爬虫系列番外篇(一):公开课
本系列是一些趣味性的爬虫案例实践以及一些趣味知识点总结,希望你能学的轻松的同时,也能获取到你想要的知识点!
快乐学习,知识始终是令人兴奋的!
(项目案例源码:https://github.com/yangge11/scrapy_pro)
蓝奏云网盘信息抓取
课程声明:
本课程为爬虫兴趣课程,针对出现在蓝奏云网盘上的资源文件,进行爬虫采集,纯粹技术学习交流,切勿用作它用!
爬虫开发四部曲:
- 确定要抓取的数据来源
- 确定抓取入口
- 确定解析方式
- 确定数据存储方式
确定要抓取的数据来源

确定抓取入口

确定解析方式

确定数据存储方式
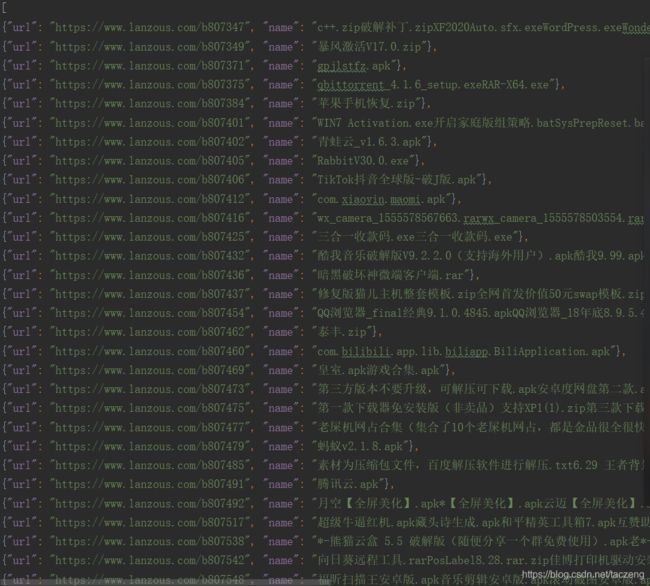
本次采用json格式的数据存储lanzoiu.json
课程记录:
- 确立抓取信息
Apk名称、下载链接、大小、发布时间
- 确定爬虫抓取入口
https://www.lanzous.com/b808695
通过更改链接,实现采集
- 确立解析方式
Json解析(json如何解析,json.loads(text))
- 确定数据存储方式
最好的方式是存储mysql
还可以通过excel或者txt文本的形式存储
https://www.json.cn/#
项目情况:
Scrapy(python爬虫框架)
Github地址:
https://github.com/yangge11/scrapy_pro
爬虫备注:
1.有一点,网站上看到的数据不一定是爬虫就能抓到的数据:
问题:
为什么网站上面肉眼看到的数据,通过爬虫抓取,却无法抓到
原因:浏览器打开是加载了对方的js文件的,而爬虫打开,只访问了url请求,并没有执行js
解决方案:
- 能不能程序加载js文件(能,使用无头浏览器可以解决,但是这种方式不推荐,非常有损爬虫性能)
- 有没有其他的接口,能够访问到这个数据(有的)
爬虫访问:请求url==>获取这个url返回的数据
浏览器访问:请求url==>获取这个url返回的数据,如果有js就执行js,并且执行js里面的请求==》多了几次url请求
怎么找这些多了的url请求:
2.做爬虫访问,需要关注的点:
请求参数和请求headers(决定你能不能拿到数据)
请求频率和请求ip(决定你拿到数据之后会不会被封)
网络IO(决定你爬虫采集的性能)
找到了关键性接口:
https://www.lanzous.com/filemoreajax.php
POST
lx: 2(b开头暂时不变)
fid: 809018(请求链接获取)
uid: 383946——源码获取的
pg: 1(页面)
rep: 0(不变)
t: 1573830004——源码获取的,先获取t后面的变量名,再根据变量名找到值(var ibjjhv = '1573830780';
)
k: a8aa0f7d0f273f51b113f9a6d0454280——源码获取的,先获取t后面的变量名,再根据变量名找到值(var ibjjhv = '1573830780';
)
up: 1(不变)
比较复杂的情况——请求的时候不给你这些数据,这些数据是前端js计算出来的
accept: application/json, text/javascript, */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
content-length: 90
content-type: application/x-www-form-urlencoded
cookie: UM_distinctid=16e6f0421ac166-0cfa72ea5813c3-7711a3e-240000-16e6f0421ad7e3; pc_ad1=1; CNZZDATA1253610885=2031186109-1573826454-%7C1573826454; CNZZDATA1253610888=940304754-1573816854-%7C1573827654; sec_tc=AQAAAP5v50W3cgwAePSa50D6tsLiEmCr
origin: https://www.lanzous.com
referer: https://www.lanzous.com/b809018
sec-fetch-mode: cors
sec-fetch-site: same-origin
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36(是一个比较关键的headers,最好在爬虫访问的时候加上,不然很容易被鉴定为爬虫)
x-requested-with: XMLHttpRequest
这个项目有一点值得注意:
不能进行高并发的请求,否则,会被视为爬虫,封禁IP(解决方案:使用代理IP去进行高并发抓取)
一般遇到httpcode=403forbidden就代表被对方反爬