python爬虫:下载进击的巨人全集视频
一、前言
最近进击的巨人最终季开播了,看的我心潮澎湃。主角们都沧桑了不少,曾经的女神三笠如今变得跟个少妇似的,但战斗力依旧爆表,米卡莎yyds!
刚好这段时间学习了爬虫相关代码,就写代码下载全集视频来练练手吧。
二、背景
众所周知,由于被认为血腥,进击的巨人在天朝被封禁了。但是这并不能阻挡热爱动漫的肥宅们。众多无名小站被发掘出来,成为二次元们的天堂。
樱花动漫算是其中知名度比较高的网站了,我将从该网站进行爬取。
Url:http://www.imomoe.ai/

三、实战
以第一季为例,进行实战讲解。
想下载第一季的全部视频,思路如下:
- 拿到所有集数和对应的在线播放网址
- 从在线播放的网页链接中找到视频在服务器上的缓存地址
- 通过视频地址将视频下载到本地
看起来很简单,我本来也以为不复杂,实际操作下来还是遇到了一些问题,还好跌跌撞撞最后都愉快的解决了。
1、获取所有集对应的在线播放网址
获取所有集数和对应的在线播放网址还是比较简单的。
打开第一季的目录网页,不难发现,只要拿到id属性为play_0的div标签,就能获取到所有的集数和对应的播放网址,都放在该标签下的a标签中。

用BeautifulSoup匹配id属性为play_0的div标签即可。代码如下:
season_1_url = 'http://www.imomoe.ai/view/4225.html'
season_1_response = requests.get(season_1_url)
season_1_response.encoding = 'gb2312'
season_1_soup = BeautifulSoup(season_1_response.text, 'lxml')
season_1_soup_info = season_1_soup.find('div', id="play_0")

再找到其中的a标签
season_1_info = season_1_soup_info.find_all('a')

然后,点击第一集,发现其在线播放网址是http://www.imomoe.ai/player/4225-0-0.html,其实就是http://www.imomoe.ai后面接上该标签下href属性里的东西。
于是,编写代码如下:
Season_1 = pd.DataFrame()
for i in range(len(season_1_info)):
Season_1.loc[i,'集数'] = season_1_info[i].text
Season_1.loc[i,'网址'] = 'http://www.imomoe.ai' + season_1_info[i].get('href')

至此,就获取到了第一季每一集对应的在线播放网址,简简单单。
2、获取视频地址
这一步对我来说还是有点坎坷的,摸爬滚打了好久才摸索出来。
从在线播放网页源代码可以很轻松的找到视频地址,video标签的src属性里就存放着视频地址。

也即:http://quan.qq.com/video/1098_bb647971ef1b4ec9cec8fbe201374e3a,先放出来,后面要用到。

把这个网址复制到浏览器地址栏可以直接打开。
到这里,我心想,就这就这就这?简单的一批。
于是,继续干
first_url = 'http://www.imomoe.ai/player/4225-0-0.html'
first_response = requests.get(first_url)
first_response.encoding = 'gb2312'
first_soup = BeautifulSoup(first_response.text, 'lxml')
first_soup.find('video', class_="dplayer-video dplayer-video-current")
然后,返回空。。。寂寞了。我也有试过其他的包含video的标签,但都不包含源代码里清晰可见的视频地址。
仔细对比查看发现,根本没爬到想要的视频地址。好家伙我直接懵逼,由于不懂JavaScript,我完全不知道问题出在哪,我只能猜测视频是动态加载的。
这种情况讲道理我不会应对,只能放大招了,直接上selenium.webdriver。
于是
driver = webdriver.Chrome()
driver.get(first_url)
time.sleep(3)
first_response = driver.page_source
first_soup = BeautifulSoup(first_response)
first_soup.find_all('div', class_="dplayer-video-wrap")
结果,还是返回了个寂寞。我快崩溃了要,明明浏览器打开好好的,怎么用webdriver还是不行。真是为难我一个小白了,我真的看不出来里面哪里不对劲,绝望。
然后我一遍遍的看网页返回的内容,我不懂JavaScript,所以只能硬看。皇天不负有心人,终于被我发现了端倪。

在这个地方隐藏着视频地址!!!踏破铁鞋无觅处,得来全不费工夫。这事成了!
把iframe标签src属性里的东西提取出来,再用正则表达式匹配视频地址就OK了。话不多说,上代码。
item = first_soup.find_all('iframe')[1].get('src')
findLink = re.compile(r'vid=(.*?)&userlink=')
re.findall(findLink,item)[0]

如此一来,第一集的视频地址就get到了。
接下来,用一个循环就能轻松获取到第一季每一集的视频地址了。
findLink = re.compile(r'vid=(.*?)&userlink=')
for i in range(len(Season_1)):
url = Season_1.loc[i,'网址']
driver = webdriver.Chrome()
driver.get(url)
response = driver.page_source
soup = BeautifulSoup(response)
item = soup.find_all('iframe')[1].get('src')
Season_1.loc[i,'视频地址'] = re.findall(findLink,item)[0]
driver.quit()

第二步,大功告成!
3、下载视频
有了视频地址,下载视频就不难了。用urllib.request.urlretrieve函数就能轻松下载。
path = r'C:\我的文件\迅雷下载\进击的巨人'
# 函数说明:回调函数,打印下载进度
def Progress(blocknum,blocksize,totalsize):
"""
blocknum:当前的块编号
blocksize:每次传输的块大小
totalsize:网页文件总大小
"""
percent = blocknum*blocksize/totalsize
if percent > 1.0:
percent = 1.0
percent = percent*100
print("\r%.2f%% 已下载:%.2f Mb 文件大小:%.2f Mb" %(percent,blocknum*blocksize/1e6,totalsize/1e6), end=' ')
for i in range(len(Season_1)):
download_url = Season_1.loc[i,'视频地址']
if os.path.exists(path + './第一季') != 1:
os.mkdir(path + './第一季')
filename = os.path.join(path, '第一季', Season_1.loc[i,'集数']+'.mp4')
print('正在下载%s' %Season_1.loc[i,'集数'])
urllib.request.urlretrieve(download_url, filename, Progress)
print()
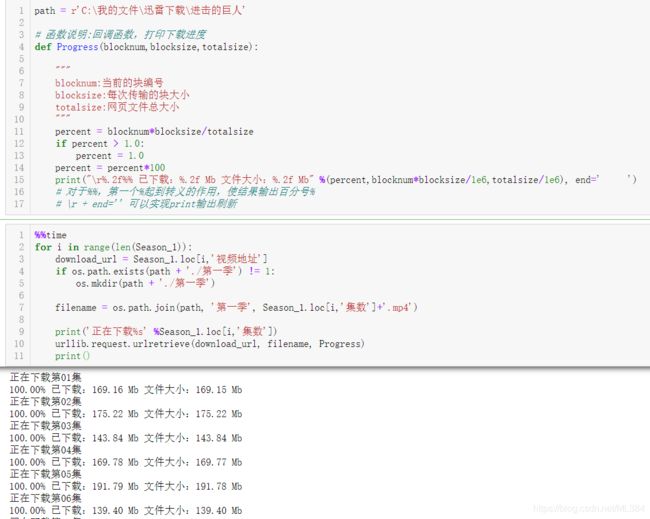
于是,第一季视频全部下载完毕,耶。
四、代码整合
将代码整合在一起,一次性下载四季的所有视频,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 20 14:35:06 2021
@author: Liuw
"""
import time
import pandas as pd
import re
import requests
from bs4 import BeautifulSoup
import urllib
from selenium import webdriver
import os
def get_episode_URL(season_URL,Season):
'''
函数说明:获取每一集的播放网址
Parameters:
season_URL:一季的目录网址
Season:用于存储爬取信息的DataFrame
Return:
Season
'''
season_response = requests.get(season_URL)
season_response.encoding = 'gb2312'
season_soup = BeautifulSoup(season_response.text, 'lxml')
season_soup_info = season_soup.find('div', id="play_0")
season_info = season_soup_info.find_all('a')
for i in range(len(season_info)):
Season.loc[i,'集数'] = season_info[i].text
Season.loc[i,'网址'] = 'http://www.imomoe.ai' + season_info[i].get('href')
return Season
def get_video_URL(Season):
'''
函数说明:获取每一集的视频存放地址
Parameters:
Season: 已保存视频播放地址的DataFrame
Reruen:
Season: 添加视频存放地址后的Dataframe
'''
for i in range(len(Season)):
url = Season.loc[i,'网址']
driver = webdriver.Chrome() # 用webdrive进行爬取
driver.get(url)
time.sleep(3)
response = driver.page_source
soup = BeautifulSoup(response, 'lxml')
item = soup.find_all('iframe')[1].get('src')
Season.loc[i,'视频地址'] = re.findall(findLink,item)[0]
driver.quit()
time.sleep(1)
return Season
def Progress(blocknum,blocksize,totalsize):
'''
函数说明:回调函数,打印下载进度
Parameters:
blocknum:当前的块编号
blocksize:每次传输的块大小
totalsize:网页文件总大小
Return:
无
'''
percent = blocknum*blocksize/totalsize
if percent > 1.0:
percent = 1.0
percent = percent*100
print("\r%.2f%% 已下载:%.2f Mb 文件大小:%.2f Mb" %(percent,blocknum*blocksize/1e6,totalsize/1e6), end=' ')
# 对于%%,第一个%起到转义的作用,使结果输出百分号%
# \r + end='' 可以实现print输出刷新
def download(Season, save_dir):
'''
函数说明:逐集下载
Parameters:
Season: 添加视频存放地址后的Dataframe
save_dir: 视频保存文件夹名称
Return:
无
'''
for i in range(len(Season)):
download_url = Season.loc[i,'视频地址']
if os.path.exists(path + './' + save_dir) != 1:
os.mkdir(path + './' + save_dir)
filename = os.path.join(path, save_dir, Season.loc[i,'集数']+'.mp4')
print('正在下载%s' %Season_1.loc[i,'集数'])
urllib.request.urlretrieve(download_url, filename, Progress)
print()
time.sleep(5)
if __name__ == "__main__":
URL = [
'http://www.imomoe.ai/view/4225.html',
'http://www.imomoe.ai/view/2489.html',
'http://www.imomoe.ai/view/7047.html',
'http://www.imomoe.ai/view/7947.html'
]
save_dir = ['第一季','第二季','第三季','第四季']
Season_1 = pd.DataFrame()
Season_2 = pd.DataFrame()
Season_3 = pd.DataFrame()
Season_4 = pd.DataFrame()
seasonList = [Season_1, Season_2, Season_3, Season_4]
path = r'C:\我的文件\迅雷下载\进击的巨人'
findLink = re.compile(r'vid=(.*?)&userlink=')
for i in range(4):
print('正在爬取%s' % save_dir[i])
get_episode_URL(URL[i], seasonList[i])
get_video_URL(seasonList[i])
download(seasonList[i], save_dir[i])
运行即可一次性下载四季到目前为止的全部视频,大功告成。


全部下载完大约用时一个半小时,主要是webdriver爬取太慢了,而我也不会别的方法,只能将就了。