OCR 领域新霸主?来看看它有没有这个实力
我们团队在题目的允许上,去寻找开源的 OCR 识别算法的模型,在 github 上有 AdvancedEAST 和 AttentionOCR 算法,知名度还是比较高的,还有 EasyOCR,还有 PaddleOCR。
最近参加 “中国软件杯” 的一个 OCR 识别相关的比赛。
赛题链接:http://www.cnsoftbei.com/plus/view.php?aid=516
部分要求如下:

手撕代码害怕鸭。

我们团队在题目的允许上,去寻找开源的 OCR 识别算法的模型,在 github 上有AdvancedEAST和AttentionOCR算法,知名度还是比较高的,还有EasyOCR,还有PaddleOCR。对这几种 OCR 识别算法模型做了分析,得出了一些结论,并且选择了一个精确度特别高的模型,具体是谁,还需要继续往下看。
想了解一个东西,肯定要先看一下效果如何。就像看论文一样,肯定先看摘要,如果摘要里提及的内容个关键点并不是自己想要的,那么就没必要往下看了。
她的识别效果有如下:

识别效果图
她不管你是横着、还是竖着、还是标点符号;只要是文字就能给你检测出来,精度肯定也没的说,大都在0.98以上。
她现在已经支持汉语、英语、日语、德语、法语等等语言的识别。
她关键还有直接操作式 的网页版和移动版,没编程基础,没开发环境也能让你轻松使用。
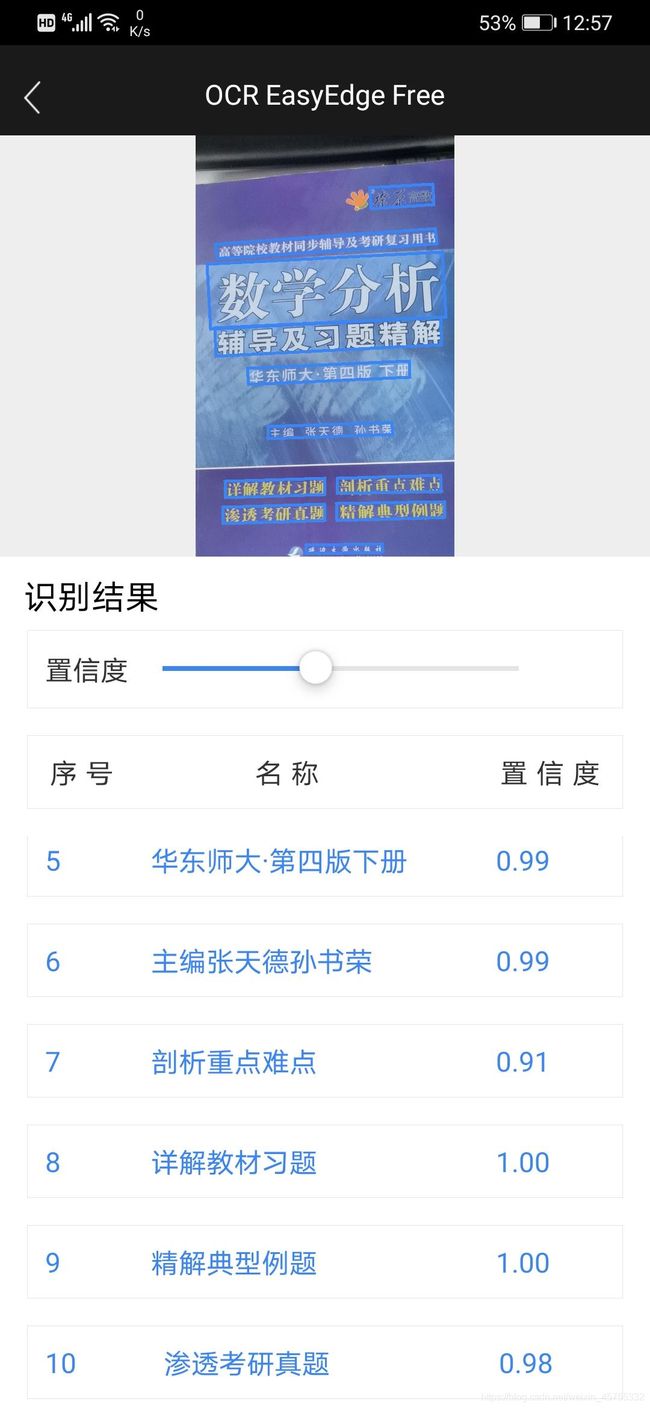
移动端识别效果图

网页版识别效果图
不得不承认,这个开源的项目真是的良品。这效果太棒了,方便、简单、实用、识别的还贼快。真的爱了。

哈哈,她看起来是不是很棒呀!
但是看这么多了,你还不知道我说的她是谁,是不是挺着急的。
她有着一层神秘的面纱,咱们慢慢的来揭开这层神秘的面纱。
她就是百度开源的PaddleOCR项目。
光说不练假把式下面就具体介绍下 OCR 以及 PaddleOCR 的优越性能和开发一个简单的示例使用步骤。
我们的参赛作品(部分 PPT 展示):
PPT可能做的不太好,大家有问题可以尽管提出来,嘿嘿,多多交流嘛!
复制代码



真的很牛逼,PaddleOCR搭配上我们自己写的NLP,简直就是无敌呀!

当然了,现在还在参赛阶段,其他的还不方便公开,如果想要源代码和其他资料的话,赛后我都可以提供,可以留言邮箱,或者加我的粉丝群,等待我上传即可。
复制代码(一)什么是 OCR
OCR——光学字符识别(Optical Character Recognition)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。
(二)应用举例
OCR技术有着丰富的应用场景,包括已经在日常生活中广泛应用的面向垂类的结构化文本识别,如车牌识别、银行卡信息识别、身份证信息识别、火车票信息识别等等,此外,通用 OCR 技术也有广泛的应用,如在视频场景中,经常使用OCR技术进行字幕自动翻译、内容安全监控等等,或者与视觉特征相结合,完成视频理解、视频搜索等任务。

(三)OCR 难点
- 1、技术难点:如
透视、缩放、弯曲、杂乱、字体、多语言、模糊等; - 2、OCR 应用常
对接海量数据,但要求数据能够得到实时处理; - 3、并且 OCR 应用
常部署在移动端或嵌入式硬件,而端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求。
如此多的难点,肯定是要解决的啊,所以有难点就有解决的办法——PaddleOCR 解决了上述所有的问题。是不是很期待的了解 PaddleOCR 呢?
下面揭开PaddleOCR的神秘面目。一起来认识一下PaddleOCR。
(一)总结介绍
- PaddleOCR 是一款超轻量中英文识别模型
- 目标是打造丰富、领先、实用的文本识别模型 / 工具库
- 3.5M 实用超轻量 OCR 系统,支持在服务器,移动,嵌入式和 IoT 设备之间进行培训和部署
- 同时支持中英文识别;支持倾斜、竖排等多种方向文字识别
- 支持 GPU、CPU 预测
- 可运行于 Linux、Windows、MacOS 等多种系统
- 用户既可以通过 PaddleHub 很便捷的直接使用该超轻量模型,也可以使用 PaddleOCR 开源套件训练自己的超轻量模型
上面是官方解释,总结几点:
- 1、体积小;
- 2、运行快;
- 3、方便简单;
- 4、性能还贼好。
(二)相关地址总结
为了方便小伙伴们后期的使用,我把我使用的网址给大家总结汇总了一下,如下所示。
该模型已经开源,而且还给了很多的教程:
1、GitHub 开源地址:https://github.com/PaddlePaddle/PaddleOCR
2、源码 PaddleHub 在线体验:https://aistudio.baidu.com/aistudio/projectdetail/507159
3、AI 快车道 2020-PaddleOCR 学习教程: aistudio.baidu.com/aistudio/ed…
4、网页版体验网址:https://www.paddlepaddle.org.cn/hub/scene/ocr
5、移动端下载二维码:

(一)PaddleOCR 项目介绍
OCR 用户的需求很难通过一个通用模型来满足,为了方便开发者使用自己的数据自定义超轻量模型,除了 3.5M 超轻量模型外(可识别 6622 个汉字),PaddleOCR 同时提供了 2 种文本检测算法(EAST、DB)、4 种文本识别算法(CRNN、Rosseta、STAR-Net、RARE),基本可以覆盖常见 OCR 任务的需求,并且算法还在持续丰富中。
特别是模型训练 / 评估中的中文 OCR 训练预测技巧,更是让人眼前一亮,点进去可以看到中文长文本识别的特殊处理、如何更换不同的 backbone 等业务实战技巧,相当符合开发者项目实战中的炼丹需求。
以上这些在其官方GitHub上有详细的使用文档教程,建议把该项目克隆到本地,直接看那个md格式的中文版文档,介绍的非常详细,从安装部署到运行测试,每一步都有,堪称最全OCR开发者文档大礼包。

首先这些教程大都是基于Linux的,对一些没有服务器或者刚接触深度学习的同学来说运行运行起来可能有点困难。

下面博主就来讲下怎么在 Windows 系统上直接运行。
(二)测试自己的数据
相信想尝试源码的同学大都要有 Python 深度学习的环境,可能有些没有 paddle 的环境,当然这安装起来也很简单,而且 pip 下载极快,毕竟是国产的框架嘛!嘿嘿。
飞桨官网 paddle 环境配置教程:https://www.paddlepaddle.org.cn/install/quick
配好环境之后将 GitHub 的源码下载或者 Git 克隆到本地,在 PaddleOCR 里建个 py 文件输入以下内容:
from paddleocr import PaddleOCR
from tools.infer.utility import draw_ocr
from PIL import Image
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
img_path = 'img/test.png'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/doc/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.show()
im_show.save('img/result.jpg')
复制代码
当然,也可以对整个文件夹里的图片内容进行检测识别并可以保存识别结果。
from paddleocr import PaddleOCR
from tools.infer.utility import draw_ocr
from PIL import Image
import os
import csv
def pre_save(img_path,save_path,csv_path):
f = open(csv_path, 'w', encoding='utf-8')
writer = csv.writer(f)
writer.writerow(["img", "result"])
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
i=0
for img in os.listdir(img_path):
print(img_path+'/'+img)
i+=1
result = ocr.ocr(img_path+'/'+img, cls=True)
image = Image.open(img_path+'/'+img).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/doc/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save(save_path+img)
al = []
for res in result:
result = res[1][:][:]
al.append(result)
print(str(al))
writer.writerow([img,str(al)])
print(i)
img_path=r'F:\lzpython\PaddleOCR-develop\doc\imgs'
save_path=r'F:\chrome\zrbdata\imgs\result1/'
csv_path=r'F:\chrome\zrbdata\imgs\result.csv'
pre_save(img_path,save_path,csv_path)
复制代码
不管你电脑是否有 GPU,用这个代码,该模型都能跑(只是有 GPU 跑的更快一些罢了)。
回归正题,我们是来分析哪个模型算法比较好的;也到了最精彩的片段。
单说肯定也看不出优秀之处,不如对比来看,嘿嘿! 现在主流的 ocr 开源项目主要有 easyocr、chineseocr_lite 当然还有大牛 paddleocr
我们分别对比下面几种:
- 1、教程的完备性对比;
- 2、易用性对比;
- 3、运行速度对比;
- 4、精准度对比;
- 5、多角度对比。
(一)教程的完备性对比
- 作为一个开发者(入门没多久的开发者),EasyOCR 的文档真的一言难尽,chineseocr_lite 的教程对 pycharm 使用者也是不太友好的
- PaddleOCR 的文档上面也贴出来了,不细说了自己看吧,从安装到训练到部署,可以说是我见过最详细的教程了。
总结:
1、EasyOCR 和 chineseocr_lite 教程不便于没基础的人使用;
2、PaddleOCR 的文档齐全,通俗易懂,适合无基础的人使用。
(二)易用性对比
PaddleOCR有网页版,移动版,可以让使用者直接用;在开发者使用时也是一样,PaddleOCR 的详细的文档可以让开发者快速理解模型,并能训练自己的数据,甚至可以增加一些功能;EasyOCR 应该也可以跟 Paddle 似的扩展不少东西,但还是苦于没有文档,没办法;chineseocr_lite 给出了网页版和 api 接口也挺方便的,但还是苦于教程不全面,不太方面配置。- 同时 PaddleOCR 给出了多种模型,可以供开发者在不同场合使用。
(三)运行速度对比
评价一个算法的好坏,我们往往都是从时空复杂度来评价。
-
用我的低配置电脑,
同样的图片,从开始识别到打印出内容,PaddleOCR耗时2.15秒,EasyOCR耗时9.96秒,这只是一张图片,几秒钟看不出啥区别,要是对很多张图片或者视频中的文字进行识别的话,差距确实有点大。 -
接下来用
多张图片进行运行时间上的对比,其主要差距有:-
在我的电脑上运行,其
运行时间上有明显差距,PaddleOCR跑了141张图片,仅仅用了6.9秒,平均耗时为0.048s,与官方给的耗时数据相吻合;而EasyOCR跑了121张图片却用了40.24秒,平均耗时为0.33s。 -
为啥 EasyOCR 用了 121 张图片呢?因为他不支持. gif 格式的图片的识别,所以我将 20 张. gif 格式的图片删了
。

这是官方给的评估耗时数据:
在GPU T4上,移动端模型只需要137ms,而在骁龙 855 移动端处理时延也只有300ms左右。 -


(四)精度对比
当然了,评价一个模型是否可以使用,肯定要看准确度了,如果识别的都不准确,那肯定是无法进行应用的。以下面这个图片为例。

(1)PaddleOCR:
PaddleOCR识别出了53段横竖文字(可以从图上看出,已经包含了该图片的所有文字了),其中错别字也就五个左右吧,置信度在0.6以下的有3段,大部分文字置信度都在0.8以上。

(2)EasyOCR:
EasyOCR识别出了 63 段文字(没图片框,看不出所有文字是否全被识别),从识别内容和精度上来看,与 paddleocr 还有一定距离。
( '红动中国WWW. REDOCN.COM', 0.14594213664531708)
( 'Hey,', 0.9193199872970581)
('The happxienffgefgiga', 0.000323598796967417)
( 'nian le fan tian', 0.537309467792511)
( 'look, theres', 0.22078940272331238)
('alot ofwild flowers', 0.057002753019332886)
('你怏乐所以我快乐', 0.531562089920044)
('开心童年乐翻夭', 0.8216490149497986)
('-野凰青', 0.004080250393599272)
('on the lawn.', 0.44294288754463196)
('暗香', 0.9942429661750793)
('.RE', 0.18314962089061737)
( 'Thats', 0.7607358694076538)
('my', 0.6383113861083984)
('frend', 0.45365384221076965)
('FOREVER', 0.7280043363571167)
('童年的伙侔', 0.7070863246917725)
复制代码-
(3)chineseocr_lite:
该模型识别出了 35 段文字,总体来说和 paddle 差不多,但是置信度上却相差了一大截,chineseocr_lite 置信度最高 0.59,大部分是 0.3~0.5 之前的。

(五)多角度对比
对于 OCR 方向开发者而言,开源 repo 最吸引人的莫过于:
- ① 高质量的预训练模型;
- ② 简单易上手的训练代码;
- ③ 好用无坑的部署能力。
简单对比一下目前主流 OCR 方向开源 repo 的核心能力
| 语种 | 预训练模型大小 | F1-Score | 端侧部署 | 自定义训练 | 支持 pip 安装 | |
|---|---|---|---|---|---|---|
| chineseocr_lite | 中英文 | 4.7M | 0.3899 | 支持 | 不支持 | 不支持 |
| easyOCR | 多语言 | 218M | 0.2214 | 不支持 | 不支持 | 支持 |
| PaddleOCR | 多语言 | 3.5M | 0.521 | 支持 | 支持 | 支持 |
- 对于语种方面,chineseocr_lite 仅支持中英文,easyOCR 的优势在于多语言支持,非常适合有小语种需求的开发者,但 PaddleOCR 支持的语种也越来越丰富,目前支持中英文、英文、法语、德语、韩语、日语等多国语言。
- 从预训练模型来看,
easyOCR目前暂无超轻量模型,chineseocr_lite最新的模型是4.7M左右,而PaddleOCR提供的3.5M是目前业界已知最轻量的; - 对于部署方面,
easyOCR模型较大不适合端侧部署,Chineseocr_lite和PaddleOCR相对较小,都具备端侧部署能力,而且目前PaddleOCR已经给出了移动端的APP应用; - 对于自定义训练,实际业务场景中,预训练模型往往不能满足需求,对于自定义训练和模型微调,但目前
只有PaddleOCR支持; - 从性能指标来看:针对 OCR 实际应用场景,包括合同,车牌,铭牌,火车票,化验单,表格,证书,街景文字,名片,数码显示屏等,收集的 300 张图像,每张图平均有 17 个文本框,PaddleOCR 的 F1-Score 超过 0.5,这个性能已经很不错了。
(六)其他分析
我们知道,训练与测试数据的一致性直接影响模型效果,为了更好的模型效果,经常需要使用自己的数据训练超轻量模型。PaddleOCR 本次开源内容除了 3.5M 超轻量模型,同时提供了 2 种文本检测算法、4 种文本识别算法,并发布了相应的 4 种文本检测模型、8 种文本识别模型,用户可以在此基础上打造自己的超轻量模型。
PaddleOCR 本次开源了多种业界知名的文本检测和识别算法,每种算法的效果都达到或超越了原作。在 ICDAR2015 文本检测公开数据集上,算法效果如下:
| 模型 | 骨干网络 | precision | recall | Hmean | 下载链接 |
|---|---|---|---|---|---|
| EAST | ResNet50_vd | 88.18% | 85.51% | 86.82% | 下载链接 |
| EAST | MobileNetV3 | 81.67% | 79.83% | 80.74% | 下载链接 |
| DB | ResNet50_vd | 83.79% | 80.65% | 82.19% | 下载链接 |
| DB | MobileNetV3 | 75.92% | 73.18% | 74.53% | 下载链接 |
| SAST | ResNet50_vd | 92.18% | 82.96% | 87.33% | 下载链接 |
在 Total-text 文本检测公开数据集上,算法效果也是惊人的好。
文本识别算法部分,借鉴 DTRB[3] 文字识别训练和评估流程,实现了 CRNN、Rosseta、STAR-Net、RARE 四种文本识别算法,覆盖了主流的基于 CTC 和基于 Attention 的两类文本识别算法。使用 MJSynth 和 SynthText 两个文字识别数据集训练,在 IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE 数据集上进行评估,算法效果如下:
| 模型 | 骨干网络 | Avg Accuracy | 模型存储命名 | 下载链接 |
|---|---|---|---|---|
| Rosetta | Resnet34_vd | 80.24% | rec_r34_vd_none_none_ctc | 下载链接 |
| Rosetta | MobileNetV3 | 78.16% | rec_mv3_none_none_ctc | 下载链接 |
| CRNN | Resnet34_vd | 82.20% | rec_r34_vd_none_bilstm_ctc | 下载链接 |
| CRNN | MobileNetV3 | 79.37% | rec_mv3_none_bilstm_ctc | 下载链接 |
| STAR-Net | Resnet34_vd | 83.93% | rec_r34_vd_tps_bilstm_ctc | 下载链接 |
| STAR-Net | MobileNetV3 | 81.56% | rec_mv3_tps_bilstm_ctc | 下载链接 |
| RARE | Resnet34_vd | 84.90% | rec_r34_vd_tps_bilstm_attn | 下载链接 |
| RARE | MobileNetV3 | 83.32% | rec_mv3_tps_bilstm_attn | 下载链接 |
| SRN | Resnet50_vd_fpn | 88.33% | rec_r50fpn_vd_none_srn | 下载链接 |
使用 LSVT 街景数据集根据真值将图 crop 出来 30w 数据,进行位置校准。此外基于 LSVT 语料生成 500w 合成数据训练中文模型,相关配置和预训练文件如下:
| 模型 | 骨干网络 | 配置文件 | 预训练模型 |
|---|---|---|---|
| 超轻量中文模型 | MobileNetV3 | rec_chinese_lite_train.yml | 下载链接 |
| 通用中文 OCR 模型 | Resnet34_vd | rec_chinese_common_train.yml | 下载链接 |
具体结果怎么出来的呢?可以参考 PaddleOCR 官方给的文档——模型训练 / 评估中的文本识别部分
PaddleOCR 总结几点:
- 体积小
- 运行快
- 部署方便
- 使用简单
- 性能还贼好
通过各种维度的对比,我们还是决定使用 PaddleOCR 做为我们参加比赛的模型,现在已经开发的差不多了,可以持续关注我,等我们参加完比赛,可以把具体所有代码给公布出来,也方便大家学习。
也可以从 github.com/trending 和 paperswithcode.com/ 看一下开源项目的排名,排名也都是很不错的,说明关注这个的人还是比较多的,说明用户群体也是很多的。
当然了,现在还在参赛阶段,其他的还不方便公开,如果想要源代码和其他资料的话,赛后我都可以提供,可以留言邮箱,赛后会一一发给大家的。
复制代码GitHub 开源地址:https://github.com/PaddlePaddle/PaddleOCR
个人建议给国产开源项目一个Star,如果喜欢也可以点下Fork,我觉得这样他们会更有动力去继续创作,创新。
复制代码嘿嘿,如果 Star 了之后,可以找我拿我参赛的源代码。也算是给国产开源项目 PaddleOCR 一份支持的力量了。