使用python tkinter做window窗体界面程序,以及python多线程处理解决tk界面卡死
使用python Tk做窗体应用程序,以及python多线程处理
主要实现功能爬取各大视频平台的视频的一个功能
首先先建一个TkinterUI.py 文件
插入如下代码(有些方法是未用到的,个人没有删代码的习惯,后面说不定留着有用)
import os
import threading
import tkinter as tk
from tkinter import *
from tkinter import messagebox
from tkinter import ttk
from urllib3.connectionpool import xrange
from main import *
def InitApp():
print('程序启动')
# 创建文件夹
download_path = os.getcwd() + "/download/"
if not os.path.exists(download_path):
os.mkdir(download_path, 0o777)
app = Application(tk.Tk())
app.mainloop()
class Application(ttk.Frame):
process = None
def __init__(self, root):
# 绑定窗口关闭事件
root.protocol("WM_DELETE_WINDOW", self.on_closing)
super().__init__(root)
self.master = root
self.pack()
self.url = StringVar(None, '')
self.name = StringVar(None, '')
self.trueUrl = StringVar(None, '')
self.progress = StringVar(None, '0.00%')
self.progressRate = DoubleVar(None, '0')
self.speed = StringVar(None, '0.00MB/S')
self.WindowAttributes(root)
self.WindowContent()
#退出事件
def on_closing(self):
print('程序退出事件')
if messagebox.askokcancel("退出程序", "确定要退出吗?小老弟"):
sys.exit()
def WindowAttributes(self, root):
root.resizable(False, False)
root.title("视频播放器")
self.update()
# root.iconbitmap('favicon.ico')
self.set_win_center(root, 700, 200)
def WindowContent(self):
frame0 = Frame(self)
ttk.Label(frame0, text="视频链接地址:").pack(side="left")
ttk.Entry(frame0, textvariable=self.url, width=61).pack(side='left')
ttk.Button(frame0, text="播放视频", command=lambda: self.thread_it(self.resolveUrl)).pack(padx=10, side='left')
frame0.grid(pady=10, sticky=W)
frame1 = Frame(self)
ttk.Label(frame1, text="视频名称:").pack(side='left')
ttk.Entry(frame1, textvariable=self.name, width=20).pack(side='left')
ttk.Label(frame1, text='下载地址:').pack(side='left')
ttk.Entry(frame1, textvariable=self.trueUrl, width=34).pack(side='left')
ttk.Button(frame1, text='下载视频', command=lambda: self.thread_it(self.downVideo)).pack(padx=10, side='left')
frame1.grid(pady=10, sticky=W)
frame2 = Frame(self)
ttk.Label(frame2, text='下载进度:').pack(side='left')
ttk.Label(frame2, textvariable=self.progress).pack(ipadx=50, side='left')
ttk.Label(frame2, text='下载速度:').pack(side='left')
ttk.Label(frame2, textvariable=self.speed).pack(side='left')
ttk.Button(self, text='打开视频下载目录', command=lambda: self.thread_it(self.openExplorer)).place(x=510,y=100)
frame2.grid(pady=10, sticky=W)
frame3 = Frame(self)
progress = ttk.Progressbar(frame3, length="610", variable=self.progressRate, mode="determinate",
orient=tk.HORIZONTAL)
progress.pack(side='left')
frame3.grid(pady=10, sticky=W)
def openExplorer(self):
os.system("start explorer %s\download" % os.getcwd())
def resolveUrl(self):
_url = self.url.get()
if _url == '' or _url == None:
messagebox.showwarning('提示:', '请输入视频链接地址')
return
_trueUrl = getVideoUrl(_url)
self.trueUrl.set(_trueUrl)
def downVideo(self):
name = self.name.get()
if name == '' or name == None:
messagebox.showwarning('提示:', '视频名称不能为空!')
return
url = self.trueUrl.get()
if url == '' or url == None:
messagebox.showwarning('提示:', '下载地址不能为空!')
self.downloadFile(name + '.mp4', url)
# 下载文件(文件名,下载地址)
def downloadFile(self, name, url):
headers = {
'Proxy-Connection': 'keep-alive'}
r = requests.get(url, stream=True, headers=headers)
length = float(r.headers['content-length'])
f = open(os.getcwd() + r'/download/' + name, 'wb')
count = 0
count_tmp = 0
time1 = time.time()
for chunk in r.iter_content(chunk_size=512):
if chunk:
f.write(chunk)
count += len(chunk)
if time.time() - time1 > 2:
p = count / length * 100
speed = (count - count_tmp) / 1024 / 1024 / 2
count_tmp = count
self.progress.set(formatFloat(p) + '%')
self.speed.set(formatFloat(speed) + 'MB/S')
self.progressRate.set(formatFloat(p))
print(name + ': ' + formatFloat(p) + '%' + ' Speed: ' + formatFloat(speed) + 'M/S')
time1 = time.time()
f.close()
self.progress.set('0.00%')
self.progressRate.set('0')
self.speed.set('0.00MB/S')
messagebox.showinfo('提示:', '下载完成!')
# 设置窗口居中
def set_win_center(self, root, curWidth='', curHight=''):
'''
设置窗口大小,并居中显示
:param root:主窗体实例
:param curWidth:窗口宽度,非必填,默认200
:param curHight:窗口高度,非必填,默认200
:return:无
'''
if not curWidth:
'''获取窗口宽度,默认200'''
curWidth = root.winfo_width()
if not curHight:
'''获取窗口高度,默认200'''
curHight = root.winfo_height()
# print(curWidth, curHight)
# 获取屏幕宽度和高度
scn_w, scn_h = root.maxsize()
# print(scn_w, scn_h)
# 计算中心坐标
cen_x = (scn_w - curWidth) / 2
cen_y = (scn_h - curHight) / 2
# print(cen_x, cen_y)
# 设置窗口初始大小和位置
size_xy = '%dx%d+%d+%d' % (curWidth, curHight, cen_x, cen_y)
root.geometry(size_xy)
# 多线程任务
def thread_it(self, func, *args):
'''将函数打包进线程'''
# 创建
t = threading.Thread(target=func, args=args)
# 守护 !!!
t.setDaemon(False)
# 启动
t.start()
# 阻塞--卡死界面!
# t.join()
def AppMain():
InitApp()
# getVideoUrl()
AppMain()
然后再建一个简单的处理类 main.py
import os
import re
import time
import urllib
import requests
from selenium import webdriver
from tkinter import ttk
from bs4 import BeautifulSoup
import unittest
#打包时添加
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning) # 去掉ssl烦人的警告
def getVideoUrl(url):
print('正在解析...')
#打开浏览器(不弹出浏览器页面)
try:
#隐藏浏览器
option = webdriver.ChromeOptions()
# option.add_argument('headless')
# driver = webdriver.Chrome(chrome_options=option)
# 1.新版本谷歌浏览器-解决控制提示
option.add_experimental_option("useAutomationExtension", False)
option.add_experimental_option("excludeSwitches", ['enable-automation'])
# 2.旧版本浏览器-解决控制提示(待测试)
#option.add_argument('disable-infobars')
driver = webdriver.Chrome(chrome_options=option)
except:
print('谷歌浏览器启动失败!正在切换Mdge浏览器...')
try:
driver = webdriver.Edge()
except:
print('Edge浏览器启动失败!请联系开发者')
return
#打开浏览器
#driver = webdriver.Chrome()
#最大化浏览器
#driver.maximize_window()
#打开页面
#videoUrl='https://www.iqiyi.com/v_19rsxd4hwg.html'
videoUrl = url
driver.get("http://vip.52jiexi.top/?url="+videoUrl)
respone=requests.get('http://vip.52jiexi.top/?url='+videoUrl)
#正则表达获取,iframe的地址
print(respone.text)
iframe=driver.find_element_by_class_name('iframeStyle')
iframeSrc=re.search(r'src="(.*)" class', respone.text).group(1)
#iframeSrc= iframe.get_attribute('src')
print('iframeSrc:'+iframeSrc)
#iframUrl=re.findall('',respone.text)
#print(iframUrl[0].group(1))
#通过contains函数,提取匹配特定文本的所有元素
frame = driver.find_element_by_xpath("//iframe[contains(@src,'"+iframeSrc+"')]")
#进入iframe页面
driver.switch_to.frame(frame)
div=driver.find_element_by_id('player')
video= div.find_element_by_id('video')
trueUrl=video.get_attribute('src')
print(trueUrl)
#downloadPath=os.getcwd()+r'/download/text.mp4'
return trueUrl
#downloadFile('陈翔六点半之民间高手.mp4',url)
# 下载文件-urllib.request
def getDown_urllib(url, file_path):
try:
urllib.request.urlretrieve(url, filename=file_path)
return True
except urllib.error.URLError as e:
# hasttr(e, 'code'),判断e 是否有.code属性,因为不确定是不是HTTPError错误,URLError包含HTTPError,但是HTTPError以外的错误是不返回错误码(状态码)的
if hasattr(e, 'code'):
print(e.code) # 打印服务器返回的错误码(状态码),如403,404,501之类的
elif hasattr(e, 'reason'):
print(e.reason) # 打印错误原因
def formatFloat(num):
return '{:.2f}'.format(num)
接着还有一个重要的东西
程序中需要用到chromediver.exe 和MicrosoftWebDriver.exe 这个东西需要根据自己的浏览器下载不同的版本放到程序根目录下
chromediver.exe 下载:https://npm.taobao.org/mirrors/chromedriver/
下载的版本怎么看,如下图,关于chrome里面可见 88.04324
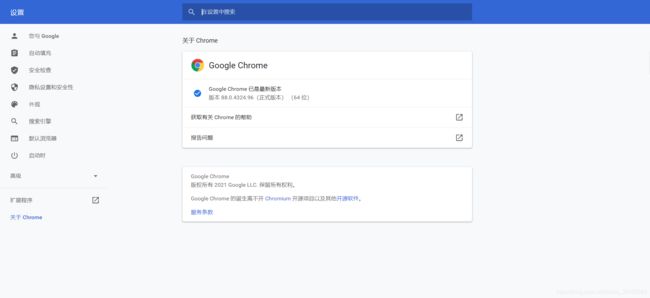
MicrosoftWebDriver.exe 下载地址:(看版本原理同chrome)
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
运行效果图
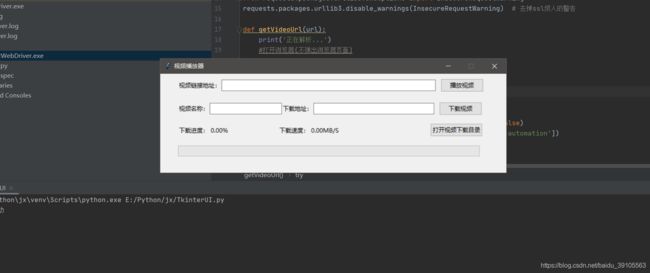
最后放一张我整个项目的目录(有些东西是自动生成的)
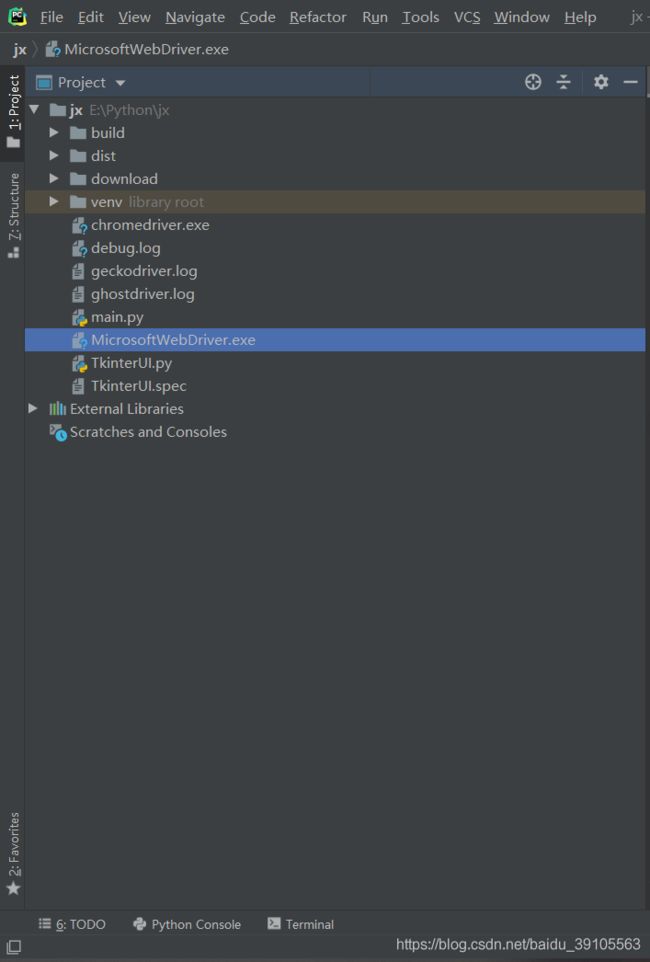
源码下载:https://download.csdn.net/download/baidu_39105563/14900592
本人所有博客中所发布的资源文件一律免费