路网数据对于城市中的很多应用,比如车载导航和线路优化等,都非常重要。传统的道路数据采集方法依赖于采集车,消耗大量的人力物力。随着GPS设备的普及,海量轨迹数据在城市里产生,使我们能够用轨迹数据去生成路网。这个问题在近十年中已经有了广泛的研究,但是其中很多方法的精确度(precision)并不高,特别是上下道路,平行道路等地方。由于轨迹数据在城市内并不是均匀分布的,对于那些车辆频繁通行的地方,我们有没有办法进一步提高这些区域路网推测的精确度呢?
本文将介绍美国麻省理工学院(MIT)与卡塔尔哈马德-本-哈利法大学(HBKU)联合在国际地理信息领域顶会ACM SIGSPATIAL 2018上发表的论文《RoadRunner: Improving the Precision of Road Network Inference from GPS Trajectories》,使得在提高路网推测精确度的同时,不损失覆盖率(或召回率,recall)。本文将路网推测的问题分为两阶段,_先用本文提出的RoadRunner算法在高轨迹密度区域推测出高精确度地图,然后与传统的轨迹推测路网方法结合,_满足召回率的要求。RoadRunner的核心思想是利用每条轨迹的连通性来判断相交的轨迹是行驶在同一条道路上,还是平行的两条路上。

一、问题背景
从轨迹中推测路网是一个非常有挑战的问题。图1左侧两栏给出了基于概率密度估计(KDE)和k-Means聚类的两类传统算法在三个城市(洛杉矶、波士顿、芝加哥)上的表现。生成的地图有三个问题:
1)上层道路会与下层道路连接;
2)实际不相交的邻接道路会连通;
3)详细的拓扑很难识别,例如高速路的交叉口。
本文提出了 RoadRunner ,该方法利用 增量的方式基于轨迹的流构建路网。 在每一次迭代中,RoadRunner通过一个轨迹过滤算子,考虑前驱相同的子轨迹集合来生成路段。这种方法对于除去相邻路段的干扰非常重要,并且对于GPS的噪声和道路拓扑较为鲁棒。虽然RoadRunner精确度较高,但是过滤操作会导致轨迹较少的区域丢失道路。为了进一步提高路网推测的召回率,本文提出了一种合并操作将RoadRunner推测的结果与传统方法推测的结果整合。图1右侧一栏展示了文本提出的方法的效果。

二、RoadRunner
RoadRunner的算法流程如图2所示。算法的输入是一个初始的路网,可以来自于现有路网或者用别的方法推测得到的路网。我们先把初始路网中所有的顶点加入队列Q,队列中的顶点称为active顶点(第2-3行)。在每一轮迭代中,RoadRunner从队列中挑选一个active顶点v,通过Trace操作提取轨迹在顶点v处的流出方向(第5-6行)。对于每个流出方向θ,我们加入一条从v出发,方向为θ,距离为固定长度d的小路段来扩展当前路网(第7-11行)。然后通过Merge操作,尝试将该小路段的另一个顶点u合并到现有路网。如果合并失败,我们将u加入Q用于下一轮迭代(第12-14行)。当Q为空时,算法停止,并返回当前路网。

▲图2. RoadRunner算法框架▲
值得注意的一点是,为了有效地进行Trace和Merge,在每一次迭代中,RoadRunner只保留一部分和当前路段相关的子轨迹集合用于路网的生成。图3是某处的卫星地图和对应的轨迹数据分布。假设我们现在要从图3下图蓝色顶点处扩展路网。由于三条高亮的路在该处空间距离非常接近,而且它们的朝向也近乎相同,如果我们考虑所有轨迹数据,我们可能会将红色的路与绿色的路相连,或者把红色的路和蓝色的路合并。但是通过排除不在当前正在扩展的路段附近的轨迹,我们能够得到一个干净得多的子轨迹集合(只覆盖红色道路的轨迹)。我们将这个轨迹过滤操作称为路径过滤算子(way path filter)。实现方式如下: 给定一个圆心沿着路段的圆序列(半径代表道路宽度),路径过滤算子只保留按顺序通过这些圆的轨迹。 对于一个active顶点,我们可以基于当前路网,计算一条长度为k的路径(以active顶点为结束),然后沿着这条路径生成圆序列(每个圆的半径可以通过轨迹数据动态估计),来构造过滤条件。

▲图3. 引入路径过滤算子的动机▲
接下来,我们简单介绍一下Trace和Merge操作的具体实现。
1,Tracing
Trace操作的目的是为了 提取轨迹在顶点v处的主要流出方向。 如图4上图所示,我们要提取轨迹在蓝色顶点处的方向。我们首先应用路径过滤算子得到经过蓝色顶点之前的路径的子轨迹集合(绿色显示),我们发现轨迹在交叉路口处明显分为了三组。我们以蓝色顶点为圆心,D为半径画一个圆(如粉色圆所示),然后在顶点处生成72个角度用于等分圆周。再以每一个角度与圆的交点为圆心,r为半径,构造一个小圆(如黄色圆所示)。然后再次利用路径过滤去筛选得到经过之前路径以及经过该小圆的轨迹T'
。最后,该角度的轨迹数量记录为
![]()
,其中M为一个常数,用于滤噪。我们将每个角度的轨迹条数都计算出,并存储在一个72维的向量中,再利用高斯核对该向量进行平滑,然后检测局部峰值。图4下图可视化了平滑后的计数值的分布,算法检测得到三个方向的局部峰值。

▲图4. Trace操作举例▲
2,Merging
当我们生成一条路段后,需要将它和已有路网合并。但是这并不容易,合并的过程中,需要确保上下关系,平行关系以及多层级关系等等。为了克服这些挑战,本文只有在通过路段的轨迹未来的分布匹配的情况下,才会合并两个路段。图5中,我们展示了经过蓝色和绿色的路径的轨迹未来的分布情况。我们可以很明显发现,在例子(a)中两者的分布并不一致,但是在例子(b)中两者的分布几乎一样。
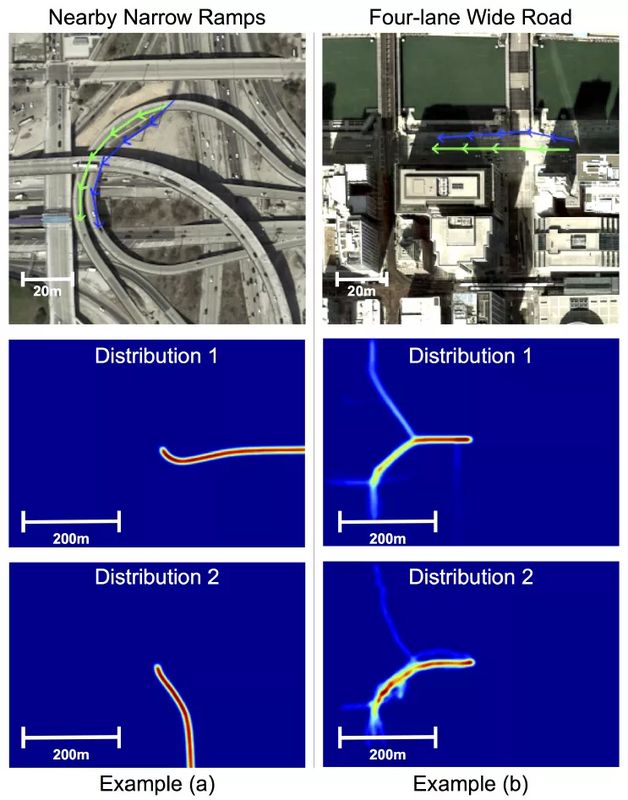
▲图5. Merge操作举例▲
Merge操作具体实现如图6所示。对于一个要合并的顶点v,我们计算经过v的路径的轨迹未来的分布,然后我们找到v周围的顶点u,如果经过u的路径的轨迹未来分布和v的一致,我们加入路段(u,v),并返回True;如果v的分布与周围顶点都不同,则返回False。

▲图6. Merge操作▲
三、两阶段路网推测
RoadRunner虽然有较高的精确度,但是由于路径过滤算子对轨迹的筛选,很多低频访问区域的路段会丢失。所以在第二阶段,为了提高召回率,需要将RoadRunner的结果与其他路网推测算法结果合并。
假设G1为RoadRunner推测的路网,G2为其他能够捕捉低频通行路段的路网生成算法输出的结果。我们首先删除G2中距离G1中路段Rmerge范围内的路段得到G2',因为这些路段路段RoadRunner已经成功推测完成了。然后我们将G1与G2'放在一起得到G。然而,从G2'中加入的路段和其余路段并不连通。为了连通这些道路,对于G中每一个度为1的顶点v,我们在满足以下两个条件时,让其与周围路段(u,w)连通:1)v到
(u,w)的距离小于Rmerge;2)经过路径 v → p → u 或者 v → p → w的轨迹超过一定阈值,其中p为v在路段(u,w)上的投影点。
四、实验结果
本文在4个城市(洛杉矶、波士顿、芝加哥、纽约)上验证了提出的方法的有效性,每个城市选择了一块4kmx4km的区域,轨迹数据累计约有6万条。OpenStreetMap被当作真实路网用于验证。
图7给出了不同方法在不同参数设定下,错误率和召回率的变化曲线(越接近左上角性能越好,不同数据集结果取平均)。实验结果显示,RoadRunner+KDE的方法(RR-2+BE-2)比只用KDE的方法(BE-2)有33.6%的错误率降低,RoadRunner+kMeans的方法(RR-2+Kharita-20)比只用kMeans的方法(Kharita-20)有60.7%的错误率降低。

▲图7. 实验结果▲
五、小结
本文提出了一个两阶段的路网推测框架,能够在不损失召回率的情况下,提升精度。本框架中的核心模块是RoadRunner,它利用轨迹数据的连接性来生成准确的路网,面对复杂的路况,与现有相比有很好的表现。
推荐阅读:
欢迎点击【京东智联云】,了解开发者社区
更多精彩技术实践与独家干货解析
欢迎关注【京东智联云开发者】公众号