Pytorch入门——手把手教你MNIST手写数字识别
MNIST手写数字识别教程
要开始带组内的小朋友了,特意出一个Pytorch教程来指导一下
[!] 这里是实战教程,默认读者已经学会了部分深度学习原理,若有不懂的地方可以先停下来查查资料
本文仅仅放出该教程
全部代码请看 Pytorch入门——MNIST手写数字识别代码
目录
- MNIST手写数字识别教程
-
- 1 什么是MNIST?
- 2 使用Pytorch实现手写数字识别
-
- 2.1 任务目的
- 2.2 开发环境
- 2.3 实现流程
- 3 具体代码实现
-
- 3.1 数据预处理部分
-
- 3.1.1 初始化全局变量
- 3.1.2 构建数据集
- 3.2 训练部分
-
- 3.2.1 构建模型
- 3.2.2 构建迭代器与损失函数
- 3.2.3 构建训练循环
-
- 3.2.3.1 训练部分代码
- 3.2.3.2 测试部分代码
- 3.2.3.3 训练循环代码
- 3.3 数据预后处理部分
-
- 3.3.1 训练结果可视化
- 3.3.2 保存模型
- 4 完整代码
1 什么是MNIST?
MNIST是计算机视觉领域中最为基础的一个数据集,也是很多人第一个神经网络模型
MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据集,包含了60,000个样本的训练集以及10,000个样本的测试集。

MNIST中所有样本都会将原本28*28的灰度图转换为长度为784的一维向量作为输入,其中每个元素分别对应了灰度图中的灰度值。MNIST使用一个长度为10的one-hot向量作为该样本所对应的标签,其中向量索引值对应了该样本以该索引为结果的预测概率。
2 使用Pytorch实现手写数字识别
2.1 任务目的
如本文标题所示,MNIST手写数字识别的主要目为:训练出一个模型,让这个模型能够对手写数字图片进行分类。
2.2 开发环境
为了实现本文的目标,你需要安装如下Python库
1. pytorch >= '1.4.0'
2. torchvision
3. tqdm
4. matplotlib
Pytorch官网上有着详细的安装教程,你可以看着来进行安装 - 传送门
tqdm库是Python的一个动态显示库,我们需要他来进行训练可视化
pip install tqdm
matplotlib库是Python的一个数据可视化库,我们需要他来进行训练结果可视化
pip install matploblib
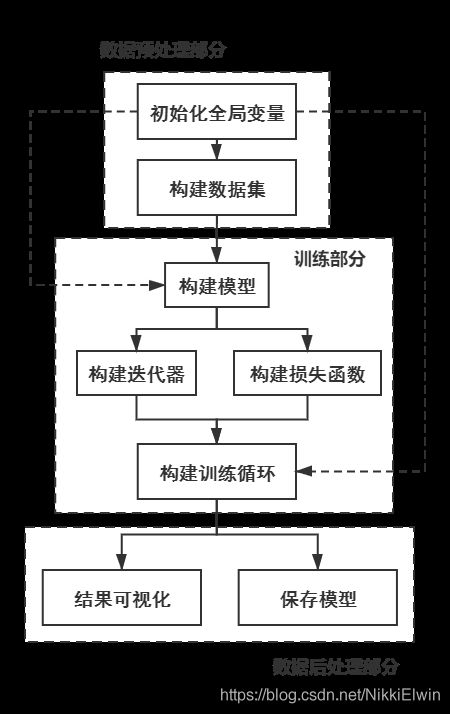
2.3 实现流程
本代码的实现流程如下所示
3 具体代码实现
3.1 数据预处理部分
3.1.1 初始化全局变量
首先,我们需要导入上述提到的库,为了能够更全面的展示程序中每个函数的具体来源,因此本项目中的库不采用缩写的方式
import torch
import torchvision
from tqdm import tqdm
import matplotlib
对于Pytorch,我们需要手动去定义它是在CPU还是在GPU中训练;同时,我们需要使用到torchvision中的图片处理库torchvision.transforms来将图片转换为适用于网络的张量。
#如果网络能在GPU中训练,就使用GPU;否则使用CPU进行训练
device = "cuda:0" if torch.cuda.is_available() else "cpu"
#这个函数包括了两个操作:将图片转换为张量,以及将图片进行归一化处理
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean = [0.5],std = [0.5])])
3.1.2 构建数据集
torchvision中的torchvision.datasets库中提供了MNIST数据集的下载地址,因此我们可以直接二调用对应的函数来下载MNIST的训练集和测试集
path = './data/' #数据集下载后保存的目录
#下载训练集和测试集
trainData = torchvision.datasets.MNIST(path,train = True,transform = transform,download = True)
testData = torchvision.datasets.MNIST(path,train = False,transform = transform)
Pytorch中提供了一种叫做DataLoader的方法来让我们进行训练,该方法自动将数据集打包成为迭代器,能够让我们很方便地进行后续的训练处理
#设定每一个Batch的大小
BATCH_SIZE = 256
#构建数据集和测试集的DataLoader
trainDataLoader = torch.utils.data.DataLoader(dataset = trainData,batch_size = BATCH_SIZE,shuffle = True)
testDataLoader = torch.utils.data.DataLoader(dataset = testData,batch_size = BATCH_SIZE)
至此,数据集已经准备完毕。
3.2 训练部分
3.2.1 构建模型
在这里使用的是一个简单的卷积神经网络,其结构如下
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.model = torch.nn.Sequential(
#The size of the picture is 28x28
torch.nn.Conv2d(in_channels = 1,out_channels = 16,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2,stride = 2),
#The size of the picture is 14x14
torch.nn.Conv2d(in_channels = 16,out_channels = 32,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2,stride = 2),
#The size of the picture is 7x7
torch.nn.Conv2d(in_channels = 32,out_channels = 64,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.Flatten(),
torch.nn.Linear(in_features = 7 * 7 * 64,out_features = 128),
torch.nn.ReLU(),
torch.nn.Linear(in_features = 128,out_features = 10),
torch.nn.Softmax(dim=1)
)
def forward(self,input):
output = self.model(input)
return output
其中torch.nn.Sequential函数能够自动将层数合并为一个模型,对于新手而言这种方式能够减少非常多的计算过程
随后,我们需要构建一个模型实例
net = Net()
#将模型转换到device中,并将其结构显示出来
print(net.to(device))
to() 方法用于将张量放入到指定的设备(如CPU或GPU中),记住的是:不同设备的张量是无法进行运算的
如果一切正常,那么输出结果如下
Net(
(model): Sequential(
(0): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): Flatten(start_dim=1, end_dim=-1)
(9): Linear(in_features=3136, out_features=128, bias=True)
(10): ReLU()
(11): Linear(in_features=128, out_features=10, bias=True)
(12): Softmax(dim=1)
)
)
读者也可以根据自己的兴趣去修改网络结构。
3.2.2 构建迭代器与损失函数
对于简单的多分类任务,我们可以使用交叉熵损失来作为损失函数;
而对于迭代器而言,我们可以使用Adam迭代器
lossF = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters())
模型在构建迭代器的时候需要将所有参数传入到迭代器中,可以通过**net.parameters()**方法来得到模型的所有参数。
3.2.3 构建训练循环
训练循环是很多新手最头疼的地方,因此将会着重讲解这一部分
对于一个普通的训练循环,他的流程如下:
⋯ → 训 练 → 验 证 → 下 一 轮 训 练 → 下 一 轮 验 证 → … \dots\rightarrow 训练\rightarrow 验证 \rightarrow 下一轮训练 \rightarrow 下一轮验证 \rightarrow \dots ⋯→训练→验证→下一轮训练→下一轮验证→…
我们根据这个流程,构建一个循环框架
EPOCHS = 10 #总的循环
for epoch in range(1,EPOCHS + 1):
"""
训练部分
"""
"""
测试部分
"""
3.2.3.1 训练部分代码
对于训练部分,我们可以构造的模块为
#构建tqdm进度条
processBar = tqdm(trainDataLoader,unit = 'step')
#打开网络的训练模式
net.train(True)
#开始对训练集的DataLoader进行迭代
for step,(trainImgs,labels) in enumerate(processBar):
#将图像和标签传输进device中
trainImgs = trainImgs.to(device)
labels = labels.to(device)
#清空模型的梯度
net.zero_grad()
#对模型进行前向推理
outputs = net(trainImgs)
#计算本轮推理的Loss值
loss = lossF(outputs,labels)
#计算本轮推理的准确率
predictions = torch.argmax(outputs, dim = 1)
accuracy = torch.sum(predictions == labels)/labels.shape[0]
#进行反向传播求出模型参数的梯度
loss.backward()
#使用迭代器更新模型权重
optimizer.step()
#将本step结果进行可视化处理
processBar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item()))
3.2.3.2 测试部分代码
对于测试部分,我们可以构造的模块为
#构造临时变量
correct,totalLoss = 0,0
#关闭模型的训练状态
net.train(False)
#对测试集的DataLoader进行迭代
for testImgs,labels in testDataLoader:
testImgs = testImgs.to(device)
labels = labels.to(device)
outputs = net(testImgs)
loss = lossF(outputs,labels)
predictions = torch.argmax(outputs,dim = 1)
#存储测试结果
totalLoss += loss
correct += torch.sum(predictions == labels)
#计算总测试的平均准确率
testAccuracy = correct/(BATCH_SIZE * len(testDataLoader))
#计算总测试的平均Loss
testLoss = totalLoss/len(testDataLoader)
#将本step结果进行可视化处理
processBar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f, Test Loss: %.4f, Test Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item(),testLoss.item(),testAccuracy.item()))
3.2.3.3 训练循环代码
将上述两个循环进行结合,就是最终的训练循环代码了
EPOCHS = 10
#存储训练过程
history = {
'Test Loss':[],'Test Accuracy':[]}
for epoch in range(1,EPOCHS + 1):
processBar = tqdm(trainDataLoader,unit = 'step')
net.train(True)
for step,(trainImgs,labels) in enumerate(processBar):
trainImgs = trainImgs.to(device)
labels = labels.to(device)
net.zero_grad()
outputs = net(trainImgs)
loss = lossF(outputs,labels)
predictions = torch.argmax(outputs, dim = 1)
accuracy = torch.sum(predictions == labels)/labels.shape[0]
loss.backward()
optimizer.step()
processBar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item()))
if step == len(processBar)-1:
correct,totalLoss = 0,0
net.train(False)
for testImgs,labels in testDataLoader:
testImgs = testImgs.to(device)
labels = labels.to(device)
outputs = net(testImgs)
loss = lossF(outputs,labels)
predictions = torch.argmax(outputs,dim = 1)
totalLoss += loss
correct += torch.sum(predictions == labels)
testAccuracy = correct/(BATCH_SIZE * len(testDataLoader))
testLoss = totalLoss/len(testDataLoader)
history['Test Loss'].append(testLoss.item())
history['Test Accuracy'].append(testAccuracy.item())
processBar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f, Test Loss: %.4f, Test Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item(),testLoss.item(),testAccuracy.item()))
processBar.close()
假如一切正常,能看到以下的训练过程
[1/10] Loss: 1.4614, Acc: 0.9479, Test Loss: 1.5050, Test Acc: 0.9355: 100%|███████| 235/235 [00:12<00:00, 19.04step/s]
[2/10] Loss: 1.4612, Acc: 0.9792, Test Loss: 1.4843, Test Acc: 0.9544: 100%|███████| 235/235 [00:10<00:00, 21.72step/s]
[3/10] Loss: 1.4612, Acc: 0.9688, Test Loss: 1.4824, Test Acc: 0.9571: 100%|███████| 235/235 [00:10<00:00, 22.30step/s]
[4/10] Loss: 1.4612, Acc: 1.0000, Test Loss: 1.4806, Test Acc: 0.9581: 100%|███████| 235/235 [00:10<00:00, 22.40step/s]
[5/10] Loss: 1.4915, Acc: 0.9688: 36%|████████████████ | 84/235 [00:03<00:06, 24.97step/s]
3.3 数据预后处理部分
数据后处理的部分包括训练结果可视化以及模型保存两个环节
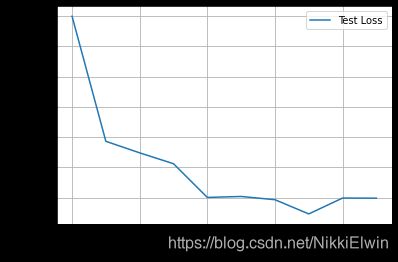
3.3.1 训练结果可视化
我们需要使用到matplotlib来对结果进行可视化
#对测试Loss进行可视化
matplotlib.pyplot.plot(history['Test Loss'],label = 'Test Loss')
matplotlib.pyplot.legend(loc='best')
matplotlib.pyplot.grid(True)
matplotlib.pyplot.xlabel('Epoch')
matplotlib.pyplot.ylabel('Loss')
matplotlib.pyplot.show()
#对测试准确率进行可视化
matplotlib.pyplot.plot(history['Test Accuracy'],color = 'red',label = 'Test Accuracy')
matplotlib.pyplot.legend(loc='best')
matplotlib.pyplot.grid(True)
matplotlib.pyplot.xlabel('Epoch')
matplotlib.pyplot.ylabel('Accuracy')
matplotlib.pyplot.show()
结果如下图所示

3.3.2 保存模型
对于新手而言,我们选择直接保存整个模型
torch.save(net,'./model.pth')
若想对这一方面有进一步的了解,可以参考这篇文章 传送门
4 完整代码
由于篇幅所限,完整的代码我将放在另一个博客中
Pytorch入门——MNIST手写数字识别代码