Hadoop学习( HDFS实现分布式存储:
Hadoop 核心-HDFS
前面提过,大数据的特点是: 体量大 类型繁多 值密度低 产生和处理速度快。
当数据集的大小超过一台独立的物理计算机的存储能力时:
就必须对它进行分区并存储到若干台单独的计算机上,然后将这些计算机通过网络连接。
并对网络中的文件系统进行集中管理 , 由此构成分布式文件系统 (HDFS)
HDFS概述
介绍:
在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。
统一管理分布在 :集群上的文件系统称为分布式文件系统
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目Hadoop 非常适于存储
大型数据(比如 TB 和 PB) ,
其就是使用HDFS 作为存储系统HDFS 使用多台计算机 集群 存储文件,
并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.Google 发布了三篇论文, 被称作为三驾马车, 其中有一篇叫做
GFS
是描述了 Google 内部的一个叫做 GFS 的分布式大规模文件系统 :具有强大的可伸缩性和容错性
Doug Cutting 后来根据GFS的论文, 创造了一个新的文件系统, 叫做HDFS
适合的应用场景
存储非常大的文件:
- 这里非常大指的是几百M、G、或者TB级别,适合需要
高吞吐量,对延时没有要求的程序。采用流式的数据访问方式:
一次写入、多次读取数据集经常从数据源生成或者拷贝一 次,然后在其上做很多分析工作 。运行于商业硬件上:
- Hadoop不需要特别贵的机器,可运行于普通廉价机器;
同样,HDFS也存在缺点 以下应用就不适合在HDFS上运行:
低延时的数据访问:
- 不适合对延时要求在毫秒级别的应用,HDFS是为高吞吐数据传输设计的,因此可能
牺牲延时无法大量的存储小文件:
- 大量小文件,
元数据保存在NameNode的内存中,
整个文件系统的文件数量会受限于NameNode的内存大小;
NameNode相当于一个老大, 手下有很多的DataNode小弟, 小弟存储文件数据, 老大只需要记录不同小弟存储的数据;
当老大的内存满了就不能记录小弟了无论是大数据还是 1kb小数据 , 记录都在 老大NameNode 的 元数据中…不支持多用户
写入/修改文件:
- 写入/修改, 都是基于
流访问:
目前在HDFS 的一个文件,同时只能有一个用户写入 , 并且只能写在文件末尾…(还有待升级!!)
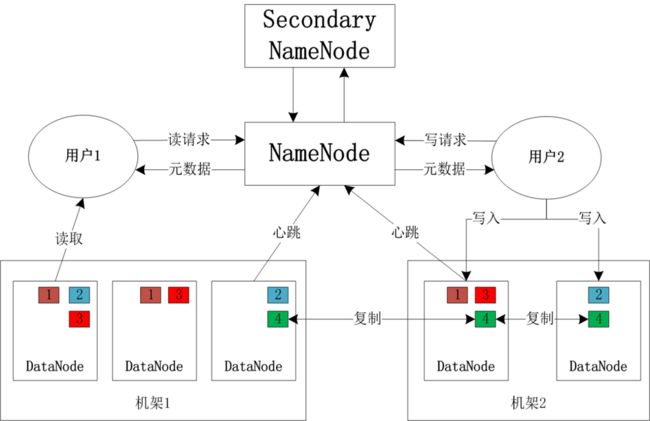
HDFS 的架构
HDFS是一个 主/从(Mater/Slave)体系结构
HDFS由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。
Client:就是客户端
文件切分:
- 文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,
文件块:如图DataNode数字编号的方块
— 它是文件存储理的最小逻辑单元,默认块大小为64MB.- 使用文件块的好处是:
文件的所有块并不需要存储在同一个磁盘上,可以利用集群上的任意一个磁盘进行存储。
对分布式系统来说,由于块的大小是固定的,因此计算单个磁盘能存储多少个块就相对容易可简化存储管理。
在数据冗余备份时, 将每个块复制到几台独立的机器上(默认为三台)
可以确保在块、磁盘或机器发生故障后数据不会丢失。如果发现一个块不可用,系统会从其他地方读取另个副本这个过程对用户是透明的NameNode和DataNode节点:
NameNode:就是 master,它是一个主管、管理者。
- NameNode 负责管理文件系统的命名空间,属于
管理者角色。
它维护文件系统树内所有文件和目录,记录每个文件在各个DataNode.上的位置和副本信息:并协调客户端对文件的访问。
这些信息以两种形式存在:命名空间镜像文件 edits_*和编辑日志文件 fsimage_*- NameNode元数据:
NameNode在内存中保存着整个文件系统的名称 空间和文件数据块的地址映射
整个HDFS可存储的文件数受限于NameNode的内存大小;
位于NameNode节点node1的:hadoop/ dfs/name/ current目录 (由hdfs-site.xml中的dfs .namenode. name. dir 属性指定)- NameNode心跳机制
全权管理数据块的复制,周期性的接受心跳和块的状态报告信息(包含该DataNode上所有数据块的列表)
若接受到心跳信息,NameNode认为DataNode工作正常,
如果在10分钟后还接受到不到DN的心跳,那么NameNode认为DataNode已经宕机 ,
这时候NN准备要把DN上的数据块进行重新的复制。
确保DataNode 稳定, 进行存储/记录/备份...操作, 确保程序稳定…DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
存储实际的数据块。执行数据块的读/写操作。 提供真实文件数据的存储服务。
Data Node以数据块的形式存储HDFS文件
典型的块大小是64MB 尽量将数据块分布到各个不同的DataNode节点上。Data Node 响应HDFS 客户端进行读写请求
Data Node 周期性向NameNode汇报心跳信息 / 数据块信息 / 缓存数据块信息
DataNode节点的数据存储目录为/home/hduser/hadoop/dfs/data
(由:hdfs- -site. xml中的dfs.datanode.data.dir 属性指定)。Secondary NameNode:辅助 NameNode,分担其工作量。
定期合并 fsimage和fsedits,并推送给NameNode,在紧急情况下,可辅助恢复 NameNode。
- 如果在NameNode上的数据损坏,HDFS中所有的文件都不能被访问
为了保证NameNode的高可用性,Hadoop对NameNode进行了补充Secondary NameNode- 相当于NameNode的快照能够周期性地备份NameNode记录NameNode中的元数据等,
也可以用来恢复NameNode,但SecondaryNameNode中的备份会滞后于NameNode. 所以会带来一定的数据损失。
为了防止宕机.通常是将Secondary NameNode 和NameNode 设置为不同的主机。- 有点类似于, 老大的助手:
前线在战斗, 司令并不能实时了解情况, 经常有助理讲前选的最新数据报告老大
老大把旧数据 和 新数据 合并就是整个战争的情报数据 !
HDFS的副本机制和机架感知
HDFS 文件副本机制
- 一个文件有可能大于集群中任意一个磁盘,引入块机制,可以很好的解决这个问题
- 使用块作为文件存储的逻辑单位可以简化存储子系统
- 块非常适合用于数据备份进而提供数据容错能力
在Hadoop1当中, 文件的 block 块默认大小是 64M,Hadoop2当中, 文件的 block 块大小默认是128M,
block 块的大小可以通过hdfs-site.xml当中的配置文件进行指定:
<property>
<name>dfs.block.sizename>
<value>块大小 以字节为单位value>
property>
机架感知
HDFS分布式文件系统的内部有一个副本存放策略:以默认的副本数=3为例:
1、第一个副本块存本机
2、第二个副本块存跟本机同机架内的其他服务器节点
3、第三个副本块存不同机架的一个服务器节点上
Master/Slave 架构
一个HDFS 集群, 由一个 NameNode 和多个 DataNode 组成, 属于典型的Master/Stave模式;
数据读流程:
由客户端向Namelote请求访问某个文件。
Namelede 返回该文件所在位置即在哪个DataNode.上, 然后 由客户端从该DataNode读取数据。
数据写流程:
由客户端向NameNode发出文件写请求NameNode告诉客户该向哪个DataNode写入该文件,
然后由客户将文件写入该DataNode节点,随后该DataNode将该文件自动复制到其他DataNode节点上,默认三份备份。
Hadoop FS Shell 命令:
语法:
Hadoop fs < args>
其中hadoop: , 命令位于SHADOOP_HOME /bin目录下
fs: 为其参数,表示FS Shell
< args>: 是fs的子命令,格式类似于Linux Shell 命令,并且功能也类似,如下:
- 创建目录:mkdir
列表文件:ls
查看文件:cat
转移文件:put、get、mv、cp
删除文件:rm、rmr
管理命令:test、du、expunge
使用 FS Shell 命令, 操作HDFS
HDFS 可以在这里查看, 当前实现要启动 NameNode DataNode … start-all.sh
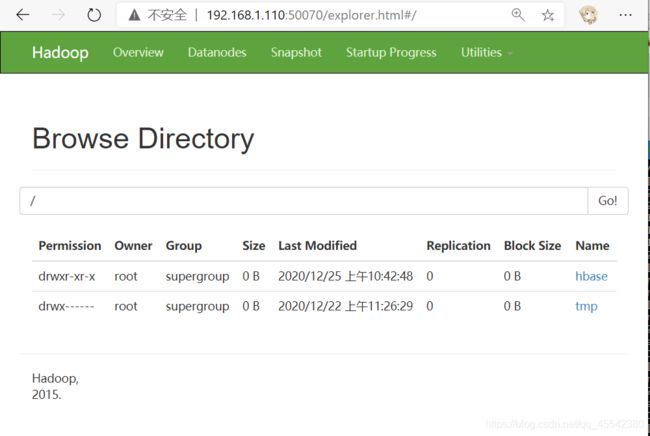
查看文件系统
查看所有文件
hadoop fs -ls /:后面指定要查询文件系统的目录~
>Hadoop 也可以访问本地目录:个人觉得没啥,直接用linux 自己的命令不香吗?
对要访问本地的文件目录前加上file://前缀
hadoop fs -ls file:///指定本地文件访问
或 Linuxls 目录进行直接访问!
一般主要使用hadoop fs命令来操作HDFS文件系统!


创建目录:接受路径指定的URI作为参数,创建这些目录
不支持支持同时创建多级目录, 使用-p参数可以递归创建目录
Hadoop fs [-p] -mkdir 文件名
# 在文件系统根目录下创建 user目录
hadoop fs -mkdir /user
# 在HDFS中创建“/user/hadoop”目录,前提需要有 /user
hadoop fs -mkdir /user/hadoop
# 同时创建多个目录,"空格" 分隔区分,创建多个文件目录;
hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
查看文件 cat
指定查看文件路径, 当然前提 HDFS中要有该文件!
hadoop fs -cat URI [URI…]
# 查看HDFS文件“file1.txt”和“file2.txt”
hadoop fs -cat /input2/file1.txt /input2/file2.txt
# 查看本地系统文件“file3.txt”
hadoop fs -cat file:///home/hduser/file3.txt
转移文件 put ,get, mv, cp
put: 对应上传
从本地文件系统中复制单个或多个文件到HDFS
hadoop fs -put 本地文件1 本地文件2 ... HDFS目录
hadoop fs -moveFromLocal 本地文件 HDFS目录
和put命令类似,但是源文件localsrc拷贝之后自身被删除
# 将本地 /home/hduser/file/file1.txt 文件复制到HDFS目录“/input2”
hadoop fs -put /home/hduser/file/file1.txt /input2
# 将多个本地文件复制到HDFS目录“/input2”
hadoop fs -put /home/hduser/file/file1.txt /home/hduser/file/file2.txt /input2
get:对应下载
复制HDFS文件到本地文件系统,是put的逆操作
hadoop fs -get HDFS上文件 指定存放的本地目录
# 将HDFS文件“/input2/file1”复制到本地文件系统“$HOME/file”中
hadoop fs -get /input2/file1 $HOME/file
mv:
将hdfs上的文件从原路径移动到目标路径(移动之后文件删除),该命令不能夸文件系统;
hadoop fs -mv 文件1 文件2 ... 移动目录
# 将HDFS上的file1.txt、file2.txt移动到dir1中
hadoop fs -mv /input2/file1.txt /input2/file2.txt /user/hadoop/dir1
cp:
将文件从源路径复制到目标路径
-f 选项将覆盖目标,如果它已经存在。
-p 选项将保留文件属性(时间戳、所有权、许可、ACL、XAttr)。
hadoop fs -cp 本地文件1 本地文件2 ... HDFS目录
# 在HDFS中复制多个文件到“/user/hadoop/dir1”
hadoop fs -cp /input2/file1.txt /input2/file2.txt /user/hadoop/dir1
# 在本地文件系统中复制多个文件到目录“/tmp”
hadoop fs -cp file:///file1.txt file:///file2.txt file:///tmp
删除文件 rm , rmr
删除指定的文件,只删除非空目录和文件
hadoop fs -rm 非空目录和文件
rm的递归版本,整个文件夹及子文件夹将全部删除
hadoop fs -rmr 非空目录和文件
# 删除非空文件“/intpu2/file1.txt”
hadoop fs -rm /intpu2/file1.txt
# 递归删除“/user/hadoop/dir1”
hadoop fs -rmr /user/hadoop/dir1
检查 Test
hadoop fs -test -[选项] 文件/目录
-e:检查文件是否存在。如果存在则返回0
-z:检查文件是否0字节。如果是则返回0
-d:检查路径是否为目录,如果是则返回1,否则返回0
检测文件/目录大小 du
hadoop fs -du 文件/目录
# 显示文件大小,如果是目录则列出所有文件,及其大小
hadoop fs -du /input2
清空回收站
hadoop fs -expunge
HDFS 的 Java API操作:
配置Windows下Hadoop环境
以上呢, 都是直接在 Linux 上的 Hadoop 中, 直接使用命令行形式操作HDFS;
然而, 这一定不是常用的, 这种操作一般都是在运维时候适合使用的方式:
实际开发中, 都是以Java代码的形式来操作 Hadoop HDFS;
接下来介绍, 如何在Windows中使用Java来操作 HDFS:(首先还要对windows环境进行配置)
在windows系统需要配置hadoop运行环境,否则直接运行代码会出现以下问题:
缺少winutils.exe
Could not locate executable null \bin\winutils.exe in the hadoop binaries
缺少hadoop.dll
Unable to load native-hadoop library for your platform… using builtin-Java classes where applicable
步骤:
第一步:
将hadoop2.7.5(或是其它版本的Hadoop) 文件夹拷贝到一个没有中文没有空格的路径下;需要同学可以私聊资源~
第二步:
在windows上面配置hadoop的环境变量:
HADOOP_HOME变量值:hadoop的安装路径,并将%HADOOP_HOME%\bin添加到path中
第三步:
把hadoop2.7.5文件夹中bin目录下的hadoop.dll文件放到系统盘:C:\Windows\System32 目录下
第四步:关闭windows重启(重启电脑!)
ok, 到这儿windows 就可以操作! Hadoop了!

Java操作 HDFS: 涉及的主要类
操作步骤:
使用FileSystem API编程步骤
获取Configuration对象
获取文件系统的实例FileSystem对象
使用FileSystem对象操作文件…
涉及的主要类
Configuration
- 该类的对象封转了客户端或者服务器的配置
conf.set(); 设置的属性优先级要更高!,如果配置文件中指定的属性与set(); 重复则使用 set(); 滴!FileSystem
- 该类的对象是一个
文件系统对象,
可以用该对象的一些方法来对文件进行操作, 可以通过:FileSystem 类的静态方法 get();获得该对象- get 方法从 conf 中的一个参数 fs.defaultFS 的配置值判断具体是什么类型的文件系统
- 如果我们的代码中没有指定 fs.defaultFS , 并且工程 ClassPath 下也没有给定
相应的配置, conf 中的默认值就来自于 Hadoop 的 Jar 包中的 core-default.xml- 默认值为 file:/// , 则获取的不是一个 DistributedFileSystem 的实例, 而是一个本地文件系统的客户端对象

获取 FileSystem 的几种方式
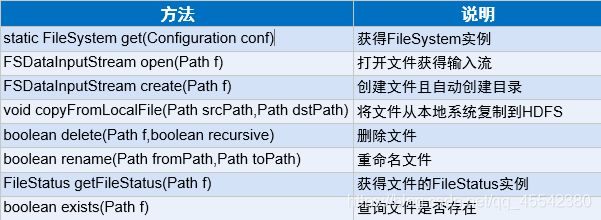
File Ststem类提供两个静态方法获取 FileSystem文件系统实例:
public static FileSystem get(Configuration conf)
public static FileSystem get(URI uri,Configuration conf)
前者由conf决定,也就是由 core- site.xml 中的fs.defautFS 决定返回哪个文件系统的实例
而后者以指定的URI方案为准,将忽略 fs.defautFfs 属性。
第一种方式:普通Configuration set()方式不指定用户
public void getFileSystem1() throws IOException {
Configuration configuration = new Configuration();
//指定我们使用的文件系统类型:
//set(); 会覆盖原来定义好配置文件的属性值...(关于配置文件可以参考上一篇博客~)
//hdfs://192.168.1.110:9000 这里填写自己本机的访问!!
configuration.set("fs.defaultFS", "hdfs://192.168.1.110:9000");
//获取指定的文件系统
FileSystem fileSystem = FileSystem.get(configuration);
System.out.println(fileSystem.toString());
//...正式操作
}
第二种方式:new Configuration() FileSystem指定文件系统访问端口
public void getFileSystem2() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.1.110:9000"),
new Configuration());
System.out.println("fileSystem:"+fileSystem);
//...正式操作
}
第三种方式:指定操作用户, 常用对于创建操作必须要用!
public void getFileSystem2() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.1.110:9000"),new Configuration(),"root");
System.out.println("fileSystem:"+fileSystem);
//...正式操作
}
所用的Jar包 Maven坐标..
Maven超详细教程 Maven可以借鉴this
Maven坐标库:
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.7.5version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-coreartifactId>
<version>2.7.5version>
dependency>
dependencies>
Java常用操作 HDFS:
下载: 从HDFS上下载文件到,Windows本地…
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
public class Hadoop {
//下载: 从HDFS上下载文件到,Windows本地...
public static void downLoad() throws Exception {
//创建 Configuration FileSystem
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.110:9000");
FileSystem fileSystem = FileSystem.get(conf);
//new Path(); 表示HDFS文件系统上的路径;
InputStream is = fileSystem.open(new Path("/user/abc.txt"));
//造文件,要事先确保本地有文件才往里面写文件呀~
File ff = new File("D:/abc.txt");
FileOutputStream os = new FileOutputStream(ff); //创建写入流~
//Hadoop 提供的IOUtils
//可以在输入流out(读) 输出流input(写) 复制数据,由hadoop-common..jar提供!
IOUtils.copy(is, os);
//关闭资源
os.close();
is.close();
}
public static void main(String[] args) {
try {
downLoad();
} catch (Exception e) {
e.printStackTrace();
}
}
}
查看HDFS文件列表
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import java.net.URI;
public class Hadoop {
//查看HDFS文件列表
public static void fileList() throws Exception {
//创建 Configuration FileSystem 对于一些文件需要访问权限需要指定一个用户...
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.1.110:9000"),new Configuration(),"root");
System.out.println("fileSystem:"+fileSystem);
//fileSystem.listFiles:根据HDFS目录,返回目录下File数组;
//new Path(); 表示HDFS文件系统上的路径; true:表示目录包含子目录~
RemoteIterator<LocatedFileStatus> it = fileSystem.listFiles(new Path("/"), true);
//循环打印文件名;
while (it.hasNext()) {
LocatedFileStatus next = it.next();
System.out.println(next.getPath().toString());
}
//关闭文件系统
fileSystem.close();
}
public static void main(String[] args) {
try {
fileList();
} catch (Exception e) {
e.printStackTrace();
}
}
}
创建目录并创建文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class Hadoop {
public static void createDir() throws Exception {
//创建 Configuration FileSystem 对于一些文件需要访问权限 需要指定一个用户...
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.1.110:9000"),new Configuration(),"root");
//fileSystem.mkdirs(..); 在HDFS 文件系统上创建,文件目录...(支持层级创建~)
fileSystem.mkdirs(new Path("/hello/dir/test"));
//fileSystem.createNewFile(..); 在HDFS 文件系统上创建,文件;
fileSystem.createNewFile(new Path("/hello/dir/test/abc.txt"));
fileSystem.close();
}
public static void main(String[] args) {
try {
createDir();
} catch (Exception e) {
e.printStackTrace();
}
}
}
拷贝 或 上传: [本地]文件;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class Hadoop {
//拷贝 或 上传: [本地]文件;
public static void upload() throws Exception {
//创建 Configuration FileSystem 对于一些文件需要访问权限 需要指定一个用户...
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.1.110:9000"),new Configuration(),"root");
//fileSystem.copyFromLocalFile(); 拷贝本地文件到 HDFS那里去~ 当然 文件要事先存在! 目录存在则上传文件,不存在会自动创建!
fileSystem.copyFromLocalFile(new Path("D://abc.txt"), new Path("/hello/dir/"));
fileSystem.close();
}
public static void main(String[] args) {
try {
upload();
} catch (Exception e) {
e.printStackTrace();
}
}
}
删除HDFS 文件/目录结构;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class Hadoop {
public static void delete() throws Exception {
//创建 Configuration FileSystem 对于一些文件需要访问权限 需要指定一个用户...
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.1.110:9000"),new Configuration(),"root");
//fileSystem.delete(); 删除指定目录/文件 true包含子目录结构删除!
fileSystem.delete(new Path("/hello/dir/"), true); //删除HDFS上, hello目录下 dir目录结构;
fileSystem.close();
}
public static void main(String[] args) {
try {
delete();
} catch (Exception e) {
e.printStackTrace();
}
}
}
文件查询 getFileStatus( path p);
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class Hadoop {
public static void selFlie() throws Exception {
//创建 Configuration FileSystem 对于一些文件需要访问权限 需要指定一个用户...
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.1.110:9000"),new Configuration(),"root");
//getFileLinkStatus(path p); 返回一个文件对象;
FileStatus stat = fileSystem.getFileLinkStatus(new Path("/user"));
System.out.println("文件路径:"+stat.getPath());
System.out.println("文件块大小:"+stat.getBlockSize());
System.out.println("文件大小:"+stat.getLen());
System.out.println("副本数量:"+stat.getReplication());
System.out.println("用户:"+stat.getOwner()) ;
System.out.println ("用户组:"+stat.getGroup());
System.out.println("权限:"+stat.getPermission().toString());
fileSystem.close();
}
public static void main(String[] args) {
try {
selFlie();
} catch (Exception e) {
e.printStackTrace();
}
}
}
多文件合并 并写入文件HDFS中!
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.net.URI;
public class Hadoop {
public static void bigFile() throws Exception {
//创建 Configuration FileSystem 对于一些文件需要访问权限 需要指定一个用户...
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.1.110:9000"),new Configuration(),"root");
//在文件系统上创建一个文件,存储小文件的 大文件
FSDataOutputStream os = fileSystem.create(new Path("/bigFile.txt"));
//获取本地对象
LocalFileSystem local = FileSystem.getLocal(new Configuration());
//获取本地的文件列表
FileStatus[] fileStatuses = local.listStatus(new Path("D:\\out"));
for (FileStatus fileStatus : fileStatuses) {
//获取第I个文件输入对象
FSDataInputStream is = local.open(fileStatus.getPath());
//将读取的文件写入到大文件中
IOUtils.copy(is, os);
//每次结束并关闭资源!
IOUtils.closeQuietly(is);
}
IOUtils.closeQuietly(os);
fileSystem.close();
}
public static void main(String[] args) {
try {
bigFile();
} catch (Exception e) {
e.printStackTrace();
}
}
}
到这里, 基本的步骤就是如此了…欢迎后面学习, 建议一建三连呀!