如何跑通第一个 SQL 作业
简介: 本文由阿里巴巴技术专家周凯波(宝牛)分享,主要介绍如何跑通第一个SQL。
一、SQL的基本概念
1.SQL 分类
SQL分为四类,分别是数据查询语言(DQL)、数据操纵语言(DML)、数据定义(DDL)语言和数据控制语言(DCL)。今天将介绍前三种语言的使用。

接下来介绍几个基本概念。
2.SQL 开发

● Scripts,即SQL文本。在SQL文本里面可以写上文介绍的前三种语言;
● Schema,即元数据。SQL里面需要使用的表和函数,是通过Schema进行定义的;
● Artifacts,即UDF Jar包;
3.Catalog
在 Flink SQL里,Catalog是管理元数据的。Catalog通过Catalog.DB.Table来定位一张表。除了DB和Table,Catalog还能注册函数,如UDF、UDTF和UDAF。
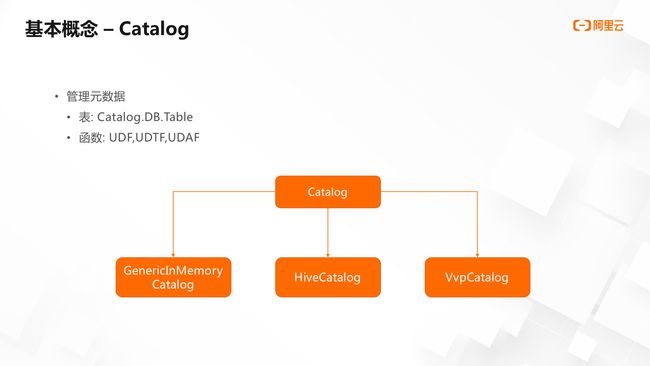
在Flink Catalog里,有三种Catalog实现:
● 第一个是GenericInMemoryCatalog,是内存版的Catalog。平常在使用 Flink SQL的时候,默认是内存版的Catalog。当程序运行结束,第二次重新运行的时候,会重新生成一个Catalog实例。
● 第二个是HiveCatalog,Flink里比较好的支持了HiveCatalog,可以从Hive HMS里读取元数据,同时也可以往Hive里注册表,写数据到Hive里面去。
● 第三个Catalog是 VVP平台里面开发的Catalog,即VvpCatalog,它实现了Flink Catalog的接口,底层是使用的数据库。
4.Deployment
Deployment是一个作业的描述,目前有两种任务类型,JAR和SQL。

Deployment上有升级策略(Upgrade strategy)和恢复策略(Restore strategy)。Upgrade strategy是指Deployment运行后,用户可以对Deployment的参数进行修改,这个修改如何影响Deployment的运行就是由不同的升级策略决定的;Restore strategy 指启动 Flink任务时,是否从 Savepoint/Checkpoint进行恢复就是不同的恢复策略。
Flink的版本和配置,常用的Flink的参数都可以在这里进行配置。例如:Task Managers 数量,Jobmanager和Taskmanager 的 CPU 和内存等。
Deployment上除了作业描述外,还有期望状态和实际状态。期望状态是指用户所期望的目标状态,例如当要将运行中的作业停止时,期望状态就是Canceled;操作完成的实际运行状态就是实际状态。
总的来说,Deployment是一个任务的描述模板。VVP平台内部的状态机会根据Deployment的期望状态和实际状态来控制作业的实际运行。
5.Job
Deployment启动时会生成一个Job,这个Job对应一个具体的 Flink Job。同一时间,一个Deployment上只会有一个正在运行的Job。
二、SQL的语法说明
1.语法说明
首先看下图的语句,分别是创建源表和创建结果表。


下图是注册函数。函数的注册分为两步,第一步上传JAR包,然后在系统上可以勾选自动注册;第二种是使用 Flink 语法进行手工注册。

使用函数有两种方式,第一是内置函数的使用,如下图UPPER是 Flink 自带的函数;第二种是自定义函数,像MyScalarFunc。

在VVP平台里,也支持 Flink 里的Temporary Table,可以将它理解为临时表,只在当前会话周期内有效。在下图例子中,我们创建了两个Temporary Table,读取datagen_source表中的数据,输出到blackhole_sink表。

下图是Temporary View的语法示例。前面两段是一样的临时表;第三条语句是创建了一个tmp_view,它代表从Datagen_source的查询。在Flink里面Temporary View可以理解为让SQL的书写变得更简单,它不会对数据进行一个持久化,和数据库里面View概念是不一样的。第四条语句是从 view里面读取数据并写入到sink表里。

下图是Statement set的语法示例,这个语法目前在 Flink 1.11版本里还没有,但是在VVP平台做了一些支持。

如上图,BEGIN STATEMENT SET和END这两个语句之间可以写多条 insert into语句。上图的例子是读取datagen_source 表往两张sink表同时写。这个语句提交后会启动一个完整的Flink Job,里面会有1个source和两个sink。
2.SQL的应用范围

Create Table,它注册的表会写入系统Catalog里,在VVP平台上面会写到VvpCatalog中,并进行持久化。好处是适合多个query共享元数据。
Create Temporary Table,临时表。它会写到内存版的Catalog里,不会持久化。所以它适合不需要共享元数据的场景,只给当前query使用。
Create Temporary View,主要目的是简化SQL语句。如果不通过Create Temporary View,对于逻辑复杂的SQL写起来会相当复杂,可读性也很差。
Statement Set,适合需要输出到多个下游的场景。
三、SQL 实战
接下来向大家展示销量统计的实例。如下图所示,需求是统计每小时成交量。

我们首先创建两张表,一个是源表,一个是结果表。下图是创建源表的语句,数据源来自kafka,然后定义watermark是5秒钟。

下图是结果表,也是一个kafka表。
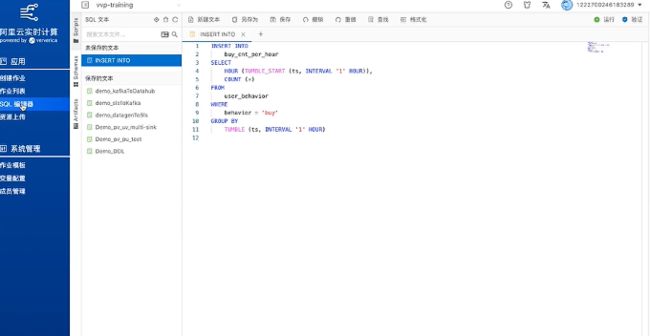
下图是查询语句,从源表读取数据后,会通过tumble window窗口聚合对数据做一个统计,这样就求出了每小时的成交量。

1.实战演示
打开VVP的界面,左侧有SQL编辑器,在这个编辑器左边有三栏,第一栏是Scripts,写SQL文本的地方;第二栏是Schemas,用来定义元数据;第三栏是Artifacts, 用来注册UDF。
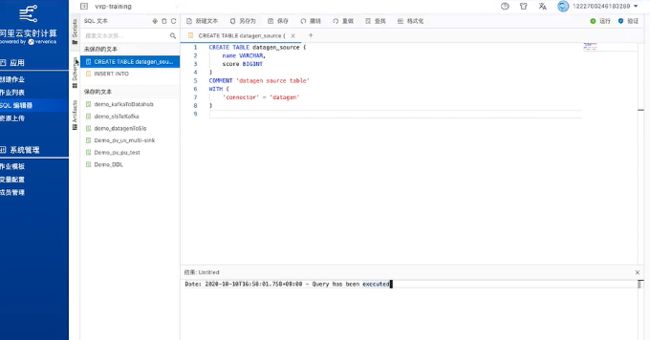
首先定义一张datagen_source的表。点击右上角的验证按钮,验证通过后点击旁边的运行。点击运行之后,可以在下面看到运行的结果,运行成功后点击左侧的Schemas,可以找到刚刚创建的datagen_source表。
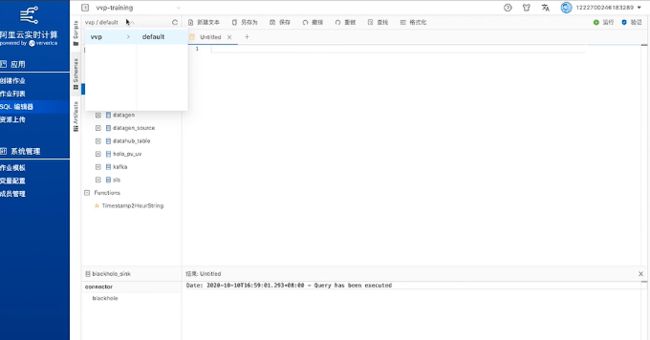
然后再创建一张sink表,connector类型是blackhole。然后验证并运行。

这样两张表都已经注册到Catalog里面去了,默认的Catalog名字是VVP,Database名字是Default。
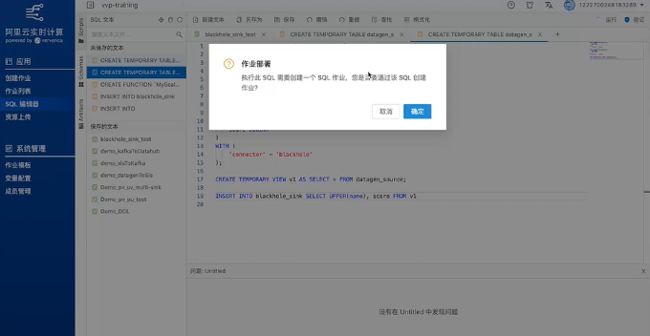
接下来就可以写SQL语句。比如说写一条INSERT INTO语句,写完之后点验证并运行。在运行这条INSERT INTO语句时,系统会提示是否要创建一个SQL作业,点击确认,补充名称等信息,SQL作业就创建好了。
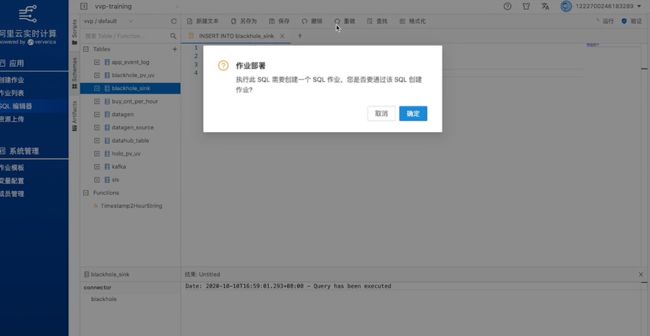
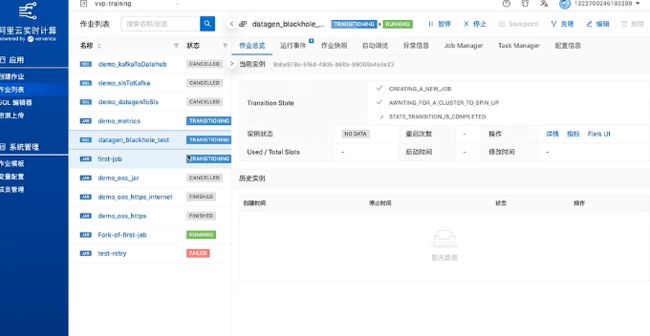
点击启动这个作业,启动过程中可以在页面上看到关于这个作业的很多信息和配置。
2.UDF实战展示
UDF开发完成后会打一个JAR包,然后点SQL编辑器左侧的Artifacts,然后点“+”号,将JAR 包上传上来。
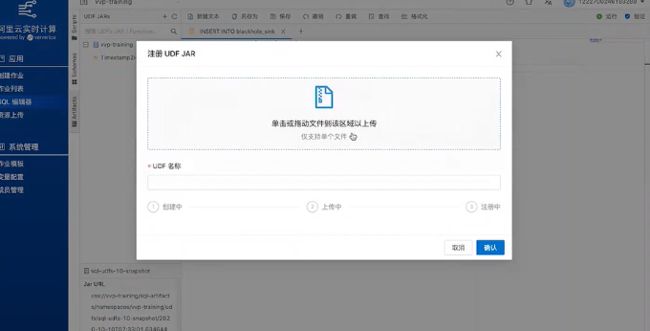
上传完毕,完善JAR 包名称等信息后,点确认完成。JAR包上传过程中,VVP系统会对JAR 包进行解析。解析之后系统会提示是否注册,勾选需要注册的内容,点击创建Function。
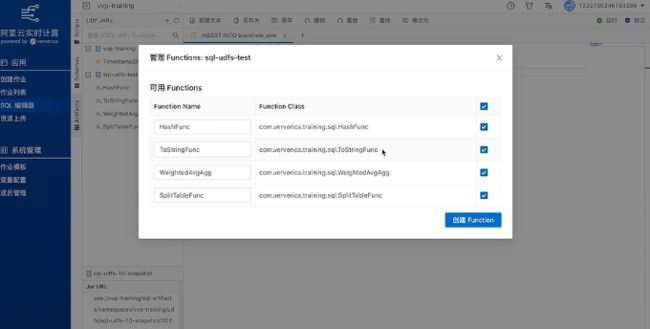
然后如下图,上面就是已注册的Function,下面是可用Function,可以选择继续注册或关掉窗口。
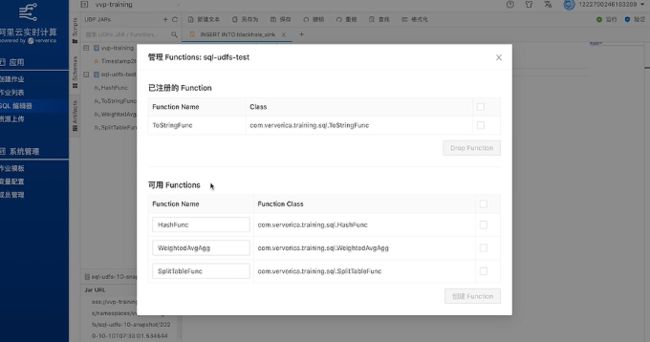
如果不需要这个函数了,可以在页面左侧找到已经注册的Function,点击右侧尾部图标,选择Drop Function。若想重新注册,有两种方法,第一可以点击管理Function;第二通过 Flink的注册函数手动注册。
用注册好的Function创建SQL作业。
在创建页面下拉可以看到很多高级配置,只修改自己需要的配置即可。

3.Temporary table的使用
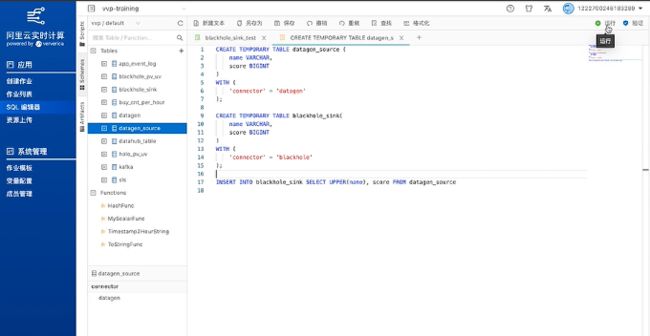
上面的例子是注册在Catalog里的,如果不想每次都在Catalog里面进行注册,那就可以直接使用 Temporary table。
如下图将table的创建和INSERT INTO全部写在一起,这样就可以直接创建一个新的SQL作业,而不用提前在Catalog里注册了。
4.Temporary View
将前面Temporary View例子页面中的语句复制到VVP平台的SQL编辑器中,直接点击运行就可以创建一个作业。
5.Statement Set
将前面Statement Set例子页面中的语句复制到编辑器中,直接点击运行就可以创建一个作业。启动后,可以通过下图看到运行情况,这个任务从一个源表中读取数据输出到了两个不同的sink表中。
6.查询实战
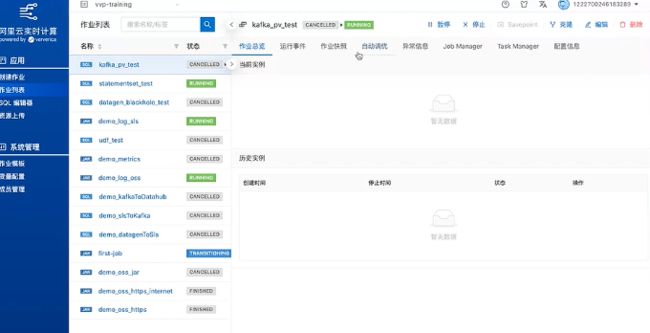
将前面SQL 实战中创建源表、结果表和查询页面的语句分别复制粘贴到VVP平台的SQL编辑器并启动运行。从下图可以看到这个读写kafka的任务运行起来了。
作者:周凯波(宝牛),阿里巴巴技术专家
原文链接
本文为阿里云原创内容,未经允许不得转载