ACM Weekly 1
ACM Weekly 1
- 涉及的知识点
-
- 快速幂
-
- 理论基础
- 探寻
-
- 最初解法
- 核心解法
- 利用编程特性来优化
- 素数筛
-
- 探寻
-
- 暴力解法
- 平方逼近法
- 埃氏筛
- 欧拉筛
- 位运算
- 拓展
-
- 题目
- bitset
- 尺取法
- 参考文献
涉及的知识点
第一周练习主要涉及快速幂算法、素数筛、位运算
拓展知识点:bitset、尺取法
快速幂
理论基础
快速幂算法是建立在取模原则上的算法,其原理为下面几个公式,在此给出证明:
1. ( m × n ) % p = ( ( m % p ) × ( n % p ) ) % p (m\times n)\%p=((m\%p)\times(n\%p))\%p (m×n)%p=((m%p)×(n%p))%p
证明:
m % p = ( i × p + c ) = c m\%p=(i \times p+c)=c m%p=(i×p+c)=c
n % p = ( j × p + d ) = d n\%p=(j \times p+d)=d n%p=(j×p+d)=d
( ( m % p ) × ( n % p ) ) % p = ( c × d ) % p ((m\%p)\times(n\%p))\%p=(c \times d)\%p ((m%p)×(n%p))%p=(c×d)%p
( m × n ) % p = ( ( i × p + c ) × ( j × p + d ) ) % p = ( i × j × p + ( j × d + i × c ) × p + c × d ) % p = ( c × d ) % p (m\times n)\%p=((i\times p+c)\times(j\times p+d))\%p=(i\times j\times p+(j\times d+i\times c)\times p+c\times d)\%p=(c\times d)\%p (m×n)%p=((i×p+c)×(j×p+d))%p=(i×j×p+(j×d+i×c)×p+c×d)%p=(c×d)%p
( m − / + n ) % p = ( ( m % p ) − / + ( n % p ) ) % p (m-/+ n)\%p=((m\%p)-/+(n\%p))\%p (m−/+n)%p=((m%p)−/+(n%p))%p
2. ( ( m % p ) + / − ( n % p ) ) % p = ( c + / − d ) % p ((m\%p)+/-(n\%p))\%p=(c+/-d)\%p ((m%p)+/−(n%p))%p=(c+/−d)%p
证明:
( m + / − n ) % p = ( i × p + c + / − j × p + d ) % p = ( ( i + j ) × p + c + / − d ) % p = ( c + / − d ) % p (m+/-n)\%p=(i \times p+c+/-j \times p+d)\%p=((i+j)\times p+c+/-d)\%p=(c+/-d)\%p (m+/−n)%p=(i×p+c+/−j×p+d)%p=((i+j)×p+c+/−d)%p=(c+/−d)%p
探寻
快速幂一般所解决的是求算式 a b % p a^b\%p ab%p的值的问题,通过上述运算法则的运用,我们可以尝试用代码的方式来实现快速幂问题的解答
最初解法
利用积之余为余之积的性质,可以得到最初的解法,通过循环来进行逐个消去。
代码
int result=1;
for(int i=1;i<=power;i++)
{
result=base;
result=result%p;//p为取余的数,若不进行取余操作,相当于乘了power次*
return result%p;
}
//根据公式逐步分解
核心解法
因计算an需n次循环,可将其变为(a2)n/2,则运算的结果只需n/2次,以此类推,将an分解,最后得出求出的幂结果实际上就是在变化过程中所有当指数为奇数时底数的乘积。
代码
int result=1;
while(power)
{
if(power^1)//如果是偶数
{
power>>=1;//除2
base=base*base%p;//底数平方
}
else//如果奇数
{
power--;//构造偶数,多的一个1单独处理
result=result*base%p;
power>>=1;//变成偶数了,同if
base=base*base%1000;
}
return result;
}
//根据公式逐步分解
利用编程特性来优化
编程语言中可以采用位运算的性质,对快速幂算法的速度进行进一步提升。
代码
result=1;
while(power)
{
if(power^0)
result=result*base%p;
power>>=1;
base=base*base%p;
}
return result;
//根据公式(3)逐步分解
例题1(POJ3641)

题目大意:给出两个数p,a,如果a的p次方对p取余等于a并且p不是素数,输出yes,否则输出no
思路:首先判断p是否为质数,之后利用快速幂计算出ap对p取余的结果,直接判断结果与a是否相等
代码
#include 例题2(POJ1995)

题目大意:给出N个底数指数对,计算它们的和对M取余的结果
思路:多个快速幂累加
代码
#include 素数筛
素数筛的基本应用是给定一个数据范围,求出该范围内哪些数是质数以及其数量,有多重方法可以实现目的。
探寻
素数筛的方法多样,但时间复杂度各个不一,下面对其进行探究
暴力解法
利用素数的定义,逐个判断,从2到n(针对一个数)
代码
for(int i=2;i<=n;i++)
if(n%i==0)
return false;
return true;
平方逼近法
通过平方逼近n,减少不必要的筛选, n n n\sqrt n nn(针对一个数)
代码
for(int i=2;i<=n/i;i++)
if(n%i==0)
return false;
return true;
埃氏筛
当我们找到一个合数时,该合数的倍数肯定都不是质数,当找到一个质数时,其倍数也不为质数,以此基准来排除
代码
bool Primes[1e6]={
1,1};
for(int i=2;i<=n;i++)
if(!Primes[i])//如果没被筛掉,那肯定是质数
for(int j=2*i;j<=r/j;j+=i)//筛掉它的倍数
Primes[j]=true;
欧拉筛
欧拉筛的时间复杂度为 O ( n ) O(n) O(n),是非常快速的算法,和埃氏筛有类似的地方,相当于埃氏筛的深层简化
原理:最小质因数×最大因数(非自身)=该合数
代码
bool IsPrime[121212];//真值为素数
int Prime[121212],ans;
void Choose(int n)//筛选到n
{
memset(IsPrime,1,sizeof(IsPrime));//初始化
//假设每个数为素数
IsPrime[1]=IsPrime[0]=1;
for(int i=2;i<=n;i++)
{
if(IsPrime[i])//如果这个数没筛掉,那么将其加入素数序列
Prime[++ans]=i;
for(int j=1;j<=ans&&i*Prime[j]<=n;j++)
{
IsPrime[i*Prime[j]]=0;
if(!i%Prime[j])break;
}
}
}
对于给定范围内的一个数i,如果它并未被筛去,那么我们便可以它为基础来筛去更多的数,在代码中,我们每次以所遍历到的数i作为基础,首先,如果它是素数,那么直接加入序列中,之后,我们期望它符合最小质因数×最大因数(非自身)=该合数的原理,以每个已筛出的素数为最小质因数作为前提,那么,在循环中Prime[j](最小质因数)×i(最大因数)被筛去,为了确保这一条件,添加了if(!i%Prime[j])break; 这一行,为什么要停下呢?因为在其之后是不属于先前所提到的原理的,注意,我们在筛选的过程中是必须遵循最小质因数×最大因数(非自身)=该合数的原则的,并不是说之后的数字不能通过这一层被筛,而是为了避免重复,限定了条件避免重复筛去。
证明这一行代码可以符合该原理
证明如下:
1.i×Prime[J] (j
i×Prime[J]=Prime[j]×i/Prime[j]×Prime[J],Prime[j]才是最小质因数,Prime[J]不是
2.i×Prime[t] (t
Primep[t]是最小质因数,Prime[j]不是
3.i的最小质因数为Prime[j]
倘若有更小的质因数,则应当在j之前中断
正确性证明
证明该算法的正确性,即证明所有的合数在筛选的过程中都被筛去
对于一个合数X,X=Y×Prime,而Y的最小质因数应大于等于Prime,那么当外层到i=Y时,内层遍历所有小于等于Y的质数,因为Y的最小质因数不小于Prime,所以i在内层到Prime之前不会break,即因为内层会遍历到B的最小质因数,而B的最小质因数大于Prime,所以必定会遍历到Prime,而此时i=B,那么此时便有i×Prime=B×Prime被筛去
O(n)时间复杂度证明
欧拉筛的原理为"X×质数"来筛去合数,又由先前的证明,所有合数必然可以被筛去,那么探求时间复杂度的关键便是同一个合数是否会被另一种"X×质数"组合筛去从而产生重复 更加详细的说明请参考最后文献 例题1(POJ2739) 思路:先筛选出数据范围内的数据,随后根据查询进行在线累和进行判断 代码 例题2(POJ3126) 题目大意:给出一对数A,B(四位数),判断它们是否都为质数且A能否通过每次只变化一位,变化多次来达到B 思路:首先筛选出10000以内素数,之后用BFS的思路去处理 代码 例题3(POJ2689) 题目大意:给出一个上界与下界,判断在这个上下界之中存在的相邻素数的最大素数对与最小素数对 思路:首先,题目所涉及到的数据过于庞大,直接筛选出给定范围内的所有素数并不可行,但是对于给定的L,R区间,区间长度相对于整个范围较小,所以我们可以只筛选出一部分来使用,筛选的素数范围为1~ R \sqrt R R。我们的目标是L~R内的所有素数,换言之,我们的目标是筛去L ~R内的所有合数,那么,筛去这些合数,我们只需要1 ~ R \sqrt R R内的素数即可,也就是说,我们先筛出1 ~ R \sqrt R R的素数,再用这些素数来筛出L~R内的素数,下面给出证明: 对于一个合数X,它可以分为两个质因子相乘,一个大于 X \sqrt X X,设为B,一个设为最小质因子小于 X \sqrt X X,设为S,对于L ~R范围,则所有S< R \sqrt R R,在欧拉筛中,在到达B之前,S必定已经筛去了X(由上述的欧拉筛证明可知) 那么,在筛选出所有的素数之后,对所求的相邻素数进行两两比对并记录,最后可得出结果 代码 例题1(POJ1753) 题目大意:给出一个4×4的期盼,每个位置非正即反,现在进行操作,每次翻转以一枚棋子为中心的上下左右中五颗棋子,求出至少翻转多少次才能使所有棋子状态相同 思路:将棋盘的状态看做一个16位的二进制数,每4位为一行,使用BFS,每次对一层进行拓展来方便记录层数 代码 例题2(POJ2453) 题目大意:给出一个数I,找出一最小的大于I且对应二进制位与I相等的数 思路:该题有两种思路,第一种为暴力解法,直接从大于I的序列中遍历寻找,第二种使用贪心,为了找到第一个比I大,而二进制数1的个数又等于I的数,首先需要找到I中第一个二进制位为1的地方(从小到大),如果在0位开始变化的话,势必会使一个高位的1变成一个低位的1,这样得出来的数不会大于I,找到第一个个1位后,就需要找到之后的第一个0位,以此来将首个1位移动到第一个比它大的0位上,将修改后的对应二进制位数转换为十进制输出便是答案 代码(暴力) 代码(贪心) 本周拓展包括了两道竞赛题目以及bitset的相关用法、竞赛书上提及的尺取法,属于课后延伸内容 HDU 6702 题目大意:找到最小 C,使(A xor C)& (B xor C)最小(xor为异或) 思路:需要求的是 ( A ⊕ C ) & ( B ⊕ C ) (A\oplus C)\& (B\oplus C) (A⊕C)&(B⊕C),以某一位来看,设某一位结果为X,进行化简 代码 HDU 6186 题目大意: 从 n 个数中去除一个数后,计算它们的与、或、异或值 思路:第一种方法是利用前缀和的思想,预处理前缀后缀与或异或的值的值,对于每个查询直接输出,第二种方法是利用位运算的性质,我们先得到所有的数的与或异或值。接下来考虑每次查询,对于异或而言,只需要再异或一次 p 位置上的数,对于与而言,只有当 a p a_p ap的这一位为 0 并且所有数在这一位为 0 的个数为 1 时,它才能对这一位产生决定性影响,同理,对于或而言,只有当 a p a_p ap这一位为 1 并且所有数在这一位为 1 的个数为 1 时,它才能对这一位产生决定性影响。所以我们预处理出每一位的 1 和 0 的个数,对于每个 p 位置的数,判断它能否产生决定性影响即可。 证明异或的只需异或一次p即可: 代码(前缀和思想) 代码(位运算) 这一部分具体参考后面给出的文献,只强调一点bitset0位为低位 该知识点以POJ 3061为例 题目大意:给出长度为n的数列整数 a 0 , a 1 , . . . a n − 1 a_0,a_1,...a_{n-1} a0,a1,...an−1以及整数S,求出总和不小于S的连续子序列的长度的最小值,如果解不存在,输出0 思路:第一种方法是前缀和,先提前计算好和,可以确定所需序列的起点,之后采用二分查找的方法确定序列和不小于S的结尾的最小值,时间复杂度为O(nlogn),第二种方法便是尺取法,对于一个区间来说,如果它已经满足序列和大于等于S,其右端点就没有必要再向右延伸,此时只需要左端点向右拓展,进行试探,观察是否能缩短区间,如果右端点到达总区间末尾序列和仍然小于S,则中断,时间复杂度为O(n) 代码(前缀和) 代码(尺取法)
假设目标合数为T,存在一质数p,使得p×A=Prime×B,因为Prime为T的最小质因数,所以LHS=p×A/Prime×Prime,即A可以整除Prime,且A
题目大意:给出一系列的数,判断是否有连续的质数序列的和能满足等于本身的条件,如果有,则求出有多少个#include 
#include 
#include 位运算

#include 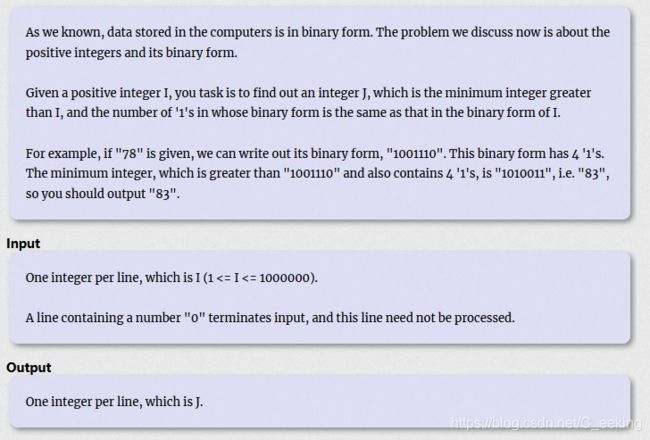
#include #include 拓展
题目
X = ( A ⊕ C ) & ( B ⊕ C ) = ( A B C ˉ + A ˉ B ˉ C ) X=(A\oplus C)\& (B\oplus C)=(AB\bar{C}+\bar{A}\bar{B}C) X=(A⊕C)&(B⊕C)=(ABCˉ+AˉBˉC)
要求取最小值,所以X尽量为0,根据真值表可得AB相等时, X = C = A & B X=C=A\&B X=C=A&B,不等时为0,所以取C为A&B即可,考虑特殊情况,注意使用long long#include
设所有数异或的总结果为X,p之前的异或结果为Pre,p之后的异或结果为Aft,X=Pre^p^Aft
X^p=Pre^p^Aft^p=Pre^p^Aft^p=Pre^p^p^Aft=Pre^0^Aft=Pre^Aft#include #include bitset
尺取法
#include #include 参考文献