零基础班第十七课 - hive进阶
第一章:上次课回顾
第二章:Hive DDL(分区表)
-
2.1 分区表简介
-
2.2 分区表的使用
- 2.2.1 第一种:创建分区表、把数据加载至分区
- 2.2.2 第二种:在hdfs上创建文件目录,上传文件,alter刷新分区信息 -
2.3 多级分区
-
2.4 动态分区
- 2.4.1 抛砖引玉
- 2.4.2 动态分区的使用
第三章:Hive的其它连接使用方式
第四章:Hive建表时的一些数据类型
第一章:上次课回顾
零基础班第十六课 - Hive DML详解:
https://blog.csdn.net/zhikanjiani/article/details/89391164
回顾:上次课主要讲了如何把数据加载到Hive中去,对于离线批处理,要采用load的方式,而不是insert。
生产背景:BI人员从关系型数据库转型大数据,使用关系型数据库方式来操作大数据,在hive中采用insert方式插入后产生一堆小文件,
问:该如何处理?
-
在hive0.14版本后支持insert(性能不行,还会产生小文件),采用load方式加载,此时我们可以进行数据的查询,导出数据后期采用sqoop。
-
还讲了一些基本的SQL用法,groupby分组(select中出现的字段一定要在groupby中体现或在聚合函数中出现)
第二章:Hive DDL(分区表)
2.1 分区表的简介
为什么采用分区表:
-
eg:举例拨打10086客服热线,我们按1 --> 业务查询 (第一层)–> 按1(余额查询)(第二层),我们的每一步操作都是有一条记录的;我们拨打人工,专席还会帮你转接;账号高级还会有专席来接听。
-
如果这些话务记录全部都存储到一张表上去,那就是等死,数据量是非常大的。
-
传统做法:日志记录会存储到关系型数据库,至少要做到分表(以天为单位进行分表)。
call_record_20190418 //4月18号的记录做一张表
call_record_20190419 //4月19号的记录做一张表 -
查询的话给定时间范围,就会去拼接表,相比查询整个表,性能肯定是高出不少的,比如select * from where day between 20190418 and 20190420;
大数据中hive、spark都需要分区表:
- 在Hive中任何一张表对应到HDFS上不是一个文件夹就是一个文件
举例:
1、有如下两张分区表:
/user/hive/warehouse/emp/d=20190418
/user/hive/warehouse/emp/d=20190419
2、查找d='20190418’这天的记录
select * from table where d=‘20190418’
3、这样的话不用去全表扫描,带来的性能提升是非常大的
大数据中需要的优化:
瓶颈:IO:disk network 磁盘IO(像分区表这种方式就能减少很多的数据读取操作)和网络IO
查询的话可以以天为单位进行查询
2.2 分区表的使用
前提:数据准备:
- 我们接下来要创建一个话务投诉分区表,有如下几个字段,“投诉事件编号”、“投诉事件”、
10703430736748 2018-04-01 06:01:15
10703430736749 2018-04-01 07:01:15
10703430736750 2018-04-01 08:01:15
10703430736751 2018-04-01 09:01:15
第一步:创建分区表
2.2.1 第一种:创建分区表、把数据加载至分区
语法定义:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name] table_name
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ....)]
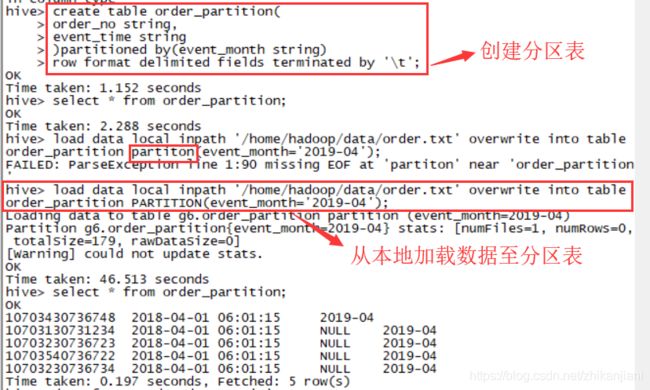
开始创建order_partition分区表:
create table order_partition(
order_no string,
event_time string
) partitioned by(event_month string)
row format delimited fields terminated by '\t';
创建订单分区表,表中两个字段:订单编号字段以及订单时间字段;创建的分区表按月分隔;注意字段类型要写,’\t’指的是要加载进来的数据以tab键分割。
第二步:load加载数据进分区
语法如下:
- 需要到Hive DML中的load中去查看语法
LOAD DATA LOCAL INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1), partcol2=val2....]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
自己写SQL把数据加载进去:
load data local inpath '/home/hadoop/data/order.txt'
overwrite into table order_partiton
PARTITION(event_month='2019-04');
查询order_partition表信息:
- desc formatted order_partition;
- 我们发现这个分区表是存储在hdfs上的
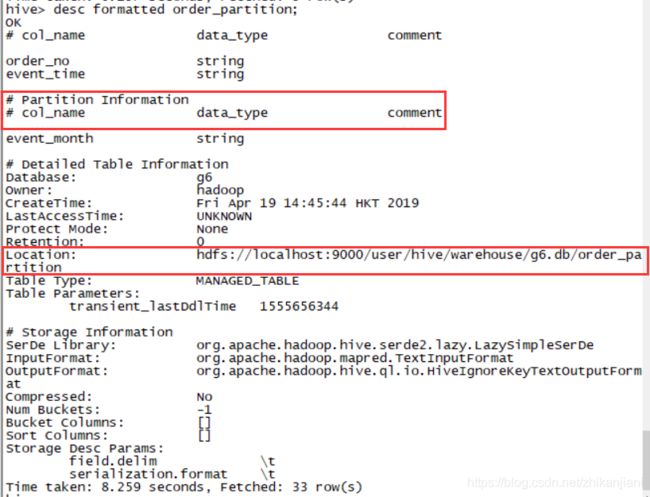
1、查看我们创建的这个分区表的信息,然后我们发现数据是存储在/event_month=2019-04下面的。
- hadoop fs -ls /user/hive/warehouse/g6.db/order_partition

2、真实数据是存放在如下路径下的:
路径:hadoop fs -ls /usr/hive/warehouse/g6.db/order_partition/event_month=2019-04
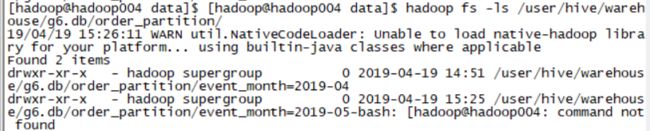
3、这个2019-04其实是一个伪列:

2.2.2 第二种:在hdfs上创建文件目录,上传文件,alter刷新分区信息
第一种方式是Hive下建好分区,然后把数据加载进去;此处我们来讲第二种方式:先在HDFS上创建好目录,把数据put上去,再在Hive中查询。
前提:数据准备
0、在hdfs上创建目录,把数据put上去
- hdfs dfs -mkdir -p /user/hive/warehouse/ruozeg6.db/order_partition/2019-05
- hdfs dfs -put order.txt /user/hive/warehouse/ruozeg6.db/order_partition/2019-05
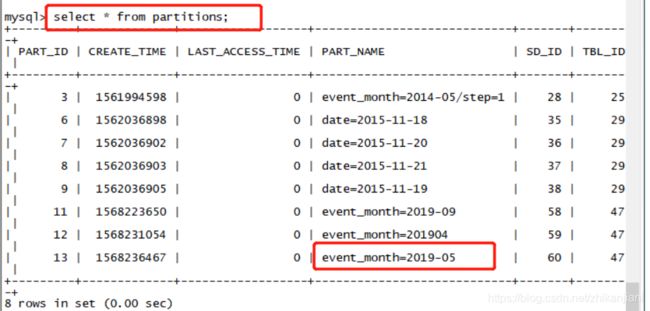
1、进入MySQL数据库,select * from partition;
- 我们能够查到TBL_ID是47,表下面有两个分区,于是使用命令:select * from TBLS where TBL_ID = 47

2、47这张表中有2个分区,2019-05是我们手工创建的,需要刷新分区信息,才能够使它感知的到
语法:
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location'][, PARTITION partition_spec [LOCATION 'location'], ...];
刷新分区信息的SQL语句:
ALTER TABLE order_partition ADD IF NOT EXISTS PARTITION (event_month='2019-05')

在Hive中刷新分区信息后在MySQL中才能查到:
小结:
我们一再强调Hive的数据一部分是在关系型数据库(元数据信息),另一部分是在hdfs上中;如果元数据信息中没有囊括进去,那我们是永远也查询不到的。
如果想要查看分区呢?
hive (ruozeg6)> show partitions order_partition;
OK
event_month=2019-05
event_month=2019-09
event_month=201904
Time taken: 0.155 seconds, Fetched: 3 row(s)
2.3 创建多级分区
1、创建多级分区表
create table order_multi_partition(
order_no string,
event_time string
)
PARTITIONED BY(event_month string, step string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
2、加载数据
- 多级分区加载数据
- 多级分区的应用场景:(数据量大按月询范围还是大,可以按天,按小时)
- load data local inpath ‘/home/hadoop/data/order.txt’ overwrite into table order_mulit_partitioned
PARTITIONED(event_month=‘2019-05’,step=“1”);
3、使用select查询语句:
- select * from order_mulit_partitioned where event_month=‘2019-05’ and step=‘1’;

注意点:
- 分区表在查询的时候一定要把分区目录带到最底层去,一个手贱每加或者漏了,很可能被刷屏。
2.4 动态分区
一级分区、多级分区都是静态分区
2.4.1 抛砖引玉
需求一:
本地data目录下有一份员工emp表,按照部门编号写到指定的分区中去
1、便捷的拷贝语句:show create table emp; //可以直接查看emp表的建表语法。
create table emp_static_partition(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double
) PARTITIONED BY (deptno int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
2、把数据写到emp_static_partition表中去:
Hive官网中insert的语法(insert是DML,所以去到Hive DML中去查找):
1、INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
2、INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
3、把emp表中deptno=20的如下字段取出来,插入到emp_static_partition中去,这个SQL执行是跑MapReduce的。
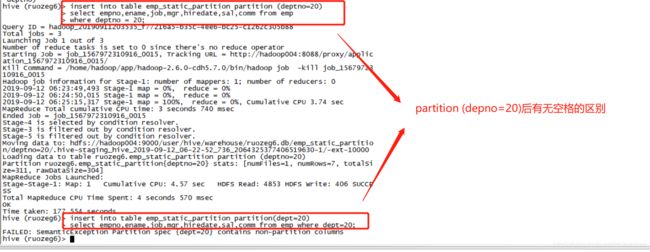
insert into table emp_static_partition PARTITION (deptno=20)
select empno,ename,job,mgr,hiredate,sal,comm from emp
where deptno=20;
问题:
- 我们常见的SQL有如下:insert into table students VALUES (‘fred flintstone’,35,1.28),(‘barney rubble’, 32, 2.32)
这种SQL和3中的insert的SQL的区别
注意:禁止使用带VALUES的这种
4、SQL一查询数据就直接出来了
hive (ruozeg6)> select * from emp_static_partition where deptno = 20;
OK
7369 SMITH CLERK 7902 1980-02-15 200.0 NULL 20
7698 BLADE ANALYST 7658 1992-05-25 1300.0 NULL 20
7369 SMITH CLERK 7902 1980-02-15 200.0 NULL 20
7698 BLADE ANALYST 7658 1992-05-25 1300.0 NULL 20
1416 ron player 7643 1997-01-23 5000.0 1500.0 20
1415 erath IT 7528 1996-02-18 5500.0 1000.0 20
1416 zacker engineer 3628 1995-11-03 5800.0 NULL 20
Time taken: 2.129 seconds, Fetched: 7 row(s)
2.4.2 引出动态分区
我们使用这种方式可以得知一个部门下的员工信息,那假设有20个部门呢,岂不是要查死人。
1、创建动态分区表(表名改掉即可),dept后面不跟值,第二行查出的是所有的员工信息,怎么对应上去,deptno在select的最后才能与之对应
SQL如下:
insert into table emp_dynamic_partition partiiton (deptno)
select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp
运行SQL报错:
- 日志中提示:hive.exec.dynamic.partition.mode=nonstrict //需要调整这个模式
hive (ruozeg6)> insert into table emp_dynamic_partition partition (deptno)
> select empno,ename,job,mgr,hiredate,sal,comm,dept from emp;
FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
2、直接在Hive中设置:set hive.exec.dynamic.partition.mode=nonstrict;
- 设置完后重新运行1中的SQL:等待它跑MapReduce
3、分别运行如下三个SQL:
- select * from emp_dynamic_partition;
- select * from emp_dynamic_partition where deptno = 20;
- select * from emp_dynamic_partition where deptno = 30;
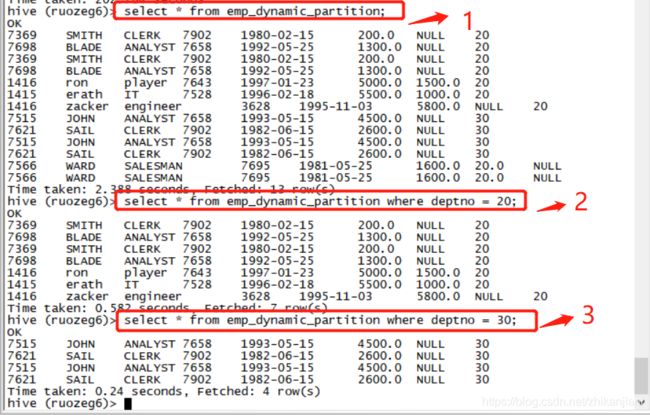
小结:
- 底层实现原理就是拿字段来匹配字段
1、要把hive.exec.dynamic.partition.mode这个模式关掉
2、一定要跟在select语句的最后
扩展:如果是多级动态分区呢,该怎么匹配?
insert into table emp_dynamic_partition partiiton (deptno,step)
select empno,ename,job,mgr,hiredate,sal,comm,deptno,step from emp
强调:
insert的两种方式:
1、insert values //值的这种方式不能用
2、insert into tables select …
第三章:Hive的其它使用方式
第一种:Hive server2+beeline
在我们启动Hive的过程中,注意一句话:
- WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
[hadoop@hadoop004 bin]$ pwd
/home/hadoop/app/hive/bin
[hadoop@hadoop004 bin]$ ll
total 32
-rwxr-xr-x. 1 hadoop hadoop 881 Mar 24 2016 beeline
drwxr-xr-x. 3 hadoop hadoop 4096 Mar 24 2016 ext
-rwxr-xr-x. 1 hadoop hadoop 7751 Mar 24 2016 hive
-rwxr-xr-x. 1 hadoop hadoop 1900 Mar 24 2016 hive-config.sh
-rwxr-xr-x. 1 hadoop hadoop 885 Mar 24 2016 hiveserver2
-rwxr-xr-x. 1 hadoop hadoop 832 Mar 24 2016 metatool
-rwxr-xr-x. 1 hadoop hadoop 884 Mar 24 2016 schematool
- 进入到Hive的bin目录中:hiveserver2+beeline是配合使用的,在高级班学习中,还有一个thriftserver+beeline,这两个基本是一样的。
怎么找对应的网页目录:
1、hive.apaceh.org --> 2、Hive wiki --> 3、User Documentation --> 4、HiveServer2
Hiveserver2 Introduction:
- HiveServer2 (HS2) is a service that enables clients to execute queries against Hive(是一个服务能够是使得客户端去执行SQL). Hiveserver2 is the sucessor to HiveServer1 which has been deprecated. HS2 supports multi-client concurrently and authertication(支持多个客户端并发访问服务). It is designed to provide better support for open API clients like JDBC and ODBC(使用JDBC、ODBC可以直接连接到服务上进行查询)
Hive server2(服务端)+beeline(客户端)的使用:
- server + clinet的方式,所以我们先启动服务。
启动服务还分为两种方式:前端和后端
1、前端的方式:直接进到$HIVE_HOME/bin目录下,使用命令:./hiveserver2
2、后端启动的方式:nohup
前端启动的不能关,关了服务就停了。
还是去官网上找:hiveserver2 + beeline
跳转到如下网址:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
思考?
通过clinet端连接到服务上需要哪些信息:
Beeline的使用:
1、解读:-u jdbc:hive2:// 固定写法;hadoop004指的是机器的ip;10000是beeline的端口号;ruoze_g6是在hive-site.xml体现的;-n hadoop 指定的是hadoop机器的用户名(hostname)
- beeline -u jdbc:hive2://hadoop004:10000/ruoze_g6 -n hadoop
启动Beeline(在$HIVE_HOME/bin目录下):
- 启动命令:beeline -u jdbc:hive2://hadoop004:10000/ruoze_g6 -n hadoop
Beeline启动过程的坑:
- 明确的是连接到Hive上来了;在高级班的课程中,spark怎么会连接到hive上去了
Connected to: Apache Hive (version 1.1.0-cdh5.7.0)
Driver: Hive JDBC (version 1.1.0-cdh5.7.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.1.0-cdh5.7.0 by Apache Hive
每次在Client端(beeline)成功执行一个命令时,都会在Server端(./hiveserver2)返回一个ok
这个玩意儿和我们学Hive有什么关系么?
- 回字的八种写法掌握了有意思么 -PK
第四章:Hive建表时的一些数据类型
第一种:array_type:
数据准备:
1、第一列是名字,和第二列以tab键进行分割
[hadoop@hadoop004 data]$ pwd
/home/hadoop/data
[hadoop@hadoop004 data]$ cat hive_array.txt
ruoze beijing,shanghai,tianjin,hangzhou
jepson changshu,chengdu,wuhan,beijing
2、建表语句如下:
hive (ruozeg6)> create table hive_array (
> name string,
> work_locations array
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
OK
Time taken: 3.52 seconds
3、把数据导进来:
load data local inpath '/home/hadoop/data/hive_array.txt'
into table hive_array;
4、2中的建表语句漏了一个属性,删除表后重新建表,再把数据加载进来
hive (ruozeg6)> create table hive_array (
> name string,
> work_locations array
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
> COLLECTION ITEMS TERMINATED BY ",";
OK
Time taken: 3.52 seconds
开始进行需求分析:
需求一
- 查找出这个表中:人名以及这个人所工作的第一个地方,索引是从0开始的。
hive (ruozeg6)> select name,work_locations[0] from hive_array;
OK
ruoze beijing
jepson changshu
Time taken: 0.112 seconds, Fetched: 2 row(s)
hive (ruozeg6)> select name,work_locations[10] from hive_array;
OK
ruoze NULL
jepson NULL
Time taken: 0.095 seconds, Fetched: 2 row(s)
需求二
- 统计出表中每个人一共工作过几个地方? 引出size函数
hive (ruozeg6)> select name,size(work_locations) from hive_array;
OK
ruoze 4
jepson 4
Time taken: 0.081 seconds, Fetched: 2 row(s)
需求三
- 求出表中在天津上班的人? 引出array_contains函数
hive (ruozeg6)> select * from hive_array where array_contains(work_locations,"tianjin");
OK
ruoze ["beijing","shanghai","tianjin","hangzhou"]
Time taken: 0.092 seconds, Fetched: 1 row(s)
小结:
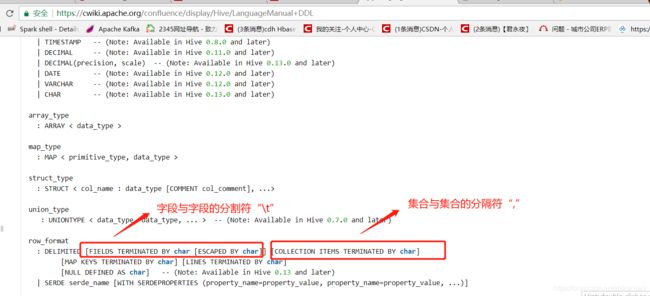
- Array type在建表的时候需要加上一句:COLLECTION ITEMS TERMINATED BY “,”
- 在查找的时候使用:数组字段名 --> work_locations[0],下标从0开始。
对于复杂的数据类型,我们只要掌握两点:如何存储、如何取值?
第二种:map type
第一步:
数据准备:
- map key-value的形式
数据解读:
- 从father字段开始:以key:value的形式对应,每组key、value间以#符号分割
[hadoop@hadoop004 data]$ cat hive_map.txt
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu
2,lisi,father:ron,#mother:rebacca#brother:john
第二步:
- 开始创建表:
create table hive_map (
id int,
name string,
members map,
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
COLLECTION ITEMS TERMINATED BY '#';
运行该SQL报错:
- 仅仅是因为map和collection的先后顺序错乱所导致的
hive (ruozeg6)> create table hive_map(
> id int,
> name string,
> members map
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> MAP KEYS TERMINATED BY ':'
> COLLECTION ITEMS TERMINATED BY '#';
FAILED: ParseException line 8:0 missing EOF at 'COLLECTION' near '':''
hive (ruozeg6)> create table hive_map(
> id int,
> name string,
> members map
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY '#'
> MAP KEYS TERMINATED BY ':';
OK
Time taken: 0.171 seconds
- 所以Hive官网的文档显得尤为重要。

第三步:加载数据进hive_map
hive (ruozeg6)> load data local inpath '/home/hadoop/data/hive_map.txt' overwrite into table hive_map;
Loading data to table ruozeg6.hive_map
Table ruozeg6.hive_map stats: [numFiles=1, numRows=0, totalSize=106, rawDataSize=0]
OK
Time taken: 0.567 seconds
SQL进行需求分析:
需求一:
- 列举出id name name对应的成员变量中的父亲这个值
hive (ruozeg6)> select id,name,members['father'] from hive_map;
OK
1 zhangsan xiaoming
2 lisi ron
Time taken: 0.215 seconds, Fetched: 2 row(s)
需求二:
- 分别求出亲属关系中的key、value
hive (ruozeg6)> select map_keys(members) from hive_map;
OK
["father","mother","brother"]
["father","mother","brother"]
["father","mother","brother"]
["father","mother","brother"]
Time taken: 0.069 seconds, Fetched: 4 row(s)
hive (ruozeg6)> select map_values(members) from hive_map;
OK
["xiaoming","xiaohuang","xiaoxu"]
["ron","rebacca","john"]
["meixuefang","guxiangmei","meiguojun"]
["sail","ron","zacker"]
Time taken: 0.092 seconds, Fetched: 4 row(s)
需求三:
- 分别求出每一行中它有几个亲属关系
hive (ruozeg6)> select size(members) from hive_map;
OK
3
3
3
3
Time taken: 0.069 seconds, Fetched: 4 row(s)
第三种:struct type
数据准备:
- 数据解读:ip + 用户名:年龄
[hadoop@hadoop004 data]$ cat hive_struct.txt
192.168.1.1#zhangsan:25
10.0.0.135#lisi:27
192.168.137.252#sail:24
10.0.0.135#robert:29
2、建表语句
hive (ruozeg6)> create table hive_struct (
> ip string,
> userinfo struct
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '#'
> COLLECTION ITEMS TERMINATED BY ':';
OK
Time taken: 0.504 seconds
3、加载数据并且查询
hive (ruozeg6)> load data local inpath '/home/hadoop/data/hive_struct.txt' into table hive_struct;
Loading data to table ruozeg6.hive_struct
Table ruozeg6.hive_struct stats: [numFiles=1, totalSize=88]
OK
Time taken: 0.358 seconds
hive (ruozeg6)> select userinfo.name,userinfo.age from hive_struct;
OK
zhangsan 25
lisi 27
sail 24
robert 29
Time taken: 0.043 seconds, Fetched: 4 row(s)
总结:
1、array_type数组是用work_locations[0]取值
2、map type是用members[key]
3、struct_type是用userinfo.name
这些结构都是行式存储,要转换成列式才能使用,我们只需要把他们清洗出来,做成一张大宽表;肯定是设计一个数据的转换,基于转换的这张表进行查询的