怎么提取mask的边界_HCP是怎么处理结构像数据的

HCP是质量很高的公开数据集,我最近在研究其中的结构像数据,整理了一下官方的预处理过程。
对于FreeSurfer, 我们在使用的时候,只需要一句recon-all就可以执行完所有的计算,接着就可以进行读取结果,关于recon-all的计算细节我们可能不怎么关心。这篇文章会涉及很多我们不知道也不会妨碍我们使用FreeSurfer 的原理性知识,所以读起来可能没那么容易。
如果有地方犯错,欢迎大家斧正。
Let‘s go!
PreFreeSurfer
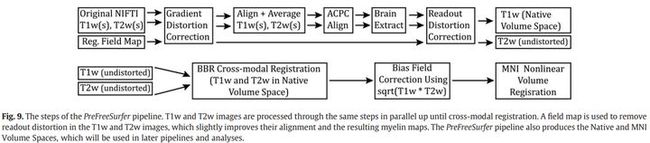
1. MR gradient-nonlinearity-induced 失真校正
由于the custom HCP Skyra 的设计,使得HCP Skyra图像的梯度非线性影响更显著,特别在额叶。
失真校正中,每个梯度线圈产生的磁场用a spherical harmonic expansion来模拟。
校正然后使用FreeSurfer中的gradient_nonlin_unwarp工具包的自定义版(参考文献),这个定制版本的工具包计算了一个FSL格式的 warpfield,该warpfield通过使用专有的西门子梯度系数文件(我需要提供这个文件吗?)和图像的mm坐标空间(图像矩阵空间和扫描轴之间的旋转,sform斜的部分,sform将体素坐标与扫描仪的mm坐标空间相关联,由nii标准定义)来表示图像的空间失真。这个warpfield可以与其它转换连接起来或者通过样条插值(产生的模糊少于三线性插值)应用到图像上。
对于HCP Skyra(这是什么?),需要这样的校正(头部在isocenter以上约5cm),对于普通的扫描仪,不需要这种校正。
2. 随后使用FSL的FLIRT,将任何重复的run的T1w和T2w的图像与一个6自由度的刚体变换对齐。HCP数据中,只有质量评价中判断为“good”或“excellent”的图像被用于处理。对于很多被试,只有一个run(only a single run)被用于T1w或者T2w。
3. 为了更高的鲁棒性(系统在遇到异常或危险时保持稳定的能力),图像内部裁剪成较小的FOV(field of view)以去除颈部(150 mm in z in humans),这一步使用FSL的automated robustfov tool,并且图像与MNI空间模板进行12自由度(DOF)FLIRT配准对齐。这种对齐使得MNI空间脑mask在最终配准前被应用,以mask out任何残留的移位的头皮脂肪信号。最终的转换到输出平均空间是通过样条插值来最小化模糊(blurring)。

4. 接着,T1w和T2w平均图像对齐到MNI空间模板(具有0.7mm分辨率的HCP数据)使用刚体6自由度变换,由12自由度的仿射配准而得。这步对齐的目的是使图像的方向与模板大致,便于可视化。这一步还将坐标空间轴与MNI模板的坐标空间轴对齐,移除mm坐标空间和图像矩阵之间的旋转(i.e. 移除nii sform的倾斜量,因为在不同的成像软件平台上,倾斜sform的处理并不一致)。与之前在各个run之间平均的过程类似,使用robustfov来保证该配准是robust的以及这个变换运用的是样条插值。
5. 上一步“acpc alignment”之后,使用初始线性(FLIRT)和非线性(FNIRT)配准图像到MNI模板,实现了robust的初始大脑提取(initial brain extraction),然后,这个warp被倒转,模板大脑mask被带回到acpc-alignment空间。这种将atlas brain mask带到个人空间的方法优于其他的大脑提取方法,比如FSL的BET,唯一不好的是增加了处理的时间。这个最初的brain mask被用来协助最终配准到MNI space的过程,并协助Freesurfer的brain mask创建过程。
6. 创建一个被试的未失真native volume space的最后一步是消除读出写真,读出写真 T1w和T2w图像之间是不同的,因为它们的读出停顿时间不同(因此带宽不同)。与梯度非线性或EPI失真相比,这种失真是相当微妙的,但与EPI失真相似的是,由于磁化率的差异,在B0不均匀性高的地方,这种失真最大(特别是眶额皮层和颞下皮层)。因此,读出失真可以采用与EPI失真相同的方法校正,即用一个field map作为失真场(distortion field),并根据读出停留时间对其进行缩放。
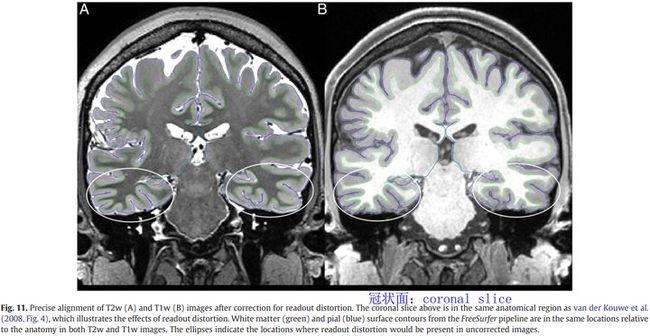
对于field map的预处理,一个标准的梯度回波field map(有两个大小(magnitude)的图像(在两个不同的TEs)和一个相位差异图像),被转为field map(单位是弧度每秒)使用fsl_prepare_fieldmap script。然后平均magnitude和field map图像进行了梯度非线性失真校正(就像T1w和T2w图像一样)。根据读出失真,将the field map magnitude image 进行变形(warped),并分别用6自由度FLIRT将其配准到T1w和T2w。然后根据这些配准变换the field map,并用于解变形T1w和T2w,消除其中存在的差分读出失真。尽管被校正的T1w和T2w图像的分辨率高于the field map,但B0不均匀性是平滑变化的,因此用该方法可以准确地校正。经过readout-distortion-corrcted的T1w图像已经消除了所有空间失真,它表示每个被试的native volume space。
使用FLIRT的基于边界的配准(BBR)代价函数(6 自由度)将未失真的T2w图像cross-modally配准到T1w图像,并将其带入native volume space。BBR旨在对齐组织边界上的强度梯度,而不是最小化整个图像强度集的成本函数。这种配准策略使用了与人眼评估图像对齐相同的对比度机制,如果a field map不能用于结构图,流程可以在没有field map的情况下运行,只是执行T2w到T1w的FLIRT BBR cross-modal配准,也没有消除读出失真。当T1w和T2w图像在同一空间时,采用myelin mapping的同强度不均匀性校正方法对T1w和T2w图像进行B1偏置和B1+偏置校正。偏置场F由non-brain tissues阈值化(threshold out)后的T1w和T2w图像乘积的平方根估计。这种方法之所以有效,是因为灰质和白质内的T1w MPRAGE中的对比度x和在T2w空间中的1/x在相乘后本质上抵消了,而偏置场F却没有。

7. 在扩大阈值偏置场估计(F)以填充FOV后,偏置场用5mm的sigma平滑。这个方法避免了在FSL的FAST和MINC的nu_correct等算法中遇到的问题,这些算法使用白质均匀性作为偏置场校正的基础。正如T1w和T2w图像中由于髓鞘的含量导致灰质不均匀一样,白质也不均匀。由于灰质和白质不均匀性不是密切相关的,用白质强度的不均匀性来校正灰质的不均匀性很可能会引入错误。
8. 在T1w和T2w图像偏置场校正之后,使用FLIRT 12自由度仿射将T1w图像被配准到MNI空间,然后进行FNIRT非线性配准,产生最后的从被试的native volume space到MNI space的非线性volume变换。
PreFreesurfer流程的输出被整理到一个文件夹(默认是T1w),包括the native volume space图像和一个子文件夹(默认是MNINonLinear),包括MNI空间图像。
另外这个PreFreesurfer流程可以在许多人类数据集中稳定地工作(HCP Pilot datasets;Conte69 datasets ;HCP Phase Ⅱ datasets),如果给黑猩猩和猕猴适当的模板和大脑尺寸,也将适用于黑猩猩和猕猴的数据集。因此,流程没有严格地限制在MNI空间,可以与任何其他标准空间一起工作,但有一个前提是在所需的输出分辨率下生成适当的模板文件(i.e. 获取的数据分辨率为高分辨率模板)。
FreeSurfer
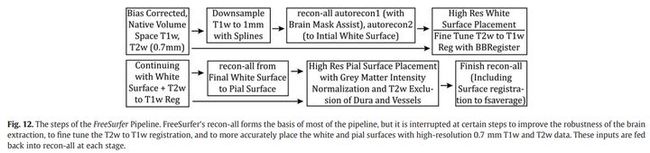
在PreFreesurfer流程结束后,运行FreeSurfer流程。FreeSurfer 的recon-all步骤对于优化1mm各同向性数据来说,是经过广泛实验和稳定的。然而,针对分辨率更高的HCP Phase Ⅱ数据,我们对这个流程的几个方面进行了微调。Recon-all的一个限制是它不能处理分辨率大于1mm各同向性的图像或者大于256*256*256体素的结构扫描。我们获得的0.7mm的各同向性分辨率结构像扫描超过了这个限制,因此必须在执行recon-all之前通过样条插值降采样至1mm。因此,recon-all的大多数处理都会在1mm的各同向性降采样(RAS)空间进行,我们称为FreeSurfer空间.
1. FreeSurfer流程的T1w像输入是PreFreeSurfer流程生成的native volume space输出——失真和偏差校正后的T1w图像(the distortion- and bias-corrected T1w image)。这个T1w图像被标准化为标准全脑平均强度来保证FreeSurfer向8-bit数据类型的转换是鲁棒性强的。早先,HCP Phase Ⅱ的T1w数据没有使用FreeSurfer的大脑提取之前的线性配准进行可靠的配准。而现在使用PreFreeSurfer中生成的initial mask来辅助配准,以保证FreeSurfer的internal brain mask是正确的。
除了这些改变外,recon-all照常运行。最终的白质表面生成使用1mm降采样T1w图像的分割。对于最后的白质表面放置,我们使用了HCP T1w图像的0.7mm分辨率。将所需的FreeSurfer volume和surface文件引入0.7mm的native volume space,对高分辨率的T1w volume进行强度归一化,并根据0.7mm T1w图像中的强度梯度调整白质表面位置。这一调整修正了由于白质表面在1mm处存在局部体积效应而在灰质层中放置太浅的区域。
另外,T2w到T1w的配准使用FreeSurfer的BBRegister算法进行微调,得到的结果比FLIRT的BBR的结果稍微更准确,因为FreeSurfer配准时使用的表面质量更高。

然后将校正后的白质表面带回到FreeSurfer空间,继续进行recon-all处理(注意表面没有重新retessellated所以没有像原始的0.7mm图像那样产生那么多的顶点)。Recon-all阶段完成了白质表面的球形膨胀、基于皮质折叠模式的对fsaverage表面的配准以及脑沟和脑回的自动分割等。
2. 在pial表面生成之前,再次停止recon-all,使用一种改进的算法同时使用高分辨率的T1w和T2w图像得到pial表面。
首先,T1w和T2w图像标准化到标准平均白质强度。如上所述,在PreFreeSurfer偏差场校正后,灰白质之间的残余强度不均匀性并不一定相关,因此我们不使用FreeSurfer的白质特定强度标准化图像来生成pial 表面。取而代之,我们对T1w图像进行灰质特定强度标准化。初始的pial表面是由使用放宽高斯参数的高分辨率的PreFreeSurfer偏差校正的T1w图像生成的(包括灰质平均强度上下4 sigmas,与标准设置的3 sigmas)。这往往包含大量的硬脑膜和血管,可能导致pial表面不能正常跟随眼底沟(sulcal fundi),但降低了排除浅髓灰质的可能性。为了去除硬脑膜和血管,使用T2w图像erode the pial表面。在T2w图像中硬脑膜和血管与灰质的强度相差很大,但在T1w图像中它们接近等强度。
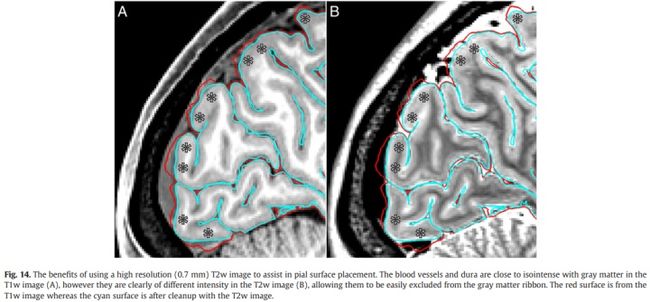
初始的pial表面与白质表面一起来定义一个初始的体素灰质带,它的中心位于两个表面之间。对T1w图像使用带约束的方法和5mm的sigma进行平滑,然后用平滑后的图像(移除平均后)对原始图像进行分割。这些操作有效地在灰质带内进行空间高通滤波,消除了图像中髓鞘含量差异的低频效应,同时保留了相对皮质pial表面和径向皮质内对比度的高频效应。这个空间高通滤波的T1w图像用于重新生成具有更多限制性高斯参数(灰质平均强度上下2sigma)的pial 表面。
T2w表面再一次被用来移除脑硬膜和血管,结果就是最终的pial 表面。Pial表面现在适当地跟随volume的轮廓,但是并不排除轻度髓鞘化的灰质。这些操作的好处在先前介绍的平均Conte69 myelin maps上很明显,尤其是在轻度髓鞘化的内侧前额叶和前扣带回皮层中。在这个pial表面生成之后,recon-all继续完成。最后的步骤包括表面和体积解剖分离,结构体积、表面积、厚度的形态学测量。
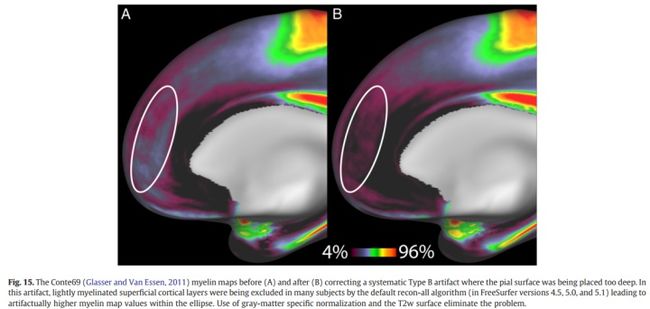
PostFreeSurfer

1. 将freesurfer的输出转换成标准的NIFTI和GIFTI格式.另外从FreeSurser的1mm isotropic downsampled (RAS) space 转到 native volume space. The white, pial, spherical, registered spherical surfaces转换成gii表面(surface)文件,thickness, curvature, sulc 转换成gii形状(shape)文件。
三种FreeSurfer的皮质分裂(cortical parcellation)转为gii label文件,三种full subcortical volume parcellations转为nii label文件。Volume parcellations的其中之一,wmparc,二值化,膨胀(dilate)三次侵蚀(erode)两次产生一个精确的特定被试的灰质、白质的大脑mask,用于后续的功能和扩散处理。(侵蚀和扩张过程的目标是填补mask内的大部分洞,和大脑紧密贴合。扩张比侵蚀多一次是确保mask向下采样时,partial volume brain voxels没有被排除在面具之外。)
另外,将T1w和T2w的结构变换(PreFreesurfer和Freesurfer生成)合并为单一变换,应用于平均的T1w和T2w图像,通过单一样条插值将其带入native volume and MNI spaces.
在这个文件夹中,通过平均the white and pial surfaces, 生成了一个mid-thickness表面,基于这个表面,生成了inflated和very inflated表面。这些文件整理为了一个“spec”文件,按数据类型列出相关文件,可以加载到Connectome Workbench中,以查看标准的解剖数据集。
以上的表面坐标文件都存在于native volume space, native surface mesh space,存储在T1w/Native folder。
2. PostFreesurfer生成的下一个空间是native mesh(原生网格),MNI volume space,所有的解剖表面文件都使用native到MNI 非线性体积变换进行转换。有一个spec文件生成,其中包含标准解剖数据集,数据在MNINonLinear/Native中。
3. 下一步是将个体被试的native-mesh表面配准到Conte69群体平均表面,将标准FreeSurfer registration与group fsaversge连接,配准到Conte69 atlas上。这个联合的表面配准被应用到所有的表面和表面数据文件,使得它们符合164k_fs_LR标准表面网络(这个mesh的平均顶点间距在中间厚度上约0.9mm,这代表了在2mm各向同性分辨率下获得的fMRI数据的过采样)。生成了一个spec文件在MNINonlinear的根目录。
为了避免文件过大,使用了32k_fs_LR空间,平均顶点间距在中间厚度表面上约2mm,这个表面不像原生网络那样精确地跟踪解剖轮廓,它能准确地描绘出大脑皮层的形状,以便进行视觉化和表面约束分析。因为顶点的数量更少,一旦数据被映射到使用更精确的本地网格(native mesh)的表面上,这个低分辨率的表面更适合功能或连接分析。同样,有一个spec文件,列出了解剖数据的标准集,和数据一起在MNINonLinear/fsaverage_LR32k文件夹中。
之后,这个32k_fs_LR mesh从MNI空间转到native volume空间,以便使用这个mesh进行可视化发生在native volume空间中。同样,有一个spec文件,列出了解剖数据的标准集,和数据一起在T1w/ fsaverage_LR32k文件夹中。
4.采用一种新的自适应重心表面重采样方法
5. 产生皮质带(cortical ribbon)的精确体积分割;产生表面髓鞘(myelin maps)图和带体积髓鞘图(ribbon volume myelin maps),简单地说,就是white和pial表面之间的体素的T1w/T2w比率被映射到中厚表面上。
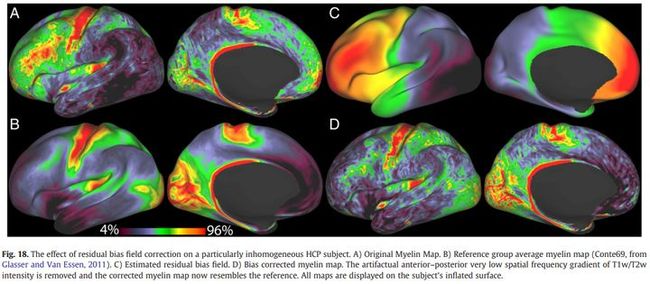
6. 平面上T1w/T2w强度的预期低空间频率分布模型来校正图像中存在的残余偏置场。
在Conte69 mesh上取之前的组平均myelin maps,使用PostFreesurfer流程的表面配准逆向将它们带入每个个体的native mesh中。
上图展示这种校正对具有特别大残余偏置场的HCP主体的效果。
校正过的myelin maps文件:MyelinMap_BC文件
References
The minimal preprocessing pipelines for the Human Connectome Project[J]. Neuroimage, 2013, 80:105-124.
FreeSurfer的官方WIKI