通用AI元素识别在UI自动化测试的最佳实践
前言
在UI自动化测试中,元素被识别出来后,才能更加精确地模拟相关用户行为,才能更好地开展自动化的其他内容。一般移动端APP会有页面元素属性,比如:ID,ClassName,Text等,可以方便定位需要操控的元素控件。对于相对复杂的APP,尤其是移动APP跨平台开发框架的出现比如,比如RN或者Flutter,又比如小程序,可以通过基于chrome devtool protocol方式定位元素属性,也有通过图片相似度匹配方式。
这类常规的方式是通过自动化框架识别元素,而这类的UI控件识别框架的结果输出往往依赖于开发同学在代码中对控件元素进行合理有效的命名,且一旦这些控件元素被混淆后就很难进行有效的元素定位。
因此,寻找一个更有效地方法,从根本性问题着手,结合现有的端自身的识别能力,把绝大多数的问题解决是否可行的方向出发,从爱奇艺APP的自动化实践中分享一个通用的方案,方便大家学习和参考。
01 面临挑战
挑战1:自动化框架元素识别能力不足
像现在很多应用在PC端目前就没有能识别出元素的自动化框架从而无法进行UI自动化测试,而在移动端市场上常用的一些自动化测试框架,比如python-uiautomator2依赖于开发框架和开发对元素的命名才能识别,对RN页面、H5、小程序等元素的识别支持也不是很好。
挑战2:多机型多分辨率兼容
回归测试中需要对多机型进行覆盖测试,因机型分辨率的问题,同一个页面也会因不同的设备展示效果不一样,哪怕同样的元素在不同的设备上展示的大小会不一致。
挑战3:多样式元素,半透明元素,无属性元素
像现在很多应用都有皮肤主题,不同的皮肤背景色使用的对应的ICON也有不一样。在没有合理的控件元素命名的情况下,如果单纯用图片匹配的方式,很难剔除背景色对图片匹配结果的影响。
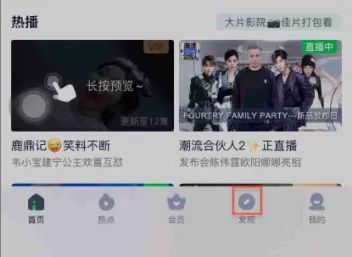
APP在不同设备不同皮肤下对比
元素显示:较小
元素中间显示:浅灰
元素边缘显示:浅灰
底部多个tab间距:较宽
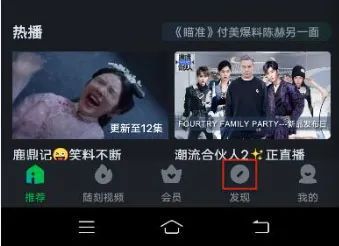
元素显示:较大
元素中间显示:黑色
元素边缘显示:黑色
底部多个tab间距:较窄
02 技术探索
初期方案:
服务端保存截取后的待识别控件元素小图,使用多种图片匹配算法方案。
(1.图片Hash 2.模板匹配 3.SIFT特征检测)
基本满足单设备,单背景色的图片查找。
当出现复杂背景,元素变化等情况将无法识别,并且也无法满足多设备多端的识别需求。
技术攻坚:
经过探索发现AI能进行物体识别,既然经过训练AI模型能识别人、物、体等,那么能不能识别APP UI控件元素和图片呢?
首先我们要选择合适的模型,检测有多种网络模型。
对大目标难检测问题的解决——SSD。SSD使用多层特征图进行检测,只是用了高层来进行检测没有底层并没有用来进行物体的检测,SSD速度很快,但与其他物体相比,对小物体的性能较差。
对于小目标难检测问题的解决——FPN。FPN中融入了特征金字塔,自下而上生成了高质量的特征金字塔提高了目标检测的准确率,尤其体现在小物体的检测。FPN可以更好的检测小物体;缺点就是时间成本太高。
采用的网络模型— YOLOv3
YOLOv3吸收了SSD的长处,同时增加了类FPN多尺度预测,能检测识别大目标也能检测小目标,同时检测速度也非常快;缺点是目标位置有偏移,对重叠密集型目标检测不是很好。
下图展示一下YOLOv3的数据(来自网络)
目标检测效果

与其他模型的数据对比
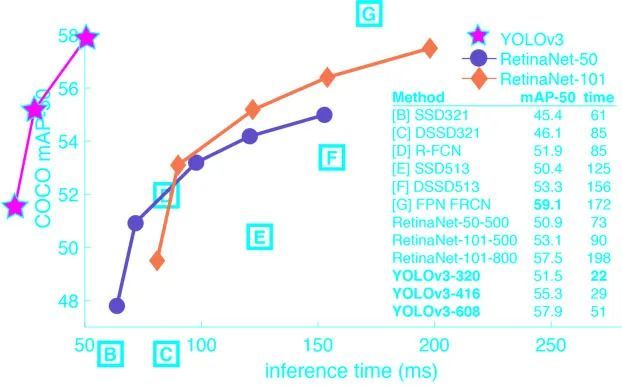
YOLOv3满足了我们即要检测大目标又要检测小目标,同时速度快的需求,我们要针对缺点进行优化。
03 落地实现
自动收集处理素材
AI训练需要大量的素材,如何能快速的收集大量素材,从三个方向着手。
1.在回归测试脚本中增加自动截图,在执行自动化回归用例时自动收集并上传;
2.在新版本APP稳定性测试中,画面变化截图自动收集并上传;
3. 通过AI测试中台提供入口让用户自主上传收集;
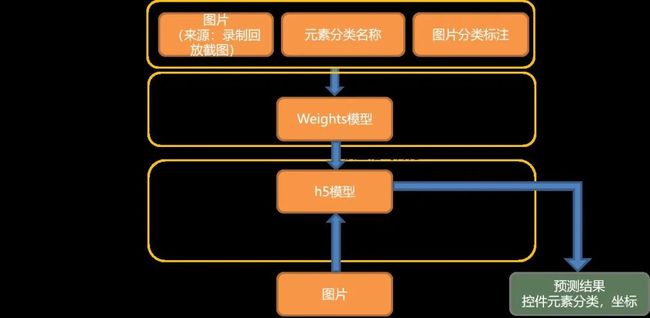
为加强训练召回率,我们统一对图片进行MD5去重,并将图片调整为训练需要的尺寸,最后统一将素材保存到素材库服务器。
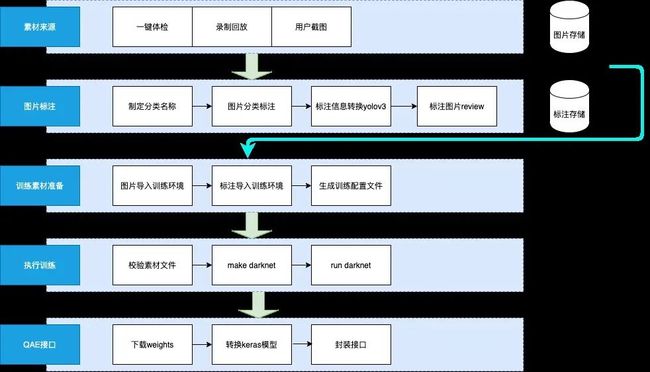
收集完素材后就进入了我们的训练阶段。
训练封装流程图:
YOLOv3密集型识别能力差的缺点,我们的APP中元素不会密集出现,当出现元素重叠那就是UI的BUG。
解决识别偏移的缺点:
![]()
元素识别,提取图片
![]()
分析图片,识别边缘
![]()
去除边缘
![]()
生成返回中心点
滑动查看更多
预测接口将返回给用户以下信息:元素的分类代码,left,top,width,height

元素预测接口落地情况一
在UI自动化测试录制回放落地
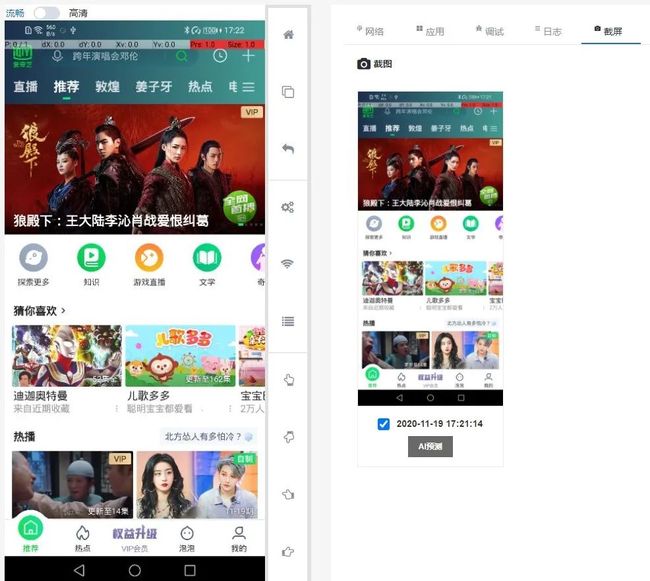
目前UI自动化方案:脚本录制使用的是我们自研的web版本IDE,脚本回放执行则使用我们封装python库。在录制时,用户一键可以检测手机设备上的所有元素,并对其进行操作
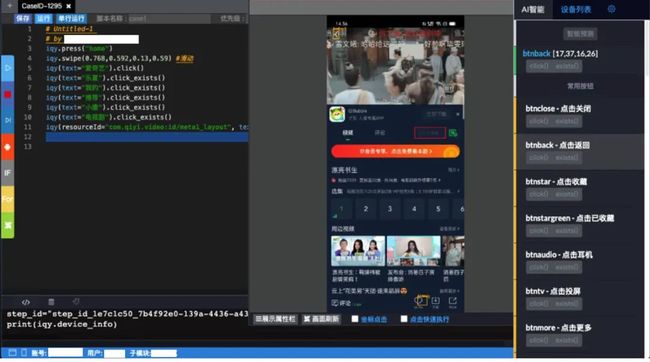
从上图我们可以看到,我们会将AI识别的元素设备画面中,同时在右侧会有一个LIST展示并可以对元素进行操作,操作时会自动生成脚本,将脚本发送给py库,如果是点击操作py库会以元素的中心点坐标为操作。
# 录制脚本生成的代码示例
# 判断搜索元素是否存在
if iqy.AI(btn=”btnsearch”).exists():
# 搜索元素存在则点击
iqy.AI(btn=”btnsearch”).click()
# 也可以写成
iqy.AI(btn=”btnsearch”).click_exists()
# 进阶用法
els=iqy.AI(btn=”btnsearch”)
#获取相关属性
data=els[0]
print(data["ratio"],"AI预测匹配度")
print(data["w"],"矩形width")
print(data["h"],"矩形height")
print(data["x"],"矩形左上x坐标")
print(data["x0"],"矩形左上x坐标")
在录制回放中最常见的是各种关闭按钮问题。我们在回归执行自动化时,经常会遇到突然出现一个弹窗,当遇到这种回放就无法继续了。
使用iqy.AI(btn="close").click_exists(),可精准处理APP内部各种广告弹窗。解决了因为活动无法关闭导致case执行失败问题。
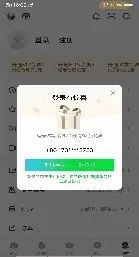
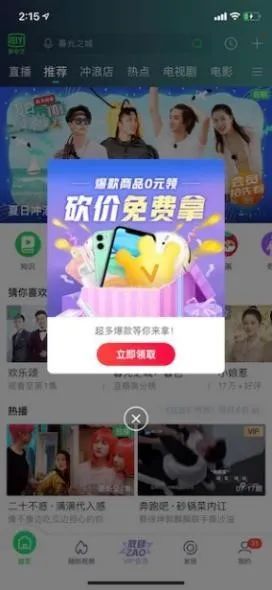
播放器在播放节目的时候画面一直在变,而播放器中的播放、暂停按钮也是高频使用的。
通过传统方式比较难识别,使用AI就变得很简单。
iqy.AI(btn="play")
iqy.AI(btn="pause")
目前我们经过训练了200+个元素(移动端60余个,PC端140余个)。像关闭按钮的识别召回率达94%,其他按钮80%+
实际收益:已在录制回放中广泛使用,每日自动运行CASE任务稳定率使用AI与未使用对比提升15%
元素预测接口落地情况二
在无属性页面中使用(安卓端,IOS端,PC端)。
我们使用元素预测+图片算法+文字识别研发出页面结构拆分功能。
落地APP稳定性测试,PC端稳定性测试中。
页面拆分功能对无属性控件的页面(小程序,RN,H5)的自动化提供了有效的解决方案。
具体实现如下:

原图处理
元素、图片、文字识别
元素聚合

返回单元素,聚合元素
滑动查看更多
实际收益:安卓APP 使用AI增强算法与未使用前对比,activity的覆盖率增加60%,bug总量增加30%
04 将AI能力拓展外部
对接其他业务打造部署一体化AI测试中台
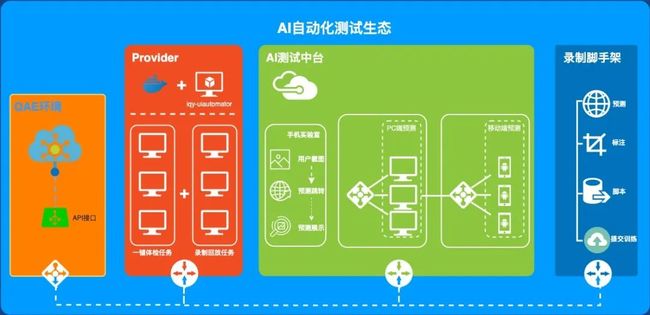
AI测试中台给予用户从自主上传素材,素材标注,标注审核到训练产出模型,一条完整链路的操作能力。
AI预测服务调用方只需要提交一张图片或给一个图片的URL地址,预测服务就会调用到API接口输出对应的控件元素分类、坐标等预测结果。

AI测试中台在用户提交图片后,会在画面上展示预测结果,同时给出Py库的写法示例和python请求API示例。

对接手机云测平台
在云测平台用户一键点击就可以直接调起AI预测接口。
AI测试中台部署中遇到的难点
1.同等性能的CPU和GPU的价格可能也会接近十倍;
2.同等价格的CPU和GPU速度差可能在十倍以上。
因此我们的AI测试中台的预测接口使用的是GPU环境。
GPU品牌使用较多的是Intel和NVIDIA,在预测接口部署中我们遇到一个重大问题。我们训练是在Inter的GPU上生产出的模型,部署后发现一直未使用GPU进行计算。这使得请求耗时需要5~10秒,这么长的请求耗时对用户来说是较糟糕的体验。
GPU计算和CPU计算时间相差数十倍。正常情况下GPU预测都在几百毫秒。经调研发现是模型类型的原因,不同的模型类型对GPU环境有不同的要求;Inter的GPU上训练出来的YOLOv3模型无法在NVIDA的GPU环境上使用,最终采用转换模型才解决GPU预测环境耗时过长的问题。
解决方案:YOLOv3 weights模型 转换Keras模型。
05 后续规划
AI赋能自动化测试,我们已经迈出第一步,元素识别上相较原始的图片对比方案也取得了一定成果,落地也得到了用户的一致好评,为更好的服务用户带来更大的收益我们也面临了更大的挑战。
1.对复杂画面中与背景融合度高的控件识别数量需增加,需继续支持更多icon元素识别。
2.对复杂页面的拆图能力有限,需增加对悬浮小图标,层叠图片的支持。
3.Card复杂度提升,左中右分栏card,上中下分类card,文字围绕card都是需要解决的问题。
4.Banner、menus、tabs、input的识别。
5.训练基于素材,素材的多样性和数量直接影响召回率,原始图片素材来源于自动化任务,自动化产出的多样性新图片增长受限。后续调研在原有图片基础上进行处理图片,生成多样训练素材。
6.支持更复杂的元素操作:例如计算从某元素到指定元素,能过某个特征验证元素。

也许你还想看
0.7秒完成动漫线稿上色,爱奇艺发布AI上色引擎
爱奇艺知识移动端组件化探索和实践

扫一扫下方二维码,更多精彩内容陪伴你!
