<学习笔记>Algorithm Library Design 算法库设计in c++ I
课程网址http://www.mpi-inf.mpg.de/~kettner/courses/lib_design_03/
做部分内容的总结翻译。
1.产生式编程Generative Programming
- 产生式编程
指的是根据用户需求,自动的从已有的初级的可复用的部件组装成高度定制的中间或终端产品。
- 领域工程
产生式编程高度强调复用性,与领域工程密切相关,领域工程设计复用性而应用工程使用复用性。
- 特征建模
特征建模描述特定概念实体的通用的以及可变的特征,并描述可变特征之间的依赖性。
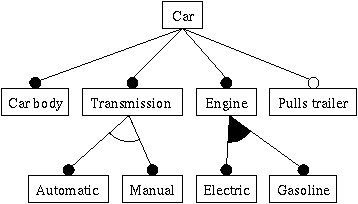
如上图,对于车这个概念实体:
车必须有一个车身,一个变速器,一个引擎。它可以有一个pulls trailer(拖车?)可选的。
对于变速器,它可以是自动的也可以是手工的。两个特性互斥,只能有一个且至少有一个。
对于引擎,它可以有电动装置,也可以有汽油装置,至少有一个,可以两个都有。
于是对于合理的不同特征配置,我们可以组装出下面几种汽车:
{ {Car body, {Automatic}, {Electric}}, {Car body, {Automatic}, {Electric}, Pulls trailer}, {Car body, {Manual}, {Electric}}, {Car body, {Manual}, {Electric}, Pulls trailer}, {Car body, {Automatic}, {Gasoline}}, {Car body, {Automatic}, {Gasoline}, Pulls trailer}, {Car body, {Manual}, {Gasoline}}, {Car body, {Manual}, {Gasoline}, Pulls trailer}, {Car body, {Automatic}, {Electric, Gasoline}} {Car body, {Automatic}, {Electric, Gasoline}, Pulls trailer}, {Car body, {Manual}, {Electric, Gasoline}} {Car body, {Manual}, {Electric, Gasoline}, Pulls trailer}, }
- 特征组装(绑定)时机
可以有下面几种情况:
- 编码时: C++模板,如std::list<int>
- 编译时: C++函数重载,模板(实参演绎,traits),C预处理器-DNDEBUG
- 链接时: makefile配置
- 载入时: 动态链接库
- 运行时(低频率): Sun's HotSpot technology for Java
- 运行时(高频率): C++虚函数
- 经验特征集合
对于ADT的设计可以考虑下面的特征:
- 属性: 如stack的size属性,对于属性可以考虑它是否是const等特征。
- 数据结构: 用来实现ADT
- 操作: 如存取函数,签名,…可能的不同实现方法,可能的优化和特化,绑定模式及绑定时间。
- 错误处理: 异常安全性
- 存储管理: 在stack还是heap上分配,标准分配方式还是定制的分配方式,线程安全性,持久性。
- 同步: 保证共享数据区的多线程安全访问,防止死锁,线程同步
- 持久性: 读写对象到硬盘
- 看待角度和主观性: 考虑可能的使用ADT的不同应用程序的不同需求
对于容器ADT可能考虑:
- 操作的具体数据类型
- 索引方法,如采用整型Key
- 结构: 表示的结构,如 matrix
对于算法可能考虑:
- 问题所属领域: 尝试将问题归为一组,如排序类算法,查找类算法
- 数据访问方法: 如通过accessor,或者通过iterator
- 优化
- 错误处理
- 存储管理
- 并行性: 可能对特定硬件优化
2.C++语言
- 类构造函数,析构函数 1 class A {
2 int i; // private
3 public :
4 A(); // default constructor
5 A( const A & a); // copy constructor
6 A( int n); // user defined
7 ~ A(); // destructor
8 };
9
10 int main() {
11 A a1; // calls the default constructor
12 A a2 = a1; // calls the copy constructor (not the assignment operator)
13 A a3(a1); // calls the copy constructor (usual constructor call syntax)
14 A a4( 1 ); // calls the user defined constructor
15 } // automatic destructor calls for a4, a3, a2, a1 at the end of the block
16
17 class A {
18 int i; // private
19 public :
20 A() : i( 0 ) {} // default constructor
21 A( const A & a) : i(a.i) {} // copy constructor, equal to the compiler default
22 A( int n) : i(n) {} // user defined
23 ~ A() {} // destructor, equal to the compiler default
24 };
25涉及到指针,资源管理需要小心,默认的拷贝构造函数是浅拷贝,下面自己给出深拷贝的拷贝构造函数
关于operator= 下面给出的是很好的一个实现,采用了copy and swap技术,利用了临时变量newbuf
的析构函数自动析构原有的资源(不用if this != &buf也可以)并且是‘异常安全’的。
具体可参考effective c++ 条款11和29.
1 class Buffer {
2 char * p;
3 public :
4 Buffer() : p( new char [ 100 ]) {}
5 ~ Buffer() { delete[] p; }
6
7 Buffer( const Buffer & buf) : p( new char [ 100 ]) {
8 memcpy( p, buf.p, 100 );
9 }
10 void swap( Buffer & buf) {
11 char * tmp = p;
12 p = buf.p;
13 buf.p = tmp;
14 }
15 Buffer & operator = ( const Buffer & buf) {
16 // Check for self-assignment, but its only an optimization
17 if ( this != & buf) {
18 // In general: perform copy constructor and destructor
19 // Make sure that self-assignment is not harmful.
20 Buffer newbuf( buf); // create the new copy
21 swap( newbuf); // exchange it with 'this'
22 // the destructor of newbuf cleans up the data previously
23 // stored in 'this'.
24 }
25 return * this ;
26 }
27 }; - explict用于避免构造函数的隐式转换
struct Buffer { Buffer( int n); // construtor to allocate n bytes for buffer // ... }; void rotate( Buffer& buf); // a function to rotate buffer cyclically int main() { rotate( 5); // oops, a temporary Buffer initialized with 5 will be created }//避免隐式转换
struct Buffer { explicit Buffer( int n); // ... };
构造函数与函数的二义性
struct S {
S(int);
};
void foo( double d) {
S v( int(d)); // function declaration
S w = S( int(d)); // object declaration
S x(( int(d))); // object declaration
}
这个坑还是很深的,因为你想定义一个对象而编译器却认为是函数的声明,很容易出错。C++编译器总是尽可能能解释为函数声明。
用括号括起来是因为我们不能给名称加如foo((int))但是可以给变量加foo((int (x)))
下面是我出过错的地方
<typename T1, typename T2>
class pair;
::pair<int, int> mpair(::pair<int, double>()); //这是函数声明不是产生一个临时变量再用它拷贝构造mpair
:pair<int, int> mp = mpair2; //错误: 请求从‘pair<int, int> ()(pair<int, double> (*)())’转换到非标量类型‘pair<int, int>’
编译器认为::pair<int, int> mpair(::pair<int, double>()) 是pair<int, int> ()(pair<int, double> (*)())的函数声明,而mpair后面的括号里面被认为是一个函数指针。
解决方法::pair<int, int> mpair((::pair<int, double>()));
很绕!不使用匿名对象的话可以提高可读性。参考effective STL 第6条 当心C++编译器最烦人的分析机制,里面给出的错误例子是将一个存有整数int的文件中所有整数拷贝到一个list中。
ifstream dataFile(“ints.dat”);
list<int> data(istream_iterator<int>(dataFile), istream_iterator<int>()); //这样是函数声明!
解决方法1
list<int> data((istream_iterator<int>(dataFile)), istream_iterator<int>());
去掉匿名对象
istream_iterator<int> dataBegin(dataFile);
istream_iterator<int> dataEnd();
list<int> data(dataBegin, dataEnd);
总之当你用到匿名对象构造一个类对象的时候,考虑一下你是否实际上写成了一个函数声明。
- 继承
class B : public A { int j; };//下面b中的j在转型的时候丢失了
int main() { B b; A a = b; }//基类默认的构造函数析构函数会被自动实现,但是用户给出的构造函数是不会被继承类所继承的,所以用户需要在继承类构造函数中显式调用基类的用户定义的构造函数。
基类先构造,继承类部分再构造,继承类部分先析构,基类在析构。不要在构造析构过程中调用虚函数,如果用delete基类指针的方式析构一个继承类对象,那么要注意
基类的析构函数应为虚函数,即为多态基类的析构函数设置为虚函数。否则继承类的析构函数不会被调用,继承类的成员也可能未被销毁。(effective c++ 条款5,6,7,9,12)
class B : public A { int j; public: B( int n) : A(n) {} B( int n, int m) : A(n), j(m) {} };The first constructor and the default constructor leave the value of j uninitialized. We solve this in the following example and use default values to implement the three constructors in one.class B : public A { int j; public: B( int n = 0, int m = 0) : A(n), j(m) {} }; - 虚函数
struct Shape { virtual void draw() = 0; };We derive different concrete classes from Shape and implement the member function draw for each of them.struct Circle : public Shape { void draw(); }; struct Square : public Shape { void draw(); };We cannot create an object of a class that contains pure virtual member functions, but we can have pointer of this type and we can assign pointer of the derived types to them. If we call a member function through this pointer, the program figures out at runtime which member function is meant, Circle::draw orSquare::draw.int main() { Shape* s1 = new Circle; Shape* s2 = new Square; s1->draw(); // calls Circle::draw s2->draw(); // calls Square::draw }This runtime flexibility is achieved with a virtual function table per class. (dispatch table with function pointers). Each object gets an additional pointer referring to this table. Thus, each object knows at runtime of which type it is, which is also used for the runtime type information in C++. These extra costs, additional pointer and one more indirection for a function call, are only imposed on objects which class or base classes use virtual member functions.Since we don't know the size of the actually allocated objects any more, we also have to use a virtual member function to delete the objects properly. It is sufficient to define a virtual, empty destructor in the base class. (see also Shape.C)
struct Shape { virtual void draw() = 0; //提供接口继承。但是也可以提供实现,只是需要子类显示调用该实现。如Shape::draw() virtual ~Shape() {} //一定需要是虚函数 }; // ... the derived shape classes int main() { Shape* s1 = new Circle; Shape* s2 = new Square; s1->draw(); // calls Circle::draw s2->draw(); // calls Square::draw delete s1; delete s2; } - 类的static成员
//静态成员变量
#include <iostream.h>
struct Counter {
static int counter;
Counter() { counter++; }
};
int Counter::counter = 0;
int main() {
Counter a;
Counter b;
Counter c;
cout << Counter::counter << endl; //3
}
注意类中的静态变量counter的定义,只能出现在一个编译单元,类中的静态变量也类似与全局变量。static变量会在main执行之前被初始化好,在同一个编译单元内,
所有的静态变量会按照它们在该单元的声明顺序被初始化,但是不同编译单元的non local static对象的初始话顺序是不定的(nonlocal static对象指global对象,
及除了定义在函数里面的static对象之外的所有static对象) 如果不同编译单元的non local static 对象存在初始化依赖,即某个对象必须要先构造出来,则会出问题。
具体参加effective c++ 条款4 30页,书中提到将static变量转移到函数里面成为local static变量,类似singlton手法。
关于nonlocal static 和 local static对象的构造时机的区别(初此之外其它方便无差异,也是程序结束后才析构),参见
local static对象和non-local static对象在初始化时机上的差异
//静态成员函数
struct A {
static int i;
int j;
static void init();
};
void A::init() {
i = 5; // fine
// j = 6; // is not allowed
}
int main() {
A::init();
assert( A::i == 5);
}
模版
"Lazy" Implicit Instantiation
网页上这个是仅仅类模版具有的特性,函数模版也应该是吧只要没有被用到没有被实例话就行。意思是说类里面的成员函数,编译器不会去管一个函数内部可能的存在的(实参不支持操作)只要具体使用该类模版的实例化后的对象没有用到该函数。如List类可能会有一个sort函数,sort函数要求实参具有可比运算符,如果你实例后的List对象所用的实参是不具有可比性的,那也没关系,只要你不尝试调用sort就不会出错。
-
类成员函数模板
参见effective c++ 条款45 运用成员函数模板接受所有兼容类型
#include <iostream>
using namespace std;
template <class T1, class T2>
struct pair {
T1 first;
T2 second;
pair() {} // don't forget the default constructor if there are also others,even if you only declare your copy constructor you will lose the defualt constructor
pair( const T1& a, const T2& b) : first(a), second(b) {}
// template constructor
template <class U1, class U2>
pair( const pair<U1,U2>& p);
};template <class T1, class T2>
template <class U1, class U2>
pair<T1,T2>::pair( const pair<U1,U2>& p)
: first( p.first), second( p.second) {}int main() {
::pair< int, int> p1( 5, 8);
::pair< double, double> p2(p1);
}注意上面的程序gcc 4.2.4无法编译通过,因为那个template constructor在类外面的定义,gcc报
错误: 模板参数表太多。
但是可以在函数类里面inline 定义。但是诡异的是其实C++是支持这种形式的定义的,问题出在
#include <iostream> 如果没有它程序就编译通过,iostream怎么会影响到它呢,很诡异啊,
谁能告诉我这是为什么?
-
特化,偏特化
template <>
struct vector<bool> {
// specialized implementation
};
template <class Allocator = std::allocator>
struct vector<bool,Allocator> {
// partially specialized implementation
};
当前函数没有偏特化,只有全特化。
-
局部类型,typename关键字
参考 ec++ 条款42 了解typename的双重含义。
template <class T>
struct list {
typedef T value_type;
};
int main() {
list<int> ls;
list<int>::value_type i; // is of type int
}
template <class Container>
struct X {
typedef Container::value_type value_type; // not correct,value_type是一个类型呢还是Container类的一个静态变量呢?因为Container是模板参数,我们还不知道它的具体类型。
// ...
};
template <class Container>
struct X {
typedef typename Container::value_type value_type;
// ...
};
The keyword typename is used to indicate that the name following the keyword does in fact denote the name of a type. However, one cannot just liberally sprinkle code with typenames. More precisely, one must use the keyword typename in front of a name that:
- denotes a type; and
- is qualified: i.e., it contains a scope operator `::'; and
- appears in a template; and
- is not used in a list of base-classes or as an item to be initialized by a constructor initializer list, and
- has a component left of a scope resolution operator that depends on a template parameter.
template<class T>
struct S : public X<T>::Base { // no typename, because of 4
S(): X<T>::Base{ // no typename, because of 4
typename X<T>::Base(0)) } // typename needed
X<T> f() { // no typename, because of 2
typename X<T>::C *p; // declaration of pointer p, typename needed 因为T的存在不知道X<T>的具体类型
X<T>::D *q; // no typename ==> multiplication!
}
X<int>::C *s_; // typename allowed but not needed
};
struct U {
X<int>::C *pc_; // no typename, because of 2 我们知道X<int>的具体类型
};
-
动态多态与静态多态
Polymorphism 多态,指相同的代码可以处理不同的数据类型。C++支持动态和静态的多态,动态多态通过运行时查找虚函数表,而静态多态通过编译时的模板实例化。
动态多态是面向对象编程的核心,而静态多态是泛型编程的核心。
struct Shape {
virtual void draw() const = 0; //注,原文没有const但是如果display(const Shape& s)则要求这必须加const否则不能调用s.draw
virtual ~Shape() {}
};
struct Circle : public Shape {
void draw() const;
};
struct Square : public Shape {
void draw() const;
};
Now we have two ways of writing a single function that works for circles, squares, and any other classes derived from Shape:
我们有两种方法来写一个单独函数,可以操作Circle,Square以及所有从Shape继承而来的类型。
void display (const Shape& s) { // dynamic polymorphism
s.draw();
}
template <class T> // static polymorphism
void display (const T& s) { // T 不需要一定从Shape继承而来的类型,有draw接口即可
s.draw();
}
对于这种情况动态多态更好一些,这是因为
1.静态多态不适合操作一组不同类型的数据。Heterogeneous dynamic collections are difficult to handle。
class Drawing {
list<Shape*> components; // relies on dynamic polymorphism
// ...
}
这里必须用动态多态,即使你采用模板也可以但是Shape,Circle,Square的虚函数机制是必须的。
即使
template <class T>
void display(T s) {
s->draw()
}
也是虚函数其实质作用,因为你只能定义list<Shape*> components,不能list<Shape>或者 list<Shape&>
list<Shape&> 不行,因为 79. 只把值和智能指针放到容器中。把值对象存放在容器中:容器总是假定包含的是类值类型(value-like类型),包括值类型(直接持有),只能指针和迭代器(iterator)。
list<Shape>不行,因为Shape是个抽象类不能实例化,即使Shape不是抽象类那么转换成Shape就丢掉了子类的特性,不可能产生正确的draw结果了。
在操作一组相似但不同的数据集合的时候静态多态无能为力,本质上因为list又不能装入不同类型的数据如同时装入square和circle类型,
所以只能用指针,指针很强大:)如果你实在不喜欢用继承,多态,没办法,尝试动态语言吧,如Python,由于动态语言的特性,那里一个list可以混合装任何数据类型的东西。
#include <iostream>
#include <list>
using namespace std;
struct Shape {
virtual void draw() const = 0;
virtual ~Shape() {}
};
struct Circle : public Shape {
void draw() const
{
cout << "Drawing circle" << endl;
}
};
struct Square : public Shape {
void draw() const
{
cout << "Drawing square" << endl;
}
};
void display (const Shape& s)
{ // dynamic polymorphism
cout << "const haha" << endl;
s.draw();
}
int main()
{
Circle c1;
Square s1;
//list<Shape&> shape_list; //wrong!
//list<Shape> shape_list; //wrong!
typedef list<Shape *> List;
typedef List::iterator Iter;
List shape_list;
Iter iter;
shape_list.push_back(&c1);
shape_list.push_back(&s1);
for (iter = shape_list.begin(); iter != shape_list.end(); ++iter) {
(*iter)->draw();
}
return 1;
}
//result
Drawing circle
Drawing square
2.静态多态会产生代码膨胀问题。因为一个display<T>对于square 和 circle会产生不同的代码,不同的类型实例化都会产生不同代码。
3.不支持分离编译。No separate compilation. Compilation of display<T> needs the definition of T.
当然也有更适合静态多态的场合:
例如交换两个相同类型的对象。
template <class T>
void swap( T& a, T& b) {
T tmp = a;
a = b;
b = tmp;
}
The basic operations used by swap are copy constructor and assignment. To do this with virtual functions, we need a base class with virtual versions of copy constructor and assignment. Because a constructor cannot be virtual and virtual assignment has its problems (see [Gillam98]), we use normal member functions:
swap基本的操作是拷贝构造以及赋值。用虚函数实现的话,我们需要基类有虚的构造函数和赋值操作符。但是因为构造函数不能是虚函数,以及虚的赋值操作符有种种问题,我们使用普通的函数。
struct Swappable {
virtual Swappable* clone() const =0;
virtual Swappable& assign(const Swappable& rhs) =0;
virtual ~Swappable() {};
}
void swap (Swappable& a, Swappable& b) {
Swappable* tmp = a.clone();
a.assign(b);
b.assign(*tmp);
delete tmp;
}
现在只有是从Swappable继承而来的并且适当定义了assign和clone函数的对象,swap函数就可以调用其工作。显然这比用模板实现繁琐了许多,不方便不灵活。
动态多态的其他问题:
1.不能很好的处理常规类型built_int types.
2.影响运行效率(Virtual function call overhead, no inlining.)
3.没有编译时类型检查。Static type checking is compromised. For example, trying to swap objects of two different types cannot be detected at compile time