朴素贝叶斯代码_李航统计学习方法:第四章 朴素贝叶斯 ( 含有笔记、代码、注释 )...
分类问题
① 日常生活中我们每天都进行着分类过程。
② 例如:
- 当你看到一个人,你的脑子下意识判断他是学生还是社会上的人。
- 走在路上,对身旁的朋友说 "这个人的父母有教养" 之类的话。
分类数学描述
① 从数学角度来说,分类问题可做如下定义:
已知集合
② 其中:
- I 叫做特征集合。
- C 叫做类别集合,其中每一个元素是一个类别。
- f 叫做分类器。
注:分类算法的任务就是构造分类器 f。
③ 分类算法的内容是要求给定特征,让我们得出类别,这也是所有分类问题的关键。
朴素贝叶斯分类
① 朴素贝叶斯分类算法的核心算法,是下面这个贝叶斯公式:
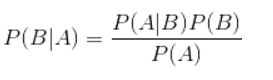
注:换个表达形式就会明朗很多,如下:

② 我们最终要求的是 p(类别|特征)。
实例
① 给定数据,如下所示:
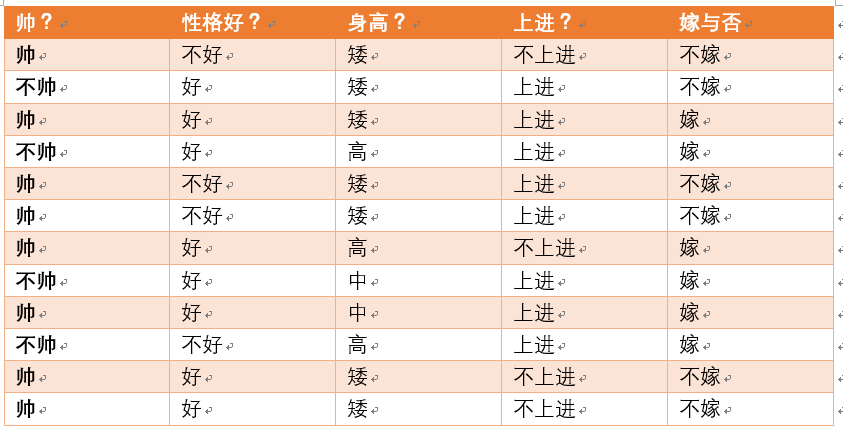
② 问题:
- 如果一对是男女朋友,男生向女生求婚。
- 男生的四个特点分别是不帅、性格不好、身高矮、不上进。
- 判断一下女生是嫁还是不嫁?
③ 这个典型的分类问题,就会转为数学问题,比较p(嫁|(不帅、性格不好、身高矮、不上进))与p(不嫁|(不帅、性格不好、身高矮、不上进))的概率。
④ 比较嫁与不嫁的概率,选择概率大的类别。
⑤ 结合朴素贝叶斯公式:

⑥ 我们需要求出 p(嫁|(不帅、性格不好、身高矮、不上进),这是我们不知道的。
⑦ 朴素贝叶斯公式可以将其转化为三个好求的量:
- p(不帅、性格不好、身高矮、不上进|嫁)
- p(不帅、性格不好、身高矮、不上进)
- p(嫁)
⑧ 将待求的量转化为其它可求的值,通过可求的量,就可以求出待求的值了。
朴素解释
① 三个好求的量是根据已知训练数据统计得来的。
注:p(不帅、性格不好、身高矮、不上进|嫁) = p(不帅|嫁)*p(性格不好|嫁)*p(身高矮|嫁)*p(不上进|嫁)。
注:通过统计右边几个概率,就得到了左边的概率。
② 这个等式成立的条件需要特征之间相互独立。
注:这就是朴素贝叶斯分类有朴素一词的来源,朴素贝叶斯算法是假设各个特征之间相互独立,那么这个等式就成立了。
特征不独立
① 假如特征之间不相互独立,那么右边概率的估计是不可做的。
② 比如:
- 我们有4个特征,其中帅包括{帅,不帅},性格包括{不好,好,爆好},身高包括{高,矮,中},上进包括{不上进,上进}。
- 那么四个特征的联合概率分布总共是4维空间,总个数为2*3*3*2=36个。
注:36个,计算机扫描统计还可以。
注:现实生活中,往往有非常多的特征,每一个特征的取值也是非常之多,那么计算机扫描统计变得几乎不可做。
② 比如:
- 假如我们没有假设特征之间相互独立,那么我们统计的时候,就需要在整个特征空间中去找,比如统计p(不帅、性格不好、身高矮、不上进|嫁),
- 我们就需要在嫁的条件下,去找四种特征全满足分别是不帅,性格不好,身高矮,不上进的人的个数,由于数据的稀疏性,很容易统计到0的情况,这是不合适的。
③ 朴素贝叶斯法对条件概率分布做了条件独立性的假设,这是一个较强的假设。
④ 特征之间相互独立这一假设使得朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率。
⑤ 将上面公式整理一下如下:

⑥ 下面将一个局部一个局部的进行统计计算。
注:在数据量很大的时候,根据中心极限定理,频率是等于概率的。
⑦ 统计 p(嫁) =
- 首先,整理训练数据,嫁的样本数如下,一共有6个:
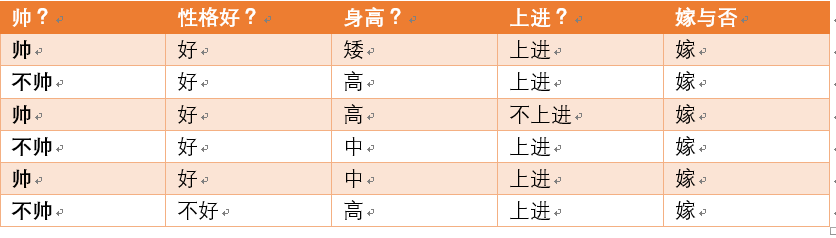
- p(嫁) = 6/12(12是总样本数) = 1/2
- p(不帅|嫁) 统计满足样本数如下,有3个:

- 则 p(不帅|嫁) = 3/6 = 1/2
- p(性格不好|嫁) 统计满足样本数如下,有一个:

- 则 p(性格不好|嫁) = 1/6
- p(矮|嫁) 统计满足样本数如下,有一个:

- 则 p(矮|嫁) = 1/6
- p(不上进|嫁) 统计满足样本数如下,有一个:

- 则 p(不上进|嫁) = 1/6
- 下面开始求分母,p(不帅)、p(性格不好)、p(矮)、p(不上进)
- 统计样本如下:

- 不帅统计如红色所示,占4个,p(不帅) = 4/12 = 1/3
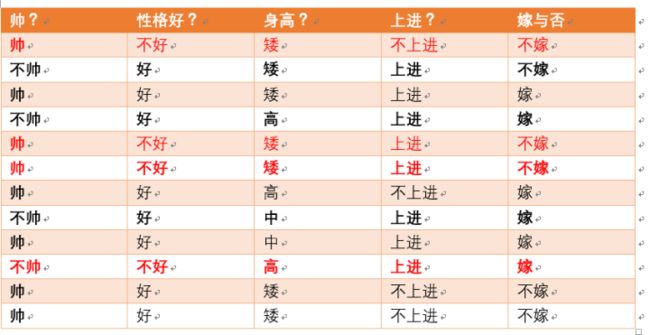
- 性格不好统计如红色所示,占4个,那么p(性格不好) = 4/12 = 1/3
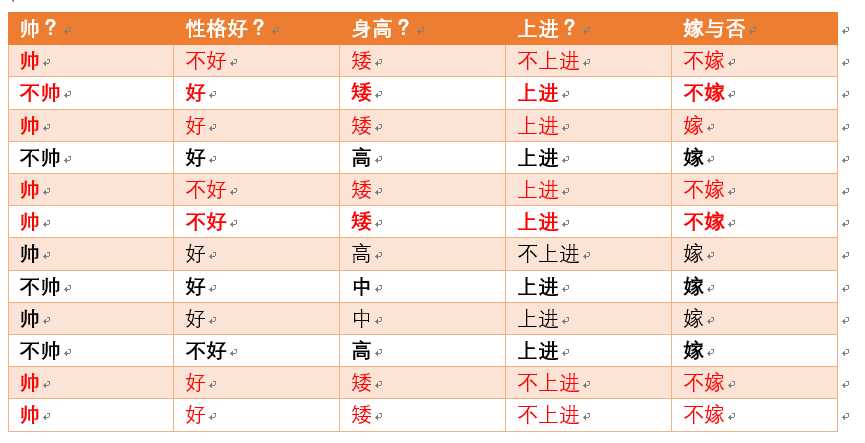
- 身高矮统计如红色所示,占7个,那么p (身高矮) = 7/12
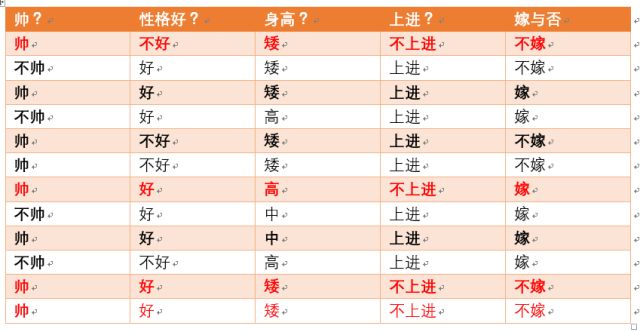
- 不上进统计如上红色所示,占4个,那么p(不上进) = 4/12 = 1/3
⑧ 要求 p(不帅、性格不好、身高矮、不上进|嫁) 的所需项全部求出来了,带入进去即可:
= (1/2*1/6*1/6*1/6*1/2)/(1/3*1/3*7/12*1/3)
⑨ 下面根据同样的方法来求p(不嫁|不帅,性格不好,身高矮,不上进),完全一样的做法。
注:公式如下:

注:一个一个来进行统计计算,这里与上面公式中,分母是一样的,于是我们分母不需要重新统计计算。
- p(不嫁) 根据统计计算如下(红色为满足条件):
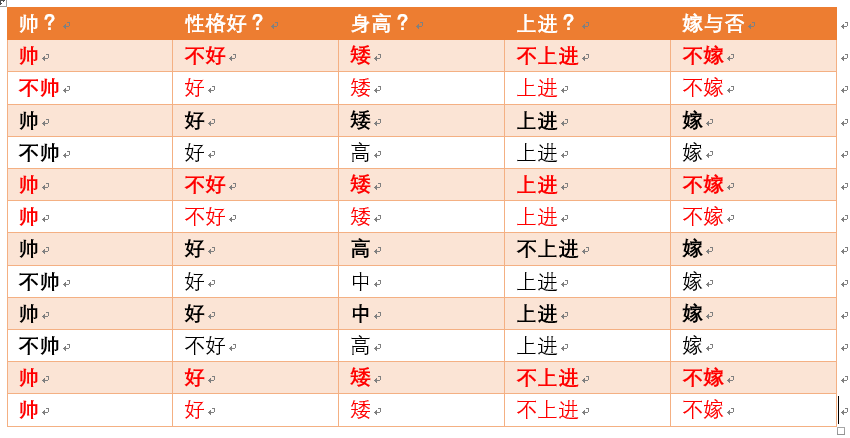
- 则 p(不嫁)=6/12 = 1/2
- p(不帅|不嫁) 统计满足条件的样本如下(红色为满足条件):
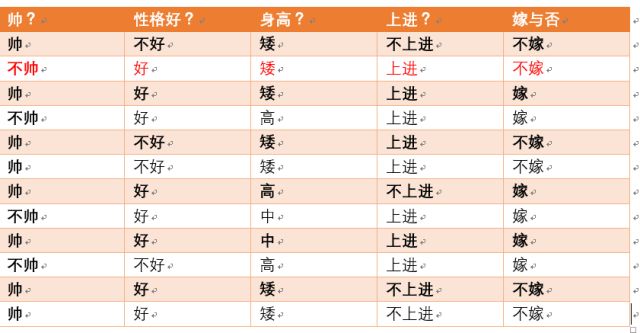
- p(不帅|不嫁) = 1/6
- p(性格不好|不嫁) 据统计计算如下(红色为满足条件):
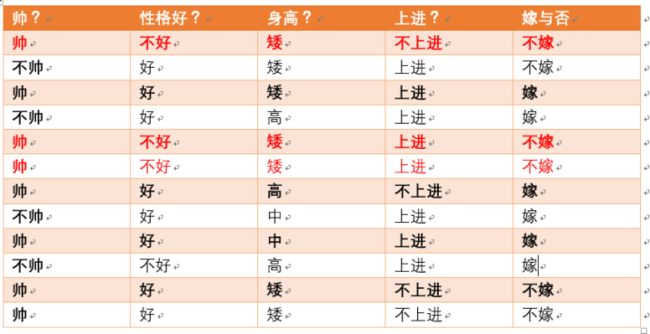
- p(性格不好|不嫁) =3/6 = 1/2
- p(矮|不嫁) 据统计计算如下(红色为满足条件):

- p(矮|不嫁) = 6/6 = 1
- p(不上进|不嫁) 据统计计算如下(红色为满足条件):
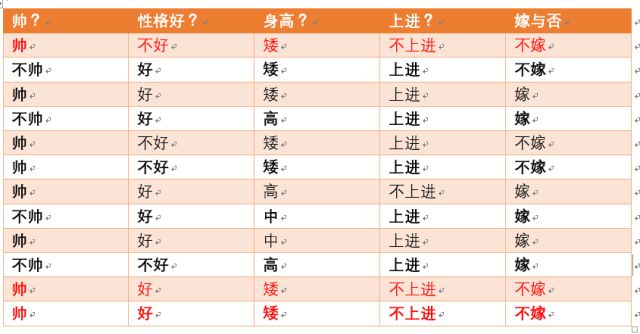
- 则 p(不上进|不嫁) = 3/6 = 1/2
⑩ 根据公式:
p(不嫁|不帅、性格不好、身高矮、不上进) = ((1/6*1/2*1*1/2)*1/2)/(1/3*1/3*7/12*1/3)
比较概率大小
① 显然(1/6*1/2*1*1/2) > (1/2*1/6*1/6*1/6*1/2)
② 于是 p(不嫁|不帅、性格不好、身高矮、不上进) > p(嫁|不帅、性格不好、身高矮、不上进)
③ 所以根据朴素贝叶斯算法可以给这个女生答案,是不嫁。
朴素贝叶斯缺点
① 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。
② 实际上朴素贝叶斯模型并非比其他分类方法具有最小的误差率,因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
朴素贝叶斯优点
① 算法逻辑简单,易于实现。
② 分类过程中时空开销小。
③ 在属性相关性较小时,朴素贝叶斯性能最为良好。
朴素贝叶斯改进
① 半朴素贝叶斯之类的算法可以通过考虑部分关联性适度改进。
先验概率
① 天气炎热,石头来到超市准备买个西瓜,可是没有太多的经验,不知道怎么样才能挑个熟瓜。
② 如果石头对这个西瓜没有任何了解,包括瓜的颜色、形状、瓜蒂是否脱落。
③ 那么按常理来说,西瓜成熟的概率大概是 60%。
注:概率 P(瓜熟) 就被称为先验概率。
注:也就是说,先验概率是根据以往经验和分析得到的概率,先验概率无需样本数据,不受任何条件的影响。
注:石头只根据常识而不根据西瓜状态来判断西瓜是否成熟,这就是先验概率。
后验概率
① 石头以前学到了一个判断西瓜是否成熟的常识,就是看瓜蒂是否脱落。
注:一般来说,瓜蒂脱落的情况下,西瓜成熟的概率大一些,大概是 75%。
注:如果把瓜蒂脱落当作一种结果,然后去推测西瓜成熟的概率,这个概率 P(瓜熟 | 瓜蒂脱落) 就被称为后验概率。
注:后验概率类似于条件概率。
② 石头买西瓜的例子中,P(瓜熟,瓜蒂脱落) 称之为联合分布,它表示瓜熟了且瓜蒂脱落的概率。
③ 联合概率,满足下列乘法等式:
注:P(瓜熟 | 瓜蒂脱落) 就是刚刚介绍的后验概率,表示在 "瓜蒂脱落" 的条件下,"瓜熟" 的概率。
注:P(瓜蒂脱落 | 瓜熟) 表示在 "瓜熟" 的情况下,"瓜蒂脱落" 的概率。
④ 计算瓜蒂脱落的概率,实际上可以分成两种情况:
- 瓜熟状态下瓜蒂脱落的概率。
- 瓜生状态下瓜蒂脱落的概率。
⑤ 瓜蒂脱落的概率就是这两种情况之和。
⑥ 我们推出全概率公式:
单个特征判断瓜熟
① 西瓜的状态分成两种:瓜熟与瓜生,概率分别为 0.6 与 0.4,且瓜熟里面瓜蒂脱落的概率是 0.8,瓜生里面瓜蒂脱落的概率是 0.4。
② 那么,如果我现在挑一个瓜蒂脱落的瓜,判断该瓜是熟瓜的概率,就是计算一个后验概率的问题。
注:根据上面推导的联合概率和全概率公式,可以求出:
注:一项一项来看:
- 条件概率 P(瓜蒂脱落 | 瓜熟) = 0.8
- 先验概率 P(瓜熟) = 0.6
- 条件概率 P(瓜蒂脱落 | 瓜生) = 0.4
- 先验概率 P(瓜生) = 0.4
注:将以上数值带入上式,得:
注:瓜蒂脱落的瓜是好瓜的概率是 0.75。
注:计算后验概率的公式就是利用贝叶斯定理。
多个特征判断瓜熟
① 石头专门在网上搜索了一下,知道判断一个瓜是否熟了,除了要看瓜蒂是否脱落,还要看瓜的形状和颜色。
② 形状有圆和尖之分,颜色有深绿、浅绿、青色之分。
③ 使用刚刚引入的贝叶斯定理思想来尝试解决这个问题。
注:特征由原来的 1 个,变成现在的 3 个,我们用 X 表示特征,用 Y 表示瓜的类型(瓜熟还是瓜生)。
注:根据贝叶斯定理,后验概率 P(Y=ck | X=x) 的表达式为:
注:其中,ck 表示类别,k 为类别个数。
注:k = 1,2,c1 表示瓜熟,c2 表示瓜生。
高斯分布
① 如果 x 是连续变量,如何去估计似然度P(x|yi)呢?
② 我们可以假设在yi的条件下,x服从高斯分布(正态分布)。
③ 根据正态分布的概率密度函数即可计算出P(x|yi),公式如下:
高斯朴素贝叶斯
① 如果 x 是多维的数据,那么我们可以假设P(x1|yi),P(x2|yi)...P(xn|yi)对应的事件是彼此独立的,这些值连乘在一起得到P(x|yi)。
② "彼此独立" 也就是朴素贝叶斯的朴素之处。
代码实战
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, :])
# print(data)
return data[:,:-1], data[:,-1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_test[0], y_test[0]运行结果:
(array([5.7, 2.9, 4.2, 1.3]), 1.0)
sorted(key=lambda)
① 建立一个列表a
a = [1,5,3,6,2]
② 直接使用sorted方法,返回一个列表就是排序好的
sorted(a)
运行结果为:
[1,2,3,5,6]
③ 假如 a 是一个由元组构成的列表,我们就需要用到参数key,也就是关键词。
注:下面这句命令,lambda是一个隐函数,是固定写法,不要写成别的单词;
注:x 表示列表中的一个元素,在这里,表示一个元组,x 只是临时起的一个名字,你可以使用任意的名字。
注:x[0]表示元组里的第一个元素,当然第二个元素就是x[1];
a=[('b',4),('a',0),('c',2),('d',3)]
sorted(a,key=lambda x:x[1])
注:所以这句命令的意思就是按照列表中第一个元素排序。
运行结果:
a=[('a',4),('c',4),('d',4),('b',4),]
class NaiveBayes:
def __init__(self):
self.model = None
@staticmethod
def mean(X):
return sum(X) / float(len(X))
# mean(X)获得 X 的数学期望。
def stdev(self, X):
avg = self.mean(X)
return math.sqrt(sum([pow(x - avg, 2) for x in X]) / float(len(X)))
# stdev(self, X)获得 X 标准差 (方差)。
def gaussian_probability(self, x, mean, stdev):
exponent = math.exp(-(math.pow(x - mean, 2) /
(2 * math.pow(stdev, 2))))
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent
# 获得高斯分布概率密度函数
def summarize(self, train_data):
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
return summaries
# 对X_train进行均值处理和标准差处理。
def fit(self, X, y):
labels = list(set(y)) # 设 y 是 label
data = {
label: [] for label in labels}
for f, label in zip(X, y): # 每个特征、标签遍历
data[label].append(f) # 在每个标签后面添加特征,这里类别就分出来了。
self.model = {
label: self.summarize(value) # 模型为字典,key为类别,values为这个类别中的值求出数学期望和标准差
for label, value in data.items()
}
return 'gaussianNB train done!'
# 对每个类别求出数学期望和标准差
# 计算概率
def calculate_probabilities(self, input_data):
probabilities = {} # 设原先的各类别概率集合为空集
for label, value in self.model.items(): # 遍历高斯朴素贝叶斯模型中,每个类别的数学期望和标准器每个元素
probabilities[label] = 1
for i in range(len(value)): # 对每一个值进行遍历
mean, stdev = value[i] # 或者第"i"个类别,即对应的第i个值,将它们对应为mean和stdev。
probabilities[label] *= self.gaussian_probability(
input_data[i], mean, stdev) # 利用第"i"个类别的mean和stdev,计算输入input_data[i]属于每个类别的概率。
return probabilities
# 类别
def predict(self, X_test):
# {0.0: 2.9680340789325763e-27, 1.0: 3.5749783019849535e-26}
label = sorted(
self.calculate_probabilities(X_test).items(), # sort函数对测试集进行求概率,获得probabilities字典,然后取字典中元素。
key=lambda x: x[-1])[-1][0] # label 为 sort函数后,最后一行第一列,即标签。
return label # 返回标签。
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y: # 如果分类正确。
right += 1 # 那么标间的个数加1。
return right / float(len(X_test))
model = NaiveBayes()
model.fit(X_train, y_train)运行结果:
'gaussianNB train done!'
print(model.predict([4.4, 3.2, 1.3, 0.2]))运行结果:
0.0
model.score(X_test, y_test)运行结果:
1.0
scikit-learn实例
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X_train, y_train)运行结果:
GaussianNB(priors=None, var_smoothing=1e-09)
clf.score(X_test, y_test)运行结果:
1.0
clf.predict([[4.4, 3.2, 1.3, 0.2]])运行结果:
array([0.])
from sklearn.naive_bayes import BernoulliNB, MultinomialNB # 伯努利模型和多项式模型参考文献:
- 知乎/忆臻/带你理解朴素贝叶斯分类算法
- 知乎/红色石头/白话朴素贝叶斯
- 知乎/李小文/高斯朴素贝叶斯
- Github/黄海广/朴素贝叶斯
更多《 机器学习 》,关注专栏 ♬ ♬
打字不易,请点赞!
注:因为你的 "点赞",是我更新的动力 (正反馈)。
