4个字节为当前时间戳
- 接下来3个字节的机器ID
- 接下来的2个字节中MongoDB的服务进程id
- 最后3个字节是简单的增量值
④ 数据的操作
- 插入语法
db.集合名称.insert(document)
-
插入文档时,如果不指定_id参数,MongoDB的会为文档分配一个唯一的的ObjectId
-
例1:
db.stu.insert({name:'gj',gender:1}) -
例2:
s1={_id:'20160101',name:'hr'} s1.gender=0 db.stu.insert(s1) -
简单查询
db.集合名称.find()
- 数据的更新
db.集合名称.update(
,
,
{multi: }
)
- 参数查询:查询条件,类似SQL语句更新中,其中部分
- 参数更新:更新操作符,类似SQL语句更新中集部分
- 参数多:可选,默认是假的,表示只更新找到的第一条记录,值为真表示把满足条件的文档全部更新
例3:全文档更新
db.stu.update({name:'hr'},{name:'mnc'})
例4:指定属性更新,通过操作符$集
db.stu.insert({name:'hr',gender:0})
db.stu.update({name:'hr'},{$set:{name:'hys'}})
例5:修改多条匹配到的数据
db.stu.update({},{$set:{gender:0}},{multi:true})
- 数据的保存语法
db.集合名称.save(document)
- 如果文档的_id已经存在则修改,如果文档的_id不存在则添加
db.stu.save({_id:'20160102','name':'yk',gender:1})
db.stu.save({_id:'20160102','name':'wyk'})
- 删除 语法
db.集合名称.remove(
,
{
justOne:
}
)
- 参数查询:可选,删除的文档的条件
- 参数来说只是个:可选,如果设为真或1,则只删除一条,默认为false,表示删除多条
例:只删除匹配到的第一条
db.stu.remove({gender:0},{justOne:true})
例:全部删除
db.stu.remove({})
- 关于大小的示例
创建集合
db.createCollection('sub',{capped:true,size:10})
插入第一条数据库查询
db.sub.insert({title:'linux',count:10})
db.sub.find()
插入第二条数据库查询
db.sub.insert({title:'web',count:15})
db.sub.find()
插入第三条数据库查询
db.sub.insert({title:'sql',count:8})
db.sub.find()
插入第四条数据库查询
db.sub.insert({title:'django',count:12})
db.sub.find()
插入第五条数据库查询
db.sub.insert({title:'python',count:14})
db.sub.find()
- limit限制
方法限制():用于读取指定数量的文档
db.集合名称.find().limit(NUMBER)
参数号表示要获取文档的条数
如果没有指定参数则显示集合中的所有文档
例1:查询2条学生信息
db.stu.find().limit(2)
- 投影
在查询到的返回结果中,只选择必要的字段,而不是选择一个文档的整个字段
如:一个文档有5个字段,需要显示只有3个,投影其中3个字段即可
参数为字段与值,值为1表示显示,值为0不显示
db.集合名称.find({},{字段名称:1,...})
特殊:对于_id列默认是显示的,如果不显示需要明确设置为0
例1
db.stu.find({},{name:1,gender:1})
例2
db.stu.find({},{_id:0,name:1,gender:1})
- 排序
方法sort(),用于对结果集进行排序
db.集合名称.find().sort({字段:1,...})
参数1为升序排列
参数-1为降序排列
例1:根据性别降序,再根据年龄升序
db.stu.find().sort({gender:-1,age:1})
- 统计个数
方法count()用于统计结果集中文档条数
db.集合名称.find({条件}).count()
也可以与为
db.集合名称.count({条件})
例1:统计男生人数
db.stu.find({gender:1}).count()
例2:统计年龄大于20的男生人数
b.stu.count({age:{$gt:20},gender:1})
- 消除重复
方法distinct()对数据进行去重
db.集合名称.distinct('去重字段',{条件})
例1:查找年龄大于18的性别(去重)
db.stu.distinct('gender',{age:{$gt:18}})
11.4 备份与恢复
语法
mongodump -h dbhost -d dbname -o dbdirectory
-h:服务器地址,也可以指定端口号
-d:需要备份的数据库名称
-o:备份的数据存放位置,此目录中存放着备份出来的数据
例1
sudo mkdir test1bak
sudo mongodump -h 192.168.196.128:27017 -d test1 -o ~/Desktop/test1bak
恢复
语法
mongorestore -h dbhost -d dbname --dir dbdirectory
-h:服务器地址
-d:需要恢复的数据库实例
--dir:备份数据所在位置
例2
mongorestore -h 192.168.196.128:27017 -d test2 --dir ~/Desktop/test1bak/test1
11.5 与python交互
-
安装python包
pip install pymongo -
使用:
-
引入包pymongo
import pymongo -
连接,创建客户端
client=pymongo.MongoClient("localhost", 27017) -
获得数据库test1
db=client.test1 -
获得集合stu
stu = db.stu -
添加文档
s1={name:'gj',age:18} s1_id = stu.insert_one(s1).inserted_id -
查找一个文档
s2=stu.find_one() -
查找多个文档1
for cur in stu.find(): print cur -
查找多个文档2
cur=stu.find() cur.next() cur.next() cur.next() -
获取文档个数
print stu.count()
12. Scrapy框架使用Selenium
- 案例目标:
- 本节案例主要是通过Scrapy框架使用Selenium,以PhantomJS进行演示,爬取淘宝商品信息案例,并将信息存入数据库MongoDB中。
- 准备工作:
- 请确保PhantomJS和MongoDB都已安装号,并确保可以正常运行,安装好Scrapy、Selenium和PyMongod库。
① 创建项目
- 首先新建项目,名为scrapyseleniumtest:
scrapy startproject scrapyseleniumtest
- 进入项目目录下,创建一个Spider(爬虫类):
cd srapytseleniumtest
scrapy genspider taobao www.baobao.com
- 进入settings.py的配置文件:将ROBOTSTXT_OBEY改为false
ROBOTSTXT_OBEY = False
② 定义Item类
# 定义信息封装类(图片、价格、购买人数、标题、店铺、发货源)
from scrapy import Item, Field
class ProductItem(Item):
collection = 'products'
image = Field()
price = Field()
deal = Field()
title = Field()
shop = Field()
location = Field()
③ 解析页面
- 在配置文件settings.py最后面定义搜索关键字和最大页码数信息:
KEYWORDS = ['iPad']
MAX_PAGE = 100
- 进入spider/taobao.py文件中编写,代码如下:
# -*- coding: utf-8 -*-
from scrapy import Request, Spider
from urllib.parse import quote
from scrapyseleniumtest.items import ProductItem
class TaobaoSpider(Spider):
name = 'taobao'
allowed_domains = ['www.taobao.com']
base_url = 'https://s.taobao.com/search?q='
def start_requests(self):
for keyword in self.settings.get('KEYWORDS'):
for page in range(1, self.settings.get('MAX_PAGE') + 1):
url = self.base_url + quote(keyword)
yield Request(url=url, callback=self.parse, meta={
'page': page}, dont_filter=True)
def parse(self, response):
pass
④ 对接Selenium
- 通过定义DownloaderMiddleware中间件来实现对Selenium的使用。
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from scrapy.http import HtmlResponse
from logging import getLogger
class SeleniumMiddleware():
def __init__(self, timeout=None, service_args=[]):
self.logger = getLogger(__name__)
self.timeout = timeout
self.browser = webdriver.PhantomJS(service_args=service_args)
self.browser.set_window_size(1400, 700)
self.browser.set_page_load_timeout(self.timeout)
self.wait = WebDriverWait(self.browser, self.timeout)
def __del__(self):
self.browser.close()
def process_request(self, request, spider):
"""
用PhantomJS抓取页面
:param request: Request对象
:param spider: Spider对象
:return: HtmlResponse
"""
self.logger.debug('PhantomJS is Starting')
page = request.meta.get('page', 1)
try:
self.browser.get(request.url)
if page > 1:
input = self.wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager div.form > input')))
submit = self.wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page)
submit.click()
self.wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)))
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.m-itemlist .items .item')))
return HtmlResponse(url=request.url, body=self.browser.page_source, request=request, encoding='utf-8',
status=200)
except TimeoutException:
return HtmlResponse(url=request.url, status=500, request=request)
@classmethod
def from_crawler(cls, crawler):
return cls(timeout=crawler.settings.get('SELENIUM_TIMEOUT'),
service_args=crawler.settings.get('PHANTOMJS_SERVICE_ARGS'))
- 在settings.py配置文件中.设置我们自定义的中间件设置:
DOWNLOADER_MIDDLEWARES = {
'scrapyseleniumtest.middlewares.SeleniumMiddleware': 543,
}
⑤ 解析页面信息
# -*- coding: utf-8 -*-
from scrapy import Request, Spider
from urllib.parse import quote
from scrapyseleniumtest.items import ProductItem
class TaobaoSpider(Spider):
name = 'taobao'
allowed_domains = ['www.taobao.com']
base_url = 'https://s.taobao.com/search?q='
def start_requests(self):
for keyword in self.settings.get('KEYWORDS'):
for page in range(1, self.settings.get('MAX_PAGE') + 1):
url = self.base_url + quote(keyword)
yield Request(url=url, callback=self.parse, meta={
'page': page}, dont_filter=True)
def parse(self, response):
products = response.xpath(
'//div[@id="mainsrp-itemlist"]//div[@class="items"][1]//div[contains(@class, "item")]')
for product in products:
item = ProductItem()
item['price'] = ''.join(product.xpath('.//div[contains(@class, "price")]//text()').extract()).strip()
item['title'] = ''.join(product.xpath('.//div[contains(@class, "title")]//text()').extract()).strip()
item['shop'] = ''.join(product.xpath('.//div[contains(@class, "shop")]//text()').extract()).strip()
item['image'] = ''.join(product.xpath('.//div[@class="pic"]//img[contains(@class, "img")]/@data-src').extract()).strip()
item['deal'] = product.xpath('.//div[contains(@class, "deal-cnt")]//text()').extract_first()
item['location'] = product.xpath('.//div[contains(@class, "location")]//text()').extract_first()
yield item
⑥ 存储结果
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DB'))
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
self.db[item.collection].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
- 配置文件信息:
ITEM_PIPELINES = {
'scrapyseleniumtest.pipelines.MongoPipeline': 300,
}
KEYWORDS = ['iPad']
MAX_PAGE = 100
SELENIUM_TIMEOUT = 20
PHANTOMJS_SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']
MONGO_URI = 'localhost'
MONGO_DB = 'taobao'
13. 代理的使用
13.1 代理服务的介绍:
- 我们在做爬虫的过程中经常最初爬虫都正常运行,正常爬取数据,一切看起来都是美好,然而一杯茶的功夫就出现了错误。
- 如:403 Forbidden错误,“您的IP访问频率太高”错误,或者跳出一个验证码让我们输入,之后解封,但过一会又出现类似情况。
- 出现这个现象的原因是因为网站采取了一些反爬中措施,如:服务器检测IP在单位时间内请求次数超过某个阀值导致,称为封IP。
- 为了解决此类问题,代理就派上了用场,如:代理软件、付费代理、ADSL拨号代理,以帮助爬虫脱离封IP的苦海。
- 测试HTTP请求及响应的网站:http://httpbin.org/
- httpbin这个网站能测试 HTTP 请求和响应的各种信息,比如 cookie、ip、headers 和登录验证等.
- 且支持 GET、POST 等多种方法,对 web 开发和测试很有帮助。
- GET地址 :http://httpbin.org/get
- POST地址:http://httpbin.org/post
- 它用 Python + Flask 编写,是一个开源项目。开源地址:https://github.com/Runscope/httpbin
- 返回信息中origin的字段就是客户端的IP地址,即可判断是否成功伪装IP:
13.2 代理的设置:
① urllib的代理设置
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy = '127.0.0.1:8888'
#需要认证的代理
#proxy = 'username:[email protected]:8888'
#使用ProxyHandler设置代理
proxy_handler = ProxyHandler({
'http': 'http://' + proxy,
'https': 'https://' + proxy
})
#传入参数创建Opener对象
opener = build_opener(proxy_handler)
try:
response = opener.open('http://httpbin.org/get')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)
② requests的代理设置
import requests
proxy = '127.0.0.1:8888'
#需要认证的代理
#proxy = 'username:[email protected]:8888'
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy,
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)
③ Selenium的代理使用
- 使用的是PhantomJS
from selenium import webdriver
service_args = [
'--proxy=127.0.0.1:9743',
'--proxy-type=http',
#'--proxy-auth=username:password' #带认证代理
]
browser = webdriver.PhantomJS(service_args=service_args)
browser.get('http://httpbin.org/get')
print(browser.page_source)
- 使用的是Chrome
from selenium import webdriver
proxy = '127.0.0.1:9743'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://' + proxy)
chrome = webdriver.Chrome(chrome_options=chrome_options)
chrome.get('http://httpbin.org/get')
④ 在Scrapy使用代理
#在Scrapy的Downloader Middleware中间件里
...
def process_request(self, request, spider):
request.meta['proxy'] = 'http://127.0.0.1:9743'
...
13.3 免费代理IP的使用
- 我们可以从互联网中获取免费的代理IP:如:西刺 http://www.xicidaili.com
import requests,random
#定义代理池
proxy_list = [
'182.39.6.245:38634',
'115.210.181.31:34301',
'123.161.152.38:23201',
'222.85.5.187:26675',
'123.161.152.31:23127',
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy,
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)
13.4 收费代理IP的使用
- 收费代理还是很多的如:
- 西刺:http://www.xicidaili.com
- 讯代理:http://www.xdaili.cn/
- 快代理:https://www.kuaidaili.com/
- 大象代理:http://www.daxiangdaili.com/
- 在requests中使用收费代理
import requests
# 从代理服务中获取一个代理IP
proxy = requests.get("http://tvp.daxiangdaili.com/ip/?tid=559775358931681&num=1").text
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy,
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)
- 在scrapy中使用收费代理
- 创建scrapy项目:scrapy startproject httpbin
- 创建爬虫文件: ```cd httpbin
scrapy genspider hb httpbin.org
```python
#编写爬虫文件hb.py
import scrapy
class HbSpider(scrapy.Spider):
name = 'hb'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/get']
def parse(self, response):
print(response.body)
#编写中间件文件:middlewares.py
class HttpbinProxyMiddleware(object):
def process_request(self, request, spider):
pro_addr = requests.get('http://127.0.0.1:5000/get').text
request.meta['proxy'] = 'http://' + pro_addr
#修改配置文件settings.py
ROBOTSTXT_OBEY = False #关闭爬虫协议
DOWNLOADER_MIDDLEWARES = {
'httpbin.middlewares.HttpbinProxyMiddleware': 543,
}
#关闭终端输出,改输出到指定日志文件中
LOG_LEVEL= 'DEBUG'
LOG_FILE ='log.txt'
- 执行信息爬取测试: scrapy crawl hb
14. 使用代理爬取信息实战
14.1 实战目标:
- 本节目标是利用代理爬取微信公众号的文章信息,从中提取标题、摘要、发布日期、公众号以及url地址等内容。
- 本节爬取的是搜索关键字为
python的,类别为微信的所有文章信息,并将信息存储到MongoDB中。 - URL地址:http://weixin.sogou.com/weixin?type=2&query=python&ie=utf8&s_from=input
14.2 准备工作:
- 首先对要爬取的微信公众号的文章信息进行分析,确定url地址。
- 分析要爬取的信息加载方式,确定属性普通加载(在响应里使用xpath或css解析)。
- 分析如何获取更多页信息的爬取。就是如何跳转下一页。(没有登录的用户只能看到10页,登陆后才可看到其他页)
- 本次案例需要使用的Python库:Scrapy、requests、pymongo。
- 在MongoDB中创建一个数据库
wenxin,让后在此库中创建一个集合wx,最后开启MongoDB数据库
14.3 具体实现:
① 创建项目
- 首先新建项目,名为weixin:
scrapy startproject weixin
- 进入项目weixin目录下,创建一个Spider(爬虫类wx):
cd weixin
scrapy genspider wx weixin.sogou.com
- 进入settings.py的配置文件:将ROBOTSTXT_OBEY改为false,忽略爬虫协议
ROBOTSTXT_OBEY = False
② 定义Item类
# 定义信息封装类(标题、摘要、公众号、时间、URL地址)
import scrapy
class WxItem(scrapy.Item):
# define the fields for your item here like:
collection = ‘wx’
title = scrapy.Field()
content = scrapy.Field()
nickname = scrapy.Field()
date = scrapy.Field()
url = scrapy.Field()
③ 解析页面
- 进入spider/wx.py文件中编写,代码如下:
# -*- coding: utf-8 -*-
import scrapy
from weixin.items import WxItem
class WxSpider(scrapy.Spider):
name = 'wx'
allowed_domains = ['weixin.sogou.com']
start_urls = ['http://weixin.sogou.com/weixin?query=python&type=2&page=1&ie=utf8']
def parse(self, response):
#解析出当前页面中的所有文章信息
ullist = response.selector.css("ul.news-list li")
#遍历文章信息
for ul in ullist:
#解析具体信息并封装到item中
item = WxItem()
item['title'] = ul.css("h3 a").re_first("(.*?)" )
item['content'] = ul.css("p.txt-info::text").extract_first()
item['nickname'] = ul.css("a.account::text").extract_first()
item['date'] = ul.re_first("document.write\(timeConvert\('([0-9]+)'\)\)")
item['url'] = ul.css("h3 a::attr(href)").extract_first()
print(item)
# 交给pipelines(item管道)处理
yield item
#解析出下一頁的url地址
next_url = response.selector.css("#sogou_next::attr(href)").extract_first()
#判断是否存在
if next_url:
url = response.urljoin(next_url) #构建绝对url地址
yield scrapy.Request(url=url,callback=self.parse) #交给调度去继续爬取下一页信息
④ 存储结果
import pymongo
class MongoPipeline(object):
''' 完成MongoDB数据库对Item信息的存储'''
def __init__(self, mongo_uri, mongo_db):
'''对象初始化'''
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
'''通过依赖注入方式实例化当前类,并返回,参数是从配置文件获取MongoDB信息'''
return cls(mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DB'))
def open_spider(self, spider):
'''Spider开启自动调用此方法,负责连接MongoDB,并选择数据库'''
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
'''选择对应集合并写入Item信息'''
self.db[item.collection].insert(dict(item))
return item
def close_spider(self, spider):
'''Spider关闭时自动调用,负责关闭MongoDB的连接'''
self.client.close()
- 修改配置文件settings.py信息:(开启MongoPipeline管道类,设置MongoDB的连接信息)
ITEM_PIPELINES = {
'scrapyseleniumtest.pipelines.MongoPipeline': 300,
}
MONGO_URI = 'localhost'
MONGO_DB = 'taobao'
⑤ 执行爬虫文件开始信息爬取
scrapy crawl wx
- 注意:当前爬取信息过多时会报如下302错误:
2018-05-30 22:40:10 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (
302) to from
 ]
]
⑥ 在中间件中使用付费代理服务来解决上面错误:
# 在middlewares.py文件中定义一个Downloader中间件
import requests
class HttpbinProxyMiddleware(object):
def process_request(self, request, spider):
pro_addr = requests.get('http://tvp.daxiangdaili.com/ip/?tid=559775358931681&num=1').text
request.meta['proxy'] = 'http://' + pro_addr
# 设置启动上面我们写的这个代理
#在settings.py配置文件中.设置我们自定义的Downloader MiddleWares中间件设置:
DOWNLOADER_MIDDLEWARES = {
'httpbin.middlewares.HttpbinProxyMiddleware': 543,
}
练习:没有登录的用户只能看到10页,登陆后才可看到其他页,那么如何实现爬取更多页信息呢?
15. Redis数据库
15.1 Redis简介
- Redis是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
- Redis与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启后可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型(hash)的数据,同时还提供包括string(字符串)、list(链表)、set(集合)和sorted set(有序集合)。
- Redis支持数据的备份,即master-slave模式的数据备份。
- Redis是一个高性能的key-value数据库。
- Redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。
- 它提供了Python,Ruby,Erlang,PHP客户端,使用很方便。
- Redis优势:
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的Strings,Lists,Hashes,Sets及Ordered Sets数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
15.2 Redis的安装:
- 官方网站:https://redis.io
- 官方文档:https://redis.io/documentation
- 中文官网:http://www.redis.cn
- GitHub:https://github.com/antirez/redis
- 可视化管理工具:https://redisdesktop.com/download
- windows下安装地址:https://github.com/MSOpenTech/redis/releases
- 可下载:Redis-x64-3.2.100.msi 直接next按钮安装即可
- 配置文件:redis.windows-service.conf
- Liunx下的安装:(如 ubuntu)
安装命令: sudo apt-get -y install redis-server
进入命令行模式:
$ redis-cli
127.0.0.1:6379> set 'name' 'zhangsan'
ok
127.0.0.1:6379> get 'name'
"zhangsan"
启停Redis服务:
sudo /etc/init.d/redis-server start
sudo /etc/init.d/redis-server stop
sudo /etc/init.d/redis-server restart
- Mac下的安装:
安装命令:brew install redis
启停服务:
brew services start redis
brew services stop redis
brew services restart redis
配置文件:
/usr/local/etc/redis.conf
- redis-py的安装:(python操作redis)
pip install redis
15.3 Redis的操作:
- Redis的数据类型:
- 共计5种类型:string(字符串)、hash(哈希表) list(双向链表)、set(集合)和sorted set(有序集合)
① String(子串类型)
set命令:设置一个键和值,键存在则只覆盖,返回ok
> set 键 值 例如: >set name zhangsan
get命令:获取一个键的值,返回值
> get 键 例如:>get name
setnx命令:设置一个不存在的键和值(防止覆盖),
> setnx 键 值 若键已存在则返回0表示失败
setex命令:设置一个指定有效期的键和值(单位秒)
> setex 键 [有效时间] 值 例如: >setex color 10 red
不写有效时间则表示永久有效,等价于set
setrange命令:替换子字符串 (替换长度由子子串长度决定)
> setrange 键 位置 子字串
> setrange name 4 aa 将name键对应值的第4个位置开始替换
mset命令:批量设置键和值,成功则返回ok
> mset 键1 值1 键2 值2 键3 值3 ....
msetnx命令:批量设置不存在的键和值,成功则返回ok
> msetnx 键1 值1 键2 值2 键3 值3 ....
getset命令:获取原值,并设置新值
getrange命令:获取指定范围的值
>getrange 键 0,4 //获取指定0到4位置上的值
mget命令: 批量获取值
>mget 键1 键2 键3....
incr命令: 指定键的值做加加操作,返回加后的结果。
> 键 例如: >incr kid
incrby命令: 设置某个键加上指定值
> incrby 键 m //其中m可以是正整数或负整数
decr命令: 指定键的值做减减操作,返回减后的结果。
> decr 键 例如: >decr kid
decrby命令: 设置某个键减上指定值
> decrby 键 m //其中m可以是正整数或负整数
append命令:给指定key的字符串追加value,返回新字符串值的长度
>append 键 追加字串
strlen求长度 >strlen 键名 //返回对应的值。
② hash类型:
hset命令:设置一个哈希表的键和值
>hset hash名 键 值
如:>hset user:001 name zhangsan
hsetnx命令:设置一个哈希表中不存在的键和值
>hsetnx hash名 键 值 //成功返回1,失败返回0
如:>hsetnx user:001 name zhangsan
hmset命令: 批量设置
hget命令: 获取执行哈希名中的键对应值
hexists user:001 name //是否存在, 若存在返回1
hlen user:001 //获取某哈希user001名中键的数量
hdel user:001 name //删除哈希user:001 中name键
hkeys user:002 //返回哈希名为user:002中的所有键。
hvals user:002 //返回哈希名为user:002中的所有值。
hgetall user:002 //返回哈希名为user:002中的所有键和值。
③ list类型(双向链表结构)
- list即可以作为“栈”也可以作为"队列"。
>lpush list1 "world" //在list1头部压入一个字串
>lpush list1 "hello" // 在list1头部压入一个字串
>lrange list1 0 -1 //获取list1中内容
0:表示开头 -1表示结尾。
>rpush list2 "world" //在list2尾部压入一个字串
>rpush list2 "hello" // 在list2尾部压入一个字串
>lrange list2 0 -1 //获取list2中内容
0:表示开头 -1表示结尾。
>linsert list2 before "hello" "there"
在key对应list的特定位置前或后添加字符串
>lset list2 1 "four"
修改指定索引位置上的值
>lrem list2 2 "hello" //删除前两个hello值
>lrem list2 -2 "hello" //删除后两个hello值
>lrem list2 0 "hello" //删除所有hello值
>ltrim mylist8 1 -1 //删除此范围外的值
>lpop list2 //从list2的头部删除元素,并返回删除元素
>rpop list2 //从list2的尾部删除元素,并返回删除元素
>rpoplpush list1 list2 //将list1的尾部一个元素移出到list2头部。并返回
>lindex list2 1 //返回list2中索引位置上的元素
>llen list2 //返回list2上长度
④ sets类型和操作:
- Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
- 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
>sadd myset "hello" //向myset中添加一个元素
成功返回1,失败(重复)返回0
>smembers myset //获取myset中的所有元素
>srem myset "one" //从myset中删除一个one
成功返回1,失败(不存在)返回0
>spop myset //随机返回并删除myset中的一个元素
>sdiff myset1 myset2 //返回两个集合的差集
以myset1为标准,获取myset2中不存在的。
> sinter myset2 myset3 交集
> sunion myset2 myset3 并集
> scard myset2 返回元素个数
> sismember myset2 two 判断myset2中是否包含two
⑤ 有序集合(sorted set):
- Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
- 不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
向名称为 key 的 zset 中添加元素 member,score 用于排序。如果该元素已经存在,则根据 score 更新该元素的顺序
redis 127.0.0.1:6379> zadd myzset 1 "one" 添加
(integer) 1
redis 127.0.0.1:6379> zadd myzset 2 "two"
(integer) 1
redis 127.0.0.1:6379> zadd myzset 3 "two"
(integer) 0
redis 127.0.0.1:6379> zrange myzset 0 -1 withscores 查看
1) "one"
2) "1"
3) "two"
4) "3"
redis 127.0.0.1:6379> zrem myzset two 删除
(integer) 1
redis 127.0.0.1:6379> zrange myzset 0 -1 withscores 查看
1) "one"
2) "1"
redis 127.0.0.1:6379>
⑥ Redis常用命令:
1. 键值相关命令
>keys * //返回键(key)
>keys list* //返回名以list开头的所有键(key)
>exists list1 //判断键名为list1的是否存在
存在返回1, 不存在返回0
>del list1 //删除一个键(名为list1)
>expire list1 10 //设置键名为list1的过期时间为10秒后
>ttl list1 //查看键名为list1的过期时间,若为-1表示以过期
>move age 1 //将键名age的转移到1数据库中。
>select 1 //表示进入到1数据库中,默认在0数据库
>persist age //移除age的过期时间(设置为过期)
15.4 Redis高级实用特性
1. 安全性:为Redis添加密码
-------------------------------
1.进入配置文件:
vi /usr/local/redis/etc/redis.conf
设置:requirepass redis的密码
2. 重启服务:
# ./redis-cli shutdown 执行关闭
# ./redis-server /usr/local/redis/etc/redis.conf 启动
3. 登录(两种)
# ./redis-cli 客户端命令链接服务器
>auth 密码值 //授权后方可使用
# ./redis-cli -a 密码 //连接时指定密码来进行授权
2. 主从复制
------------------------------------------
操作步骤:
1.先将linux虚拟机关闭,之后克隆一个。
2.启动两个虚拟机:master(主)和slave(从)
3. 在slave(从)中配置一下ip地址
# ifconfig eth0 192.168.128.229
# ping 一下看看通不通。
4. 配置从机
进入:配置文件
slaveof 192.168.128.228 6379 //配置连接主机的Redis的ip和端口
masterauth 密码 //配置连接密码
最后启动slave(从)机的Redis服务。
其他:可以通过info命令中的role属性查看自己角色是master、slave
3. 事务处理
--------------------------------------------
>multi //开启一个事务
>set age 10 //暂存指令队列
>set age 20
>exec //开始执行(提交事务)
或>discard //清空指令队列(事务回滚)
4. 乐观锁
-----------------------------------
在事务前对被操作的属性做一个:
> watch age
>multi //开启一个事务(在此期间有其他修改,则此处会失败)
>set age 10 //暂存指令队列
>set age 20
>exec //开始执行(提交事务)
或>discard //清空指令队列(事务回滚)
5. 持久化机制(通过修改配置文件做设置)
-----------------------------------
1. snapshotting(快照)默认方式
配置 save
save 900 1 #900秒内如果超过1个key被修改,则发起快照保存
save 300 10 #300秒内容如超过10个key被修改,则发起快照保存
save 60 10000
2. Append-only file(aof方式)
配置 appendonly on 改为yes
会在bin目录下产生一个.aof的文件
关于aof的配置
appendonly yes //启用aof 持久化方式
# appendfsync always //收到写命令就立即写入磁盘,最慢,但是保证完全的持久化
appendfsync everysec //每秒钟写入磁盘一次,在性能和持久化方面做了很好的折中
# appendfsync no //完全依赖os,性能最好,持久化没保证
6. 发布及订阅消息
----------------------
需要开启多个会话端口
会话1:>subscribe tv1 //监听tv1频道
会话2:>subscribe tv1 tv2 //监听tv1和tv2频道
会话3: >publish tv1 消息 //向tv1频道发送一个消息
7. 使用虚拟内存
-------------------------------
在redis配置文件中设置
vm-enabled yes #开启vm功能
vm-swap-file /tmp/redis.swap #交换出来的value保存的文件路径
vm-max-memory 1000000 #redis使用的最大内存上限
vm-page-size 32 #每个页面的大小32字节
vm-pages 134217728 #最多使用多少页面
vm-max-threads 4 #用于执行value对象换入患处的工作线程数量
15.5 Python使用Redis
import redis
# host是redis主机,需要redis服务端和客户端都启动 redis默认端口是6379
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
# 字串操作
r.set('name', 'junxi') # key是"foo" value是"bar" 将键值对存入redis缓存
print(r['name'])
print(r.get('name')) # 取出键name对应的值
print(type(r.get('name')))
# 如果键fruit不存在,那么输出是True;如果键fruit已经存在,输出是None
print(r.set('fruit', 'watermelon', nx=True)) # True--不存在
print(r.setnx('fruit1', 'banana')) # fruit1不存在,输出为True
#设置过期时间
r.setex("fruit2", "orange", 5)
time.sleep(5)
print(r.get('fruit2')) # 5秒后,取值就从orange变成None
print(r.mget("fruit", "fruit1", "fruit2", "k1", "k2")) # 将目前redis缓存中的键对应的值批量取出来
redis操作hash哈希
r.hset("hash1", "k1", "v1")
r.hset("hash1", "k2", "v2")
print(r.hkeys("hash1")) # 取hash中所有的key
print(r.hget("hash1", "k1")) # 单个取hash的key对应的值
print(r.hmget("hash1", "k1", "k2")) # 多个取hash的key对应的值
r.hsetnx("hash1", "k2", "v3") # 只能新建
print(r.hget("hash1", "k2"))
#hash的批量操作
r.hmset("hash2", {
"k2": "v2", "k3": "v3"})
print(r.hget("hash2", "k2")) # 单个取出"hash2"的key-k2对应的value
print(r.hmget("hash2", "k2", "k3")) # 批量取出"hash2"的key-k2 k3对应的value --方式1
print(r.hmget("hash2", ["k2", "k3"])) # 批量取出"hash2"的key-k2 k3对应的value --方式2
print(r.hgetall("hash1")) #取出所有的键值对
redis操作list链表
r.lpush("list1", 11, 22, 33)
print(r.lrange('list1', 0, -1))
r.rpush("list2", 11, 22, 33) # 表示从右向左操作
print(r.llen("list2")) # 列表长度
print(r.lrange("list2", 0, 3)) # 切片取出值,范围是索引号0-3
r.rpush("list2", 44, 55, 66) # 在列表的右边,依次添加44,55,66
print(r.llen("list2")) # 列表长度
print(r.lrange("list2", 0, -1)) # 切片取出值,范围是索引号0到-1(最后一个元素)
r.lset("list2", 0, -11) # 把索引号是0的元素修改成-11
print(r.lrange("list2", 0, -1))
r.lrem("list2", "11", 1) # 将列表中左边第一次出现的"11"删除
print(r.lrange("list2", 0, -1))
r.lrem("list2", "99", -1) # 将列表中右边第一次出现的"99"删除
print(r.lrange("list2", 0, -1))
r.lrem("list2", "22", 0) # 将列表中所有的"22"删除
print(r.lrange("list2", 0, -1))
r.lpop("list2") # 删除列表最左边的元素,并且返回删除的元素
print(r.lrange("list2", 0, -1))
r.rpop("list2") # 删除列表最右边的元素,并且返回删除的元素
print(r.lrange("list2", 0, -1))
print(r.lindex("list2", 0)) # 取出索引号是0的值
redis操作set集合
#新增
r.sadd("set1", 33, 44, 55, 66) # 往集合中添加元素
print(r.scard("set1")) # 集合的长度是4
print(r.smembers("set1")) # 获取集合中所有的成员
print(r.sscan("set1")) #获取集合中所有的成员--元组形式
for i in r.sscan_iter("set1"):
print(i)
#差集
r.sadd("set2", 11, 22, 33)
print(r.smembers("set1")) # 获取集合中所有的成员
print(r.smembers("set2"))
print(r.sdiff("set1", "set2")) # 在集合set1但是不在集合set2中
print(r.sdiff("set2", "set1")) # 在集合set2但是不在集合set1中
16. 分布式爬虫原理
- 在前面我们已经掌握了Scrapy框架爬虫,虽然爬虫是异步多线程的,但是我们只能在一台主机上运行,爬取效率还是有限。
- 分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,将大大提高爬取的效率。
16.1 分布式爬虫架构
- 回顾Scrapy的架构:
- Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。
- 如果有新的Request产生,就会放到队列里面,随后Request被Scheduler调度。
- 之后Request交给Downloader执行爬取,这就是简单的调度架构。
- 我们需要做的就是在多台主机上同时运行爬虫任务
 ]
]
16.2 维护爬取队列
- 关于爬取队列我们自然想到的是基于内存存储的Redis。它支持多种数据结构,如:列表、集合、有序集合等,存取的操作也非常简单。
- Redis支持的这几种数据结构,在存储中都有各自优点:
- 列表(list)有lpush()、lpop()、rpush()、rpop()方法,可以实现先进先出的队列和先进后出的栈式爬虫队列。
- 集合(set)的元素是无序且不重复的,这样我们可以非常方便的实现随机且不重复的爬取队列。
- 有序集合有分数表示,而Scrapy的Request也有优先级的控制,我们可以用它来实现带优先级调度的队列。
16.3 如何去重
- Scrapy有自动去重,它的去重使用了Python中的集合实现。用它记录了Scrapy中每个Request的指纹(Request的散列值)。
- 对于分布式爬虫来说,我们肯定不能再用每个爬虫各自的集合来去重了,因为不能共享,各主机之间就无法做到去重了。
- 可以使用Redis的集合来存储指纹集合,那么这样去重集合也是利用Redis共享的。
- 每台主机只要将新生成Request的指纹与集合比对,判断是否重复并选择添加入到其中。即实例了分布式Request的去重。
16.4 防止中断
-
在Scrapy中,爬虫运行时的Request队列放在内存中。爬虫运行中断后,这个队列的空间就会被释放,导致爬取不能继续。
-
要做到中断后继续爬取,我们可以将队列中的Request保存起来,下次爬取直接读取保存的数据既可继续上一次爬取的队列。
-
在Scrapy中制定一个爬取队列的存储路径即可,这个路径使用
JOB_DIR变量来标识,命令如下:
scrapy crawl spider -s JOB_DIR=crawls/spider -
更多详细使用请详见官方文档:http://doc.scrapy.org/en/latest/topics/jobs.html
-
在Scrapy中,我们实际是把爬取队列保存到本地,第二次爬取直接读取并恢复队列既可。
-
在分布式框架中就不用担心这个问题了,因为爬取队列本身就是用数据库存储的,中断后再启动就会接着上次中断的地方继续爬取。
-
当Redis的队列为空时,爬虫会重新爬取;当队列不为空时,爬虫便会接着上次中断支处继续爬取。
16.5 架构实现
- 首先实现一个共享的爬取队列,还要实现去重的功能。
- 重写一个Scheduer的实现,使之可以从共享的爬取队列存取Request
- 幸运的是,我们可以下载一个现成
Scrapy-Redis分布式爬虫的开源包,直接使用就可以很方便实现分布式爬虫。
17. Scrapy分布式实战
- Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。
- scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
 ]
]
17.1 准备
-
既然这么好能实现分布式爬取,那都需要准备什么呢?
-
需要准备的东西比较多,都有:
- scrapy
- scrapy-redis
- redis
- mysql
- python的mysqldb模块
- python的redis模块
-
为什么要有mysql呢?是因为我们打算把收集来的数据存放到mysql中
-
安装:
$ pip install scrapy-redis $ pip install redis -
Scrapy-Redis的官方网址:https://github.com/rmax/scrapy-redis
17.2 Scrapy-redis各个组件介绍
① connection.py
- 负责根据setting中配置实例化redis连接。被dupefilter和scheduler调用,总之涉及到redis存取的都要使用到这个模块。
② dupefilter.py
- 负责执行requst的去重,实现的很有技巧性,使用redis的set数据结构。
- 但是注意scheduler并不使用其中用于在这个模块中实现的dupefilter键做request的调度,而是使用queue.py模块中实现的queue。
- 当request不重复时,将其存入到queue中,调度时将其弹出。
③ queue.py
- 其作用如II所述,但是这里实现了三种方式的queue:
- FIFO的SpiderQueue,SpiderPriorityQueue,以及LIFI的SpiderStack。默认使用的是第二中,这也就是出现之前文章中所分析情况的原因(链接)。
④ pipelines.py
- 这是是用来实现分布式处理的作用。它将Item存储在redis中以实现分布式处理。
- 另外可以发现,同样是编写pipelines,在这里的编码实现不同于文章(链接:)中所分析的情况,由于在这里需要读取配置,所以就用到了from_crawler()函数。
⑤ scheduler.py
- 此扩展是对scrapy中自带的scheduler的替代(在settings的SCHEDULER变量中指出),正是利用此扩展实现crawler的分布式调度。其利用的数据结构来自于queue中实现的数据结构。
- scrapy-redis所实现的两种分布式:爬虫分布式以及item处理分布式就是由模块scheduler和模块pipelines实现。上述其它模块作为为二者辅助的功能模块。
⑥ spider.py
- 设计的这个spider从redis中读取要爬的url,然后执行爬取,若爬取过程中返回更多的url,那么继续进行直至所有的request完成。之后继续从redis中读取url,循环这个过程。
17.3 具体使用(对Scrapy改造):
1.首先在settings.py中配置redis(在scrapy-redis 自带的例子中已经配置好)
# 指定使用scrapy-redis的去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilters.RFPDupeFilter'
# 指定使用scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
# 指定排序爬取地址时使用的队列,
# 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
REDIS_URL = None # 一般情况可以省去
REDIS_HOST = '127.0.0.1' # 也可以根据情况改成 localhost
REDIS_PORT = 6379
2.item.py的改造
from scrapy.item import Item, Field
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, TakeFirst, Join
class ExampleItem(Item):
name = Field()
description = Field()
link = Field()
crawled = Field()
spider = Field()
url = Field()
class ExampleLoader(ItemLoader):
default_item_class = ExampleItem
default_input_processor = MapCompose(lambda s: s.strip())
default_output_processor = TakeFirst()
description_out = Join()
3.spider的改造。star_turls变成了redis_key从redis中获得request,继承的scrapy.spider变成RedisSpider。
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'myspider_redis'
redis_key = 'myspider:start_urls'
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(MySpider, self).__init__(*args, **kwargs)
def parse(self, response):
return {
'name': response.css('title::text').extract_first(),
'url': response.url,
}
启动爬虫:
$ scrapy runspider my.py
可以输入多个来观察多进程的效果。。打开了爬虫之后你会发现爬虫处于等待爬取的状态,是因为list此时为空。所以需要在redis控制台中添加启动地址,这样就可以愉快的看到所有的爬虫都动起来啦。
lpush mycrawler:start_urls http://www.***.com
更多关于配置Scrapy框架中配置:settings.py
# 指定使用scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 指定使用scrapy-redis的去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilters.RFPDupeFilter'
# 指定排序爬取地址时使用的队列,
# 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# 可选的 按先进先出排序(FIFO)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderQueue'
# 可选的 按后进先出排序(LIFO)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderStack'
# 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
# 只在使用SpiderQueue或者SpiderStack是有效的参数,指定爬虫关闭的最大间隔时间
# SCHEDULER_IDLE_BEFORE_CLOSE = 10
# 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item
# 这个已经由 scrapy-redis 实现,不需要我们写代码
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400
}
# 指定redis数据库的连接参数
# REDIS_PASS是我自己加上的redis连接密码(默认不做)
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
#REDIS_PASS = 'redisP@ssw0rd'
# LOG等级
LOG_LEVEL = 'DEBUG'
#默认情况下,RFPDupeFilter只记录第一个重复请求。将DUPEFILTER_DEBUG设置为True会记录所有重复的请求。
DUPEFILTER_DEBUG =True
# 覆盖默认请求头,可以自己编写Downloader Middlewares设置代理和UserAgent
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Accept-Encoding': 'gzip, deflate, sdch'
}
17.4 实战案例:
- 案例:实现主从分布式爬虫,爬取5i5j的楼盘信息
- URL地址:https://fang.5i5j.com/bj/loupan/
- 准备工作:
- 开启redis数据库服务
- 将第二节
Scrapy框架的使用中的案例demo复制过来两份:master(主)、slave(从)
 ]
]
① 编写slave(从)项目代码:
- 查看items.py 保持不变:
import scrapy
class FangItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
address = scrapy.Field()
time = scrapy.Field()
clicks = scrapy.Field()
price = scrapy.Field()
- 编辑爬虫文件:fang.py
# -*- coding: utf-8 -*-
import scrapy
from demo.items import FangItem
from scrapy_redis.spiders import RedisSpider
class FangSpider(RedisSpider):
name = 'fang'
#allowed_domains = ['fang.5i5j.com']
#start_urls = ['https://fang.5i5j.com/bj/loupan/']
redis_key = 'fangspider:start_urls'
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(FangSpider, self).__init__(*args, **kwargs)
def parse(self, response):
#print(response.status)
hlist = response.css("div.houseList_list")
for vo in hlist:
item = FangItem()
item['title'] = vo.css("h3.fontS20 a::text").extract_first()
item['address'] = vo.css("span.addressName::text").extract_first()
item['time'] = vo.re("(.*?)开盘")[0]
item['clicks'] = vo.re("([0-9]+)浏览")[0]
item['price'] = vo.css("i.fontS24::text").extract_first()
print(item)
yield item
#pass
- 查看pipelines.py保持不变
class DemoPipeline(object):
def process_item(self, item, spider):
print("="*70)
return item
- 编辑配置文件:settings.py配置文件:
...
ITEM_PIPELINES = {
#'demo.pipelines.DemoPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
...
# 指定使用scrapy-redis的去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
# 指定使用scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
# 指定排序爬取地址时使用的队列,
# 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# REDIS_URL = 'redis://localhost:6379' # 一般情况可以省去
REDIS_HOST = 'localhost' # 也可以根据情况改成 localhost
REDIS_PORT = 6379
- 测试:爬取具体房屋信息
# 进入爬虫文件目录找到爬虫文件:
$ scrapy runspider fang.py
另启一个终端,并连接redis数据库
$ redis_cli -p 6379
6379 >lpush fangspider:start_urls https://fang.5i5j.com/bj/loupan/
② 编写master(主)项目代码:
- 编辑items.py 储存url地址:
import scrapy
class MasterItem(scrapy.Item):
# define the fields for your item here like:
url = scrapy.Field()
#pass
- 编辑爬虫文件:fang.py
# -*- coding: utf-8 -*-
from scrapy.spider import CrawlSpider,Rule
from scrapy.linkextractors import LinkExtractor
from demo.items import MasterItem
class FangSpider(CrawlSpider):
name = 'master'
allowed_domains = ['fang.5i5j.com']
start_urls = ['https://fang.5i5j.com/bj/loupan/']
item = MasterItem()
#Rule是在定义抽取链接的规则
rules = (
Rule(LinkExtractor(allow=('https://fang.5i5j.com/bj/loupan/n[0-9]+/',)), callback='parse_item',
follow=True),
)
def parse_item(self,response):
item = self.item
item['url'] = response.url
return item
- 编辑pipelines.py负责存储爬取的url地址到redis中:
import redis,re
class MasterPipeline(object):
def __init__(self,host,port):
#连接redis数据库
self.r = redis.Redis(host=host, port=port, decode_responses=True)
#self.redis_url = 'redis://password:@localhost:6379/'
#self.r = redis.Redis.from_url(self.redis_url,decode_responses=True)
@classmethod
def from_crawler(cls,crawler):
'''注入实例化对象(传入参数)'''
return cls(
host = crawler.settings.get("REDIS_HOST"),
port = crawler.settings.get("REDIS_PORT"),
)
def process_item(self, item, spider):
#使用正则判断url地址是否有效,并写入redis。
if re.search('/bj/loupan/',item['url']):
self.r.lpush('fangspider:start_urls', item['url'])
else:
self.r.lpush('fangspider:no_urls', item['url'])
- 编辑配置文件:settings.py配置文件:
ITEM_PIPELINES = {
'demo.pipelines.MasterPipeline': 300,
#'scrapy_redis.pipelines.RedisPipeline': 400,
}
...
# 指定使用scrapy-redis的去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
# 指定使用scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
# 指定排序爬取地址时使用的队列,
# 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# REDIS_URL = 'redis:password//127.0.0.1:6379' # 一般情况可以省去
REDIS_HOST = '127.0.0.1' # 也可以根据情况改成 localhost
REDIS_PORT = 6379
- 测试:爬取更多的url地址:
# 进入爬虫文件目录找到爬虫文件:
$ scrapy runspider fang.py
17.5 处理的Redis里的数据:
- 网站的数据爬回来了,但是放在Redis里没有处理。之前我们配置文件里面没有定制自己的ITEM_PIPELINES,而是使用了RedisPipeline,所以现在这些数据都被保存在redis的demo:items键中,所以我们需要另外做处理。
- 在scrapy-youyuan目录下可以看到一个process_items.py文件,这个文件就是scrapy-redis的example提供的从redis读取item进行处理的模版。
- 假设我们要把demo:items中保存的数据读出来写进MongoDB或者MySQL,那么我们可以自己写一个process_demo_profile.py文件,然后保持后台运行就可以不停地将爬回来的数据入库了。
存入的MongoDB
- 启动的MongoDB数据库:sudo mongod
- 执行下面程序:python process_demo_mongodb.py
# process_demo_mongodb.py
import json
import redis
import pymongo
def main():
# 指定Redis数据库信息
rediscli = redis.StrictRedis(host='127.0.0.1', port=6379, db=0)
# 指定MongoDB数据库信息
mongocli = pymongo.MongoClient(host='localhost', port=27017)
# 创建数据库名
db = mongocli['demodb']
# 创建空间
sheet = db['fang']
while True:
# FIFO模式为 blpop,LIFO模式为 brpop,获取键值
source, data = rediscli.blpop(["demo:items"])
item = json.loads(data)
sheet.insert(item)
try:
print u"Processing: %(name)s <%(link)s>" % item
except KeyError:
print u"Error procesing: %r" % item
if __name__ == '__main__':
main()
十一、Python网络爬虫进阶实战(下)
18. App的信息爬取
- 之前我们讲解的都是Web网页信息爬取,随着移动互联的发展,越来越多的企业并没有提供Web网页端的服务,而是直接开发App。
- App的爬取相比Web端爬取更加容易,反爬中能力没有那么强,而且响应数据大多都是JSON形式,解析更加简单。
- 在APP端若想查看和分析内容那就需要借助抓包软件,常用的有:Filddler、Charles、mitmproxy、Appium等。
- mitmproxy是一个支持HTTP/HTTPS协议的抓包程序,类似Fiddler、Charles的功能,只不过世它通过控制台的形式操作。
 ]
] - Appium是移动端的自动化测试工具,类似于前面所说的Selenium、利用它可以驱动Android、IOS等设备完成自动化测试。
 ]
]
18.1 Charles的介绍
- Charles是一个网络抓包工具,可以完成App的抓包分析,能够得到App运行过程中发生的所有网络请求和响应内容。
- 相关连接:
- 官方网站:https://www.charlesproxy.com
- 下载链接:https://www.charlesproxy.com/download
 ]
]
Charles主要功能:
* 支持SSL代理。可以截取分析SSL的请求。
* 支持流量控制。可以模拟慢速网络以及等待时间(latency)较长的请求。
* 支持AJAX调试。可以自动将json或xml数据格式化,方便查看。
* 支持AMF调试。可以将Flash Remoting 或 Flex Remoting信息格式化,方便查看。
* 支持重发网络请求,方便后端调试。
* 支持修改网络请求参数。
* 支持网络请求的截获并动态修改。
* 检查HTML,CSS和RSS内容是否符合W3C标准。
 ]
]
18.2 Charles的配置
① 网络共享配置:
- 实现手机通过电脑上网:就是电脑通过网线上网,然后共享Wifi,手机在链接此wifi。
- 查看本机电脑的网络链接:
 ]
] - 共享wifi设置:
 ]
] - 手机链接此wifi,实现手机和电脑连接到同一个局域下
 ]
]
- 查看本机电脑的网络链接:
② 代理设置:
-
实现手机和电脑在同一局域网下的机上,完成Charles的代理设置:
-
首先查看电脑的打开Charles代理是否开启,具体操作是:
Proxy->Proxy Settings,打开代理设置界面,设置代理端口为:8888. ]
] -
打开手机的网络配置,并设置使用代理配置:
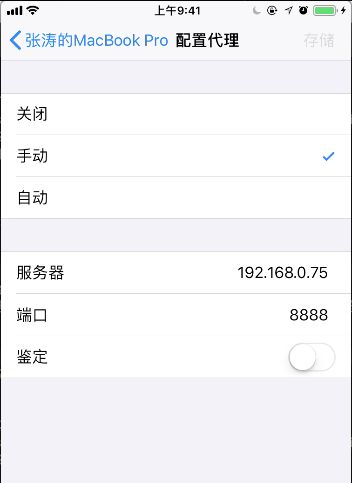 ]
]
-
③ 证书配置:
-
安装完成后,我们还需要配置相关SSL证书 来抓取HTTPS协议的信息包。
-
Windows系统:
- 首先打开Charles,点击
Help->SSL Proxying->Install Charles Root Certificate,即可进入证书安装界面。 - 点击 “安装证书” 按钮,就会打开证书导入向导。
- 点击 “下一步” 按钮,此时需要选择证书存储区域“将所有证书放入下列存储”->点击"浏览"->选择“受信任的证书颁发机构”->“确定”->“下一步”->完成。
- 首先打开Charles,点击
-
Mac系统:
- 首先打开Charles,点击
Help->SSL Proxying->Install Charles Root Certificate,即可进入证书安装界面。 - 接下来,找到Charles的证书并双击,将 “信任” 设置为 “始终信任”即可 。
- 首先打开Charles,点击
-
IOS手机:-
在网络配置和代理开启的情况下,若是你的手机是IOS系统,可以按照下面的操作进行证书配置。
-
在手机浏览器上打开chls.pro/ssl后,便会打开证书安装页面,点击安装即可。
 ]
] -
在IOS手机上,点击“设置”->“通用”->“关于本机”->“证书信任设置”,设置开启即可。
 ]
]
-
⑤ Charles 配置 HTTPS 代理的乱码问题
-
在 Charles 设置 SSL 代理:
-
Proxy –> SSL Proxying Setting –> Enable SSL Proxying
 ]
] ]
]
-
18.3 Charles的运行原理和具体使用
① 运行原理:
- 首先Charles运行在自己的PC上,Charles运行的时候会在PC的8888端口开启一个代理服务,这就是一个HTTP/HTTPS的代理。
- 确保手机和PC在同一个局域网内,我们可以使用手机模拟器通过虚拟网络连接,也可使用手机真机和PC通过无线网连接。
- 设置手机代理为Charles的代理地址,这样手机访问互联网的数据包就会流经Charles,Charles再转发这些数据包到真实的服务器,同理相反也是如此。
② 具体使用
- 手机运行App访问要爬取的平台信息,使用Charles抓包分析。
- 知道了请求和响应的具体信息,通过分析得到请求的URL地址和参数的规律,直接使用程序模拟即可批量爬取。
 ]
]
19. mitmproxy的使用
- mitmproxy是一个支持HHTP/HTTPS协议的抓包程序,类似Fiddler、Charles的功能,只不过世它通过控制台的形式操作。
- mitmproxy还有两个关联组件:
- mitmdump:它是mitmproxy的命令行接口,利用它我们可以对接Python脚本,用Python实现监听后的处理。
- mitmweb: 它是一个Web程序,通过它我们可以清楚观察mimproxy捕获的请求。
- mitmproxy的功能:
- 拦截HTTP和HTTPS请求和响应
- 保存HTTP会话请进行分析
- 模拟客户端请求,模拟服务器返回响应
- 利用反向代理将流量转发给指定的服务器
- 支持Mac和Linux上的透明代理
- 利用Python对HTTP请求和响应进行实时处理
19.1 安装和配置:
- 安装:完成mitmproxy的安装,另外还附带安装了mitmdump和mimweb这两个组件
pip3 install mitmproxy
-
配置手机和PC处于同一局域网下:(具体步骤详见上一节内容)
-
打开手机的网络配置,并设置使用代理配置,端口监听
8080:(具体步骤详见上一节内容) -
配置mitmproxy的CA证书。
-
对于mitmproxy来说,如果想要截获HTTPS请求,就需要设置CA证书,而mitmproxy安装后就会提供一套CA证书,只要客户信任了此证书即可。
-
首先运行启动
mitmdump,就会在此命令下产生CA证书,我们可以从用户目录下的.mitmproxy目录下看到。localhost:app zhangtao$ mitmdump Proxy server listening at http://*:8080 ]
] -
文件说明:
mitmproxy-ca.pemPEM格式的证书私钥mitmproxy-ca-cert.pemPEM格式证书,适用于大多数非Windows平台mitmproxy-ca-cert.p12PKCS12格式的证书,适用于大多数Windows平台mitmproxy-ca-cert.cer与mitmproxy-ca-cert.pem相同(只是后缀名不同),适用于大部分Android平台mitmproxy-dhparam.pemPEM格式的秘钥文件,用于增强SSL安全性。
-
在Mac系统下双击
mitmproxy-ca-cert.pem即可弹出秘钥串管理页面,找到mitmproxy证书,打开设置选项,选择始终信任即可。 ]
] -
将
mitmproxy-ca-cert.pem文件发送到iPhone手机上,点击安装就可以了(在IOS上通过AirDrop共享过去的)。 ]
] -
在iphone上安装CA证书(Android手机直接复制文件点击安装即可)
 ]
] -
在IOS手机上,点击“设置” - > “通用” - > “关于本机” - > “证书信任设置”,设置开启即可
 ]
]
-
19.2 mitmproxy的使用:
- 运行
mitmproxy命令就会打开一个监听窗口,此窗口就会输出一个App请求中的信息。
localhost:app zhangtao$ mitmproxy
 ]
]
- mitmproxy的按键操作说明
| 按键 | 说明 |
|---|---|
| q | 退出(相当于返回键,可一级一级返回) |
| d | 删除当前(黄色箭头)指向的链接 |
| D | 恢复刚才删除的请求 |
| G | 跳到最新一个请求 |
| g | 跳到第一个请求 |
| C | 清空控制台(C是大写) |
| i | 可输入需要拦截的文件或者域名(逗号需要用\来做转译,栗子:feezu.cn) |
| a | 放行请求 |
| A | 放行所有请求 |
| ? | 查看界面帮助信息 |
| ^ v | 上下箭头移动光标 |
| enter | 查看光标所在列的内容 |
| tab | 分别查看 Request 和 Response 的详细信息 |
| / | 搜索body里的内容 |
| esc | 退出编辑 |
| e | 进入编辑模式 |
19.3 mitmdump的使用:
- mitmdump是mitmproxy的命令行接口,同时还可以对接Python对请求进行处理。
- 使用命令启动mitmproxy,并将截获的数据保存到指定文件中,命令如下:
mitmdump -w outfile
- 使用指定命令截获的数据,如指定处理脚本文件为script.py.
mitmdump -s script.py
- 日志输出:
from mitmproxy import ctx
def request(flow):
# 修改请求头
flow.request.headers['User-Agent'] = 'MitmProxy'
ctx.log.info(str(flow.request.headers))
ctx.log.warn(str(flow.request.headers))
ctx.log.error(str(flow.request.headers))
- Request请求
from mitmproxy import ctx
# 所有的请求都会经过request
def request(flow):
info = ctx.log.info
# info(flow.request.url)
# info(str(flow.request.headers))
# info(str(flow.request.cookies))
# info(flow.request.host)
# info(flow.request.method)
# info(str(flow.request.port))
# info(flow.request.scheme)
print(flow.request.method,":",flow.request.url)
- Response响应
from mitmproxy import ctx
# 所有的请求都会经过request
def response(flow):
info = ctx.log.info
# info(flow.response.url)
# info(str(flow.response.headers))
# info(str(flow.response.cookies))
info(str(flow.response.status_code))
# info(str(flow.response.text))
- 运行手机浏览器访问:
http://httpbin.org/get测试:
20. App信息抓取实战
① 抓取目标:
-
我们的抓取目标是京东商城的App电子商品信息,并将信息保存到MongoDB数据库中。
-
我们将商品信息的id号、标题、单价、评价条数等信息
 ]
]
② 准备工作和抓取分析
-
准备工作:
- 安装app抓包工具Charles、mitmproxy。
- 配置网络,确认手机和PC处于同一局域网下,并配置好代理服务
- 安装证书,确保可以抓取HTTPS的请求信息。
- 安装并开启MongoDB数据库。
-
抓取分析:
-
打开iCharles抓包工具,让后使用手机打开京东App应用程序,让后搜索
电脑商品信息。 -
在抓包工具中获取url地址:
http://api.m.jd.com/client.action?functionId=search -
抓取信息格式为json格式。具体如下图所示
 ]
]
-
③ 代码编写:
import json
#import pymongo
from mitmproxy import ctx
#连接MongoDB数据库jddb,选择集合shop
#client = pymongo.MongoClient('localhost')
#db = client['jddb']
#collection = db['shop']
def response(flow):
#global collection
url = 'http://api.m.jd.com/client.action?functionId=search'
if flow.request.url.startswith(url):
text = flow.response.text
data = json.loads(text)
shops = data.get('wareInfo')
for shop in shops:
item = {
'spuId': shop.get('spuId'),
'wname': shop.get('wname'),
'price': shop.get('jdPrice'),
'reviews': shop.get('reviews')
}
ctx.log.info(str(item))
#写入MongoDB数据库
#collection.insert(data)
- 测试运行:
mitmdump -s script.py
 ]
]
21. 从API爬取天气预报数据
21.1 注册免费API和阅读文档
- 本节通过一个API接口(和风天气预报)爬取天气信息,该接口为个人开发者提供了一个免费的预报数据(有次数限制)。
- 首先访问和风天气网,注册一个账户。注册地址:https://console.heweather.com/
 ]
]
- 在登陆后的控制台中可以看到个人认证的key(密钥),这个key就是访问API接口的钥匙。
 ]
]
- 获取key之后阅读API文档:https://www.heweather.com/documents/api/s6
 ]
]
21.2 提取全国城市信息
- 通过API接口提取
3181个城市信息。URL地址:https://cdn.heweather.com/china-city-list.txt
 ]
]
# 从网上读取城市列表信息,并使用正则将数据解析出来。
import requests
import re
# 爬取城市信息列表
url = "https://cdn.heweather.com/china-city-list.txt"
res = requests.get(url)
data = res.content.decode('utf-8')
# 使用换行符拆分出每一条城市信息数据
dlist = re.split('[\n\r]+',data)
# 剔除前两条无用的数据
for i in range(2):
dlist.remove(dlist[0])
# 输出城市信息条数
print(len(dlist))
# 输出前20条信息
for i in range(20):
#使用空白符拆分出每个字段信息
item = re.split("\s+",dlist[i])
#输出
#print(item)
print(item[0],":",item[2])
21.3 获取指定城市的天气信息
- 此文档:https://www.heweather.com/documents/api/s6/weather
- 免费获取天气信息接口地址:https://free-api.heweather.com/s6/weather?location=城市&key=用户认证key
 ]
]
- 抓取指定城市天气信息
import requests
import time
#爬取指定城市的天气信息
url = "https://free-api.heweather.com/s6/weather?location=北京&key=a46fd5c4f1b54fda9ee71ba6711f09cd"
res = requests.get(url)
time.sleep(2)
#解析json数据
dlist = res.json()
data = dlist['HeWeather6'][0]
#输出部分天气信息
print("城市:",data['basic']['location'])
print("今日:",str(data['daily_forecast'][0]['date']))
print("温度:",data['daily_forecast'][0]['tmp_min'],"~",data['daily_forecast'][0]['tmp_max'])
print(data['daily_forecast'][0]['cond_txt_d']," ~ ",data['daily_forecast'][0]['cond_txt_n'])
print(data['daily_forecast'][0]['wind_dir'],data['daily_forecast'][0]['wind_sc'],'级')
- 输出结果:
城市: 北京
今日: 2018-06-13
温度: 18 ~ 28
雷阵雨 ~ 多云
东北风 1-2 级
21.4 综合实例
- 获取城市信息,并通过信息获取对应的天气信息。
# 从网上读取城市列表信息,并遍历部分城市信息,从API接口中爬取天气信息。
import requests
import re
import time
# 爬取城市信息列表
url = "https://cdn.heweather.com/china-city-list.txt"
res = requests.get(url)
data = res.content.decode('utf-8')
# 使用换行符拆分出每一条城市信息数据
dlist = re.split('[\n\r]+',data)
# 剔除前两条无用的数据
for i in range(2):
dlist.remove(dlist[0])
# 输出城市信息条数
print(len(dlist))
# 输出前10条信息
for i in range(10):
#使用空白符拆分出每个字段信息
item = re.split("\s+",dlist[i])
#输出
#print(item)
#print(item[0],":",item[2])
#爬取指定城市的天气信息
url = "https://free-api.heweather.com/s6/weather?location=%s&key=a46fd5c4f1b54fda9ee71ba6711f09cd"%(item[0])
res = requests.get(url)
time.sleep(2)
#解析json数据
datalist = res.json()
data = datalist['HeWeather6'][0]
#输出部分天气信息
print("城市:",data['basic']['location'])
print("今日:",str(data['daily_forecast'][0]['date']))
print("温度:",data['daily_forecast'][0]['tmp_min'],"~",data['daily_forecast'][0]['tmp_max'])
print(data['daily_forecast'][0]['cond_txt_d']," . ",data['daily_forecast'][0]['cond_txt_n'])
print(data['daily_forecast'][0]['wind_dir'],data['daily_forecast'][0]['wind_sc'],'级')
print("="*70)
- 结果:
3181
城市: 北京
今日: 2018-06-13
温度: 18 ~ 28
雷阵雨 . 多云
东北风 1-2 级
======================================================================
城市: 海淀
今日: 2018-06-14
温度: 18 ~ 30
多云 . 多云
南风 1-2 级
======================================================================
城市: 朝阳
... ...
22. 滑动验证码的识别
22.1 滑动验证码的识别介绍
- 本节目标:用程序识别极验滑动验证码的验证,包括分析识别思路、识别缺口位置、生成滑块拖动路径、模拟实现滑块拼合通过验证等步骤。
- 准备工作:本次案例我们使用Python库是Selenium,浏览器为Chrome。请确保已安装Selenium库和ChromeDriver浏览器驱动。
- 了解极验滑动验证码:
- 极验滑动验证码官网为:http://www.geetest.com/
- 验证方式为拖动滑块拼合图像,若图像完全拼合,则验证成功,否则需要重新验证,如图所示:
 ]
]
- 接下来我们链接地址:
https://account.geetest.com/login,打开极验的管理后台登录页面,完成自动化登录操作。
22.2 实现步骤:
① 初始化
- 初始化链接地址、创建模拟浏览器对象、设置登录账户和密码等信息。
EMAIL = '登录账户'
PASSWORD = '登录密码'
class CrackGeetest():
def __init__(self):
self.url = 'https://account.geetest.com/login'
self.browser = webdriver.Chrome()
#设置显示等待时间
self.wait = WebDriverWait(self.browser, 20)
self.email = EMAIL
self.password = PASSWORD
def crack():
pass
# 程序主入口
if __name__ == '__main__':
crack = CrackGeetest()
crack.crack()
② 模拟登录填写,点开滑块验证
- 在实例化CrackGeetest对象后调用crack()方法开始模拟登录验证…
- 调用open()方法,打开登录界面,获取账户和密码输入框节点,完成账户和密码的输入。
- 调用get_geetest_button()方法获取滑动验证按钮,并点击。
class CrackGeetest():
#...
def get_geetest_button(self):
''' 获取初始验证按钮,return:按钮对象 '''
button = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'geetest_radar_tip')))
return button
def open(self):
''' 打开网页输入用户名密码, return: None '''
self.browser.get(self.url)
email = self.wait.until(EC.presence_of_element_located((By.ID, 'email')))
password = self.wait.until(EC.presence_of_element_located((By.ID, 'password')))
email.send_keys(self.email)
password.send_keys(self.password)
def crack(self):
# 输入用户名密码
self.open()
# 点击验证按钮
button = self.get_geetest_button()
button.click()
#...
#...
③ 获取并储存有无缺口的两张图片
- 首先获取无缺口的验证图片,并保存到本地
- 获取滑块对象,并执行点击,让浏览器中显示有缺口图片
- 获取有缺口的验证图片,并保存到本地
def get_position(self):
''' 获取验证码位置, return: 验证码位置(元组) '''
img = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'geetest_canvas_img')))
time.sleep(2)
location = img.location
size = img.size
top,bottom,left,right = location['y'],location['y']+size['height'],location['x'],location['x']+size['width']
return (top, bottom, left, right)
def get_screenshot(self):
''' 获取网页截图, return: 截图对象 '''
#浏览器截屏
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
return screenshot
def get_geetest_image(self, name='captcha.png'):
''' 获取验证码图片, return: 图片对象 '''
top, bottom, left, right = self.get_position()
print('验证码位置', top, bottom, left, right)
screenshot = self.get_screenshot()
#从网页截屏图片中裁剪处理验证图片
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha
def get_slider(self):
''' 获取滑块, return: 滑块对象 '''
slider = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'geetest_slider_button')))
return slider
def crack(self):
#...
# 获取验证码图片
image1 = self.get_geetest_image('captcha1.png')
# 点按呼出缺口
slider = self.get_slider()
slider.click()
# 获取带缺口的验证码图片
image2 = self.get_geetest_image('captcha2.png')
#...
④ 获取缺口位置
- 对比两张图片的所有RBG像素点,得到不一样像素点的x值,即要移动的距离
BORDER = 6
INIT_LEFT = 60
class CrackGeetest():
def get_gap(self, image1, image2):
''' 获取缺口偏移量, 参数:image1不带缺口图片、image2带缺口图片。返回偏移量 '''
left = 65
for i in range(left, image1.size[0]):
for j in range(image1.size[1]):
if not self.is_pixel_equal(image1, image2, i, j):
left = i
return left
return left
def is_pixel_equal(self, image1, image2, x, y):
'''
判断两个像素是否相同
:param image1: 图片1
:param image2: 图片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
'''
# 取两个图片的像素点(R、G、B)
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 60
if abs(pixel1[0]-pixel2[0])<threshold and abs(pixel1[1]-pixel2[1])<threshold and abs(pixel1[2]-pixel2[2])<threshold:
return True
else:
return False
def crack(self):
#...
# 获取缺口位置
gap = self.get_gap(image1, image2)
print('缺口位置', gap)
# 减去缺口位移
gap -= BORDER
⑤ 获取移动轨迹
- 模拟人的行为习惯(先匀加速拖动后匀减速拖动),把需要拖动的总距离分成一段一段小的轨迹
def get_track(self, distance):
'''
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
'''
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 0
while current < distance:
if current < mid:
# 加速度为正2
a = 2
else:
# 加速度为负3
a = -3
# 初速度v0
v0 = v
# 当前速度v = v0 + at
v = v0 + a * t
# 移动距离x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track
def crack(self):
#...
# 获取移动轨迹
track = self.get_track(gap)
print('滑动轨迹', track)
⑥ 按照轨迹拖动,完全验证
def move_to_gap(self, slider, track):
'''
拖动滑块到缺口处
:param slider: 滑块
:param track: 轨迹
:return:
'''
ActionChains(self.browser).click_and_hold(slider).perform()
for x in track:
ActionChains(self.browser).move_by_offset(xoffset=x, yoffset=0).perform()
time.sleep(0.5)
ActionChains(self.browser).release().perform()
def crack(self):
#...
# 拖动滑块
self.move_to_gap(slider, track)
success = self.wait.until(
EC.text_to_be_present_in_element((By.CLASS_NAME, 'geetest_success_radar_tip_content'), '验证成功'))
print(success)
⑦ 完成登录
def login(self):
''' 执行登录 return: None '''
submit = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'login-btn')))
submit.click()
time.sleep(10)
print('登录成功')
def crack(self):
#...
# 失败后重试
if not success:
self.crack()
else:
self.login()
22.3 完整代码:
import time
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
EMAIL = '[email protected]'
PASSWORD = 'python123'
BORDER = 6
class CrackGeetest():
def __init__(self):
self.url = 'https://account.geetest.com/login'
self.browser = webdriver.Chrome()
#设置显示等待时间
self.wait = WebDriverWait(self.browser, 20)
self.email = EMAIL
self.password = PASSWORD
def __del__(self):
#self.browser.close()
pass
def get_geetest_button(self):
''' 获取初始验证按钮,return:按钮对象 '''
button = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'geetest_radar_tip')))
return button
def get_position(self):
''' 获取验证码位置, return: 验证码位置(元组) '''
img = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'geetest_canvas_img')))
time.sleep(2)
location = img.location
size = img.size
top,bottom,left,right = location['y'],location['y']+size['height'],location['x'],location['x']+size['width']
return (top, bottom, left, right)
def get_screenshot(self):
''' 获取网页截图, return: 截图对象 '''
#浏览器截屏
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
return screenshot
def get_slider(self):
''' 获取滑块, return: 滑块对象 '''
slider = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'geetest_slider_button')))
return slider
def get_geetest_image(self, name='captcha.png'):
''' 获取验证码图片, return: 图片对象 '''
top, bottom, left, right = self.get_position()
print('验证码位置', top, bottom, left, right)
screenshot = self.get_screenshot()
#从网页截屏图片中裁剪处理验证图片
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha
def open(self):
''' 打开网页输入用户名密码, return: None '''
self.browser.get(self.url)
email = self.wait.until(EC.presence_of_element_located((By.ID, 'email')))
password = self.wait.until(EC.presence_of_element_located((By.ID, 'password')))
email.send_keys(self.email)
password.send_keys(self.password)
def get_gap(self, image1, image2):
''' 获取缺口偏移量, 参数:image1不带缺口图片、image2带缺口图片。返回偏移量 '''
left = 65
for i in range(left, image1.size[0]):
for j in range(image1.size[1]):
if not self.is_pixel_equal(image1, image2, i, j):
left = i
return left
return left
def is_pixel_equal(self, image1, image2, x, y):
'''
判断两个像素是否相同
:param image1: 图片1
:param image2: 图片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
'''
# 取两个图片的像素点(R、G、B)
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 60
if abs(pixel1[0]-pixel2[0])<threshold and abs(pixel1[1]-pixel2[1])<threshold and abs(pixel1[2]-pixel2[2])<threshold:
return True
else:
return False
def get_track(self, distance):
'''
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
'''
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 0
while current < distance:
if current < mid:
# 加速度为正2
a = 2
else:
# 加速度为负3
a = -3
# 初速度v0
v0 = v
# 当前速度v = v0 + at
v = v0 + a * t
# 移动距离x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track
def move_to_gap(self, slider, track):
'''
拖动滑块到缺口处
:param slider: 滑块
:param track: 轨迹
:return:
'''
ActionChains(self.browser).click_and_hold(slider).perform()
for x in track:
ActionChains(self.browser).move_by_offset(xoffset=x, yoffset=0).perform()
time.sleep(0.5)
ActionChains(self.browser).release().perform()
def login(self):
''' 执行登录 return: None '''
submit = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'login-btn')))
submit.click()
time.sleep(10)
print('登录成功')
def crack(self):
# 输入用户名密码
self.open()
# 点击验证按钮
button = self.get_geetest_button()
button.click()
# 获取验证码图片
image1 = self.get_geetest_image('captcha1.png')
# 点按呼出缺口
slider = self.get_slider()
slider.click()
# 获取带缺口的验证码图片
image2 = self.get_geetest_image('captcha2.png')
# 获取缺口位置
gap = self.get_gap(image1, image2)
print('缺口位置', gap)
# 减去缺口位移
gap -= BORDER
# 获取移动轨迹
track = self.get_track(gap)
print('滑动轨迹', track)
# 拖动滑块
self.move_to_gap(slider, track)
success = self.wait.until(
EC.text_to_be_present_in_element((By.CLASS_NAME, 'geetest_success_radar_tip_content'), '验证成功'))
print(success)
# 失败后重试
if not success:
self.crack()
else:
self.login()
# 程序主入口
if __name__ == '__main__':
crack = CrackGeetest()
crack.crack()
23. 爬虫项目需求分析
1 项目名称
- 《豆瓣读书信息爬取项目》
2 项目描述:
-
使用Python编程语言编写一个网络爬虫项目,将豆瓣读书网站上的所有图书信息爬取下来,并存储到MySQL数据库中。
-
爬取信息字段要求:
[ID号、书名、作者、出版社、原作名、译者、出版年、页数、定价、装帧、丛书、ISBN、评分、评论人数] ]
]
3 爬取网站过程分析:
- 打开豆瓣读书的首页:https://book.douban.com/
 ]
]
- 在豆瓣读书首页的右侧点击
所有热门标签,打开豆瓣图书标签页面: - 网址:https://book.douban.com/tag/?view=type&icn=index-sorttags-all
 ]
]
- 点击
豆瓣图书标签页面中所有的标签,进行对应标签下图书信息的列表页展示。
 ]
]  ]
]
- 在豆瓣图书列表页中可以获取每本圖片詳情信息。
 ]
]
4 运行环境要求:
- 运行环境描述:
- 操作系统:Windows/Linux/Mac
- python语言3.5以上版本
- MySQL数据库
- Redis数据库
- Scrapy框架
- Scrapy-Redis
- 还有其他各种驱动组件,使用pip命令安装
5 项目中的建议:
- 本次项目信息爬取量大,建议使用分布式信息爬取。
- 访问时的错误:
检测到有异常请求从你的 IP 发出,请`登录`使用豆瓣。
- 爬取豆瓣遇到的问题:https://blog.csdn.net/eye_water/article/details/78585394
最近需要爬取豆瓣的用户评分数据构造一个数据集,但是在爬取时却出了问题:
豆瓣封IP,白天一分钟可以访问40次,晚上一分钟可以访问60次,超过限制次数就会封IP。
于是,我便去代理IP网站上找了几个代理IP,但是爬取时又碰到了问题,明明已经使用代理IP,但是一旦超过限制次数爬虫仍然不能正常访问豆瓣。
问题出在Cookie上
豆瓣利用封IP+封Cookie来限制爬虫,因此只用代理IP的话也不行,Cookie也要更换。
想法一:
每次使用代理IP时,先访问豆瓣官网获取Cookie再访问用户的评论页面。本以为换了IP,Cookie随之也会更换,其实Cookie并没有改变。
想法二:
伪造Cookie。
观察豆瓣设置的Cookie格式,并进行伪造。
24. 爬虫项目架构设计
1. 数据库设计:
- 为了方便后续的数据处理,将所有图书信息都汇总的一张数据表中。
- 创建数据库:
doubandb - 进入数据库创建数据表:
books - 表中字段:
[
ID号、书名、作者、出版社、原作名、译者、出版年、页数、
定价、装帧、丛书、ISBN、评分、评论人数
]
- 数据表结构:
CREATE TABLE `books` (
`id` bigint(20) unsigned NOT NULL COMMENT 'ID号',
`title` varchar(255) DEFAULT NULL COMMENT '书名',
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`press` varchar(255) DEFAULT NULL COMMENT '出版社',
`original` varchar(255) DEFAULT NULL COMMENT '原作名',
`translator` varchar(128) DEFAULT NULL COMMENT '译者',
`imprint` varchar(128) DEFAULT NULL COMMENT '出版年',
`pages` int(10) unsigned DEFAULT NULL COMMENT '页数',
`price` double(6,2) unsigned DEFAULT NULL COMMENT '定价',
`binding` varchar(32) DEFAULT NULL COMMENT '装帧',
`series` varchar(128) DEFAULT NULL COMMENT '丛书',
`isbn` varchar(128) DEFAULT NULL COMMENT 'ISBN',
`score` varchar(128) DEFAULT NULL COMMENT '评分',
`number` int(10) unsigned DEFAULT NULL COMMENT '评论人数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
2. 项目结构:
- 本次项目设计分为四个模块,如下图所示:
 ]
]
- 说明:
- 模块一:实现豆瓣图书信息所有标签信息的爬取,并图书的标签信息写入到Redis数据库中,此模块可使用rquests简单实现。
- 模块二:负责从Redis中获取每个图书标签,并分页式的爬取每本图书的url信息,并将信息写入到redis中。
- 模块三:负责从Redis中获取每个图书的url地址,并爬取对应的图书详情,将每本图书详情信息写回到redis数据库中。
- 模块四:负责从Redis中获取每本图书的详情信息,并将信息依次写入到MySQL数据中,作为最终的爬取信息。
- 本次项目结构采用Scrapy-Redis主从分布式架构:
- 主master负责爬取每本图书的url地址(要去重),并将信息添加到Redis的url队列中(模块二)
- 从slave负责从Redis的url队列中获取每本书的url,并爬取对应的图书信息(过滤掉无用数据)(模块三)。
3. 具体实施描述
4. 项目中的规范:
25. 爬虫项目的代码实现
25.1 数据库的准备:
- 启动MySQL和Redis数据库
- 在MySQL数据库中创建数据库:
doubandb,并进入数据库中创建books数据表
CREATE TABLE `books` (
`id` bigint(20) unsigned NOT NULL COMMENT 'ID号',
`title` varchar(255) DEFAULT NULL COMMENT '书名',
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`press` varchar(255) DEFAULT NULL COMMENT '出版社',
`original` varchar(255) DEFAULT NULL COMMENT '原作名',
`translator` varchar(128) DEFAULT NULL COMMENT '译者',
`imprint` varchar(128) DEFAULT NULL COMMENT '出版年',
`pages` int(10) unsigned DEFAULT NULL COMMENT '页数',
`price` double(6,2) unsigned DEFAULT NULL COMMENT '定价',
`binding` varchar(32) DEFAULT NULL COMMENT '装帧',
`series` varchar(128) DEFAULT NULL COMMENT '丛书',
`isbn` varchar(128) DEFAULT NULL COMMENT 'ISBN',
`score` varchar(128) DEFAULT NULL COMMENT '评分',
`number` int(10) unsigned DEFAULT NULL COMMENT '评论人数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
25.2 模块1的实现:
- 实现豆瓣图书信息所有标签信息的爬取,并图书的标签信息写入到Redis数据库中,此模块可使用rquests简单实现。
- 创建一个独立的python文件:load_tag_url.py 代码如下
#使用requests加pyquery爬取所有豆瓣图书标签信息,并将信息储存于redis中
import requests
from pyquery import PyQuery as pq
import redis
def main():
#使用requests爬取所有豆瓣图书标签信息
url = "https://book.douban.com/tag/?view=type&icn=index-sorttags-all"
res = requests.get(url)
print("status:%d" % res.status_code)
html = res.content.decode('utf-8')
# 使用Pyquery解析HTML文档
#print(html)
doc = pq(html)
#获取网页中所有豆瓣图书标签链接信息
items = doc("table.tagCol tr td a")
# 指定Redis数据库信息
link = redis.StrictRedis(host='127.0.0.1', port=6379, db=0)
#遍历封装数据并返回
for a in items.items():
#拼装tag的url地址信息
tag = a.attr.href
#将信息以tag:start_urls写入到Redis中
link.lpush("book:tag_urls",tag)
print("共计写入tag:%d个"%(len(items)))
#主程序入口
if __name__ == '__main__':
main()
- 运行:
python load_tag_url.py
25.3 模块2的实现:
- 此模块负责从Redis中获取每个图书标签,并分页式的爬取每本图书的url信息,并将信息写入到redis中。
- ① 首先在命令行编写下面命令,创建项目master(主)和爬虫文件
scrapy startproject master
cd master
scrapy genspider book book.douban.com
- ② 编辑
master/item.py文件
import scrapy
class MasterItem(scrapy.Item):
# define the fields for your item here like:
url = scrapy.Field()
#pass
- ③ 编辑
master/settings.py文件
...
ROBOTSTXT_OBEY = False
...
#下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压力。同时也支持小数:
DOWNLOAD_DELAY = 2
...
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0',
}
...
ITEM_PIPELINES = {
'master.pipelines.MasterPipeline': 300,
}
...
# 指定使用scrapy-redis的去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
# 指定使用scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
# 指定排序爬取地址时使用的队列,
# 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# REDIS_URL = 'redis://localhost:6379' # 一般情况可以省去
REDIS_HOST = 'localhost' # 也可以根据情况改成 localhost
REDIS_PORT = 6379
- ④ 编辑
master/spiders/book.py文件
# -*- coding: utf-8 -*-
import scrapy
from master.items import MasterItem
from scrapy import Request
from urllib.parse import quote
import redis,re,time,random
class BookSpider(scrapy.Spider):
name = 'master_book'
allowed_domains = ['book.douban.com']
base_url = 'https://book.douban.com'
def start_requests(self):
''' 从redis中获取,并爬取标签对应的网页信息 '''
r = redis.Redis(host=self.settings.get("REDIS_HOST"), port=self.settings.get("REDIS_PORT"), decode_responses=True)
while r.llen('book:tag_urls'):
tag = r.lpop('book:tag_urls')
url = self.base_url + quote(tag)
yield Request(url=url, callback=self.parse,dont_filter=True)
def parse(self, response):
''' 解析每页的图书详情的url地址信息 '''
print(response.url)
lists = response.css('#subject_list ul li.subject-item a.nbg::attr(href)').extract()
if lists:
for i in lists:
item = MasterItem()
item['url'] = i
yield item
#获取下一页的url地址
next_url = response.css("span.next a::attr(href)").extract_first()
#判断若不是最后一页
if next_url:
url = response.urljoin(next_url)
#构造下一页招聘列表信息的爬取
yield scrapy.Request(url=url,callback=self.parse)
- ⑤ 编辑
master/pipelines.py文件
import redis,re
class MasterPipeline(object):
def __init__(self,host,port):
#连接redis数据库
self.r = redis.Redis(host=host, port=port, decode_responses=True)
@classmethod
def from_crawler(cls,crawler):
'''注入实例化对象(传入参数)'''
return cls(
host = crawler.settings.get("REDIS_HOST"),
port = crawler.settings.get("REDIS_PORT"),
)
def process_item(self, item, spider):
#使用正则判断url地址是否有效,并写入redis。
bookid = re.findall("book.douban.com/subject/([0-9]+)/",item['url'])
if bookid:
if self.r.sadd('books:id',bookid[0]):
self.r.lpush('bookspider:start_urls', item['url'])
else:
self.r.lpush('bookspider:no_urls', item['url'])
- ⑥ 测试运行:
scarpy crawl master_book
25.4 模块3的实现:
- 负责从Redis中获取每个图书的url地址,并爬取对应的图书详情,将每本图书详情信息写回到redis数据库中。
- ① 首先在命令行编写下面命令,创建项目salve(从)和爬虫文件
scrapy startproject salve
cd salve
scrapy genspider book book.douban.com
- ② 编辑
salve/item.py文件
import scrapy
class BookItem(scrapy.Item):
# define the fields for your item here like:
id = scrapy.Field() #ID号
title = scrapy.Field() #书名
author = scrapy.Field() #作者
press = scrapy.Field() #出版社
original = scrapy.Field() #原作名
translator = scrapy.Field()#译者
imprint = scrapy.Field() #出版年
pages = scrapy.Field() #页数
price = scrapy.Field() #定价
binding = scrapy.Field() #装帧
series = scrapy.Field() #丛书
isbn = scrapy.Field() #ISBN
score = scrapy.Field() #评分
number = scrapy.Field() #评论人数
#pass
- ③ 编辑
salve/settings.py文件
BOT_NAME = 'slave'
SPIDER_MODULES = ['slave.spiders']
NEWSPIDER_MODULE = 'slave.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
...
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0',
}
...
ITEM_PIPELINES = {
#'slave.pipelines.SlavePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
...
# 指定使用scrapy-redis的去重
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
# 指定使用scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
# 指定排序爬取地址时使用的队列,
# 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# REDIS_URL = 'redis://localhost:6379' # 一般情况可以省去
REDIS_HOST = 'localhost' # 也可以根据情况改成 localhost
REDIS_PORT = 6379
- ④ 编辑
salve/spiders/book.py文件
# -*- coding: utf-8 -*-
import scrapy,re
from slave.items import BookItem
from scrapy_redis.spiders import RedisSpider
class BookSpider(RedisSpider):
name = 'slave_book'
#allowed_domains = ['book.douban.com']
#start_urls = ['http://book.douban.com/']
redis_key = "bookspider:start_urls"
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(BookSpider, self).__init__(*args, **kwargs)
def parse(self, response):
print("======================",response.status)
item = BookItem()
vo = response.css("#wrapper")
item['id'] = vo.re_first('id="collect_form_([0-9]+)"') #ID号
item['title'] = vo.css("h1 span::text").extract_first() #书名
#使用正则获取里面的info里面的图书信息
info = vo.css("#info").extract_first()
#print(info)
authors = re.search('(.*?)
' ,info,re.S).group(1)
item['author'] = "、".join(re.findall('(.*?)' ,authors,re.S)) #作者
item['press'] = " ".join(re.findall('\s*(.*?)
' ,info)) #出版社
item['original'] = " ".join(re.findall('\s*(.*?)
' ,info)) #原作名
yz = re.search('(.*?)
' ,info,re.S)
if yz:
item['translator'] = "、".join(re.findall('(.*?)' ,yz.group(1),re.S)) #译者
else:
item['translator'] = ""
item['imprint'] = re.search('\s*([0-9\-]+)
' ,info).group(1) #出版年
item['pages'] = re.search('\s*([0-9]+)
' ,info).group(1) #页数
item['price'] = re.search('.*?([0-9\.]+)元?
' ,info).group(1) #定价
item['binding'] = " ".join(re.findall('\s*(.*?)
' ,info,re.S)) #装帧
item['series'] = " ".join(re.findall('.*?(.*?)
' ,info,re.S)) #丛书
item['isbn'] = re.search('\s*([0-9]+)
' ,info).group(1) #ISBN
item['score'] = vo.css("strong.rating_num::text").extract_first().strip() #评分
item['number'] = vo.css("a.rating_people span::text").extract_first() #评论人数
#print(item)
yield item
- ⑤ 编辑
salve/pipelines.py文件
class SlavePipeline(object):
def process_item(self, item, spider):
return item
- ⑥ 测试运行
# 在spider目录下和book.py在一起。
scrapy runspider book.py
25.5 模块4的实现:
- 负责从Redis中获取每本图书的详情信息,并将信息依次写入到MySQL数据中,作为最终的爬取信息。
- 在当前目录下创建一个:item_save.py的独立爬虫文件
#将Redis中的Item信息遍历写入到数据库中
import json
import redis
import pymysql
def main():
# 指定Redis数据库信息
rediscli = redis.StrictRedis(host='127.0.0.1', port=6379, db=0)
# 指定MySQL数据库信息
db = pymysql.connect(host="localhost",user="root",password="",db="doubandb",charset="utf8")
#使用cursor()方法创建一个游标对象cursor
cursor = db.cursor()
while True:
# FIFO模式为 blpop,LIFO模式为 brpop,获取键值
source, data = rediscli.blpop(["book:items"])
print(source)
try:
item = json.loads(data)
#组装sql语句
dd = dict(item)
keys = ','.join(dd.keys())
values=','.join(['%s']*len(dd))
sql = "insert into books(%s) values(%s)"%(keys,values)
#指定参数,并执行sql添加
cursor.execute(sql,tuple(dd.values()))
#事务提交
db.commit()
print("写入信息成功:",dd['id'])
except Exception as err:
#事务回滚
db.rollback()
print("SQL执行错误,原因:",err)
#主程序入口
if __name__ == '__main__':
main()
- 使用python命令测试即可
25.6 反爬处理:
- 降低爬取频率
- 浏览器伪装
- IP代理服务的使用
26. 使用web展示爬取信息
26.1 创建项目myweb和应用web
# 创建项目框架myweb
$ django-admin startproject myweb
$ cd myweb
# 在项目中创建一个web应用
$ python3 manage.py startapp web
# 创建模板目录
$ mkdir templates
$ mkdir templates/web
$ cd ..
$ tree myweb
myweb
├── myweb
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
├── web
│ ├── admin.py
│ ├── apps.py
│ ├── __init__.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
└── templates
└── web
26.2 执行数据库连接配置,网站配置
- ① 编辑myweb/web/init.py文件,添加Pymysql的数据库操作支持
import pymysql
pymysql.install_as_MySQLdb()
- ② 编辑myweb/web/settings.py文件,配置数据库连接
...
#配置自己的服务器IP地址
ALLOWED_HOSTS = ['*']
...
#添加自己应用
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'web',
]
...
# 配置模板路径信息
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR,'templates')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
...
# 数据库连接配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'doubandb',
'USER': 'root',
'PASSWORD': '',
'HOST': 'localhost',
'PORT': '3306',
}
...
26.3 定义Model类
- 编辑myweb/web/models.py
from django.db import models
#图书信息模型
class Books(models.Model):
title = models.CharField(max_length=255) #书名
author = models.CharField(max_length=64) #作者
press = models.CharField(max_length=255) #出版社
original = models.CharField(max_length=255)#原作名
translator = models.CharField(max_length=128)#译者
imprint = models.CharField(max_length=128)#出版年
pages = models.IntegerField(default=0)#页数
price = models.FloatField() #定价
binding = models.CharField(max_length=32) #装帧
series = models.CharField(max_length=128) #丛书
isbn = models.CharField(max_length=128) #ISBN
score = models.CharField(max_length=128) #评分
number = models.IntegerField(default=0) #评论人数
class Meta:
db_table = "books" # 更改表名
26.4 URL路由配置:
- 编辑 myweb/myweb/urls.py 根路由配置文件:
from django.conf.urls import url,include
urlpatterns = [
url(r'^',include('web.urls')),
]
- 创建web子路由文件:myweb/web/urls.py 并编写代码如下:
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^$', views.index, name="index"),
url(r'^/$', views.index, name="index"),
]
26.5 编写视图处理文件
- 编辑视图文件:myweb/web/views.py
from django.shortcuts import render
from django.core.paginator import Paginator
from web.models import Books
# Create your views here.
def index(request):
#获取商品信息查询对象
mod = Books.objects
list = mod.filter()
#执行分页处理
pIndex = int(request.GET.get("p",1))
page = Paginator(list,50) #以50条每页创建分页对象
maxpages = page.num_pages #最大页数
#判断页数是否越界
if pIndex > maxpages:
pIndex = maxpages
if pIndex < 1:
pIndex = 1
list2 = page.page(pIndex) #当前页数据
plist = page.page_range #页码数列表
#封装信息加载模板输出
context = {
"booklist":list2,'plist':plist,'pIndex':pIndex,'maxpages':maxpages}
return render(request,"web/index.html",context)
26.5 编写模板输出文件
<html>
<head>
<meta charset="utf-8">
<title>浏览图书信息title>
<style type="text/css">
table{
font-size:13px;line-height:25px;border-collapse: collapse;}
table,table tr th, table tr td {
border:1px solid #dddddd; }
style>
head>
<body>
<center>
<h2>浏览图书信息h2>
<table width="95%">
<tr style="background-color:#ddeedd;">
<th>ID号th>
<th>标题th>
<th>作者th>
<th>出版社th>
<th>出版年th>
<th>单价th>
<th>评分th>
tr>
{% for book in booklist %}
<tr>
<td>{
{ book.id }}td>
<td>{
{ book.title }}td>
<td>{
{ book.author }}td>
<td>{
{ book.press }}td>
<td>{
{ book.imprint }}td>
<td>{
{ book.price }}td>
<td>{
{ book.score }}td>
tr>
{% endfor %}
table>
<p>
{% for pindex in plist %}
{% if pIndex == pindex %}
{
{pindex}}
{% else %}
<a href="{% url 'index'%}?p={
{ pindex }}">{
{ pindex }}a>
{% endif %}
{% endfor %}
center>
body>
html>
26.6 启动服务测试:
$ python manage.py runserver
使用浏览器访问测试
 ]
]
26.7 练习:
- 当数据很多时,请问如何实现百度的页面显示效果? 如:上一页 … 10,11,12,13,14,15,16,17,18 … 下一页