阿里巴巴开源限流降级神器Sentinel大规模生产级应用实践
阿里巴巴开源限流降级神器Sentinel大规模生产级应用实践
题图:
前言
互联网上关于限流算法、Sentinel功能介绍、基本结构、原理分析的文章可谓汗牛充栋,我并不打算重复制造内容。我将为大家分享在实际工作和生产环境中使用、踩坑的经验。
如果你正在做限流、熔断的技术选型,那么本文将会为你提供客观、有价值的参考;
如果你将来要在生产环境中使用Sentinel,那么本文将会帮助你后续少走弯路;
如果你正在准备求职面试,或许可以帮你的技能树和经验上增加亮点,避免你的面试评价表上被人写上“纸上谈兵”;
开源版Sentinel和阿里内部的是一样的吗?我们可以在大规模生产级应用吗?
这里我先直接告诉大家答案:开源的和内部版本是一样的,最核心的代码和能力都开源出来了。可以生产级应用,但并非 “开箱即用”,需要你做一些二次开发和调整,接下来我会对这些问题仔细展开。当然,我更推荐你直接使用阿里云上的AHAS Sentinel 控制台和ASM配置中心,那是最佳实践的输出,你可以节省很多时间、人力、运维成本等。
总体运行架构
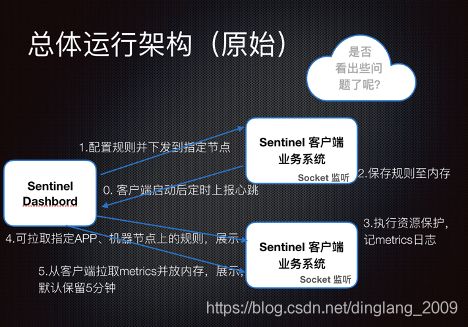
大规模生产级应用面临的问题
看完Sentinel开源版原始的运行架构,很明显其中存在一些问题:
- 限流、降级等规则保存在应用节点的内存中,应用发布重启后就会失效,这在生产环境中显然是无法接受的;
- 规则下发默认是按照机器节点维度的而非按应用维度,而正常公司的应用系统都是集群部署的,而且这样也无法支持集群限流;
- metrics信息由Dashboard拉取上来后保存到内存中,仅仅保留5分钟,错过后可能无法还原 “案发现场”,而且无法看到流量趋势;
- 如果接入限流的应用有500+个,每个应用平均部署4个节点,那么总共2000个节点,那么Dashboard肯定会成为瓶颈,单机的线程池根本处理不过来;
如何优化并解决这些问题
接下来,我们就先一一的介绍如何解决上述这些明显的问题。
首先,限流规则、降级规则等都应该按照应用维度去下发,而不是按照APP单节点的维度。因为Sentinel支持集群限流,所以开源版本的Sentinel Dashbord 在针对限流规则这块已经做了扩展,但对于熔断、系统保护等还未扩展支持按应用维度下发,感兴趣的读者可以参考 FlowControllerV2 的实现去实现。
其次,规则不应该保存内存中,应该持久化到动态配置中心,而应用直接从配置中心订阅规则即可。这样,Dashboard和应用就通过配置中心实现解耦了,这是典型的生产者消费者模式,基本运行架构如下:
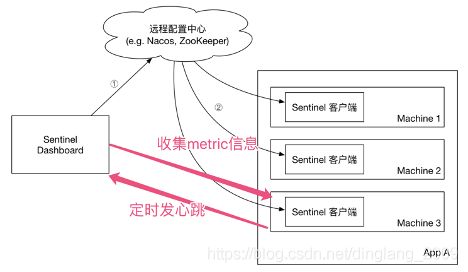
以nacos配置中心为例,Sentinel官方和社区提供了限流规则保存和订阅的Demo,接下来熔断降级、系统保护、网关限流…等规则你其实都可以“照猫画虎”的去扩展。基本模式就是:Dashboard将xxRuleEntity VO模型序列化后保存到nacos,应用从nacos订阅后反序列成xxRule领域模型。
这里我特别提醒一下各位前方有巨坑,“热点参数限流规则”和“黑名单限制规则”这块请勿直接照搬,因为Dashboard 中定义的ParamFlowRuleEntity、AuthorityRuleEntity
这2个VO模型和领域模型ParamFlowRule、AuthorityRule中的字段定义不匹配,会导致序列化/反序列化失败的问题,继而导致应用无法订阅和使用热点参数限流规则和黑名单限制规则,这块我会提交PR!!!
第3点,Dashboard中有个调度线程池,会轮询方式请求(默认是每隔1秒钟发起)各应用的机器节点查询metrics日志信息,聚合后并在界面上做监控展示(改造后还需完成持久化动作)。这是典型的pull模式,是目前监控度量领域比较通用的架构。因为是保存内存中所以默认仅保留5分钟,这也是有问题的。推荐有如下几种解法:
- Dashboard在拉取到metrics信息后,直接保存到时序数据库中,Dashboard自身也从时序数据库中取数据展示。metrics数据存多久,这个你自己根据业务来决定。以开源的Influxdb为例其自带持久策略功能(数据过期自动清理)。并且,你还可以借助Grafana等开源Dashboard做查询、聚合,展示各种漂亮的大盘、图形、排行榜等;
- 你可以将pull的模式改为push模式,在记录metrics日志时改为直接写时序数据库,当你,基于性能的考虑你也可以改为写MQ做缓冲。除了耗时,最关键的是不能因为这个记录metrics的动作影响到主业务流程的推进;
- 继续打印metrics日志,启用Sentinel Dashboard拉取metrics数据,改用直接在应用机器节点上通过采集器对metrics日志做采集、处理、上报,可以借助ELK等工具;
- 你可以尝试自己开发Prometheus Exporter,自己将metrics信息以Target形式暴露出去,由Prometheus服务端定时去拉取,同时你也可以使用Prometheus提供的各种丰富的查询、聚合的语法和能力,通过Grafana等做展示;
下图是典型的时序数据的例子,天生就是为metrics指标数据而设计的,该领域比较知名的开源软件有OpenTSDB、Influxdb等。
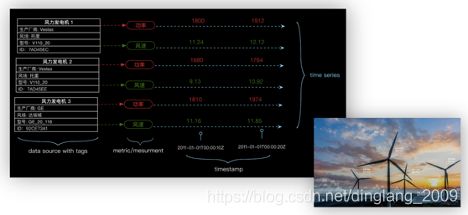
Grafana 限流大盘展示效果图
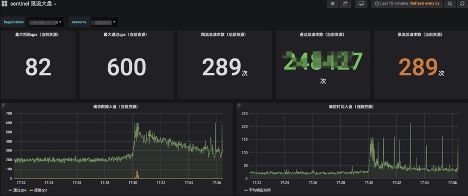
以上方式各有优劣,如果你想改动最小,并且你们应用接入和部署规模并不是特别大(500节点以内),那么请选择第1种方式。
第4点,关于接入应用和节点较多导致Dashboard在拉取、聚合时的性能瓶颈。在解决问题3的时候,如果你选择了2,3,4这几种方法,那么Sentinel自带的Dashboard将仅仅作为规则下发的工具(甚至规则下发都可以直接通过nacos配置中心的控制台完成),自然就不会有瓶颈的问题了。如果你依旧想借助Sentinel自带的Dashboard来完成metrics数据的拉取和持久化等任务,那么我提供给你有两个解法:
- 按领域隔离,不同业务域的应用连接到各自的Sentinel Dashboard上,这样自然就分摊压力减少瓶颈出现的可能性了。优点就是几乎无需做改造,缺点就是显得不统一;
- 你可以尝试改造Sentinel自带的Dashboard,让其具备无状态性。前面我们提过,应用端启动后会定时上报心跳信息,Dashboard这边默认会在内存中维护一份 “节点信息列表”的数据,这个是典型的状态性数据,应该考虑放到集中存储中,例如:redis中。然后你需要改造“拉取metrics信息”的线程池,改为分片任务方式去执行,这样达到分摊负载的作用,例如:改为使用elasticjob调度。当然,时序数据库的写入也是有可能成为瓶颈的;
- 你可以牺牲一点监控指标的时效性,将Sentinel Dashboard中fetchScheduleService调度线程池的间隔时间参数调大一点,这样可以缓解下游工作线程池的处理压力;
就我个人而言其实更推荐第1,3这两种方式,这都是改动比较小的权宜之计。
当然,按领域划分其实也是有其他好处的。你试想如果接入了500+系统,以目前开源版的Dashboard为例,左侧应用列表得拉多长?估计没法使用了,这UI和交互设计上都是业余的显然无法满足大规模生产级应用的。但是按领域隔离后,或许在体验上会有所改善。而且还有一点,目前开源版本的Dashboard只提供了最基本的登录验证功能,如果你想要权限控制、审计、审批确认等功能是需要二次开发的。如果Dashboard这块按领域独立了,在权限控制这块的风险性会更小。
当然,如果你想重构Dashboard权限控制以及UI交互这些,我建议是按照应用维度来设计,加入基本的搜索等。如果
其他的问题
应用在接入Sentinel后,需要启动时指定应用名称、Dashboard地址、客户端的端口号、日志配置、心跳设置等,要么通过JVM -D 启动参数来实现,要么在指定的路径下存放配置文件来配置。这都是不太合理的设计,对CI/CD和部署环境有侵入性,我在1.6.3版本时解决了这个问题并提交过PR,好在社区在1.7.0时解决了这个问题。
规则配置和使用上的一些经验
请不要误会,我不是教你怎么配置怎么使用,而是教你如何用好,还记得我在之前稳定性保障体系的文章中抛出关于限流的灵魂拷问吗?首先,我们简单回顾下可能会用到的Sentinel中的关键功能。接下来我将以自问自答的方式解答使用者最常见的疑惑,输出最有价值的经验和建议。
- 单机限流
- 集群限流
- 网关限流
- 热点参数限流
- 系统自适应保护
- 黑白名单限制
- 自动熔断降级
单机限流阈值配多少?
这个不能“拍脑袋”,配太高了可能会引发故障,配太低了又担心过早“误杀”请求。还是得根据容量规划和水位设定来配置,而且前提是监控告警灵敏。给出两种比较实用的方式:
- 参考单机容量规划的思路,在软负载中调整某个节点的流量权重和比例直到逼近极限为止。记录极限状态下的QPS,按照单机房70%的水位设定标准,你就可以推算出该资源的单机限流阈值了;
- 你可以周期性观察监控系统的流量图,得到线上真实的峰值QPS,如果该周期内峰值时段应用系统和业务都是健康状态的,那么你可以假设该峰值QPS就是理论水位。这种方式是可能造成资源浪费的,因为峰值时段可能并未达到系统承载极限,适合流量周期性比较规律的业务;
你真的需要集群限流吗?
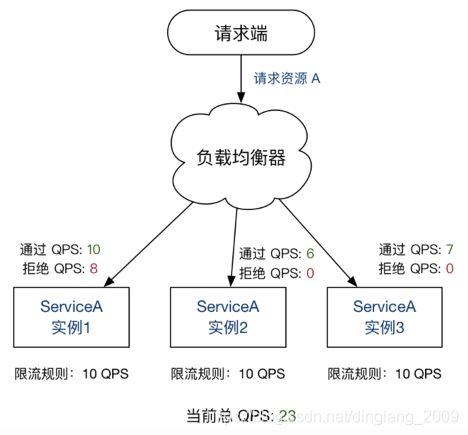
其实大多数场景下你并不需要使用集群限流,单机限流就足够了。仔细思考其实只有几种情况下可能需要使用到集群限流:
- 当想要配置单机QPS限制 < 1 时单机模式是无法满足的,只能使用集群限流模式来限制集群的总QPS。比如有个性能极差的接口单机最多只能扛住0.5 QPS,部署了10台机器那么需要将集群最大容量是5 QPS,当然这个例子有点极端。再比如我们希望某个客户调用某个接口总的最大QPS为10,但是实际我们部署了20台机器,这种情况是真实存在的;
- 上图中单机限流阈值是10 QPS,部署了3个节点,理论上集群的总QPS可以达到30,但是实际上由于流量不均匀导致集群总QPS还没有达到30就已经触发限流了。很多人会说这不合理,但我认为需要按真实情况来分析。如果这个 “10QPS”是根据容量规划的系统承载能力推算出来的阈值(或者说该接口请求如果超过10 QPS就可能会导致系统崩溃),那这个限流的结果就是让人满意的。如果这个“10 QPS”只是业务层面的限制,即便某个节点的QPS超过10了也不会导致什么问题,其实我们本质上是想限制整个集群总的QPS,那么这个限流的结果就不是合理的,并没有达到最佳效果;
所以,实际取决于你的限流是为了实现“过载保护”,还是实现业务层的限制。
还有一点需要说明的是:集群限流并无法解决流量不均匀的问题,限流组件并不能帮助你重新分配或者调度流量。集群限流只是能让流量不均匀场景下整体限流的效果更好。
实际使用建议是:集群限流 (实现业务层限制)+ 单机限流(系统兜底,防止被打爆)
既然网关层已经限流了,那应用层还需要限流吗?
需要的,双重保护是很有必要。同理,上游的聚合服务配置了限流,下游的基础服务也是需要配置限流的,试想下如果只配置了上游的限流,如果上游发起大量重试岂不是依旧可能压垮下游的基础服务?而且这种情况,我们在配置限流阈值时也需要特别注意,比如上游的A,B两个服务都依赖了下游Y服务,A,B分别配置的100 QPS,那么Y服务至少得配置为200 QPS,要不然有部分请求额外的经过透传和处理但最终又被拒绝,不仅是浪费资源,严重了还可能导致数据不一致等问题。
所以,最好是根据全链路总体的容量规划来配置(木桶短板原理),越早拦截越好,每一层都要配置限流。
热点参数限流功能实用吗?
功能挺实用的,可以防止热点数据(比如:热门店铺、黑马商品)占用并消耗过多的系统资源,导致对其他数据的请求处理受到严重影响。
还有一种需求,如果你做C端的产品,你想限制某用户访问某接口的最大QPS,或者你是做B端的SAAS产品,你想限制某租户访问某接口的最大QPS…热点参数默认不是为了满足这类需求而设计的,你需要自行扩展SLOT去实现类似的限制需求。当然,热点参数限流中的paramFlowItemList(参数例外项,可以实现指定某个客户ID=1的大客户访问某资源的最大QPS为100),这在某种程度上是可以实现这种特殊需求的。对于这种需求还有一种解决办法:我们在代码中定义resouceName时就直接给它赋予对应的业务数据标识(例如:queryAmount#{租户Id}),然后根据resouceName去控制台单独配置。
为什么还整出个系统自适应保护啊?
这个其实也是一种兜底的做法。当真实流量超过限流阈值一部分时,开销基本可以忽略,当真实流量远超限流阈值N倍时,尤其是像双十一大促、春晚红包、12306购票这种巨大流量的场景下,那么限流拒绝请求的开销就不能忽略了,这种情况在阿里内部称为“系统被摸死”,这种场景下自适应限流可以做好兜底。
黑白名单限制需要配吗?
如果你想根据请求来源做限制(仅放行指定上游系统过来的请求),那么该功能非常有用的。Sentinel中内置了“簇点链路监控”功能,有点类似调用链监控但目的不一样。
自动熔断降级有啥使用建议?
配置自动熔断降级前,首先我们需要识别出可能出现不稳定的服务,然后判断其是否可降级。降级处理通常是快速失败,当然我们业可以自定义降级处理结果(Fallback),例如:尝试包装返回默认结果(兜底降级),返回上一次请求的缓存结果(时效性降级),包装返回处理失败的提示结果等。
对弱依赖和次要功能的降级通常是人工推送开关来完成的,而Sentinel的熔断降级主要是在“调用端”自动判断并执行的,Sentinel基于规则中配置的时间窗口内的平均响应时间、错误比例、错误数等统计指标来执行自动熔断降级。
举个例子:我们系统同时支持“余额支付”和“银行卡支付”,这两个功能对应的接口默认在相同应用的同一线程池中,任何一方出现RT抖动和大量超时都可能请求积压并导致线程池被耗尽。假设从业务角度来看“余额支付”的比例更高,保障的优先级也更高。那么我们可以在检查到 “银行卡支付”接口(依赖第三方,不稳定)中RT持续上升或者发生大量异常时对其执行“自动熔断降级”(前提是不能导致数据不一致等影响业务流程的问题),这样优先保证“余额支付”的功能可以继续正常使用。
总结
本文主要介绍了Sentinel开源版在大规模生产级应用时所面临的一些问题和解法,还有在实际配置使用时的一些经验,这些经验均来自一线生产实践,希望能让读者朋友少走弯路。如有疑问,欢迎留言讨论。

作者介绍
步崖,曾就职于阿⾥巴巴和蚂蚁金服。熟悉⾼并发、⾼可用架构,稳定性保障等。 热衷 于技术研究和分享,发表过”分布式事务”、”分布式缓存”等多篇⽂章被⼴泛阅读和转载